Hash de recursos
Importante
O suporte para o Machine Learning Studio (clássico) terminará em 31 de agosto de 2024. É recomendável fazer a transição para o Azure Machine Learning até essa data.
A partir de 1º de dezembro de 2021, você não poderá criar recursos do Machine Learning Studio (clássico). Até 31 de agosto de 2024, você pode continuar usando os recursos existentes do Machine Learning Studio (clássico).
- Confira informações sobre como mover projetos de machine learning do ML Studio (clássico) para o Azure Machine Learning.
- Saiba mais sobre o Azure Machine Learning.
A documentação do ML Studio (clássico) está sendo desativada e pode não ser atualizada no futuro.
Converter dados de texto para integrar os recursos codificados usando a biblioteca Vowpal Wabbit
Categoria: Análise de Texto
Observação
Aplica-se a: somente Machine Learning Studio (clássico)
Módulos semelhantes do tipo "arrastar e soltar" estão disponíveis no designer do Azure Machine Learning.
Visão geral do módulo
Este artigo descreve como usar o módulo Hashing de Recursos no Machine Learning Studio (clássico), para transformar um fluxo de texto em inglês em um conjunto de recursos representados como inteiros. Em seguida, você pode passar esse conjunto de recursos de hash para um algoritmo de aprendizado de máquina para treinar um modelo de análise de texto.
A funcionalidade de hash de recurso fornecida neste módulo baseia-se na estrutura Vowpal Wabbit. Para obter mais informações, consulte Train Vowpal Wabbit 7-4 Model or Train Vowpal Wabbit 7-10 Model.
Mais sobre hash de recursos
O hash de recursos funciona convertendo tokens exclusivos em inteiros. Ele opera nas cadeias de caracteres exatas que você fornece como entrada e não executa análise linguística nem pré-processamento.
Por exemplo, pegue um conjunto de frases simples como essas, seguidas por uma pontuação de sentimento. Suponha que você queira usar esse texto para criar um modelo.
| TEXTO DO USUÁRIO | SENTIMENTO |
|---|---|
| Eu adorei este livro | 3 |
| Eu odiei este livro | 1 |
| O livro é ótimo | 3 |
| Eu adoro livros | 2 |
Internamente, o módulo Hashing de Recursos cria um dicionário de n-gramas. Por exemplo, a lista de bigramas para esse conjunto de dados seria algo assim:
| TERM (bigrams) | FREQUÊNCIA |
|---|---|
| Este livro | 3 |
| Adorei | 1 |
| Eu odiei | 1 |
| Eu adoro | 1 |
Você pode controlar o tamanho dos n-gramas usando a propriedade N-grams. Se você escolher bigramas, unigramas também serão computados. Assim, o dicionário também incluiria termos únicos como estes:
| Termo (unigramas) | FREQUÊNCIA |
|---|---|
| agendar | 3 |
| I | 3 |
| livros | 1 |
| é | 1 |
Depois que o dicionário for criado, o módulo Hashing de Recurso converterá os termos do dicionário em valores de hash e calculará se um recurso foi usado em cada caso. Para cada linha de dados de texto, o módulo gera um conjunto de colunas, com uma coluna para cada recurso com hash.
Por exemplo, após o hash, as colunas de recursos podem ter uma aparência semelhante a esta:
| Classificação | Recurso de hash 1 | Recurso de hash 2 | Recurso de hash 3 |
|---|---|---|---|
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 0 |
- Se o valor na coluna for 0, a linha não contém o recurso hash.
- Se o valor é 1, a linha continha o recurso.
A vantagem de usar hash de recurso é que você pode representar documentos de texto de comprimento variável como vetores de recursos numéricos de comprimento igual e obter redução de dimensionalidade. Por outro lado, se você tentasse usar a coluna de texto para treinamento como está, ela seria tratada como uma coluna de recurso categórica, com muitos, muitos valores distintos.
Ter as saídas como numéricas torna possível usar vários métodos de aprendizado de máquina diferentes com os dados, incluindo classificação, clustering ou recuperação de informações. Como as operações de pesquisa podem usar hashes inteiros em vez de comparações entre cadeias de caracteres, a obtenção dos pesos dos recursos também é muito mais rápida.
Como configurar o Hashing de Recursos
Adicione o módulo hash de recursos ao experimento no Studio (clássico).
Conecte o conjunto de dados que contém o texto que você deseja analisar.
Dica
Como o hash de recursos não executa operações lexical, como lematização ou truncamento, às vezes você pode obter melhores resultados fazendo o pré-processamento de texto antes de aplicar hash de recurso. Para obter sugestões, consulte as melhores práticas e as seções de notas técnicas .
Para colunas de destino, selecione as colunas de texto que você deseja converter em recursos de hash.
As colunas devem ser o tipo de dados de cadeia de caracteres e devem ser marcadas como uma coluna de recurso .
Se você escolher várias colunas de texto a serem usadas como entradas, ela poderá ter um efeito enorme na dimensionalidade do recurso. Por exemplo, se um hash de 10 bits for usado para uma única coluna de texto, a saída conterá 1024 colunas. Se um hash de 10 bits for usado para duas colunas de texto, a saída conterá 2048 colunas.
Observação
Por padrão, o Studio (clássico) marca a maioria das colunas de texto como recursos, portanto, se você selecionar todas as colunas de texto, poderá obter muitas colunas, incluindo muitas que não são realmente texto livre. Use a opção Limpar recurso em Editar Metadados para impedir que outras colunas de texto sejam hash.
Use o bitsize hash para especificar o número de bits a serem usados ao criar a tabela de hash.
O tamanho de bits padrão é 10. Para muitos problemas, esse valor é mais do que adequado, mas se basta para seus dados depende do tamanho do vocabulário n-gramas no texto de treinamento. Com um vocabulário grande, mais espaço pode ser necessário para evitar colisões.
Recomendamos que você tente usar um número diferente de bits para esse parâmetro e avalie o desempenho da solução de machine learning.
Para N-gramas, digite um número que define o comprimento máximo dos n-gramas a serem adicionados ao dicionário de treinamento. Um n-grama é uma sequência de n palavras tratadas como uma unidade exclusiva.
N-gramas = 1: Unigramas ou palavras simples.
N-gramas = 2: Bigrams ou sequências de duas palavras, além de unigramas.
N-gramas = 3: trigramas ou sequências de três palavras, além de bigrams e unigramas.
Execute o experimento.
Resultados
Depois que o processamento é concluído, o módulo gera um conjunto de dados transformado no qual a coluna de texto original foi convertida em várias colunas, cada uma representando um recurso no texto. Dependendo do tamanho do dicionário, o conjunto de dados resultante pode ser extremamente grande:
| Nome da coluna 1 | Tipo de coluna 2 |
|---|---|
| TEXTO DO USUÁRIO | Coluna de dados original |
| SENTIMENTO | Coluna de dados original |
| TEXTO DO USUÁRIO – Recurso de hash 1 | Coluna de recurso com hash |
| TEXTO DO USUÁRIO – Recurso de hash 2 | Coluna de recurso com hash |
| TEXTO DO USUÁRIO – Recurso de hash n | Coluna de recurso com hash |
| TEXTO DO USUÁRIO – Recurso de hash 1024 | Coluna de recurso com hash |
Depois de criar o conjunto de dados transformado, você pode usá-lo como a entrada para o módulo Treinar Modelo , juntamente com um bom modelo de classificação, como o Computador vetor de suporte de duas classes.
Práticas recomendadas
Algumas práticas recomendadas que você pode usar durante a modelagem de dados de texto são demonstradas no diagrama a seguir que representa um experimento
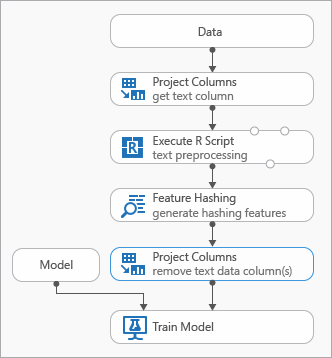
Talvez seja necessário adicionar um módulo Executar script R antes de usar Hash de recurso, para reprocessar o texto de entrada. Com o script R, você também tem a flexibilidade de usar vocabulários personalizados ou transformações personalizadas.
Você deve adicionar um módulo Selecionar Colunas no Conjunto de Dados após o módulo hash de recursos para remover as colunas de texto do conjunto de dados de saída. Você não precisa das colunas de texto após a geração dos recursos de hash.
Como alternativa, você pode usar o módulo Editar Metadados para limpar o atributo de recurso da coluna de texto.
Considere também o uso dessas opções de pré-processamento de texto para simplificar os resultados e melhorar a precisão:
- quebra de palavra
- parar remoção de palavras
- normalização de caso
- remoção de pontuação e caracteres especiais
- Decorrentes.
O conjunto ideal de métodos de pré-processamento a serem aplicados em qualquer solução individual depende de domínio, vocabulário e necessidade de negócios. Recomendamos que você experimente seus dados para ver quais métodos de processamento de texto personalizados são mais eficazes.
Exemplos
Para obter exemplos de como o hash de recursos é usado para análise de texto, consulte a Galeria de IA do Azure:
Categorização de Notícias: usa hash de recurso para classificar artigos em uma lista predefinida de categorias.
Empresas semelhantes: usa o texto de artigos da Wikipédia para categorizar empresas.
Classificação de texto: este exemplo de cinco partes usa texto de mensagens do Twitter para executar a análise de sentimento.
Observações técnicas
Esta seção contém detalhes de implementação, dicas e respostas para perguntas frequentes.
Dica
Além de usar hash de recurso, talvez você queira usar outros métodos para extrair recursos do texto. Por exemplo:
- Use o módulo Pré-processar Texto para remover artefatos como erros ortográficos ou para simplificar o preparatório de texto para hash.
- Use Extrair Frases-Chave para usar o processamento de linguagem natural para extrair frases.
- Use o Reconhecimento de Entidade Nomeada para identificar entidades importantes.
Machine Learning Studio (clássico) fornece um modelo de Classificação de Texto que orienta você usando o módulo hash de recursos para extração de recursos.
Detalhes de implementação
O módulo Hashing de Recursos usa uma estrutura de aprendizado de máquina rápida chamada Vowpal Wabbit que apresenta hashes de palavras em índices na memória, usando uma função de hash código aberto popular chamada murmurhash3. Essa função de hash é um algoritmo de hash não criptográfico que mapeia entradas de texto em números inteiros e é popular porque funciona bem em uma distribuição aleatória de chaves. Ao contrário das funções de hash criptográficas, ela pode ser facilmente revertida por um adversário, de modo que seja inadequado para fins criptográficos.
A finalidade de hash é converter documentos de texto de comprimento variável em vetores de recurso numérico de igual comprimento, para dar suporte à redução de dimensionalidade e tornar a pesquisa de pesos de recurso mais rápida.
Cada recurso de hash representa um ou mais recursos de texto n-grama (unigramas ou palavras individuais, bi-gramas, três gramas etc.), dependendo do número de bits (representado como k) e do número de n-gramas especificados como parâmetros. Ele projeta nomes de recursos para a palavra sem sinal da arquitetura do computador usando o algoritmo murmurhash v3 (somente 32 bits) que, em seguida, é AND-ed com (2^k)-1. Ou seja, o valor de hash é projetado para baixo para os primeiros k bits de ordem inferior e os bits restantes são zerados. Se o número especificado de bits for 14, a tabela de hash poderá conter 2 entradas14-1 (ou 16.383).
Para muitos problemas, a tabela de hash padrão (bitsize = 10) é mais do que adequada; no entanto, dependendo do tamanho do vocabulário de n-gramas no texto de treinamento, mais espaço pode ser necessário para evitar colisões. Recomendamos que você tente usar um número diferente de bits para o parâmetro de bits de Hashing e avalie o desempenho da solução de machine learning.
Entradas esperadas
| Nome | Tipo | Descrição |
|---|---|---|
| Dataset | Tabela de Dados | Conjunto de dados de entrada |
Parâmetros do módulo
| Nome | Intervalo | Type | Padrão | Descrição |
|---|---|---|---|---|
| Colunas de destino | Qualquer | ColumnSelection | StringFeature | Escolha as colunas às quais o hash será aplicado. |
| Hashing bitsize | [1;31] | Integer | 10 | Digite o número de bits a ser usado ao armazenar em hash as colunas selecionadas |
| N-grams | [0;10] | Integer | 2 | Especifique o número de N-gramas gerados durante o hash. Por padrão, unigrams e bigrams são extraídos |
Saídas
| Nome | Tipo | Descrição |
|---|---|---|
| Conjunto de dados transformados | Tabela de Dados | Conjunto de dados de saída com colunas com hash |
Exceções
| Exceção | Descrição |
|---|---|
| Erro 0001 | Ocorrerá uma exceção se uma ou mais das colunas especificadas do conjunto de dados não puder ser encontrada. |
| Erro 0003 | Ocorrerá uma exceção se uma ou mais das entradas for nula ou estiver vazia. |
| Erro 0004 | Ocorrerá uma exceção se o parâmetro for inferior ou igual ao valor específico. |
| Erro 0017 | Ocorrerá uma exceção se uma ou mais das colunas especificadas tiver um tipo sem suporte por módulo atual. |
Para obter uma lista de erros específicos aos módulos do Studio (clássico), consulte Machine Learning códigos de erro.
Para obter uma lista de exceções de API, consulte Machine Learning códigos de erro da API REST.