Traga seu próprio Azure Data Lake Storage Gen2
O Power Automate Process Mining oferece a opção de armazenar e ler dados de log de eventos diretamente do Azure Data Lake Storage Gen2. Esse recurso simplifica o gerenciamento de extração, transformação e carregamento (ETL) conectando-se diretamente à sua conta de armazenamento.
Atualmente, esse recurso oferece suporte à ingestão do seguinte:
-
CSV
- Arquivo CSV único.
- Pasta com vários arquivos CSV que têm a mesma estrutura. Todos os arquivos são ingeridos.
-
Parquet
- Arquivo parquet único.
- Pasta com vários arquivos parquet que têm a mesma estrutura. Todos os arquivos são ingeridos.
-
Delta-parquet
- Pasta que contém uma estrutura delta-parquet.
Pré-requisitos
A conta do Data Lake Storage deve ser Gen2. Você pode conferir isso no portal do Azure. As contas de armazenamento do Azure Data Lake Gen1 não têm suporte.
A conta do Data Lake Storage deve ter o recurso namespace hierárquico habilitado.
A função Proprietário deve ser atribuída ao usuário que executa a configuração inicial do contêiner para o ambiente para os seguintes usuários no mesmo ambiente. Esses usuários estão se conectando ao mesmo contêiner e devem ter estas atribuições:
- Função de Leitor de Dados de Blob de Armazenamento ou de Colaborador de Dados de Blob de Armazenamento atribuída
- Função de Leitor do Azure Resource Manager atribuída, no mínimo.
A regra de Compartilhamento de recursos (CORS) para sua conta de armazenamento deve ser estabelecida para compartilhar com o Power Automate Process Mining.
As origens permitidas devem ser definidas como
https://make.powerautomate.comehttps://make.powerapps.com.Os métodos permitidos devem incluir:
get,options,put,post.Os cabeçalhos permitidos devem ser tão flexíveis quanto possível. Recomendamos defini-los como
*.Os cabeçalhos expostos devem ser tão flexíveis quanto possível. Recomendamos defini-los como
*.A idade máxima deve ser o mais flexível possível. Recomendamos usar
86400.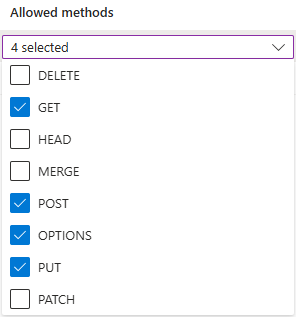
Os dados CSV no Data Lake Storage devem atender aos seguintes requisitos do formato de arquivo CSV:
- Tipo de compactação: Nenhuma
- Delimitador de coluna: Vírgula (,)
- Delimitador de linha: Padrão e codificação. Por exemplo, Padrão (\r,\n ou \r\n)

Todos os dados devem estar no formato final de log de eventos e atender aos requisitos listados em Requisitos de dados. Os dados devem estar prontos para serem mapeados para o esquema de mineração de processo. Nenhuma transformação de dados está disponível após a ingestão.
O tamanho (largura) da linha do cabeçalho está atualmente limitado a 1 MB.
Importante
Certifique-se de que o carimbo de data/hora representado em seu arquivo CSV segue o formato padrão ISO 8601 (por exemplo, YYYY-MM-DD HH:MM:SS.sss ou YYYY-MM-DDTHH:MM:SS.sss).
Conectar-se ao Azure Data Lake Storage
No painel de navegação à esquerda, selecione Process mining>Começar aqui.
No campo Nome do processo, insira um nome para o processo.
No cabeçalho Fonte de dados, selecione Importar dados>Azure Data Lake>Continuar.

Na tela Configuração de conexão, selecione sua ID da assinatura, Grupo de Recursos, Conta de armazenamento e Contêiner nos menus suspensos.
Selecione o arquivo ou pasta que contém os dados do log de eventos.
Você pode selecionar um único arquivo ou uma pasta com vários arquivos. Todos os arquivos devem ter os mesmos cabeçalhos e formato.
Selecione Avançar.
Na tela Mapear seus dados, mapeie seus dados para o esquema necessário.
Conclua a conexão selecionando Salvar e Analisar.
Definir configurações de atualização de dados incrementais
Você pode atualizar um processo ingerido do Azure Data Lake em uma agenda, por meio de uma atualização completa ou incremental. Embora não haja políticas de retenção, você pode ingerir dados de forma incremental usando um dos seguintes métodos:
Se você selecionou um único arquivo na seção anterior, acrescente mais dados ao arquivo selecionado.
Se você selecionou uma pasta na seção anterior, adicione arquivos incrementais à pasta selecionada.
Importante
Ao adicionar arquivos incrementais a uma pasta ou subpasta selecionada, certifique-se de indicar a ordem de incremento nomeando os arquivos com datas como AAMMDD.csv ou AAAAMMDDHHMMSS.csv.
Para atualizar um processo:
Acesse a página Detalhes do processo.
Selecione Configurações de Atualização.
Na tela Agendar atualização, conclua as seguintes etapas:
- Ative o botão de alternância Manter os dados atualizados.
- Nas listas suspensas Atualizar dados a cada, selecione a frequência da atualização.
- Nos campos Iniciar em, selecione a data e a hora da atualização.
- Ative o botão de alternância Atualização incremental.