Reconhecimento das diferenças entre os tipos de fluxo de dados
Os fluxos de dados são usados para extrair, transformar e carregar dados em um destino de armazenamento em que eles podem ser usados em cenários diferentes. Como nem todos os destinos de armazenamento compartilham as mesmas características, alguns recursos e comportamentos de fluxo de dados diferem de acordo com o destino de armazenamento em que o fluxo de dados carrega os dados. Antes de criar um fluxo de dados, é importante entender como os dados serão usados e escolher o destino de armazenamento de acordo com os requisitos da solução.
Selecionar um destino de armazenamento de um fluxo de dados determina o tipo do fluxo de dados. Um fluxo de dados que carrega dados em tabelas do Dataverse é categorizado como um fluxo de dados padrão. Os fluxos de dados que carregam dados em tabelas analíticas são categorizados como um fluxo de dados analítico.
Os fluxos de dados criados no Power BI são sempre fluxos de dados analíticos. Os fluxos de dados criados no Power Apps podem ser padrão ou analíticos, dependendo da seleção ao criar o fluxo de dados.
Fluxos de dados padrão
Um fluxo de dados padrão carrega dados para tabelas do Dataverse. Os fluxos de dados padrão só podem ser criados no Power Apps. Um benefício da criação desse tipo de fluxo de dados é que qualquer aplicativo, que depende de dados no Dataverse, pode trabalhar com os dados criados por fluxos de dados padrão. Aplicativos típicos que usam tabelas do Dataverse são Power Apps, Power Automate, AI Builder e Power Virtual Agents.
Para criar um fluxo de dados no Power Apps:
Nas guias do Power Apps, selecione Mais.
Selecione Fluxos de dados.
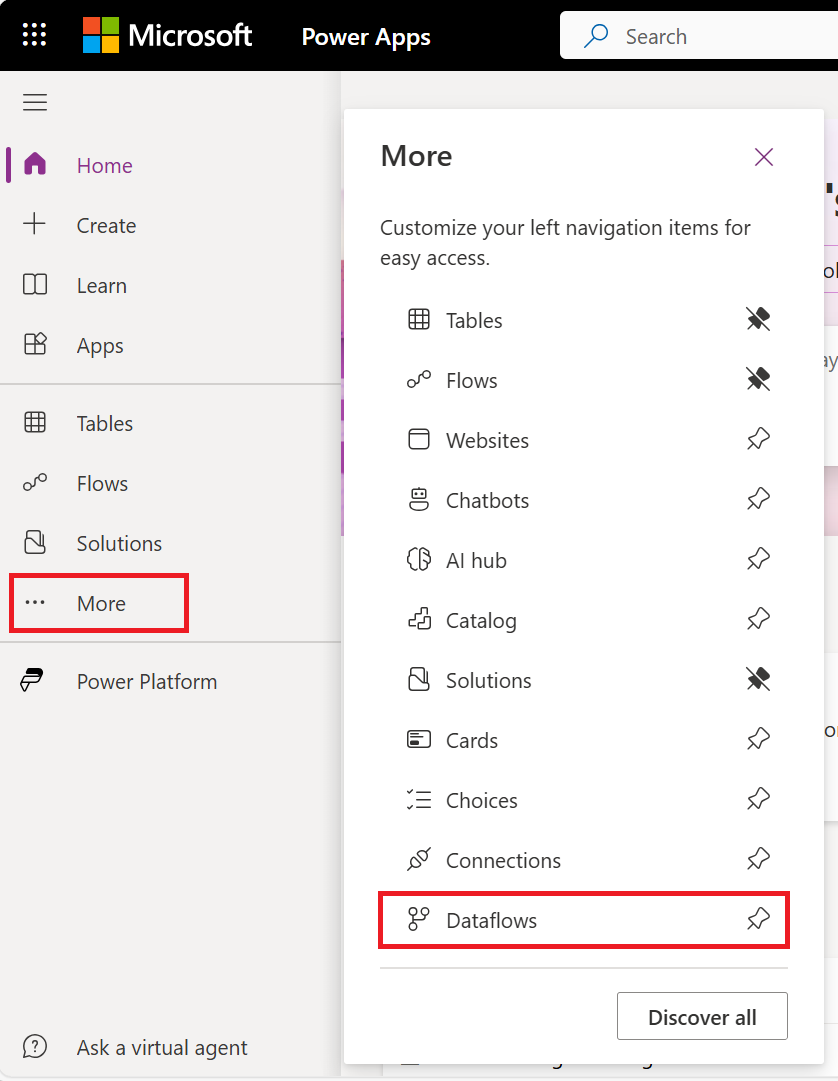
Selecione Novo fluxo de dados.
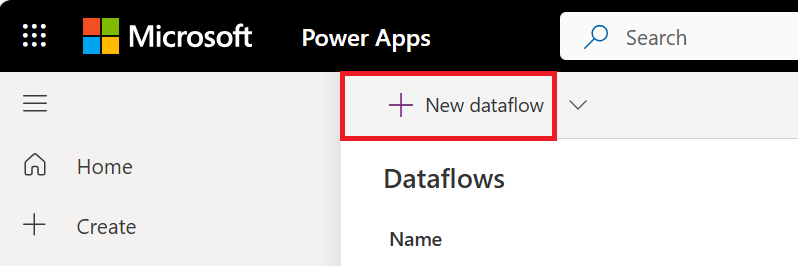
Se você estiver criando seu primeiro fluxo de dados, também poderá selecionar o botão Criar um fluxo de dados.
Versões de fluxos de dados padrão
Observação
Incentivamos os usuários de fluxo de dados do Power Platform a migrar de fluxos de dados padrão V1 para fluxos de dados padrão V2. Os fluxos de dados padrão V1 estão a caminho de serem descontinuados em um futuro próximo. Para obter mais informações sobre como migrar para fluxos de dados V2 padrão, acesse Migrar um fluxo de dados V1 padrão para um fluxo de dados V2 padrão.
Estamos trabalhando em atualizações significativas para fluxos de dados padrão para melhorar o desempenho e a confiabilidade. Essas melhorias eventualmente estarão disponíveis para todos os fluxos de dados padrão. Mas, nesse ínterim, diferenciamos entre fluxos de dados padrão existentes (versão 1) e fluxos de dados padrão novos (versão 2) adicionando um indicador de versão no Power Apps.

Comparação de recursos de versões de fluxo de dados padrão
A tabela a seguir lista as principais diferenças de recursos entre os fluxos de dados padrão V1 e V2. Também fornece informações sobre o comportamento de cada recurso em cada versão.
| Recurso | Padrão V1 | Padrão V2 |
|---|---|---|
| Número máximo de fluxos de dados que podem ser salvos com agendamento automático por locatário do cliente | 50 | Ilimitado |
| Número máximo de registros ingeridos por consulta/tabela | 500.000 | Não associado. O número máximo de registros que podem ser ingeridos por consulta ou tabela agora depende dos limites de proteção de serviço do Dataverse no momento da ingestão. |
| Velocidade de ingestão no Dataverse | Desempenho da linha de base | Desempenho aperfeiçoado por alguns fatores. Os resultados reais podem variar e depender das características dos dados ingeridos e carregar no serviço do Dataverse no momento da ingestão. |
| Política de atualização incremental | Sem suporte | Com suporte |
| Resiliência | Quando os limites de proteção de serviço do Dataverse forem encontrados, um registro é repetido até três vezes. | Quando os limites de proteção de serviço do Dataverse forem encontrados, um registro é repetido até três vezes. |
| Integração do Power Automate | Sem suporte | Com suporte |
Fluxos de dados analíticos
Um fluxo de dados analítico carrega dados para tipos de armazenamento otimizados para análise — Azure Data Lake Storage. Os ambientes do Microsoft Power Platform e os workspaces do Power BI fornecem aos clientes um local de armazenamento analítico gerenciado empacotado com essas licenças de produto. Além disso, os clientes podem vincular a conta de armazenamento do Azure Data Lake de sua organização como um destino para fluxos de dados.
Os fluxos de dados analíticos são capazes de recursos analíticos adicionais. Por exemplo, a integração com os recursos de IA do Power BI ou o uso de tabelas computadas que são discutidas posteriormente.
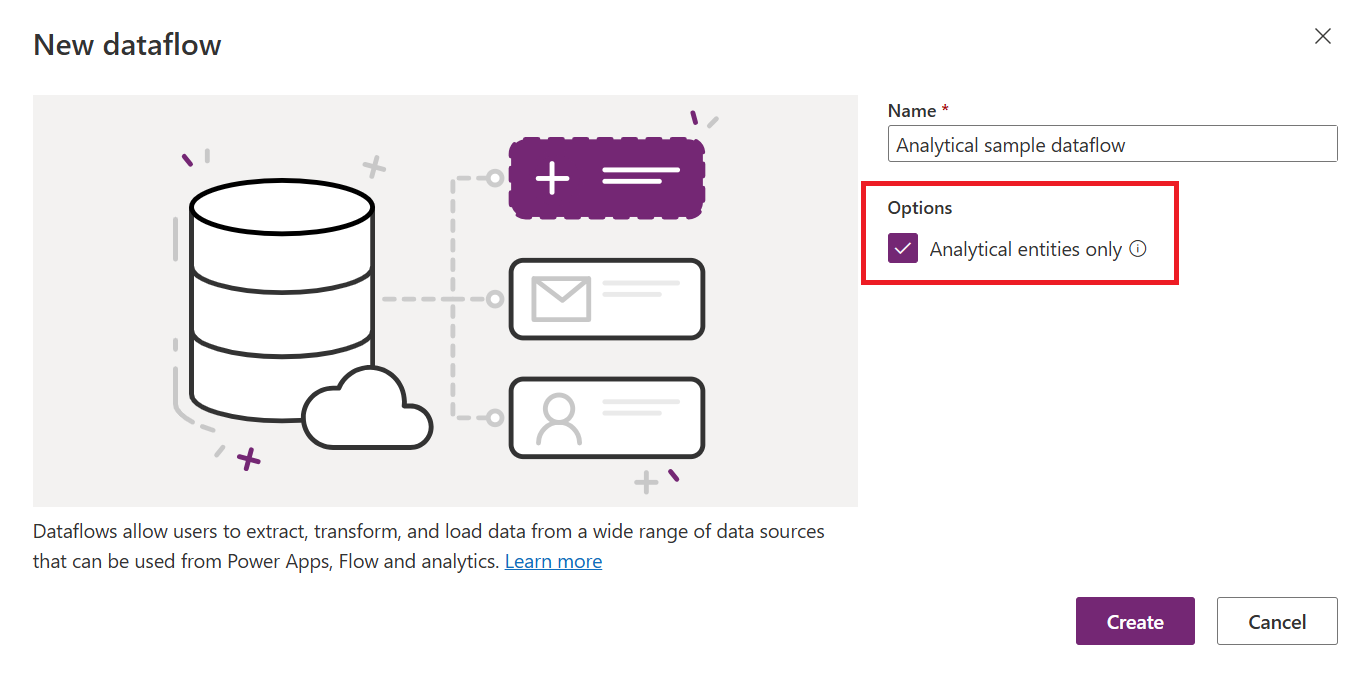
Você pode criar fluxos de dados analíticos no Power BI. Por padrão, eles carregam dados no armazenamento gerenciado do Power BI. Mas, você também pode configurar o Power BI para armazenar os dados no Azure Data Lake Storage da organização.
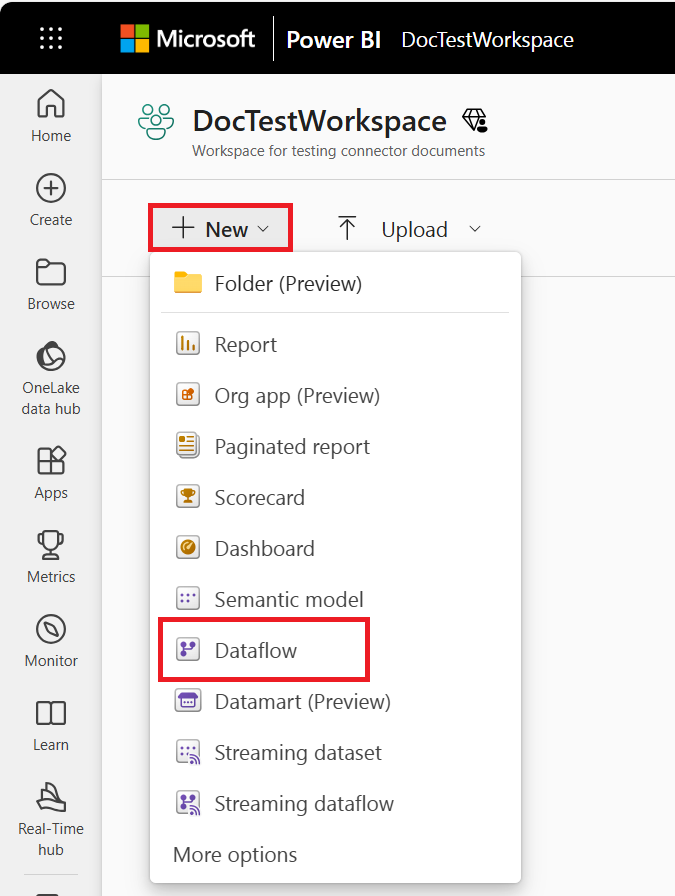
Você também pode criar fluxos de dados analíticos nos portais de insights de clientes do Power Apps e do Dynamics 365. Ao criar um fluxo de dados no portal do Power Apps, você pode escolher entre o armazenamento analítico gerenciado do Dataverse ou a conta do Azure Data Lake Storage da sua organização.
Integração de IA
Às vezes, dependendo do requisito, talvez seja necessário aplicar algumas funções de IA e machine learning nos dados por meio do fluxo de dados. Essas funcionalidades estão disponíveis em fluxos de dados do Power BI e exigem um workspace Premium.

Os seguintes artigos discutem como usar funções de IA em um fluxo de dados:
- Integração do Azure Machine Learning no Power BI
- Serviços Cognitivos no Power BI
- Machine learning automatizado no Power BI
Os recursos listados nas duas seções anteriores são específicos do Power BI e não estão disponíveis ao criar um fluxo de dados nos portais de insights de clientes do Power Apps ou do Dynamics 365.
Tabelas computadas
Uma das razões para usar uma tabela computada é a capacidade de processar grandes quantidades de dados. A tabela computada ajuda nesses cenários. Se você tiver uma tabela em um fluxo de dados e outra tabela no mesmo fluxo de dados usar a saída da primeira tabela, essa ação criará uma tabela computada.
A tabela computada ajuda no desempenho das transformações de dados. Em vez de refazer as transformações necessárias na primeira tabela várias vezes, a transformação é feita apenas uma vez na tabela computada. Em seguida, o resultado é usado várias vezes em outras tabelas.
Para saber mais sobre tabelas computadas, acesse Criar tabelas computadas em fluxos de dados.
As tabelas computadas estão disponíveis somente em um fluxo de dados analítico.
Comparação entre fluxos de dados padrão e analíticos
A tabela a seguir lista algumas diferenças entre uma tabela padrão e uma tabela analítica.
| Operação | Standard | Analítico |
|---|---|---|
| Como criar | Fluxo de dados do Power Platform | Fluxos de dados do Power BI Fluxos de dados do Power Platform marcando-se a caixa de seleção Somente entidades analíticas ao criar o fluxo de dados |
| Opções de armazenamento | Dataverse | O Power BI forneceu o armazenamento do Azure Data Lake para fluxos de dados do Power BI, o Dataverse forneceu o armazenamento do Azure Data Lake para fluxos de dados do Power Platform ou o cliente forneceu o armazenamento do Azure Data Lake |
| Transformações do Power Query | Sim | Sim |
| Funções de IA | Não | Sim |
| Tabela computada | Não | Sim |
| Pode ser usado em outros aplicativos | Sim, por meio do Dataverse | Fluxos de dados do Power BI: somente no Power BI Fluxos de dados do Power Platform ou fluxos de dados externos do Power BI: sim, por meio do Azure Data Lake Storage |
| Mapeamento para tabela padrão | Sim | Sim |
| Carga incremental | Carga incremental padrão É possível alterar usando a caixa de seleção Excluir linhas que não existem mais na saída da consulta nas configurações de carga |
Carregamento completo padrão É possível configurar a atualização incremental configurando a atualização incremental nas configurações de fluxo de dados |
| Atualização Agendada | Sim | Sim, a possibilidade de notificar os proprietários de fluxo de dados após a falha |
Cenários para usar cada tipo de fluxo de dados
Aqui estão alguns cenários de exemplo e recomendações de melhores práticas para cada tipo de fluxo de dados.
Uso entre plataformas — fluxo de dados padrão
Caso o plano para criar fluxos de dados seja usar dados armazenados em várias plataformas (não apenas no Power BI, mas também em outros serviços do Microsoft Power Platform, Dynamics 365 e assim por diante), um fluxo de dados padrão é uma ótima opção. Os fluxos de dados padrão armazenam os dados no Dataverse, que você pode acessar por meio de muitas outras plataformas e serviços.
Transformações de dados do Heavy em tabelas de dados grandes – fluxo de dados analítico
Os fluxos de dados analíticos são uma excelente opção para processar grandes quantidades de dados. Os fluxos de dados analíticos também aprimoram o poder de computação por trás da transformação. Ter os dados armazenados no Azure Data Lake Storage aumenta a velocidade de gravação em um destino. Em comparação com o Dataverse (que pode ter muitas regras para verificar no momento do armazenamento de dados), o Azure Data Lake Storage é mais rápido para transações de leitura/gravação em uma grande quantidade de dados.
Recursos de IA – fluxo de dados analítico
Se você estiver planejando usar qualquer funcionalidade de IA por meio do estágio de transformação de dados, é útil usar um fluxo de dados analítico porque você pode usar todos os recursos de IA compatíveis com esse tipo de fluxo de dados.