Resolver problemas de distorção de dados no Data Lake Analytics do Azure usando Ferramentas do Azure Data Lake para Visual Studio
Importante
O Azure Data Lake Analytics desativado em 29 de fevereiro de 2024. Saiba mais nesse comunicado.
Para análise de dados, sua organização pode usar o Azure Synapse Analytics ou o Microsoft Fabric.
O que é distorção de dados?
Resumidamente, distorção de dados é a super-representação de um valor. Imagine que você atribuiu 50 examinadores fiscais para auditar as declarações fiscais, um examinador para cada estado dos EUA. O examinador de Wyoming, porque a população lá é pequena, tem pouco a fazer. Na Califórnia, no entanto, o fiscal permanece ocupado devido à grande população do estado.

Em nosso cenário, os dados são distribuídos de modo desigual entre todos os fiscais de impostos, o que significa que alguns fiscais devem trabalhar mais do que outros. Em seu próprio trabalho, com frequência você enfrentar situações como o exemplo do fiscal de impostos fornecido aqui. Em termos mais técnicos, um vértice obtém muito mais dados do que seus colegas, uma situação que faz com que o vértice funcione mais do que os outros e isso eventualmente torna todo um trabalho mais lento. O que é pior, o trabalho pode falhar, pois vértices podem ter, por exemplo, uma limitação de 5 horas de runtime e uma limitação de 6 GB de memória.
Resolvendo problemas de distorções de dados
Ferramentas do Azure Data Lake para Visual Studio e Visual Studio Code podem ajudar a detectar se seu trabalho tem um problema de distorção de dados.
- Instale as Ferramentas do Azure Data Lake para Visual Studio
- Instalar Ferramentas do Azure Data Lake para Visual Studio Code
Se algum problema existir, você poderá resolvê-lo experimentando as soluções nesta seção.
Solução 1: melhorar o particionamento da tabela
Opção 1: Filtrar o valor chave distorcido com antecedência
Se isso não afetar sua lógica de negócios, você poderá filtrar os valores de frequência mais alta com antecedência. Por exemplo, se houver muitos 000-000-000 no GUID de coluna, talvez você não queira agregar esse valor. Antes de você agregar, você pode escrever “WHERE GUID != “000-000-000”” para filtrar o valor de alta frequência.
Opção 2: separar uma chave de partição ou distribuição diferente
No exemplo anterior, se você desejar apenas verificar a carga de trabalho de auditoria de imposto em todo o país/região, você poderá melhorar a distribuição de dados selecionando o número de ID como sua chave. Às vezes, separar uma chave de partição/distribuição diferente pode distribuir os dados mais uniformemente, mas você precisa certificar-se de que essa escolha não afeta sua lógica de negócios. Por exemplo, para calcular a soma de imposto para cada estado, talvez você queira designar Estado como a chave de partição. Se você continuar a ter esse problema, tente usar a Opção 3.
Opção 3: adicionar mais chaves de partição ou distribuição
Em vez de usar apenas Estado como uma chave de partição, você pode usar mais de uma chave para o particionamento. Por exemplo, considere adicionar o CEP como outra chave de partição para reduzir os tamanhos de partição de dados e distribuir os dados de forma mais uniforme.
Opção 4: usar a distribuição round robin
Se você não conseguir encontrar uma chave apropriada para partição e distribuição, tente usar a distribuição round robin. A distribuição round robin trata cada linha igualmente e as coloca aleatoriamente nos buckets correspondentes. Os dados são distribuídos uniformemente mas perdem as informações de localidade, um inconveniente que também pode reduzir o desempenho do trabalho para algumas operações. Além disso, se você estiver fazendo agregação para a chave distorcida de qualquer maneira, o problema de distorção de dados persistirá. Para saber mais sobre a distribuição round robin, consulte a seção Distribuições de Tabela U-SQL em CREATE TABLE (U-SQL): Criando uma tabela com esquema.
Solução 2: melhorar o plano de consulta
Opção 1: usar a instrução CREATE STATISTICS
O U-SQL fornece a instrução CREATE STATISTICS em tabelas. Essa instrução fornece mais informações ao otimizador de consulta sobre as características de dados (por exemplo, distribuição de valor) armazenadas em uma tabela. Para a maioria das consultas, o otimizador de consulta já gera as estatísticas necessárias para um plano de consulta de alta qualidade. Ocasionalmente, talvez seja necessário melhorar o desempenho da consulta criando mais estatísticas com CREATE STATISTICS ou modificando o design da consulta. Para obter mais informações, consulte a página CREATE STATISTICS (U-SQL).
Exemplo de código:
CREATE STATISTICS IF NOT EXISTS stats_SampleTable_date ON SampleDB.dbo.SampleTable(date) WITH FULLSCAN;
Observação
Informações de estatísticas não são atualizadas automaticamente. Se você atualizar os dados em uma tabela sem recriar as estatísticas, o desempenho da consulta poderá cair.
Opção 2: Usar SKEWFACTOR
Se você deseja somar o imposto de cada estado, você deve usar GROUP BY estado, uma abordagem que não evita o problema de distorção de dados. No entanto, você pode fornecer uma dica de dados em sua consulta para identificar a distorção de dados nas chaves, de forma que o otimizador consiga preparar um plano de execução para você.
Normalmente, você pode definir o parâmetro como 0,5 e 1, com 0,5 o que significa não muita distorção e uma significando distorção pesada. Já que a dica afeta a otimização do plano de execução da instrução atual e todas as instruções subsequentes, certifique-se de adicionar a dica antes de uma agregação com possível distorção relacionada à chave.
SKEWFACTOR (columns) = x
Fornece uma dica de que as colunas fornecidas têm um fator de distorção x de 0 (sem distorção) a 1 (distorção pesada).
Exemplo de código:
//Add a SKEWFACTOR hint.
@Impressions =
SELECT * FROM
searchDM.SML.PageView(@start, @end) AS PageView
OPTION(SKEWFACTOR(Query)=0.5)
;
//Query 1 for key: Query, ClientId
@Sessions =
SELECT
ClientId,
Query,
SUM(PageClicks) AS Clicks
FROM
@Impressions
GROUP BY
Query, ClientId
;
//Query 2 for Key: Query
@Display =
SELECT * FROM @Sessions
INNER JOIN @Campaigns
ON @Sessions.Query == @Campaigns.Query
;
Opção 3: usar ROWCOUNT
Além de SKEWFACTOR, para casos específicos de junção de chaves com distorção, se você souber que o outro conjunto de linhas unido é pequeno, você poderá informar o otimizador adicionando uma dica ROWCOUNT na instrução U-SQL antes de JOIN. Dessa forma, o otimizador pode escolher uma estratégia de junção de difusão para ajudar a melhorar o desempenho. Lembre-se de que ROWCOUNT não resolve o problema de distorção de dados, mas pode oferecer ajuda extra.
OPTION(ROWCOUNT = n)
Identifique um pequeno conjunto de linhas antes do JOIN, fornecendo uma contagem estimada de linhas de números inteiros.
Exemplo de código:
//Unstructured (24-hour daily log impressions)
@Huge = EXTRACT ClientId int, ...
FROM @"wasb://ads@wcentralus/2015/10/30/{*}.nif"
;
//Small subset (that is, ForgetMe opt out)
@Small = SELECT * FROM @Huge
WHERE Bing.ForgetMe(x,y,z)
OPTION(ROWCOUNT=500)
;
//Result (not enough information to determine simple broadcast JOIN)
@Remove = SELECT * FROM Bing.Sessions
INNER JOIN @Small ON Sessions.Client == @Small.Client
;
Solução 3: Melhorar o combinador e o redutor definidos pelo usuário
Às vezes você pode gravar um operador definido pelo usuário para lidar com uma lógica de processo complicada e um redutor e um combinador bem escritos podem mitigar um problema de distorção de dados em alguns casos.
Opção 1: usar um redutor recursivo, se possível
Por padrão, um redutor definido pelo usuário é executado no modo não recursivo, o que significa que reduzir o trabalho de uma chave é distribuído em um único vértice. Mas se os dados estiverem distorcidos, os grandes conjuntos de dados poderão ser processados em um único vértice e serem executados por um longo tempo.
Para melhorar o desempenho, você pode adicionar um atributo em seu código para definir a execução do redutor no modo recursivo. Desse modo, grandes conjuntos de dados podem ser distribuídos por vários vértices e executados em paralelo, o que acelera o seu trabalho.
Para alterar um redutor não recursivo para recursivo, você precisa verificar se o algoritmo é associativo. Por exemplo, a soma é associativa e a mediana não é. Além disso, você precisa garantir que a entrada e a saída do redutor mantenham o mesmo esquema.
Atributo do redutor recursivo:
[SqlUserDefinedReducer(IsRecursive = true)]
Exemplo de código:
[SqlUserDefinedReducer(IsRecursive = true)]
public class TopNReducer : IReducer
{
public override IEnumerable<IRow>
Reduce(IRowset input, IUpdatableRow output)
{
//Your reducer code goes here.
}
}
Opção 2: usar o modo combinador no nível de linha, se possível
Semelhante à dica ROWCOUNT para casos específicos de junção de chave distorcida, o modo combinador tenta distribuir grandes conjuntos de valores de chave distorcida em vários vértices, de forma que o trabalho possa ser executado simultaneamente. O modo combinador não pode resolve problemas de distorção de dados, mas pode oferecer ajuda extra para grandes conjuntos de valores de teclas distorcidas.
Por padrão, o modo combinador é Completo, o que significa que o conjunto de linhas esquerdo e o conjunto de linhas à direita não podem ser separados. Configurar o modo como Left/Right/Inner permite junção em nível de linha. O sistema separa os conjuntos de linhas correspondentes e os distribui em vários vértices que executam em paralelo. No entanto, antes de configurar o modo combinador, tome cuidado para garantir que os conjuntos de linhas correspondentes possam ser separados.
O exemplo a seguir mostra um conjunto de linhas à esquerda separado. Cada linha de saída depende de uma única linha de entrada da esquerda e, potencialmente, depende de todas as linhas da direita com o mesmo valor de chave. Se você definir o modo combinador como esquerda, o sistema separará o enorme conjunto de linhas à esquerda em conjuntos menores e os atribuirá a vários vértices.
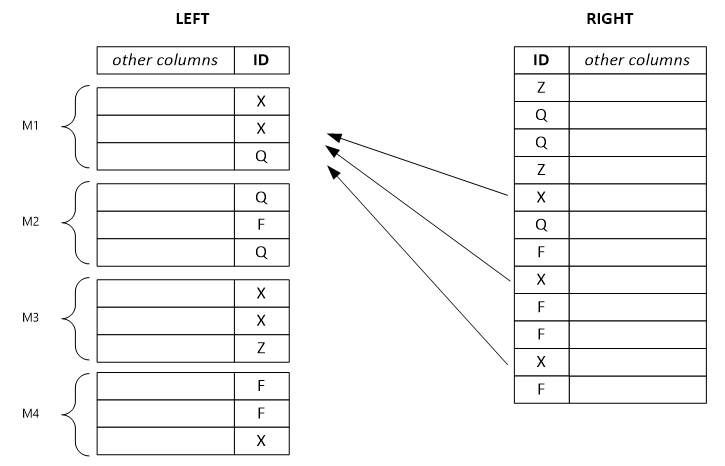
Observação
Se você definir o modo combinador errado, a combinação será menos eficiente e os resultados poderão ser incorretos.
Atributos do modo de combinador:
SqlUserDefinedCombiner(Mode=CombinerMode.Full): cada linha de saída depende potencialmente de todas as linhas de entrada da esquerda e direita com o mesmo valor de chave.
SqlUserDefinedCombiner(Mode=CombinerMode.Left): cada linha de saída depende de uma única linha de entrada da esquerda (e potencialmente de todas as linhas da direita com o mesmo valor de chave).
SqlUserDefinedCombiner(Mode=CombinerMode.Right): cada linha de saída depende de uma única linha de entrada da direita (e potencialmente de todas as linhas da esquerda com o mesmo valor de chave).
SqlUserDefinedCombiner(Mode=CombinerMode.Inner): cada linha de saída depende de uma única linha de entrada da direita e da esquerda com o mesmo valor.
Exemplo de código:
[SqlUserDefinedCombiner(Mode = CombinerMode.Right)]
public class WatsonDedupCombiner : ICombiner
{
public override IEnumerable<IRow>
Combine(IRowset left, IRowset right, IUpdatableRow output)
{
//Your combiner code goes here.
}
}