Executar scripts Python de machine learning no Machine Learning Studio (clássico)
APLICA-SE A:  Machine Learning Studio (clássico)
Machine Learning Studio (clássico)  Azure Machine Learning
Azure Machine Learning
Importante
O suporte para o Machine Learning Studio (clássico) terminará em 31 de agosto de 2024. É recomendável fazer a transição para o Azure Machine Learning até essa data.
A partir de 1º de dezembro de 2021, você não poderá criar recursos do Machine Learning Studio (clássico). Até 31 de agosto de 2024, você pode continuar usando os recursos existentes do Machine Learning Studio (clássico).
- Confira informações sobre como mover projetos de machine learning do ML Studio (clássico) para o Azure Machine Learning.
- Saiba mais sobre o Azure Machine Learning
A documentação do ML Studio (clássico) está sendo desativada e pode não ser atualizada no futuro.
O Python é uma ferramenta valiosa no conjunto de ferramentas de muitos cientistas de dados. Ele é usado em todos os estágios dos fluxos de trabalho típicos de machine learning, como exploração de dados, extração de recursos, validação e treinamento de modelos e implantação.
Este artigo descreve como o módulo Executar Script Python pode ser útil para usar código Python em serviços Web e experimentos do Machine Learning Studio (clássico).
Usando o módulo Executar Script Python
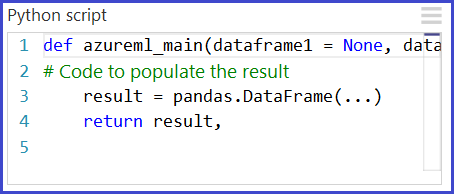
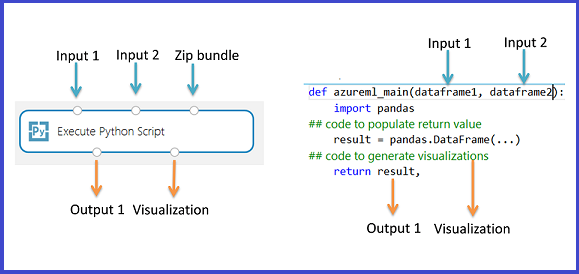
A interface primária para Python no Estúdio (clássico) é por meio do módulo Executar Script Python. Ele aceita até três entradas e produz até duas saídas, semelhante ao módulo Executar Script R. O código Python é inserido na caixa de parâmetro por meio de uma função de ponto de entrada especialmente nomeada chamada azureml_main.
Parâmetros de entrada
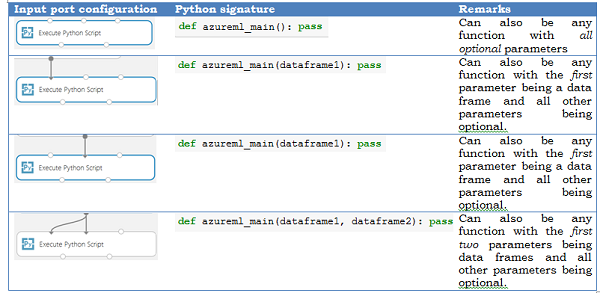
As entradas para o módulo Python são expostas como Pandas DataFrames. A função azureml_main aceita até dois Pandas DataFrames opcionais como parâmetros.
O mapeamento entre as portas de entrada e os parâmetros de função é posicional:
- A primeira porta de entrada conectada é mapeada para o primeiro parâmetro da função.
- A segunda entrada (se conectada) é mapeada para o segundo parâmetro da função.
- A terceira entrada é usada para Importar módulos do Python adicionais.
Veja a seguir uma semântica mais detalhada de como as portas de entrada são mapeadas para parâmetros da função azureml_main.
Valores de retorno de saída
A função azureml_main deve retornar um único Pandas DataFrame empacotado em uma sequência do Python, como tupla, lista ou matriz NumPy. O primeiro elemento dessa sequência é retornado na primeira porta de saída do módulo. A segunda porta de saída do módulo é usada para visualizações e não requer um valor de retorno. Esse esquema é exibido abaixo.
Conversão de tipos de dados de entrada e saída
Os conjunto de dados do Estúdio não são os mesmos dos Panda DataFrames. Consequentemente, os conjuntos de dados de entrada no Estúdio (clássico) são convertidos em Pandas DataFrames, e os DataFrames de saída são convertidos de volta em conjuntos de dados do Estúdio (clássico). Durante esse processo de conversão, também são realizadas as seguintes conversões:
| Tipo de dados do Python | Procedimento de conversão do Estúdio |
|---|---|
| Cadeias de caracteres e numéricos | Convertido no estado em que está |
| Pandas 'NA' | Convertido como 'Valor ausente' |
| Vetores de índice | Sem suporte* |
| Nomes de coluna que não são de cadeia de caracteres | Chamar str em nomes de coluna |
| Nomes de coluna duplicados | Adicionar sufixo numérico: (1), (2), (3) e assim por diante. |
*Todas as estruturas de dados de entrada na função Python sempre têm um índice numérico de 64 bits que varia de 0 até o número de linhas menos 1
Importando módulos de script Python existentes
O back-end usado para executar Python se baseia em Anaconda, uma distribuição científica do Python amplamente utilizada. Ele vem com quase 200 dos pacotes de Python mais comuns usados em cargas de trabalho centradas em dados. O Estúdio (clássico) atualmente não dá suporte ao uso de sistemas de gerenciamento de pacotes, como PIP ou Conda, para instalar e gerenciar bibliotecas externas. Se você achar necessário incorporar bibliotecas adicionais, use o cenário a seguir como guia.
Um caso de uso comum é incorporar scripts Python existentes em experimentos do Estúdio (clássico). O módulo Executar Script Python aceita um arquivo zip contendo módulos do Python na terceira porta de entrada. O arquivo é descompactado pela estrutura de execução no runtime e o conteúdo é adicionado ao caminho da biblioteca do interpretador de Python. A função do ponto de entrada azureml_main pode, então, importar esses módulos diretamente.
Por exemplo, considere o arquivo Hello.py que contém uma função simples "Olá, Mundo".
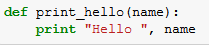
Em seguida, criamos um arquivo Hello.zip que contenha o Hello.py:

Carregue o arquivo zip como um conjunto de dados no Estúdio (clássico). Em seguida, crie e execute um experimento que usa o código Python no arquivo Hello.zip anexando-o à terceira porta de entrada do módulo Executar Script Python, como mostrado na imagem a seguir.
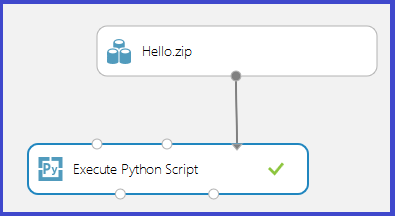
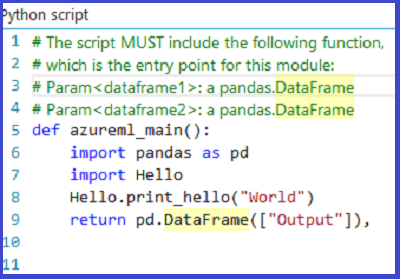
A saída do módulo mostra que o arquivo zip foi descompactado e a função print_hello foi executada.

Acessando Azure Storage Blobs
Você pode acessar os dados armazenados em uma conta de Armazenamento de Blobs do Azure seguindo estas etapas:
- Baixe o pacote de Armazenamento de Blobs do Azure para Python localmente.
- Carregue o arquivo zip no seu espaço de trabalho do Estúdio (clássico) como um conjunto de dados.
- Use
protocol='http'para criar o objeto BlobService.
from azure.storage.blob import BlockBlobService
# Create the BlockBlockService that is used to call the Blob service for the storage account
block_blob_service = BlockBlobService(account_name='account_name', account_key='account_key', protocol='http')
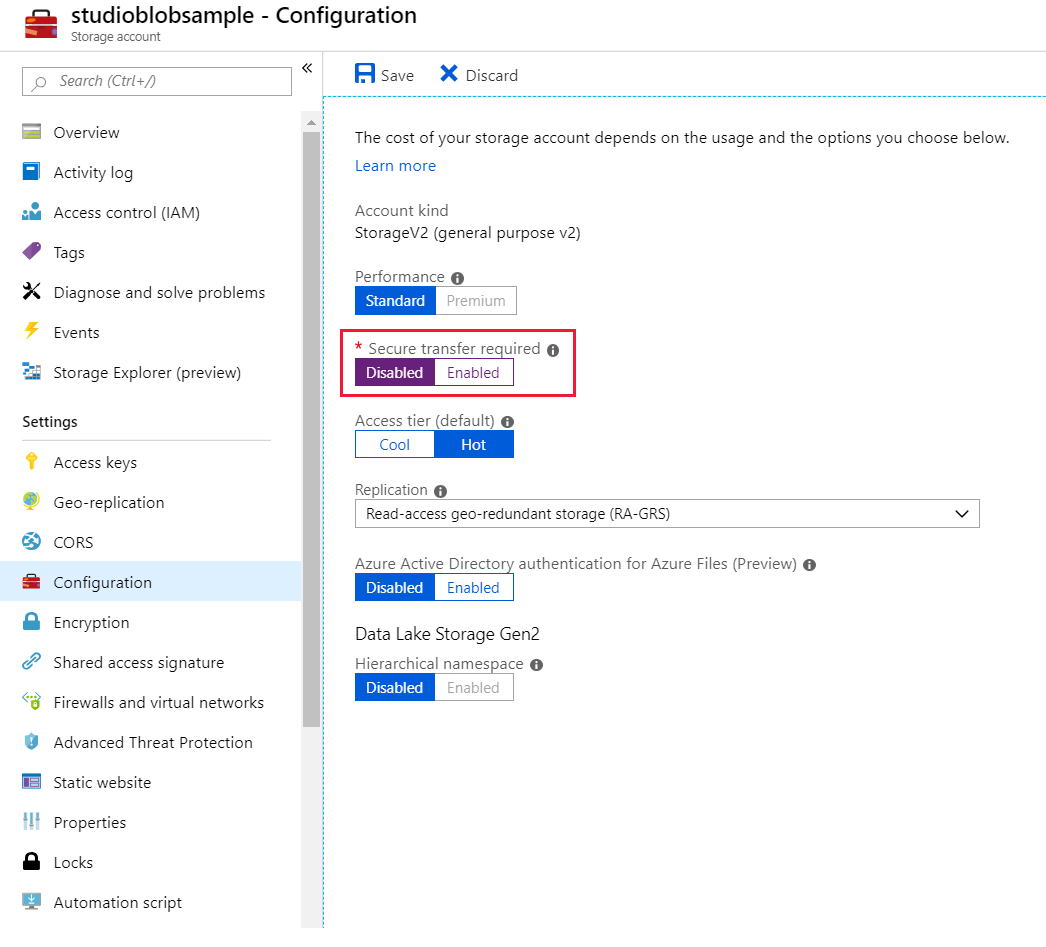
- Na guia Configuração do seu armazenamento, desabilite Transferência segura necessária.
Operacionalizando scripts Python
Quaisquer módulos Executar Script Python usados em um teste de pontuação são chamados quando publicados como um serviço Web. Por exemplo, a imagem abaixo mostra um teste de pontuação que contém o código para avaliar uma única expressão Python.
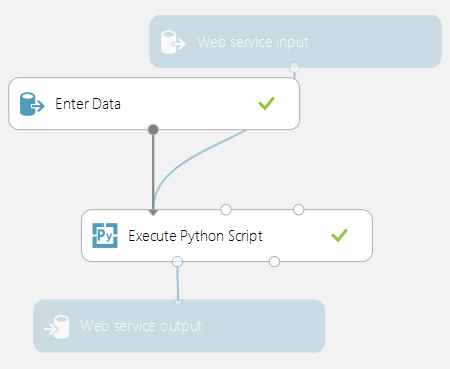
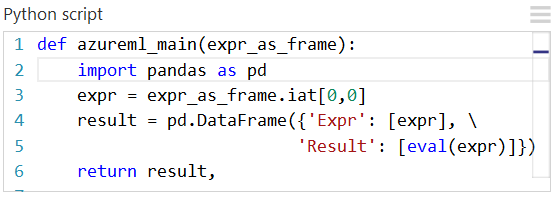
Um serviço Web criado com base nesse experimento executará as seguintes ações:
- Usar uma expressão Python como entrada (como uma cadeia de caracteres)
- Enviar a expressão Python ao interpretador de Python
- Retornar uma tabela contendo tanto a expressão como o resultado avaliado
Trabalhando com visualizações
Os gráficos criados por meio do MatplotLib podem ser retornados pelo módulo Executar Script Python. No entanto, eles não são redirecionados automaticamente para imagens como acontece quando usamos o R, por isso o usuário deve salvar explicitamente os gráficos em arquivos PNG.
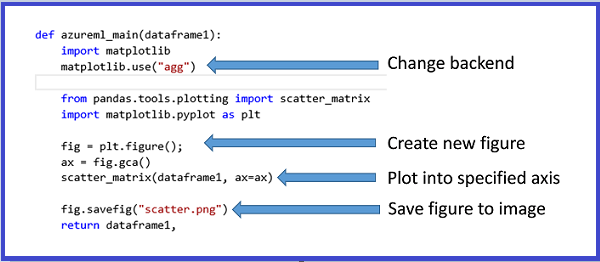
Para gerar imagens com base no MatplotLib, siga estas etapas:
- Alterne o back-end do renderizador padrão baseado em Qt para "AGG".
- Crie um novo objeto de figura.
- Obtenha o eixo e gere todos os gráficos nele.
- Salve a figura em um arquivo PNG.
Esse processo é ilustrado nas imagens a seguir, que criam uma matriz de gráfico de dispersão usando a função scatter_matrix no Pandas.
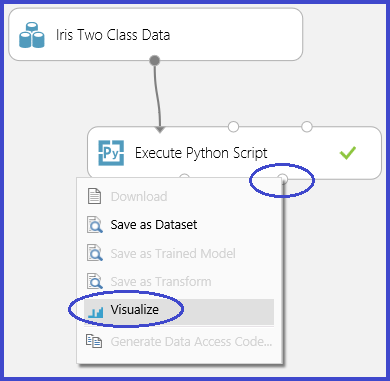
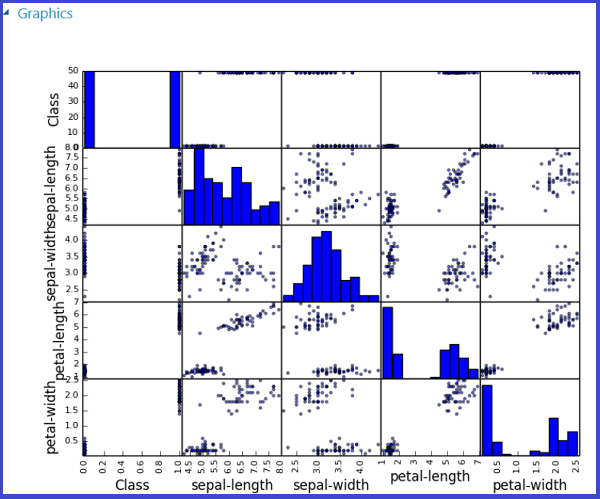
É possível retornar várias figuras salvando-as em imagens diferentes. O runtime do Estúdio (clássico) agrupa todas as imagens e as concatena para visualização.
Exemplos avançados
O ambiente Anaconda instalado no Estúdio (clássico) contém pacotes comuns, como NumPy, SciPy e Scikits-Learn. Esses pacotes podem ser usados de maneira eficaz para processamento de dados em um pipeline de machine learning.
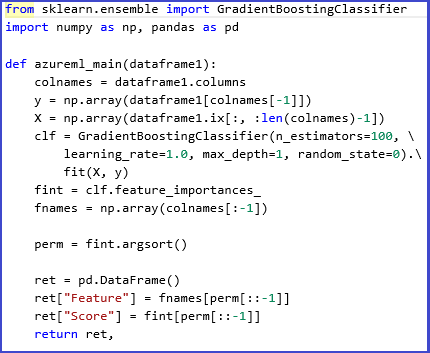
Por exemplo, o experimento e o script a seguir ilustram o uso de aprendizagem em conjunto no Scikits-Learn para calcular pontuações de importância de recursos para um conjunto de dados. As pontuações podem ser usadas para executar seleção de recursos supervisionados antes de serem alimentadas em outro modelo.
Aqui está a função Python usada para calcular as pontuações de importância e ordenar os recursos com base nas pontuações:
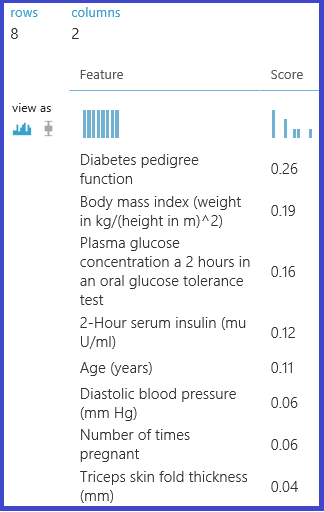
O seguinte experimento calcula e retorna as pontuações de importância dos recursos do conjunto de dados "Pima Indian Diabetes" no Machine Learning Studio (clássico):
Limitações
O módulo Executar Script Python atualmente tem as seguintes limitações:
Execução em área restrita
O runtime do Python está em área restrita no momento e não permite o acesso à rede ou ao sistema de arquivos local de maneira persistente. Todos os arquivos salvos localmente são isolados e excluídos após a conclusão do módulo. O código Python não pode acessar a maioria das pastas do computador em que é executado, com exceção do diretório atual e seus subdiretórios.
Falta de suporte para desenvolvimento e depuração sofisticados
O módulo Python atualmente não dá suporte a recursos de IDE, como IntelliSense e depuração. Além disso, se o módulo falhar em runtime, o rastreamento de pilha do Python completo estará disponível. Porém, ele deve ser exibido no log de saída para o módulo. No momento, recomendamos que você desenvolva e depure scripts Python em um ambiente como IPython e depois importe o código para o módulo.
Saída única de estruturas de dados
O ponto de entrada do Python para retornar somente uma estrutura de dados como saída. No momento, não é possível retornar objetos Python arbitrários, como modelos treinados diretamente para o runtime do Estúdio (clássico). Assim como o módulo Executar Script R, que tem a mesma limitação, é possível em muitos casos serializar objetos em uma matriz de bytes e retorná-la dentro de um quadro de dados.
Incapacidade de personalizar a instalação do Python
Atualmente, a única maneira de adicionar módulos personalizados do Python é por meio do mecanismo de compactação de arquivo zip descrito anteriormente. Embora isso seja viável para pequenos módulos, é complicado para módulos grandes (especialmente aqueles com DLLs nativas) ou um grande número de módulos.
Próximas etapas
Para saber mais, confira o Centro de Desenvolvedores do Python.