Expansão de modelo semântico do Power BI
A expansão semântica de modelos ajuda o Power BI a oferecer um desempenho rápido enquanto seus relatórios e dashboards são consumidos por um grande público. A expansão semântica do modelo usa sua capacidade Premium para hospedar uma ou mais réplicas de somente leitura de seu modelo semântico de primário. Ao aumentar a taxa de transferência, as réplicas somente leitura garantem que o desempenho não diminua quando vários usuários enviam consultas ao mesmo tempo.
Quando o Power BI cria réplicas somente leitura, ele as separa do modelo semântico de leitura/gravação primário. As réplicas somente leitura atendem a consultas de relatório e dashboard do Power BI e o modelo semântico de leitura/gravação é usado quando operações de gravação e atualização são executadas. Durante as operações de gravação e atualizações, as cópias do conjunto de dados somente leitura continuam a servir suas consultas de relatórios e painéis sem serem interrompidas. Por padrão, os modelos semânticos somente leitura e leitura-gravação são sincronizados automaticamente para que as réplicas somente leitura sejam mantidas atualizadas. No entanto, você pode desabilitar a sincronização automática e optar por sincronizar manualmente na linha de comando ou por script.
A tabela a seguir mostra a sincronização necessária para cada método de atualização quando a expansão do modelo semântico do Power BI está habilitada e a sincronização automática é desabilitada:
| Método Refresh | Sincronizar |
|---|---|
| UI sob demanda | Sincronização constante |
| Atualização Agendada | Sincronização constante |
| API REST básica | Sincronização manual necessária 1 |
| API REST avançada | Sincronização manual necessária 1 |
| XMLA | Sincronização manual necessária 1 |
1 – Com autoSyncReadOnlyReplicas em queryScaleOutSettings definido como false.
Gerenciamento de réplicas
A expansão cria uma réplica de modelo semântico de leitura/gravação e tantas réplicas somente leitura quantas forem necessárias. Todas as operações de gravação são direcionadas para a réplica de leitura/gravação. Isso inclui consultas em sessões que direcionam a réplica de leitura/gravação explicitamente, ou seja, não usam ?readonly na cadeia de caracteres da conexão. Essas consultas podem causar alto uso de CPU interativa na réplica de leitura/gravação. Nesses casos, uma nova réplica não é criada porque a carga de consulta que direciona a réplica de leitura/gravação não pode ser distribuída para réplicas somente leitura.
O número de réplicas somente leitura é determinado com base no número de CUs que suas consultas consomem. Se a demanda exceder os recursos de computação atualmente disponíveis em um nó em que o modelo é carregado e permanecer alta, uma réplica somente leitura adicional poderá ser criada em outro nó para distribuir a carga. No entanto, o número total de CUs consumidas por todas as réplicas combinadas não pode exceder o número máximo de CUs que um único modelo pode consumir em seu SKU de capacidade especificado.
Por exemplo, um determinado modelo semântico em uma capacidade F64 terá recursos suficientes em um único nó para consumir todas as CUs permitidas nesse SKU. Portanto, as capacidades F64 normalmente não são dimensionadas além de uma única réplica somente leitura. Por outro lado, as capacidades F256 e F1024+ têm maior probabilidade de criar uma segunda réplica somente leitura porque um único nó pode não ser suficiente para fornecer todas as CUs que podem ser usadas em uma capacidade F256/F1024+.
O QSO foi projetado para aproveitar o poder de computação disponível de um determinado SKU de capacidade da maneira mais eficiente e contínua possível, com o menor número de réplicas somente leitura e sem sobrecarga de gerenciamento para proprietários de modelos semânticos.
No entanto, a carga atual em uma capacidade pode ser alta o suficiente para causar limitação se mais réplicas forem adicionadas. A limitação impede que réplicas adicionais somente leitura alcancem um alto uso sustentado da CPU. Nesses casos, uma nova réplica de leitura escalada horizontalmente não é criada.
Uma réplica é removida quando o uso de para o modelo é reduzido o suficiente e permanece consistentemente baixo o suficiente.
Pré-requisitos
Por padrão, a expansão está habilitada para seu locatário, mas não está habilitada para modelos semânticos em seu locatário. Para habilitar a expansão para um modelo semântico, você deve usar as APIs REST do Power BI. Antes de instalar, os seguintes pré-requisitos devem ser atendidos:
As consultas de expansão para a configuração de modelos semânticos grandes para seu locatário estão habilitadas (padrão).
Seu espaço de trabalho reside em uma capacidade do Power BI Premium:
- PPU (Premium Por Usuário)
- SKUs do Power BI Premium P
- Um SKUs do Power BI para o Power BI Embedded (também conhecido como inserir para seus clientes).
- SKUs Fabric F
A configuração de formato de armazenamento de modelo semântico grande está habilitada.
Para gerenciar modelos semânticos usando a API REST, use cmdlets de Gerenciamento do Power BI. Instale abrindo o PowerShell no modo Administrador e executando o comando:
Install-Module -Name MicrosoftPowerBIMgmtAs seguintes versões de serviço, biblioteca e aplicativo (ou superior) dão suporte à conexão com réplicas somente leitura:
App, biblioteca ou serviço Versão Provedor Microsoft Analysis Services OLE DB para Microsoft SQL Server (MSOLAP) 16.0.20.201 (março de 2022) Microsoft.AnalysisServices.AdomdClient (ADOMD.NET) 19.36.0 (março de 2022) Power BI Desktop Junho de 2022 SQL Server Management Studio (SSMS) 19,0 Editor Tabular 2 2.16.6 Editor Tabular 3 3.2.3 DAX Studio 3.0.0
Configurar expansão para um modelo semântico
Para saber como habilitar ou desabilitar a expansão para um modelo semântico ou obter o status de expansão usando o PowerShell e as APIs REST, consulte Configurar expansão semântica de modelo.
Conectar-se a um tipo de modelo semântico específico
Quando a Expansão está habilitada, as seguintes conexões são retidas:
Por padrão, o Power BI Desktop se conecta à réplica somente leitura.
Os relatórios de conexão dinâmica se conectam a uma réplica somente leitura.
Os aplicativos cliente XMLA conectam-se ao modelo semântico de leitura/gravação por padrão.
Atualiza-se no serviço do Power BI e atualiza usando a API REST de Atualização Avançadaconecte-se ao modelo semântico de leitura/gravação.
Você pode se conectar a uma réplica somente leitura ou ao modelo semântico de leitura/gravação acrescentando uma das seguintes cadeias de caracteres à URL do modelo semântico:
- Somente leitura -
?readonly - Read-write -
?readwrite
Desabilitar a expansão semântica do modelo para seu locatário
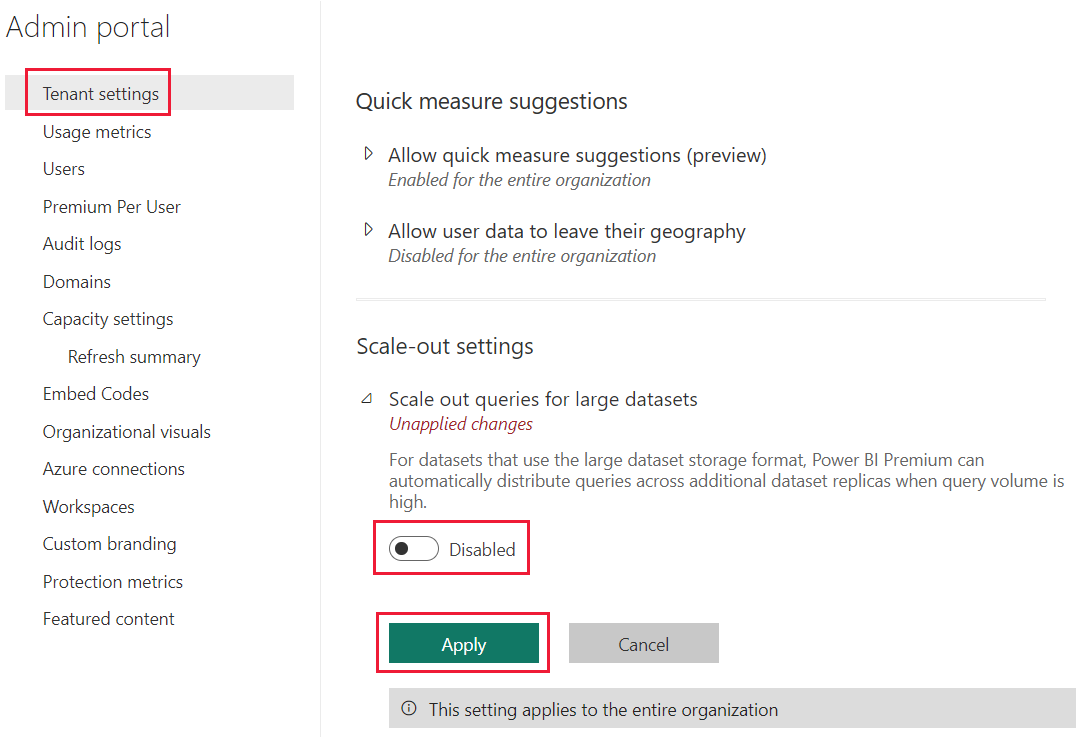
A expansão de modelo semântico do Power BI é habilitada por padrão para um locatário. Administradores do locatário do Power BI podem desabilitar essa configuração. Para desabilitar a expansão semântica do modelo para o locatário, faça o seguinte:
Vá para as configurações do locatário.
Nas configurações de expansão, expanda as consultas de expansão para modelos semânticos grandes.
Alterne a opção para Desabilitado.
Escolha Aplicar.
Considerações e limitações
Os aplicativos clientes podem se conectar à réplica somente leitura através do ponto de extremidade XMLA, desde que tenham suporte para o modo especificado na cadeia de conexão. Os aplicativos clientes também podem se conectar à instância leitura-gravação usando o ponto de extremidade XMLA.
As atualizações manuais e programadas são sempre sincronizadas automaticamente com a versão mais recente das cópias das réplicas somente leitura. As atualizações da API REST respeitam a configuração de sincronização automática. Se a sincronização automática estiver desabilitada, seu modelo semântico deverá ser sincronizado com as réplicas somente leitura usando a API REST de sincronização manual.
Com a sincronização automática desabilitada, as atualizações e atualizações XMLA devem ser sincronizadas com as cópias de modelo semântico somente leitura usando a API REST de sincronização.
Ao excluir um modelo semântico de expansão do Power BI e criar outro modelo semântico com o mesmo nome, permita que cinco minutos passem antes de criar o novo modelo semântico. Pode demorar um pouco para o Power BI remover as réplicas do modelo semântico primário.
Quando a expansão do modelo semântico do Power BI está habilitada e
autoSyncReadOnlyReplicas=false, não há suporte para alterações nos seguintes recursos:- Adição ou exclusão de funções
- Atualização do conjunto de associações de funções para qualquer função
- Modificação de uma fonte de dados
- Exclusão de fontes de dados usadas por uma DirectQuery ou uma tabela dupla
- Alterações na segurança em nível de objeto (OLS) ou expressões de segurança dinâmica em nível de linha (RLS)
Para fazer alterações nesses recursos, desabilitar a expansão e aguarde alguns minutos para que a alteração ocorra antes da habilitação.
A descoberta de associações de funções usando o conjunto de linhas Modo de Exibição de Gerenciamento Dinâmico (DMV) TMSCHEMA_ROLE_MEMBERSHIPS, não retorna nenhum resultado quando executado em relação à réplica de leitura.
Os relatórios que usam uma conexão Dinâmica sempre se conectam à réplica de leitura, mesmo que a cadeia de caracteres da conexão use
?readwrite. Entretanto, no Power BI Desktop, as conexões dinâmicas que usam?readwriteconectam-se à réplica de leitura/gravação.Os conjuntos de linhas DBSCHEMA_CATALOGS e DISCOVER_XML_METADATA Modo de Exibição de Gerenciamento Dinâmico (DMV) retornam informações de réplica de leitura/gravação ao usar
?readonlyna cadeia de conexão.O criador de perfil do SQL Server não funciona com a cadeia de conexão
?readonly.Essas operações disparam a sincronização automática mesmo quando a sincronização automática está desativada (
AutoSync=Off).- Migrar um espaço de trabalho de uma capacidade para outra.
- Alternância (ou giro) da versão da chave usada para Traga suas próprias chaves de criptografia (BYOK).
- Mover o espaço de trabalho de um modelo semântico de uma capacidade que não usa BYOK para uma capacidade que usa BYOK.
- Mover o espaço de trabalho de um modelo semântico de uma capacidade que usa BYOK para uma capacidade que não usa BYOK.
- Restauração de um modelo semântico usando o ponto de extremidade XMLA público.
Desabilitar o Formato de armazenamento de modelo semântico grande desabilita a expansão e perde todas as informações de sincronização.