Recuperar detalhes de uma página da Web
Extrair informações sobre páginas da Web é uma função essencial na maioria dos fluxos relacionados à Web. A ação Obter detalhes da página da Web permite que você recupere vários detalhes de páginas da Web e manuseie-os em seus fluxos da área de trabalho.
Para usar a ação, você precisa de uma instância de navegador já criada que especifique a página da Web da qual deseja extrair detalhes. Uma instância do navegador pode ser criada com qualquer ação de inicialização do navegador.
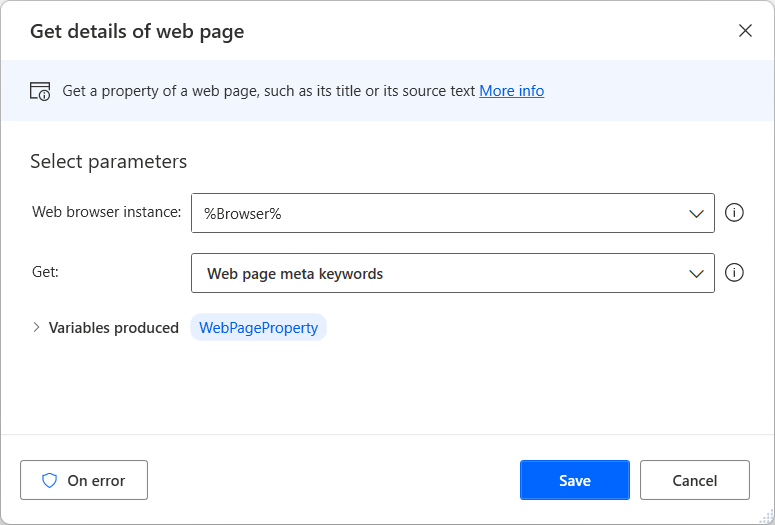
Depois de selecionar a instância de navegador apropriada, escolha as informações que deseja extrair da página da Web. A ação Obter detalhes da página da Web oferece seis opções diferentes:
- A descrição da página da Web
- As palavras-chave meta da página da Web
- O título da página da Web
- O texto da página da Web
- O código-fonte da página da Web
- O endereço URL da página da Web
As informações recuperadas são armazenadas para uso posterior em uma variável de texto chamada WebPageProperty.
Evitar erros ao recuperar detalhes
Embora a maioria das propriedades exista praticamente em todas as páginas da Web, há cenários em que a ação Obter detalhes da página da Web não recupera os detalhes selecionados. Por exemplo, páginas da Web sem palavras-chave meta são uma ocorrência comum.
Se você não tiver certeza se existe um atributo em uma página da Web, configure as opções Se houver erro da ação Obter detalhes da página da Web para continuar executando o fluxo após a falha. Para encontrar mais informações sobre o tratamento de erros de ação, consulte Tratar erros em fluxos da área de trabalho.
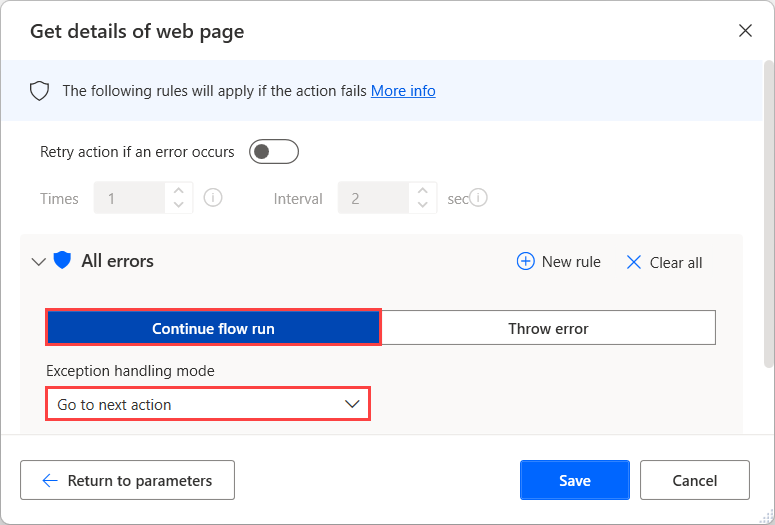
Para determinar se a extração de dados foi bem-sucedida, use uma condicional Se para verificar se a variável WebPageProperty está vazia ou não.
A condicional permite implementar diferentes funcionalidades para os casos de extração de dados bem-sucedida e malsucedida. Você pode encontrar mais informações sobre condicionais em Usar condicionais.
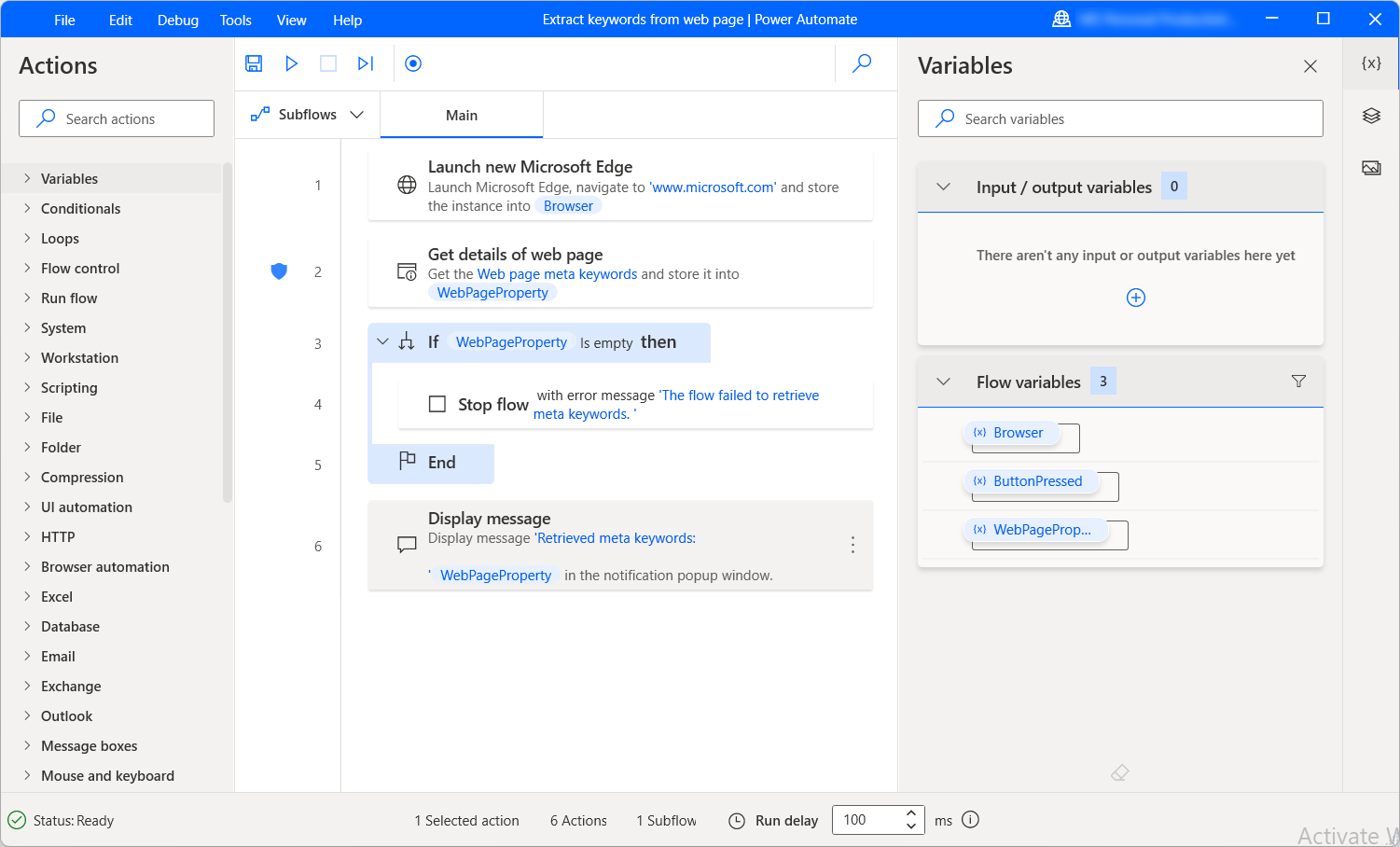
O subfluxo de exemplo a seguir recupera as palavras-chave meta disponíveis de uma página da Web e as exibe em uma caixa de mensagem. Se a extração não for bem-sucedida, o fluxo será interrompido e retornará uma mensagem de erro.