Visão geral da análise de causa raiz
A análise de causa raiz (RCA) permite localizar conexões ocultas nos seus dados. Por exemplo, ela ajuda você a entender por que alguns casos demoram mais para serem concluídos do que outros, ou por que alguns casos ficam presos em retrabalhos enquanto outros são executados sem problemas. A RCA mostrará as principais diferenças entre esses casos.
Dados obrigatórios
A RCA pode usar todos os seus atributos no nível do caso, métricas e métricas personalizadas para localizar conexões entre elas e uma métrica de sua escolha.
A melhor amostra é incluir todos os dados possíveis como um atributo no nível do caso e deixar que a RCA escolha qual atributo realmente influencia a métrica e qual não.
Como o RCA funciona
O algoritmo da RCA computará uma estrutura de árvore onde cada nó dividirá o conjunto de dados em duas partes menores. Isso é baseado em uma variável onde ele encontra a melhor correlação entre a divisão da variável e a métrica de destino. A partir disso, você pode ver as conexões ocultas nos dados. É aqui que ele dirá qual combinação de atributos influenciará o caso e de que maneira.
Como a RCA encontra a melhor divisão
Primeiro, geramos centenas a milhares de combinações de divisões possíveis. Em seguida, testamos cada divisão para descobrir como ela realmente dividirá o conjunto de dados em duas partes. Calculamos a variação da métrica principal em cada parte da divisão e calculamos a pontuação de cada divisão com o seguinte cálculo:
scoresplit_x = varianceleft * number of casesleft + varianceright * number of casesright
Depois, classificamos todas as divisões por essa pontuação e as melhores divisões são usadas desde o início, com a menor pontuação. Para a métrica principal categórica (cadeia de caracteres), calculamos a impureza de Gini em vez da variação.
Exemplo de RCA
Neste exemplo, queremos ver a causa raiz por trás da duração do caso. Nos dados, temos os atributos no nível do caso país do fornecedor, cidade do fornecedor, material,valor total e centro de custo. A duração média do caso é de 46 horas.
Ao analisar cada valor de cada atributo separadamente, podemos ver que o maior influenciador da duração do caso é quando a cidade do fornecedor é Graz, o que, em média, aumenta a duração do caso em 15 horas. Nessa análise inicial, podemos ver que os outros valores de atributos influenciam muito menos a métrica de destino. No entanto, quando computamos o modelo de árvore, podemos ver que o cálculo acima é enganoso (como na captura de tela a seguir).
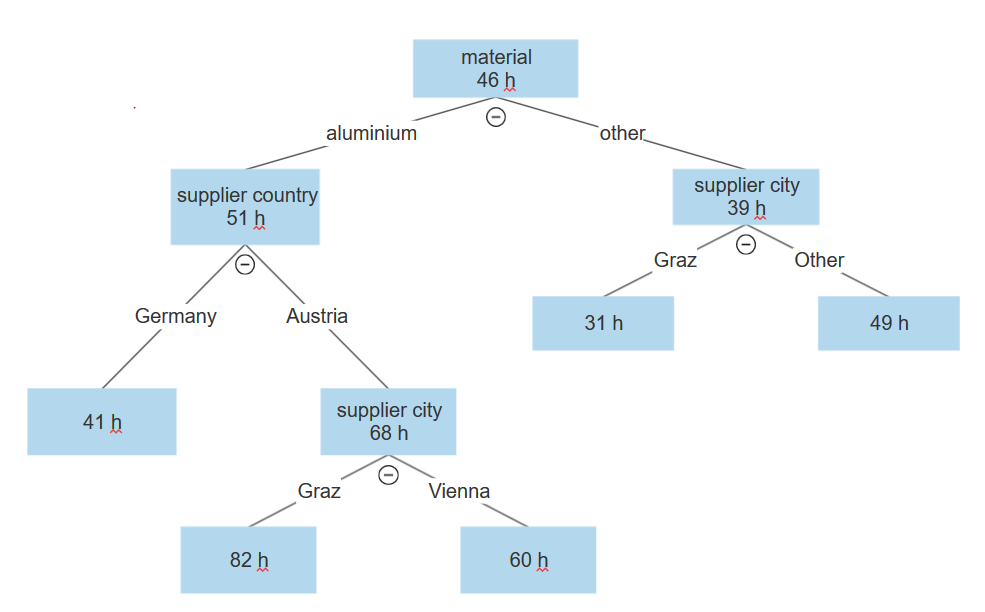
A estrutura da árvore é assim:
A primeira divisão são os dados ao longo da variável material. Os dados com alumínio estão de um lado e todos os outros materiais estão do outro lado.
A ramificação alumínio é dividida novamente por país do fornecedor em Alemanha e Áustria.
A ramificação Áustria continua com uma divisão por cidade do fornecedor, com Graz de um lado e Viena do outro.
No nó Graz, o caso médio foi 36 horas mais lento do que a duração média geral de 46 horas.
Na mesma árvore, podemos ver que, se tivermos outro material que não o alumínio, ele também será dividido pela variável cidade do fornecedor, onde de um lado está Graz e do outro está Viena, Munique ou Frankfurt. Mas aqui, os valores são o oposto. Graz tem estatísticas muito melhores do que Viena ou qualquer cidade alemã, com um caso médio em Graz sendo 15 horas mais rápido do que a média geral de todos os casos.
A partir disso, podemos ver que as estatísticas iniciais são enganosas porque Graz está tendo um desempenho ruim quando o material é alumínio. No entanto, está tendo um desempenho acima da média quando o material não é alumínio e é completamente o oposto de outras cidades.
As estatísticas da Influência da Duração do Caso leva em consideração somente um valor e, às vezes, pode ser enganoso. A RCA leva em consideração as combinações deles para fornecer mais insights sobre seu processo.