Usando o Apache Kafka® no HDInsight com o Apache Flink® no HDInsight no AKS
Importante
O Azure HDInsight no AKS se aposentou em 31 de janeiro de 2025. Saiba mais com este comunicado.
Você precisa migrar suas cargas de trabalho para microsoft fabric ou um produto equivalente do Azure para evitar o encerramento abrupto de suas cargas de trabalho.
Importante
Esse recurso está atualmente em versão prévia. Os termos de uso complementares para o Microsoft Azure Previews incluem mais termos legais que se aplicam aos recursos do Azure que estão em versão beta, em versão prévia ou ainda não lançados em disponibilidade geral. Para obter informações sobre essa versão prévia específica, consulte Azure HDInsight em informações de visualização do AKS. Para perguntas ou sugestões de funcionalidades, envie uma solicitação em AskHDInsight com os detalhes e siga-nos para mais atualizações sobre a Comunidade Azure HDInsight .
Um caso de uso bem conhecido para o Apache Flink é a análise de fluxo. A escolha popular de muitos usuários para usar os fluxos de dados, que são ingeridos usando o Apache Kafka. As instalações típicas do Flink e do Kafka começam com fluxos de eventos sendo enviados para o Kafka, que podem ser consumidos por trabalhos do Flink.
Este exemplo usa o HDInsight em clusters AKS que executam o Flink 1.17.0 para processar o consumo de dados de streaming e a produção do tópico Kafka.
Nota
FlinkKafkaConsumer foi descontinuado e será removido com Flink 1.17, use KafkaSource em vez disso. FlinkKafkaProducer foi descontinuado e será removido com Flink 1.15, use KafkaSink em vez disso.
Pré-requisitos
O Kafka e o Flink precisam estar na mesma VNet ou deve haver emparelhamento de vnet entre os dois clusters.
Criar um cluster Kafka na mesma VNet. Você pode escolher o Kafka 3.2 ou 2.4 no HDInsight com base no uso atual.
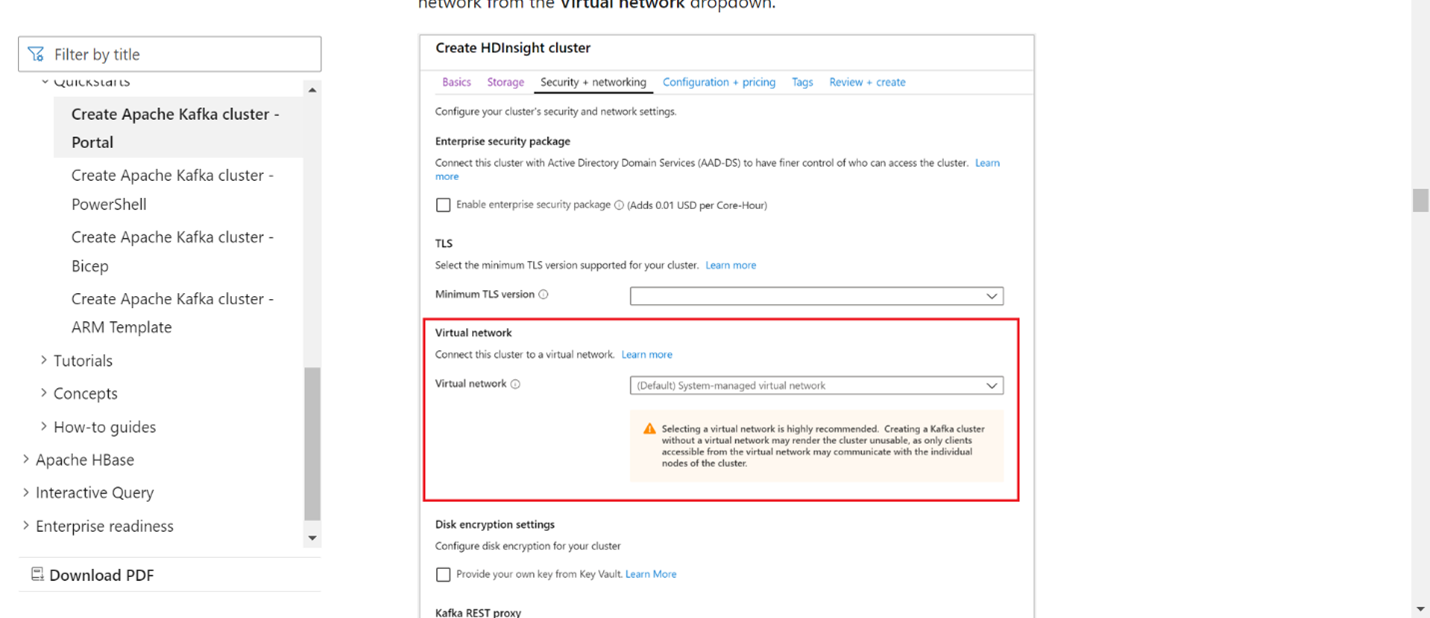
Adicione os detalhes da VNet na seção de rede virtual.
Crie um HDInsight no pool de clusters AKS na mesma rede virtual (VNet).
Crie um cluster Flink para o pool de clusters criado.

Conector do Apache Kafka
O Flink fornece um conector do Apache Kafka para a leitura e gravação de dados em tópicos do Kafka com garantias de processamento exatamente uma vez.
dependência Maven
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.0</version>
</dependency>
Construindo coletor Kafka
O sink do Kafka fornece uma classe builder para construir uma instância de um KafkaSink. Usamos o mesmo para construir nosso Sumidouro e usá-lo junto com o cluster Flink em execução no HDInsight hospedado no AKS.
SinKafkaToKafka.java
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SinKafkaToKafka {
public static void main(String[] args) throws Exception {
// 1. get stream execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. read kafka message as stream input, update your broker IPs below
String brokers = "X.X.X.X:9092,X.X.X.X:9092,X.X.X.X:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("clicks")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3. transformation:
// https://www.taobao.com,1000 --->
// Event{user: "Tim",url: "https://www.taobao.com",timestamp: 1970-01-01 00:00:01.0}
SingleOutputStreamOperator<String> result = stream.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim())).toString();
}
});
// 4. sink click into another kafka events topic
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(brokers)
.setProperty("transaction.timeout.ms","900000")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("events")
.setValueSerializationSchema(new SimpleStringSchema())
.build())
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.build();
result.sinkTo(sink);
// 5. execute the stream
env.execute("kafka Sink to other topic");
}
}
escrever um programa Java Event.java
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user,String url,Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString(){
return "Event{" +
"user: \"" + user + "\"" +
",url: \"" + url + "\"" +
",timestamp: " + new Timestamp(timestamp) +
"}";
}
}
Empacotar o jar e enviar o trabalho para Flink
No Webssh, carregue o jar e envie o jar

Na interface do usuário do painel do Flink

Produzir o tópico – interações com o Kafka

Consumir o tópico – eventos no Kafka

Referência
- Conector do Apache Kafka
- Apache, Apache Kafka, Kafka, Apache Flink, Flink e nomes de projetos de software livre associados são marcas comerciais da Apache Software Foundation (ASF).