Diretrizes de modelagem do Power BI para o Power Platform
O Microsoft Dataverse é a plataforma de dados padrão para muitos produtos de aplicativos de negócios da Microsoft, incluindo o Dynamics 365 Customer Engagement e aplicativos de tela do Power Apps e também o Dynamics 365 Customer Voice (anteriormente Microsoft Forms Pro), aprovações do Power Automate, portais do Power Apps e outros.
Este artigo fornece diretrizes para criar um modelo de dados do Power BI que se conecta ao Dataverse. Ele descreve as diferenças entre um esquema do Dataverse e um esquema otimizado do Power BI e fornece diretrizes para expandir a visibilidade dos dados do seu aplicativo de negócios no Power BI.
Devido à facilidade de instalação, implantação rápida e adoção generalizada, o Dataverse armazena e gerencia um volume cada vez maior de dados em ambientes nas organizações. Isso significa que há uma necessidade ainda maior (e uma oportunidade) de integrar a análise a esses processos. As oportunidades incluem:
- Criar relatórios sobre todos os dados do Dataverse, indo além das restrições dos gráficos já existentes.
- Fornecer acesso fácil a relatórios relevantes e filtrados contextualmente em um registro específico.
- Aprimorar o valor dos dados do Dataverse integrando-os a dados externos.
- Aproveitar a IA (inteligência artificial) interna do Power BI sem a necessidade de escrever código complexo.
- Aumentar a adoção de soluções do Power Platform aumentando sua utilidade e valor.
- Entregar aos tomadores de decisão de negócios o valor dos dados em seu aplicativo.
Conectar o Power BI ao Dataverse
A conexão do Power BI ao Dataverse envolve a criação de um modelo de dados do Power BI. Você pode escolher entre três métodos para criar um modelo do Power BI.
- Importar dados do Dataverse usando o conector do Dataverse: esse método armazena em cache (armazena) dados do Dataverse em um modelo do Power BI. Ele proporciona um desempenho rápido graças à consulta na memória. Também oferece flexibilidade de design para modeladores, permitindo que eles integrem dados de outras fontes. Devido a esses pontos fortes, a importação de dados é o modo padrão ao criar um modelo no Power BI Desktop.
- Importar dados do Dataverse usando o Link do Azure Synapse: esse método é uma variação no método de importação, pois também armazena dados em cache no modelo do Power BI, mas faz isso conectando-se ao Azure Synapse Analytics. Usando o Link do Azure Synapse para Dataverse, as tabelas do Dataverse são replicadas continuamente no Azure Synapse ou no ADLS (Azure Data Lake Storage) Gen2. Essa abordagem é usada para criar relatórios com centenas de milhares ou até milhões de registros em ambientes do Dataverse.
- Criar uma conexão DirectQuery usando o conector do Dataverse: esse método é uma alternativa à importação de dados. Um modelo do DirectQuery consiste apenas em metadados que definem a estrutura do modelo. Quando um usuário abre um relatório, o Power BI envia consultas nativas ao Dataverse para recuperar dados. Considere criar um modelo directQuery quando os relatórios tiverem que mostrar dados do Dataverse quase em tempo real ou quando o Dataverse tiver que impor a segurança baseada em função para que os usuários possam ver apenas os dados aos quais tenham privilégios para acessar.
Importante
Embora um modelo do DirectQuery possa ser uma boa alternativa quando você precisa de relatórios quase em tempo real ou imposição de segurança do Dataverse em um relatório, o desempenho desse relatório poderá ficar lento.
Veja algumas considerações sobre o DirectQuery mais adiante neste artigo.
Para determinar o método certo para o seu modelo do Power BI, considere:
- Desempenho de consulta
- Volume de dados
- Latência de dados
- Segurança baseada em função
- Complexidade de configuração
Dica
Para ver uma discussão detalhada sobre estruturas de modelo (importação, DirectQuery ou composição), seus benefícios e limitações e recursos para ajudar a otimizar modelos de dados do Power BI, consulte Escolher uma estrutura de modelo do Power BI.
Desempenho de consulta
As consultas enviadas para modelos de importação são mais rápidas do que as consultas nativas enviadas às fontes de dados do DirectQuery. Isso ocorre porque os dados importados são armazenados em cache na memória e são otimizados para consultas analíticas (operações filtrar, agrupar e resumir).
Por outro lado, os modelos do DirectQuery só recuperam dados da origem depois que o usuário abre um relatório, gerando segundos de atraso à medida que o relatório é renderizado. Além disso, as interações do usuário no relatório exigem que o Power BI faça uma nova consulta à origem, reduzindo ainda mais a capacidade de resposta.
Volume de dados
Ao desenvolver um modelo de importação, você deve se esforçar para minimizar os dados carregados no modelo. Isso é válido especialmente para modelos grandes ou modelos que você prevê que aumentarão com o passar do tempo. Para obter mais informações, confira Técnicas de redução de dados para a modelagem de importação.
Uma conexão do DirectQuery com o Dataverse é uma boa opção quando o resultado da consulta do relatório não é grande. Um resultado de consulta grande tem mais de 20 mil linhas nas tabelas de origem do relatório ou o resultado retornado ao relatório depois que os filtros são aplicados é de mais de 20 mil linhas. Nesse caso, você pode criar um relatório do Power BI usando o conector do Dataverse.
Observação
O tamanho de 20 mil linhas não é um limite rígido. No entanto, cada consulta à fonte de dados deve retornar um resultado em até 10 minutos. Posteriormente neste artigo, você aprenderá a trabalhar dentro dessas limitações e verá outras considerações de design do DirectQuery do Dataverse.
Você pode melhorar o desempenho de modelos semânticos maiores usando o conector do Dataverse para importar os dados para o modelo de dados.
Modelos semânticos ainda maiores, com várias centenas de milhares ou até milhões de linhas, podem se beneficiar do uso Link do Azure Synapse para Dataverse. Essa abordagem configura um pipeline gerenciado contínuo que copia dados do Dataverse no ADLS Gen2 como arquivos CSV ou Parquet. Em seguida, o Power BI pode consultar um pool de SQL sem servidor do Azure Synapse para carregar um modelo de importação.
Latência de dados
Nos casos em que os dados do Dataverse mudam rapidamente e os usuários de relatórios precisam ver dados atuais, um modelo do DirectQuery pode fornecer resultados de consulta quase em tempo real.
Dica
Você pode criar um relatório do Power BI que usa a atualização automática de página para mostrar atualizações em tempo real, mas somente quando o relatório se conecta a um modelo do DirectQuery.
Os modelos de dados de importação devem realizar uma atualização de dados para permitir a criação de relatórios sobre alterações de dados recentes. Tenha em mente que há limitações no número de operações diárias de atualização de dados agendadas. Você pode agendar até oito atualizações por dia em uma capacidade compartilhada. Em uma capacidade Premium ou capacidade do Microsoft Fabric você pode agendar até 48 atualizações por dia, o que pode chegar a uma frequência de atualização de 15 minutos.
Importante
Às vezes, este artigo se refere ao Power BI Premium ou às suas assinaturas de capacidade (P SKUs). Lembre-se de que a Microsoft está consolidando atualmente as opções de compra e desativando os SKUs do Power BI Premium por capacidade. Em vez disso, os clientes novos e existentes devem considerar a compra de SKUs (assinaturas de capacidade do Fabric).
Para obter mais informações, consulte Atualização importante chegando ao de licenciamento do Power BI Premium e Perguntas frequentes do Power BI Premium.
Você também pode considerar o uso da atualização incremental para obter atualizações mais rápidas e desempenho quase em tempo real (disponível apenas com o Premium ou Fabric).
Segurança baseada em função
A necessidade de impor a segurança baseada em função, poderá influenciar diretamente na escolha da estrutura de modelos do Power BI.
O Dataverse pode impor uma segurança complexa baseada em função para controlar o acesso a determinados registros por usuários específicos. Por exemplo, um vendedor pode ter permissão para ver apenas as próprias oportunidades de vendas, enquanto que o gerente de vendas pode ver todas as oportunidades de vendas de todos os vendedores. Você pode adaptar o nível de complexidade com base nas necessidades da sua organização.
Um modelo do DirectQuery baseado no Dataverse pode se conectar usando o contexto de segurança do usuário do relatório. Dessa forma, o usuário do relatório verá apenas os dados que tem permissão para acessar. Essa abordagem pode simplificar o design do relatório, desde que o desempenho seja aceitável.
Para melhorar o desempenho, você pode criar um modelo de importação que se conecta ao Dataverse. Nesse caso, você pode adicionar a RLS (segurança em nível de linha) ao modelo, se necessário.
Observação
Poderá ser desafiador replicar a segurança baseada em função do Dataverse para funcionar como a RLS do Power BI, especialmente nos casos em que o Dataverse impõe permissões complexas. Além disso, poderá ser necessário um gerenciamento contínuo para manter as permissões do Power BI em sincronia com as permissões do Dataverse.
Para obter mais informações sobre a RLS do Power BI, confira Diretrizes de RLS (segurança em nível de linha) no Power BI Desktop.
Complexidade de configuração
O uso do conector do Dataverse no Power BI, para importação ou para modelos do DirectQuery, é simples e não requer nenhum software especial nem permissões elevadas do Dataverse. Essa é uma vantagem para organizações ou departamentos que estão começando.
A opção do Link do Azure Synapse requer acesso do administrador do sistema ao Dataverse e a determinadas permissões do Azure. Essas permissões do Azure são necessárias para configurar a conta de armazenamento e um workspace do Synapse.
Práticas recomendadas
Esta seção descreve padrões de design (e antipadrões) que você deve considerar ao criar um modelo do Power BI que se conecta ao Dataverse. Apenas alguns desses padrões são exclusivos do Dataverse, mas tendem a ser desafios comuns para os criadores do Dataverse ao criar relatórios do Power BI.
Foco em um caso de uso específico
Em vez de tentar resolver tudo, concentre-se no caso de uso específico.
Essa recomendação é provavelmente o antipadrão mais comum e possivelmente mais desafiador a ser evitado. A tentativa de criar um único modelo que resolva todas as necessidades de relatório de autoatendimento é desafiadora. A realidade é que modelos bem-sucedidos são criados para responder a perguntas sobre um conjunto central de fatos a respeito de um único tópico principal. Embora inicialmente isso possa parecer limitar o modelo, na verdade é algo empoderador porque você consegue ajustar e otimizar o modelo para responder a perguntas dentro desse tópico.
Para ajudar a garantir que você tenha uma compreensão clara da finalidade do modelo, faça as seguintes perguntas.
- A qual área temática esse modelo dará suporte?
- Quem é o público-alvo dos relatórios?
- Quais perguntas os relatórios estão tentando responder?
- Qual o modelo semântico mínimo viável?
Resista à combinação de várias áreas temáticas em um único modelo simplesmente porque o usuário do relatório tem perguntas sobre várias áreas temáticas que deseja abordar por um único relatório. Ao dividir esse relatório em vários relatórios, cada um com foco em um tópico diferente (ou tabela de fatos), você poderá produzir modelos muito mais eficientes, escalonáveis e gerenciáveis.
Criar um esquema em estrela
Os desenvolvedores e administradores do Dataverse que se sentem confortáveis com o esquema do Dataverse podem ser tentados a reproduzir o mesmo esquema no Power BI. Essa abordagem é um antipadrão, e provavelmente é a mais difícil de superar porque parece correta para manter a consistência.
O Dataverse, como um modelo relacional, é adequado para a finalidade que tem. No entanto, ele não foi projetado como um modelo analítico otimizado para relatórios analíticos. O padrão mais prevalente para modelagem de dados de análise é um design de esquema em estrela. O esquema em estrela é uma abordagem de modelagem madura amplamente adotada por data warehouses relacionais. Ele requer que os modeladores classifiquem suas tabelas de modelo como dimensão ou fato. Os relatórios podem filtrar ou agrupar usando as colunas da tabela de dimensões e resumir as colunas da tabela de fatos.
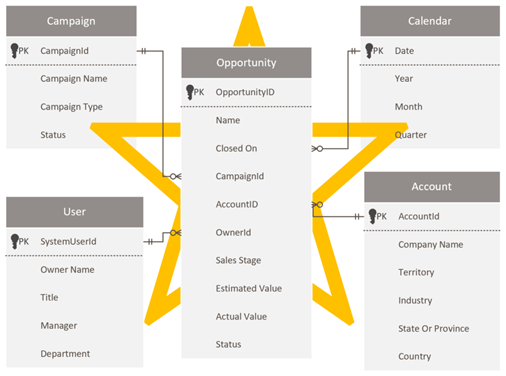
Para obter mais informações, confira Entender o esquema em estrela e a importância dele para o Power BI.
Otimizar consultas do Power Query
O mecanismo de mashup do Power Query se esforça para obter a dobragem de consultas sempre que possível por questão de eficiência. Uma consulta que consegue usar a dobragem delega o processamento da consulta ao sistema de origem.
O sistema de origem, nesse caso, o Dataverse, só precisa entregar resultados filtrados ou resumidos ao Power BI. Uma consulta dobrada costuma ser significativamente mais rápida e eficiente do que uma consulta que não é dobrada.
Para obter mais informações sobre como você realizar a dobragem de consultas, veja Dobragem de consultas do Power Query.
Observação
A Otimização do Power Query é um tópico amplo. Para obter uma melhor compreensão do que o Power Query está fazendo durante a criação e no momento da atualização do modelo no Power BI Desktop, confira Diagnóstico de consulta.
Minimizar o número de colunas de consulta
Por padrão, quando você usa o Power Query para carregar uma tabela do Dataverse, ela recupera todas as linhas e todas as colunas. Quando você consulta uma tabela de usuários do sistema, por exemplo, ela pode conter mais de mil colunas. As colunas nos metadados incluem relações com outras entidades e pesquisas em rótulos de opção, de modo que o número total de colunas cresce com a complexidade da tabela do Dataverse.
Tentar recuperar dados de todas as colunas é um antipadrão. Geralmente, isso resulta em operações de atualização de dados estendidas e fará com que a consulta falhe quando o tempo necessário para retornar os dados exceder 10 minutos.
Recomendamos que você recupere apenas colunas exigidas pelos relatórios. É geralmente uma boa ideia reavaliar e refatorar consultas quando o desenvolvimento de relatórios for concluído, permitindo que você identifique e remova colunas não usadas. Para obter mais informações, consulte Técnicas de redução de dados para modelagem de importação (Remover colunas desnecessárias).
Além disso, coloque a etapa Remover colunas do Power Query antecipadamente para que ela seja dobrada novamente para a origem. Dessa forma, o Power Query pode evitar o trabalho desnecessário de extrair dados da origem apenas para descartá-los posteriormente (em uma etapa desdobrada).
Quando você tem uma tabela que contém várias colunas, pode ser impraticável usar o construtor de consultas interativo do Power Query. Nesse caso, você pode começar criando uma consulta em branco. Em seguida, você usa o Editor Avançado para colar uma consulta mínima que cria um ponto de partida.
Considere a consulta a seguir que recupera dados de apenas duas colunas da tabela account.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name"})
in
#"Removed Other Columns"
Escrever consultas nativas
Se você tem requisitos de transformação específicos, poderá obter um melhor desempenho usando uma consulta nativa escrita no Dataverse SQL, que é um subconjunto do Transact-SQL. Você pode escrever uma consulta nativa para:
- Reduzir o número de linhas (usando uma cláusula
WHERE). - Agregar dados (usando as cláusulas
GROUP BYeHAVING). - Unir tabelas de uma forma específica (usando a sintaxe
JOINouAPPLY). - Usar funções do SQL com suporte.
Para obter mais informações, consulte:
Executar consultas nativas com a opção EnableFolding
O Power Query executa uma consulta nativa usando a função Value.NativeQuery.
Ao usar essa função, é importante adicionar a opção EnableFolding=true para garantir que as consultas sejam dobradas de volta para o serviço do Dataverse. Uma consulta nativa não será dobrada, a menos que essa opção seja adicionada. Habilitar essa opção poderá resultar em melhorias significativas de desempenho: até 97% mais rápido em alguns casos.
Considere a consulta a seguir que usa uma consulta nativa para origem de colunas selecionadas da tabela account. A consulta nativa será dobrada porque a opção EnableFolding=true está definida.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"),
dbo_account = Value.NativeQuery(
Source,
"SELECT A.accountid, A.name FROM account A"
,null
,[EnableFolding=true]
)
in
dbo_account
Você pode esperar obter as maiores melhorias de desempenho ao recuperar um subconjunto de dados de um grande volume de dados.
Dica
A melhoria no desempenho também pode depender de como o Power BI consulta o banco de dados de origem. Por exemplo, uma medida que usa a função DAX COUNTDISTINCT não mostrou quase nenhuma melhoria com ou sem a dica de dobragem. Quando a fórmula de medida foi reescrita para usar a função DAX SUMX, a consulta foi dobrada, resultando em uma melhoria de 97% em relação à mesma consulta sem a dica.
Para obter mais informações, confira Value.NativeQuery. (A opção EnableFolding não está documentada porque é específica apenas para determinadas fontes de dados).
Acelerar o estágio de avaliação
Se você estiver usando o conector do Dataverse (anteriormente conhecido como Common Data Service), poderá adicionar a opção CreateNavigationProperties=false para acelerar o estágio de avaliação de uma importação de dados.
O estágio de avaliação de uma importação de dados itera nos metadados da origem para determinar todas as relações de tabela possíveis. Esses metadados podem ser extensos, especialmente para o Dataverse. Ao adicionar essa opção à consulta, você está informando ao Power Query que não pretende usar essas relações. A opção permite que Power BI Desktop ignore esse estágio da atualização e siga em frente para recuperar os dados.
Observação
Não use essa opção quando a consulta depender de colunas de relação expandidas.
Considere um exemplo que recupera dados da tabela account. Ele contém três colunas relacionadas ao território: territory, territoryide territoryidname.
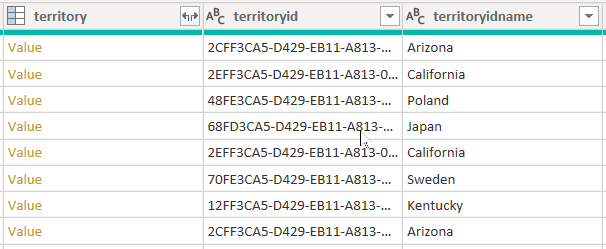
Quando você definir a opção CreateNavigationProperties=false, as colunas territoryid e territoryidname permanecerão, mas a coluna territory, que é uma coluna de relacionamento (ela mostra links de valor para), será excluída. É importante entender que as colunas de relação do Power Query são um conceito diferente para modelar relações, que propagam filtros entre tabelas de modelo.
Considere a consulta a seguir que usa a opção CreateNavigationProperties=false (na etapa Origem) para acelerar o estágio de avaliação de uma importação de dados.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"
,[CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name", "address1_stateorprovince", "address1_country", "industrycodename", "territoryidname"}),
#"Renamed Columns" = Table.RenameColumns(#"Removed Other Columns", {{"name", "Account Name"}, {"address1_country", "Country"}, {"address1_stateorprovince", "State or Province"}, {"territoryidname", "Territory"}, {"industrycodename", "Industry"}})
in
#"Renamed Columns"
Ao usar essa opção, é provável que você experimente uma melhoria significativa de desempenho se a tabela do Dataverse tiver muitas relações com outras tabelas. Por exemplo, como a tabela SystemUser está relacionada a todas as outras tabelas do banco de dados, o desempenho da atualização dessa tabela se beneficiaria definindo a opção CreateNavigationProperties=false.
Observação
Essa opção pode aprimorar o desempenho da atualização de dados de tabelas de importação ou tabelas de modo de armazenamento duplo, incluindo o processo de aplicação de alterações de janela do Editor do Power Query. Ele não melhora o desempenho da filtragem cruzada interativa de tabelas do modo de armazenamento do DirectQuery.
Resolver rótulos de escolha em branco
Se você descobrir que os rótulos de escolha do Dataverse estão em branco no Power BI, pode ser porque os rótulos não foram publicados no ponto de extremidade do TDS (Tabular Data Stream).
Nesse caso, abra o Portal do Maker do Dataverse, navegue até a área Soluções e selecione Publicar todas as personalizações. O processo de publicação atualizará o ponto de extremidade do TDS com os metadados mais recentes, disponibilizando os rótulos de opção para o Power BI.
Modelos semânticos maiores com o Link do Azure Synapse
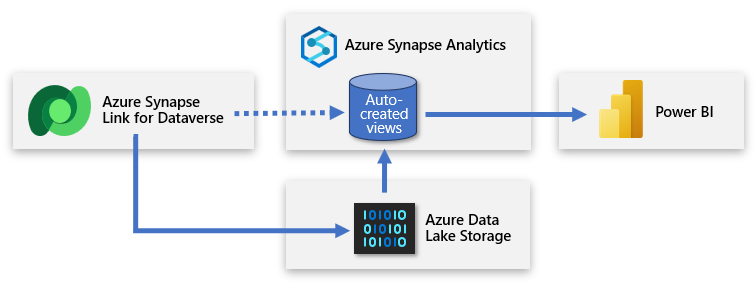
O Dataverse inclui a capacidade de sincronizar tabelas com o ADLS (Azure Data Lake Storage) e, em seguida, conectar-se a esses dados por meio de um workspace do Azure Synapse. Com um pequeno esforço, você pode configurar o Link do Azure Synapse para preencher dados do Dataverse no Azure Synapse e permitir que as equipes de dados obtenham insights mais profundos.
O Link do Azure Synapse possibilita uma replicação contínua dos dados e metadados do Dataverse para o data lake. Ele também fornece um pool de SQL sem servidor interno como uma fonte de dados conveniente para consultas do Power BI.
Os pontos fortes dessa abordagem são significativos. Os clientes ganham a capacidade de executar cargas de trabalho de análise, business intelligence e machine learning em dados do Dataverse usando vários serviços avançados. Os serviços avançados incluem Apache Spark, Power BI, Azure Data Factory, Azure Databricks e Azure Machine Learning.
Criar um Link do Azure Synapse para Dataverse
Para criar um link Azure Synapse para o Dataverse, você precisará dos seguintes pré-requisitos.
- Acesso de administrador do sistema ao ambiente do Dataverse.
- Para o Azure Data Lake Storage:
- Você deve ter uma conta de armazenamento para usar com o ADLS Gen2.
- Você deve receber acesso de Proprietário de Dados do Blob de Armazenamento e Colaborador de Dados do Blob de Armazenamento à conta de armazenamento. Para obter mais informações, consulte RBAC (Controle de acesso baseado na função) do Azure.
- A conta de armazenamento deve habilitar o namespace hierárquico.
- É recomendável que a conta de armazenamento use a RA-GRS (armazenamento com redundância geográfica com acesso de leitura).
- Para o workspace do Synapse:
- Você deve ter acesso a um workspace do Synapse e ter acesso de Administrador do Synapse. Para obter mais informações, consulte Escopos e funções RBAC internas do Synapse.
- O workspace deve estar na mesma região que a conta de armazenamento do ADLS Gen2.
A configuração envolve entrar no Power Apps e conectar o Dataverse ao workspace do Azure Synapse. Uma experiência semelhante a um assistente permite que você crie um link selecionando a conta de armazenamento e as tabelas a serem exportadas. O Link do Azure Synapse copia os dados para o armazenamento do ADLS Gen2 e cria automaticamente exibições no pool de SQL sem servidor interno do Azure Synapse. Em seguida, você pode se conectar a essas exibições para criar um modelo do Power BI.
Dica
Para ver uma documentação completa sobre como criar, gerenciar e monitorar o Link do Azure Synapse, consulte Criar um Link do Azure Synapse para o Dataverse com o workspace do Azure Synapse.
Criar um segundo banco de dados SQL sem servidor
Você pode criar um segundo banco de dados SQL sem servidor e usá-lo para adicionar exibições de relatórios personalizadas. Dessa forma, você pode apresentar um conjunto simplificado de dados ao criador do Power BI que permite criar um modelo com base em dados úteis e relevantes. O novo banco de dados SQL sem servidor se torna a principal conexão de origem do criador e uma representação amigável dos dados provenientes do data lake.
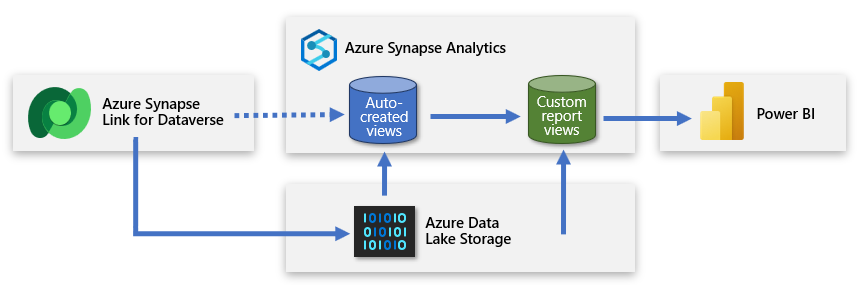
Essa abordagem fornece dados focados, enriquecidos e filtrados para o Power BI.
Você pode criar um banco de dados SQL sem servidor no espaço de trabalho do Azure Synapse usando o Azure Synapse Studio. Selecione Sem servidor como o tipo de banco de dados SQL e insira um nome de banco de dados. O Power Query pode se conectar a esse banco de dados conectando-se ao ponto de extremidade SQL do espaço de trabalho.
Criar exibições personalizadas
Você pode criar exibições personalizadas que encapsulam consultas de pool de SQL sem servidor. Essas exibições servirão como fontes de dados simples e limpas às quais o Power BI se conecta. As exibições devem:
- Incluir os rótulos associados aos campos de escolha.
- Reduzir a complexidade incluindo apenas as colunas necessárias para a modelagem de dados.
- Filtrar linhas desnecessárias, como registros inativos.
Considere a exibição a seguir que recupera dados de campanha.
CREATE VIEW [VW_Campaign]
AS
SELECT
[base].[campaignid] AS [CampaignID]
[base].[name] AS [Campaign],
[campaign_status].[LocalizedLabel] AS [Status],
[campaign_typecode].[LocalizedLabel] AS [Type Code]
FROM
[<MySynapseLinkDB>].[dbo].[campaign] AS [base]
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[OptionsetMetadata] AS [campaign_typecode]
ON [base].[typecode] = [campaign_typecode].[option]
AND [campaign_typecode].[LocalizedLabelLanguageCode] = 1033
AND [campaign_typecode].[EntityName] = 'campaign'
AND [campaign_typecode].[OptionSetName] = 'typecode'
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[StatusMetadata] AS [campaign_status]
ON [base].[statuscode] = [campaign_Status].[status]
AND [campaign_status].[LocalizedLabelLanguageCode] = 1033
AND [campaign_status].[EntityName] = 'campaign'
WHERE
[base].[statecode] = 0;
Observe que a exibição inclui apenas quatro colunas, cada uma com um nome amigável. Também há uma cláusula WHERE para retornar apenas as linhas necessárias, nesse caso, campanhas ativas. Além disso, a exibição consulta a tabela de campanha que está unida às tabelas OptionsetMetadata e StatusMetadata, que recuperam os rótulos de escolha.
Dica
Para obter mais informações sobre como recuperar metadados, consulte Acessar rótulos de opção diretamente do Link do Azure Synapse para Dataverse.
Consultar as tabelas apropriadas
O Link do Azure Synapse para Dataverse garante que os dados sejam sincronizados continuamente com os dados no data lake. Nas atividades de alto uso, as gravações e leituras simultâneas podem criar bloqueios que causam falha nas consultas. Para garantir a confiabilidade ao recuperar dados, duas versões dos dados da tabela são sincronizadas no Azure Synapse.
- Dados quase em tempo real: fornece uma cópia dos dados sincronizados do Dataverse por meio do Link do Azure Synapse de maneira eficiente, detectando quais dados foram alterados desde que foram extraídos inicialmente ou sincronizados pela última vez.
- Dados de instantâneo: fornece uma cópia somente leitura de dados quase em tempo real que são atualizados em intervalos regulares (neste caso, a cada hora). Os nomes da tabela de dados de instantâneo são acrescido de _partitioned.
Se você prever que um alto volume de operações de leitura e gravação será executado simultaneamente, recupere dados das tabelas de instantâneo para evitar falhas de consulta.
Para obter mais informações, consulte Acessar dados quase em tempo real e dados de instantâneo somente leitura.
Conectar-se ao Synapse Analytics
Para consultar um pool de SQL sem servidor do Azure Synapse, você precisará do ponto de extremidade SQL do workspace. Você pode recuperar o ponto de extremidade do Synapse Studio abrindo as propriedades do pool de SQL sem servidor.
No Power BI Desktop, você pode se conectar ao Azure Synapse usando o Conector SQL do Azure Synapse Analytics. Quando o servidor do solicitado, insira o ponto de extremidade SQL do workspace.
Considerações do DirectQuery
Há muitos casos de uso com o modo de armazenamento DirectQuery que podem atender aos seus requisitos. No entanto, o uso do DirectQuery pode afetar negativamente o desempenho do relatório do Power BI. Um relatório que usa uma conexão do DirectQuery com o Dataverse não será tão rápido quanto um relatório que usa um modelo de importação. Em geral, você deve importar dados para o Power BI sempre que possível.
Recomendamos que você considere os tópicos nesta seção ao trabalhar com o DirectQuery.
Para obter mais informações sobre como determinar quando trabalhar com o modo de armazenamento do DirectQuery, consulte Escolher uma estrutura de modelo do Power BI.
Usar tabelas de dimensão de modo de armazenamento duplo
Uma tabela de modo de armazenamento duplo é definida para usar os modos de armazenamento de importação e do DirectQuery. No momento da consulta, o Power BI determina o modo mais eficiente a ser usado. Sempre que possível, o Power BI tenta atender às consultas usando dados importados porque eles são mais rápidos.
Considere a configuração de tabelas de dimensão para o modo de armazenamento duplo sempre que possível. Dessa forma, os visuais de segmentação e as listas de cartões de filtro, que geralmente se baseiam em colunas de tabela de dimensões, serão renderizadas mais rapidamente porque serão consultadas usando dados importados.
Importante
Quando uma tabela de dimensões precisa herdar o modelo de segurança do Dataverse, não é apropriado usar o modo de armazenamento duplo.
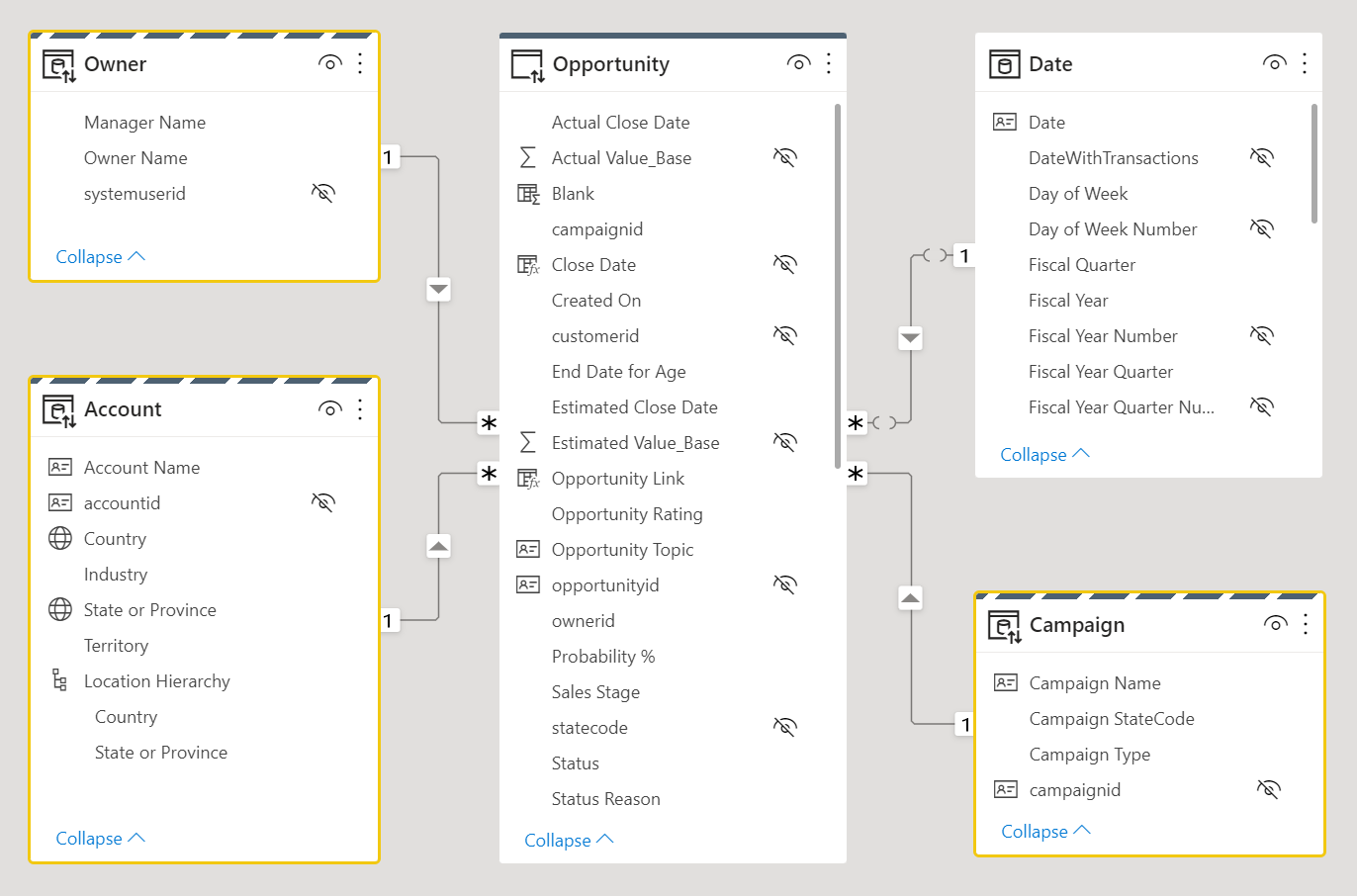
As tabelas de fatos, que normalmente armazenam grandes volumes de dados, devem permanecer como tabelas do modo de armazenamento do DirectQuery. Elas serão filtradas pelas tabelas de dimensão do modo de armazenamento duplo relacionadas, que podem ser unidas à tabela de fatos para obter filtragem e agrupamento eficientes.
Considere o design de modelo de dados a seguir. Três tabelas de dimensão, Owner, Accounte Campaign têm uma borda superior listrada, o que significa que estão definidas como modo de armazenamento duplo.
Para obter mais informações sobre os modos de armazenamento de tabelas, incluindo o armazenamento duplo, confira Gerenciar o modo de armazenamento no Power BI Desktop.
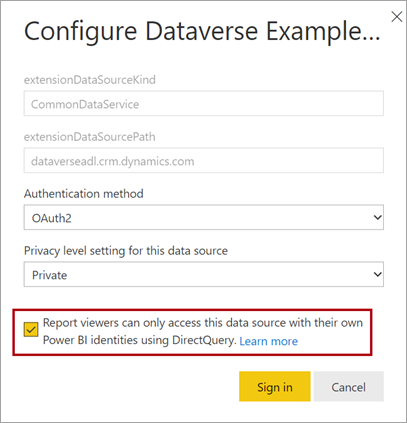
Habilitar o logon único
Ao publicar um modelo DirectQuery no serviço do Power BI, você pode usar as configurações do modelo semântico para habilitar o SSO (logon único) usando o Microsoft Entra ID OAuth2 para os usuários do relatório. Você deve habilitar essa opção quando as consultas do Dataverse precisarem ser executadas no contexto de segurança do usuário do relatório.
Quando a opção de SSO está habilitada, o Power BI envia as credenciais autenticadas do Microsoft Entra do usuário do relatório nas consultas ao Dataverse. Essa opção permite que o Power BI cumpra as configurações de segurança definidas na fonte de dados.
Para obter mais informações, confira SSO (logon único) para fontes do DirectQuery.
Replicar "Meus" filtros no Power Query
Ao usar do Microsoft Dynamics 365 Customer Engagement (CE) e Power Apps criados com base em modelos no Dataverse, você pode criar exibições que mostram apenas registros em que um campo de nome de usuário, como Owner, é igual ao usuário atual. Por exemplo, você pode criar exibições chamadas "Minhas oportunidades abertas", "Meus casos ativos" e outras.
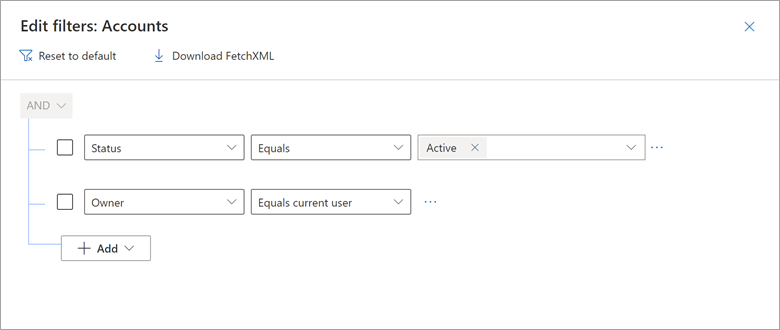
Considere um exemplo em que a exibição Minhas Contas Ativas do Dynamics 365 inclui um filtro no qual Proprietário é igual ao usuário atual.
Você pode reproduzir esse resultado no Power Query usando uma consulta nativa que insira o token CURRENT_USER.
Considere o exemplo a seguir que mostra uma consulta nativa que retorna as contas do usuário atual. Na cláusula WHERE, observe que a coluna ownerid é filtrada pelo token CURRENT_USER.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false],
dbo_account = Value.NativeQuery(Source, "
SELECT
accountid, accountnumber, ownerid, address1_city, address1_stateorprovince, address1_country
FROM account
WHERE statecode = 0
AND ownerid = CURRENT_USER
", null, [EnableFolding]=true])
in
dbo_account
Ao publicar o modelo no serviço do Power BI, você precisa habilitar o logon único (SSO) para que o Power BI envie as credenciais autenticadas do Microsoft Entra do usuário do relatório para o Dataverse.
Criar modelos de importação suplementares
Você pode criar um modelo do DirectQuery que impõe permissões do Dataverse sabendo que o desempenho será lento. Em seguida, você pode complementar esse modelo com modelos de importação direcionados a assuntos públicos específicos que podem impor permissões RLS.
Por exemplo, um modelo de importação pode fornecer acesso a todos os dados do Dataverse, mas não impor nenhuma permissão. Esse modelo seria adequado para executivos que já tenham acesso a todos os dados do Dataverse.
Como outro exemplo, quando o Dataverse impõe permissões baseadas em função por região de vendas, você pode criar um modelo de importação e replicar essas permissões usando RLS. Como alternativa, você pode criar um modelo para cada região de vendas. Em seguida, você pode conceder permissão de leitura a esses modelos (modelos semânticos) aos vendedores de cada região. Para facilitar a criação desses modelos regionais, você pode usar parâmetros e modelos de relatório. Para obter mais informações, consulte Criar e usar modelos de relatório no Power BI Desktop.
Conteúdo relacionado
Para obter mais informações relacionadas a este artigo, confira os recursos a seguir.