Considerações de mapeamento de campo para fluxos de dados padrão
Ao carregar dados em tabelas do Dataverse, é necessário mapear as colunas da consulta de origem na experiência de edição do fluxo de dados às colunas da tabela do Dataverse de destino. Além do mapeamento de dados, deve-se levar em conta outras considerações e práticas recomendadas. Neste artigo, abordamos as configurações de fluxo de dados distintas que controlam o comportamento da atualização de fluxo de dados e, como resultado, os dados na tabela de destino.
Controlar se os fluxos de dados criam ou atualizam registros a cada atualização
A cada atualização de um fluxo de dados, ele busca registros da origem e os carrega no Dataverse. Se você executar o fluxo de dados mais de uma vez, conforme configurar o fluxo de dados, poderá:
- Criar novos registros a cada atualização de fluxo de dados, mesmo que esses registros já existam na tabela de destino.
- Criar novos registros, caso ainda não existam na tabela, ou atualizar os registros existentes, se já existirem na tabela. Esse comportamento é conhecido como executar upsert.
O uso de uma coluna de chave indica ao fluxo de dados para executar upsert em registros na tabela de destino, enquanto não selecionar uma chave indica ao fluxo de dados para criar novos registros na tabela de destino.
Uma coluna de chave é única e determinística de uma linha de dados na tabela. Por exemplo, em uma tabela Pedidos, se a ID do pedido for uma coluna de chave, você não deverá ter duas linhas com a mesma ID do pedido. Além disso, uma ID do pedido (digamos um pedido com a ID 345) deve representar apenas uma linha na tabela. Para escolher a coluna de chave para a tabela no Dataverse a partir do fluxo de dados, você precisa definir o campo de chave na experiência Mapear Tabelas.
Escolher um nome primário e um campo de chave ao criar uma nova tabela
A imagem a seguir mostra como você pode escolher a coluna de chave a ser preenchida da origem ao criar uma nova tabela no fluxo de dados.
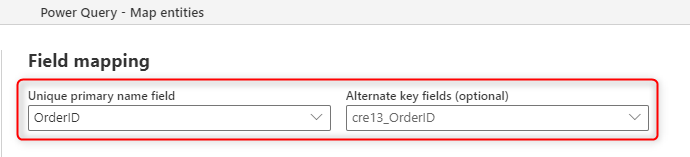
O campo de nome primário que você vê no mapeamento de campo é para um campo de rótulo; este campo não precisa ser exclusivo. O campo usado na tabela para verificar a duplicação é o campo definido no campo Chave Alternativa.
Ter uma chave primária na tabela garante que, mesmo que você tenha linhas de dados duplicadas no campo mapeado para a chave primária, as entradas duplicadas não serão carregadas na tabela. Esse comportamento mantém uma alta qualidade dos dados na tabela. A alta qualidade dos dados é essencial na construção de soluções de relatórios baseadas na tabela.
O campo nome primário
O campo nome primário é um campo de exibição usado no Dataverse. Esse campo é usado em exibições padrão para mostrar o conteúdo da tabela em outros aplicativos. Esse campo não é o campo de chave primária e não deve ser considerado assim. Esse campo pode ter valores duplicados, pois é um campo de exibição. A prática recomendada, no entanto, é usar um campo concatenado para mapear para o campo de nome primário, de modo que o nome seja totalmente explicativo.
O campo de chave alternativa é o que é usado como a chave primária.
Escolher um campo de chave ao carregar em uma tabela existente
Ao mapear uma consulta de fluxo de dados para uma tabela Dataverse existente, você pode escolher se e qual chave deve ser usada ao carregar dados na tabela de destino.
Esta imagem mostra como escolher a coluna de chave a ser usada ao executar upsert em registros para uma tabela Dataverse existente:

Definir a coluna ID Exclusiva de uma tabela e usá-la como um campo de chave para executar upsert de registros em tabelas Dataverse existentes
Todas as linhas da tabela do Microsoft Dataverse têm identificadores únicos definidos como GUIDs. Esses GUIDs são a chave primária de cada tabela. Por padrão, a chave primária de uma tabela não pode ser definida por fluxos de dados e é gerada automaticamente pelo Dataverse quando um registro é criado. Há casos de uso avançados em que é desejável aproveitar a chave primária de uma tabela. Por exemplo, integrar dados com fontes externas, mantendo os mesmos valores de chave primária na tabela externa e na tabela Dataverse.
Observação
- Esse recurso só está disponível ao carregar dados em tabelas existentes.
- O campo identificador exclusivo só aceita uma sequência contendo valores de GUID. Qualquer outro tipo de dados ou valor leva à falha na criação do registro.
Para aproveitar o campo identificador único de uma tabela, selecione Carregar na tabela existente na página Mapear Tabelas ao criar um fluxo de dados. No exemplo mostrado na imagem a seguir, os dados são carregadas na tabela CustomerTransactions e a coluna TransactionID é usada pela fonte de dados como o identificador exclusivo da tabela.
Observe que, na lista suspensa Selecionar chave, é possível selecionar o identificador exclusivo da tabela, que sempre é chamado de "tablename + id". Como o nome da tabela é "CustomerTransactions", o campo identificador exclusivo é denominado "CustomerTransactionId".

Depois de selecionada, a seção de mapeamento de coluna é atualizada para incluir o identificador único como uma coluna de destino. Você pode mapear a coluna de origem que representa o identificador único de cada registro.

Quais são bons candidatos para o campo de chave
O campo de chave é um valor único que representa uma linha única na tabela. É importante ter esse campo porque ele ajuda a evitar registros duplicados na tabela. Esse campo pode vir de três fontes:
A chave primária no sistema de origem (como OrderID no exemplo anterior). campo concatenado criado por meio de transformações do Power Query no fluxo de dados.
Uma combinação de campos a serem selecionados na opção Chave Alternativa. Uma combinação de campos usados como um campo de chave também é chamada de chave composta.
Remover linhas que não existem mais
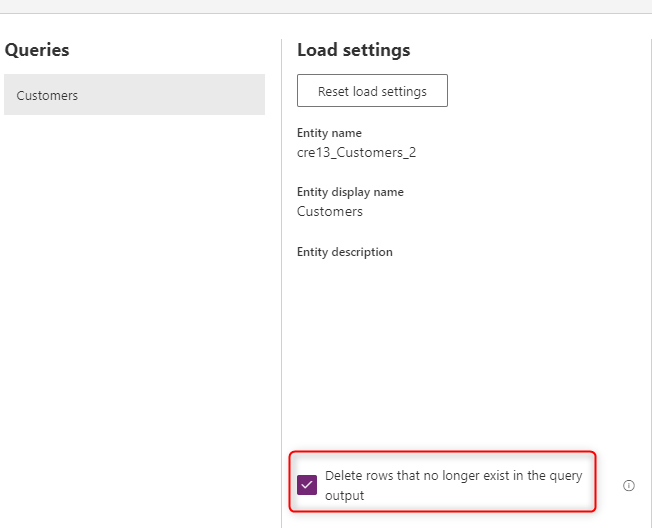
Para que os dados da tabela sejam sempre sincronizados com os dados do sistema de origem, escolha a opção Excluir linhas que não existem mais na saída da consulta. No entanto, essa opção causa lentidão no fluxo de dados porque há a necessidade de uma comparação de linhas com base na chave primária (chave alternativa no mapeamento de campo do fluxo de dados) para que essa ação ocorra.
A opção significa que, se houver uma linha de dados na tabela que não consta na saída de consulta da próxima atualização de fluxo de dados, essa linha será removida da tabela.
Observação
Os fluxos de dados V2 padrão dependem dos campos createdon e modifiedon para remover linhas inexistentes na saída de fluxos de dados da tabela de destino. Se essas colunas não existirem na tabela de destino, os registros não serão excluídos.
Limitações conhecidas
- Atualmente, não há suporte para mapeamento para campos de pesquisa polimórfica.
- No momento, não há suporte ao mapeamento a campos de pesquisa em vários níveis, uma pesquisa que aponta para o campo de pesquisa de outras tabelas.
- Atualmente, não há suporte para mapeamento para Campos Status e Motivo do Status.
- Não há suporte ao mapeamento de dados em textos multilinhas com caracteres de quebra de linha e as quebras de linha são removidas. Você pode usar a marca de quebra de linha
<br>para carregar e preservar o texto multilinhas. - Só existe suporte ao mapeamento para campos Opção configurados com a seleção múltipla ativada sob certas condições. O fluxo de dados carrega apenas dados em campos Escolha com a opção de seleção múltipla ativada, e uma lista separada por vírgulas de valores (inteiros) dos rótulos é usada. Por exemplo, se os rótulos forem "Choice1, Choice2, Choice3" com valores inteiros correspondentes de "1, 2, 3", os valores da coluna deverão ser "1,3" para selecionar a primeira e a última opções.
- Os fluxos de dados V2 padrão dependem dos campos
createdonemodifiedonpara remover linhas inexistentes na saída de fluxos de dados da tabela de destino. Se essas colunas não existirem na tabela de destino, os registros não serão excluídos. - O mapeamento para campos cuja propriedade IsValidForCreate está definida como
falsenão tem suporte (por exemplo, o campo Conta da entidade Contato).