Gerenciamento de Configuração do Apache Flink® no HDInsight no AKS
Importante
O Azure HDInsight no AKS se aposentou em 31 de janeiro de 2025. Saiba mais com este comunicado.
Você precisa migrar suas cargas de trabalho para microsoft fabric ou um produto equivalente do Azure para evitar o encerramento abrupto de suas cargas de trabalho.
Importante
Esse recurso está atualmente em versão prévia. Os termos de uso complementares para o Microsoft Azure Previews incluem mais termos legais que se aplicam aos recursos do Azure que estão em versão beta, em versão prévia ou ainda não lançados em disponibilidade geral. Para obter informações sobre essa versão prévia específica, consulte Azure HDInsight em informações de visualização do AKS. Para perguntas ou sugestões de funcionalidades, envie uma solicitação em AskHDInsight com os detalhes e siga-nos para mais atualizações na Comunidade do Azure HDInsight .
O HDInsight no AKS fornece um conjunto de configurações padrão do Apache Flink para a maioria das propriedades e algumas com base em perfis de aplicativo comuns. No entanto, caso seja necessário ajustar as propriedades de configuração do Flink para melhorar o desempenho de determinados aplicativos com uso de estado, paralelismo ou configurações de memória, você pode alterar a configuração do trabalho Flink usando a Seção Trabalhos Flink no HDInsight no cluster do AKS.
Vá para Configurações > Tarefas do Flink > Clique em Atualizar.
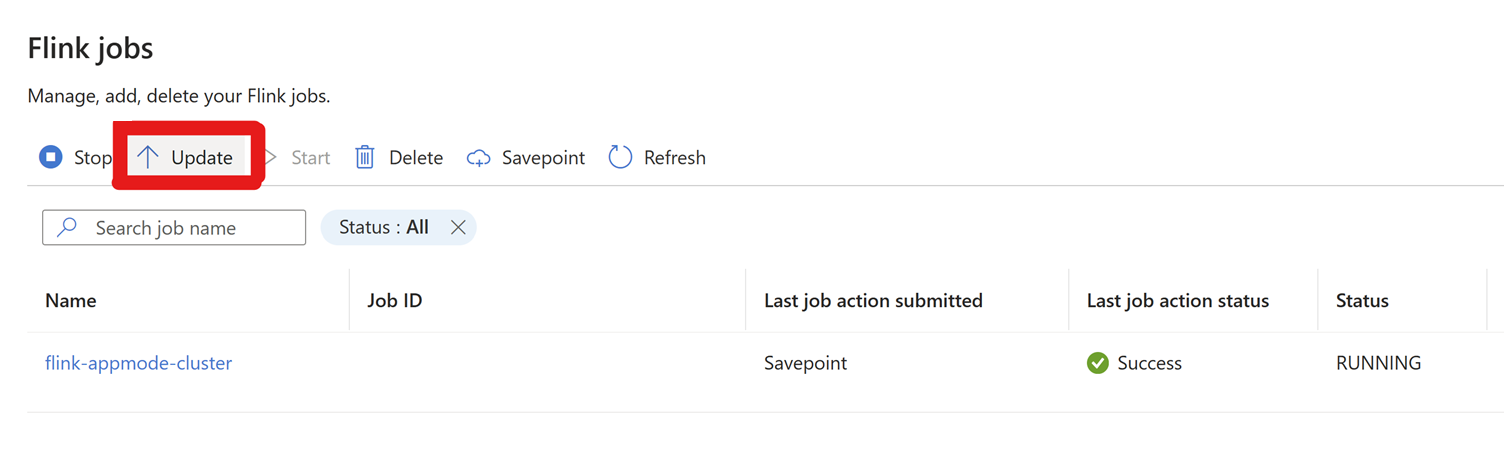
Clique em + Adicionar uma linha para editar a configuração.
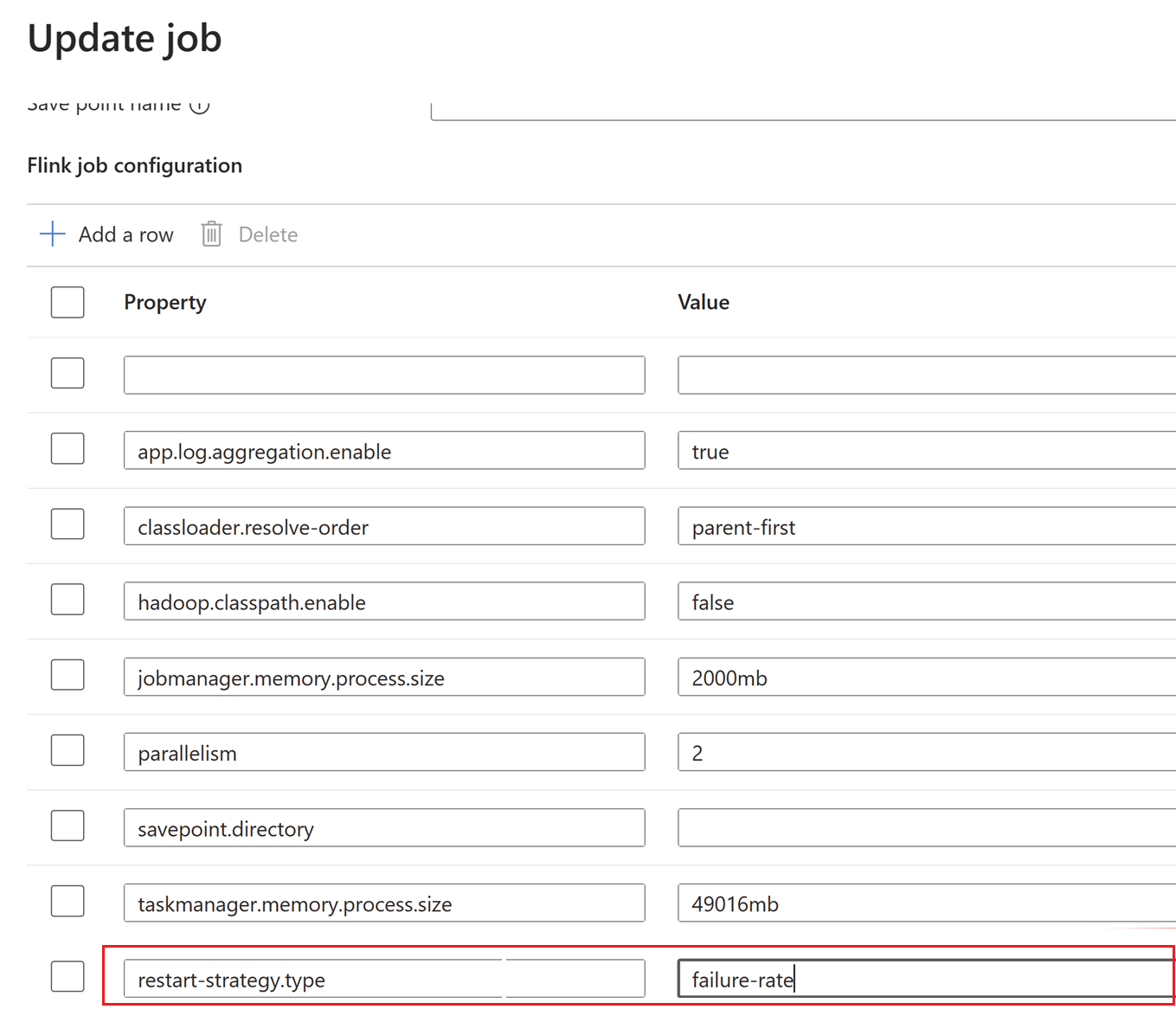
Aqui, o intervalo de ponto de verificação é alterado no nível do cluster.
Atualize as alterações clicando OK e, em seguida, Salvar.
Depois de salvas, as novas configurações são atualizadas em alguns minutos (aproximadamente 5 minutos).
Configurações, que podem ser atualizadas usando as Configurações do Gerenciamento de Configuração.
processMemory size:As configurações padrão do tamanho da memória do processo ou do gerenciador de tarefas e do gerenciador de tarefas seriam a memória configurada pelo usuário durante a criação do cluster.
Esse tamanho pode ser configurado usando a propriedade de configuração abaixo. Para alterar a memória do processo do gerenciador de tarefas, use essa configuração.
taskmanager.memory.process.size : <value>Exemplo:
taskmanager.memory.process.size : 2000mbPara gerente de trabalho
jobmanager.memory.process.size : <value>Nota
A memória máxima do processo configurável é igual à memória configurada para
jobmanager/taskmanager.


Intervalo de ponto de verificação
O intervalo de ponto de verificação determina a frequência com que o Flink dispara um ponto de verificação. Definido em milissegundos e pode ser definido usando a propriedade de configuração a seguir
execution.checkpoint.interval: <value>
A configuração padrão é 60.000 milissegundos (1 min), esse valor pode ser alterado conforme desejado.
Camada de Estado
O mecanismo de gerenciamento de estado determina como o Flink gerencia e persiste o estado da sua aplicação. Isso afeta a forma como os pontos de verificação são armazenados. Você pode configurar o `backend de estado` usando a seguinte propriedade:
state.backend: <value>
Por padrão, os clusters do Apache Flink no HDInsight no AKS usam o Rocks DB.
Caminho de armazenamento do ponto de verificação
Permitimos pontos de verificação persistentes por padrão armazenando os pontos de verificação no armazenamento abfs conforme configurado pelo usuário. Mesmo que o trabalho falhe, uma vez que os pontos de verificação são persistentes, ele pode ser facilmente iniciado com o ponto de verificação mais recente.
state.checkpoints.dir: <path> Substitua <path> pelo caminho desejado em que os pontos de verificação estão armazenados.
Por padrão, armazenado na conta de armazenamento (ABFS), configurada pelo usuário. Esse valor pode ser alterado para qualquer caminho desejado, desde que os pods Flink possam acessá-lo.
Máximo de pontos de verificação simultâneos
Você pode limitar o número máximo de pontos de verificação simultâneos definindo a seguinte propriedade: checkpoint.max-concurrent-checkpoints: <value>
Substitua <value> pelo número máximo desejado de pontos de verificação simultâneos. Por exemplo, 1 para permitir apenas um ponto de verificação por vez.
Máximo de pontos de verificação retidos
Você pode limitar o número máximo de pontos de verificação a serem mantidos definindo a seguinte propriedade:
state.checkpoints.num-retained: <value> Substituir <value> pelo número máximo desejado. Por padrão, retivemos no máximo cinco pontos de verificação.
Caminho de Armazenamento do Savepoint
Permitimos pontos de salvamento persistentes por padrão armazenando os pontos de salvamento no armazenamento abfs (conforme configurado pelo usuário). Se o usuário quiser parar e, posteriormente, iniciar o trabalho com um ponto de salvamento específico, ele poderá configurar esse local.
state.checkpoints.dir: <path> Substitua <path> pelo caminho desejado em que os pontos de salvamento estão armazenados.
Por padrão, armazenado na conta de armazenamento, configurado pelo usuário. (Damos suporte à ABFS). Esse valor pode ser alterado para qualquer caminho desejado, desde que os pods Flink possam acessá-lo.
Alta disponibilidade do Gerenciador de Tarefas
No HDInsight em AKS, o Flink usa o Kubernetes como infraestrutura. Mesmo que o Gerenciador de Trabalho falhe no meio devido a qualquer problema conhecido/desconhecido, o pod será reiniciado em alguns segundos. Portanto, mesmo que o trabalho seja reiniciado devido a esse problema, o trabalho será recuperado do ponto de verificação mais recente.
Perguntas Freqüentes
Por que a tarefa falha no meio? Mesmo que os trabalhos falhem abruptamente, se os pontos de verificação estiverem acontecendo continuamente, o trabalho será reiniciado automaticamente do ponto de verificação mais recente.
Alterar a estratégia de trabalho no meio? Há casos de uso, em que o trabalho precisa ser modificado durante a produção devido a algum bug no nível do trabalho. Durante esse tempo, o usuário pode interromper o trabalho, o que automaticamente pegaria um ponto de salvamento e o salvaria no local do ponto de salvamento.
Clique em
savepointe aguarde a conclusão dosavepoint.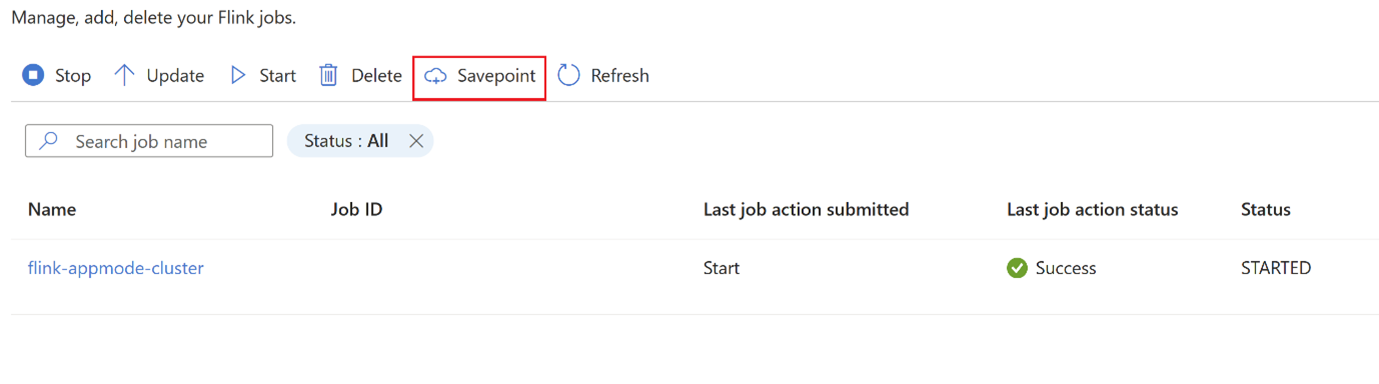
Após a conclusão do ponto de salvamento, clique em iniciar e a guia Iniciar Trabalho será exibida. Selecione o nome do ponto de salvamento na lista suspensa. Edite as configurações, se necessário. E clique em OK.
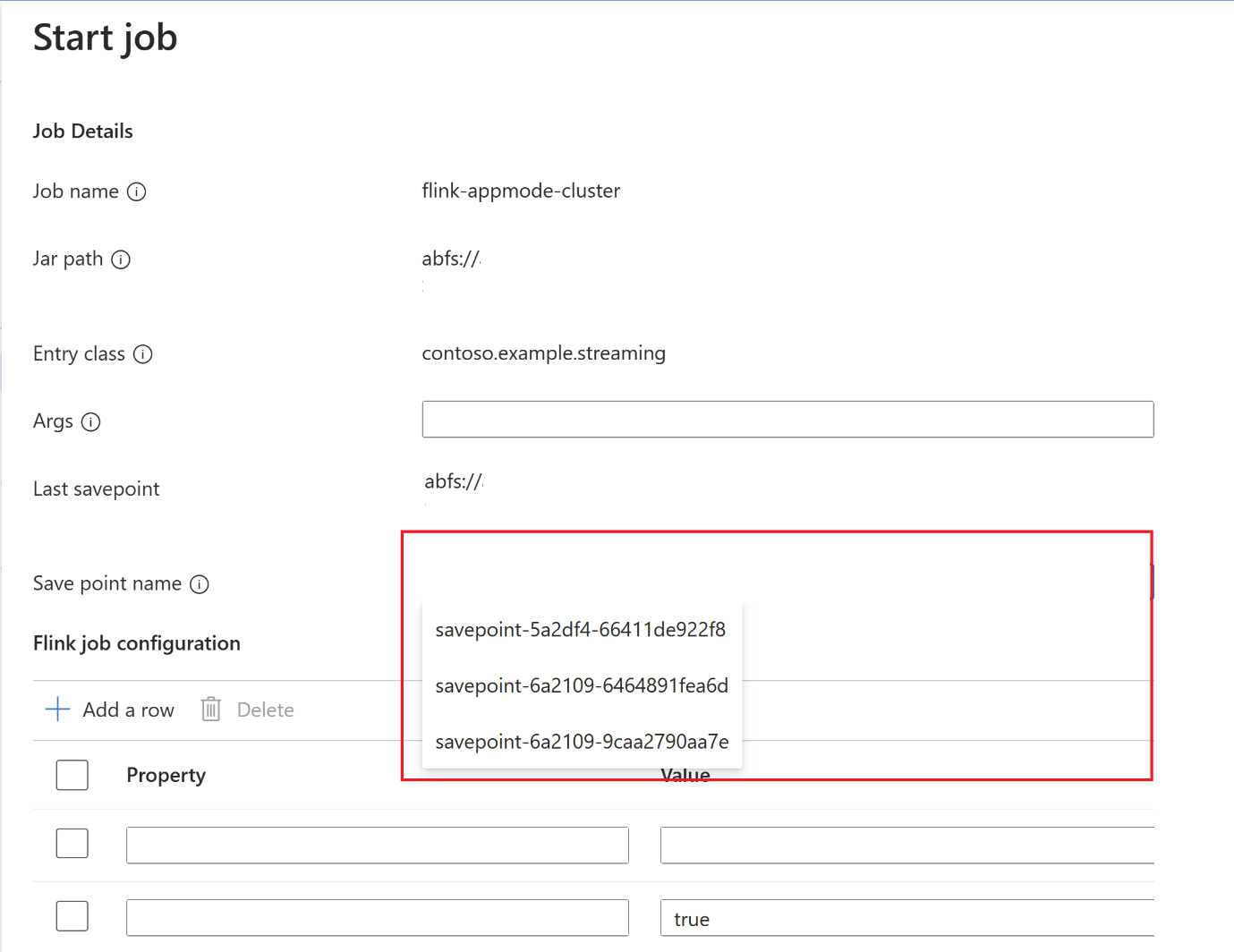


Como o savepoint é fornecido no trabalho, o Flink sabe de onde começar a processar os dados.
Referência
- configurações do Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink e nomes de projeto de software livre associados são marcas comerciais do ASF (Apache Software Foundation).