Ingerir dados do Dataverse exportados com o Azure Data Factory
Depois de exportar dados do Microsoft Dataverse para o Azure Data Lake Storage Gen2 com o Azure Synapse Link for Dataverse, você pode usar o Azure Data Factory para criar fluxos de dados, transformar seus dados e executar análises.
Observação
O Azure Synapse Link for Dataverse era conhecido anteriormente como Exportar para o data lake. O serviço foi renomeado em maio de 2021 e continuará a exportar dados para o Azure Data Lake, bem como para o Azure Synapse Analytics.
Este artigo mostra como realizar as seguintes tarefas:
Defina a conta de armazenamento do Data Lake Storage Gen2 com os dados do Dataverse como origem em um fluxo de dados do Data Factory.
Transforme os dados do Dataverse no Data Factory com um fluxo de dados.
Defina a conta de armazenamento do Data Lake Storage Gen2 com os dados do Dataverse como coletora em um fluxo de dados do Data Factory.
Execute seu fluxo de dados criando um pipeline.
Pré-requisitos
Esta seção descreve os pré-requisitos necessários para ingerir dados exportados do Dataverse com o Data Factory.
Funções do Azure. A conta de usuário usada para entrar no Azure deve ser membro da função colaborador ou proprietário ou um administrador da assinatura do Azure. Para exibir as permissões que você tem na assinatura, acesse o portal do Azure, selecione seu nome de usuário no canto superior direito, selecione ... e, em seguida, selecione Minhas permissões. Se você tiver acesso a várias assinaturas, selecione a apropriada. Para criar e gerenciar recursos secundários para o Data Factory no portal do Azure — incluindo conjuntos de dados, serviços vinculados, pipelines, gatilhos e tempos de execução de integração — você deve pertencer à função Colaborador do Data Factory no nível do grupo de recursos ou acima.
Azure Synapse Link for Dataverse. Neste guia, presume-se que você já exportou os dados do Dataverse usando o Azure Synapse Link for Dataverse. Neste exemplo, os dados da tabela de contas são exportados para o data lake.
Azure Data Factory. Neste guia, pressupõe-se que você já tenha criado um data factory com a mesma assinatura e o mesmo grupo de recursos da conta de armazenamento que contém os dados do Dataverse.
Definir a conta de armazenamento do Data Lake Storage Gen2 como uma fonte
Abra o Azure Data Factory e selecione o data factory que está na mesma assinatura e no mesmo grupo de recursos da conta de armazenamento que contém os dados do Dataverse. Selecione Criar fluxo de dados na página inicial.
Ative o modo Depuração de fluxo de dados e selecione o tempo de vida útil preferencial. Isso pode levar até 10 minutos, mas você pode prosseguir com as etapas a seguir.

Selecione Adicionar fonte.

Em Configurações da fonte, faça o seguinte:
- Nome do fluxo de saída: insira o nome desejado.
- Tipo de origem: selecione Em linha.
- Tipo de conjunto de dados em linha: selecione Common Data Model.
- Serviço vinculado: selecione a conta de armazenamento no menu suspenso e, depois, vincule um novo serviço fornecendo os detalhes da sua assinatura e deixando todas as configurações padrão.
- Amostragem: se você quiser usar todos os seus dados, selecione Desabilitar.
Em Opções de fonte, faça o seguinte:
Formato de metadados: selecione Model.json.
Localização raiz: insira o nome do contêiner na primeira caixa (Contêiner) ou opte por Procurar o nome do contêiner e selecione OK.
Entidade: insira o nome da tabela ou opte por Procurar a tabela.

Verifique a guia Projeção para garantir que o esquema foi importado com sucesso. Se você não vir nenhuma coluna, selecione Opções de esquema e marque a opção Inferir tipos de coluna dessincronizados. Configure as opções de formatação para corresponder ao conjunto de dados e selecione Aplicar.
É possível ver os dados na guia Versão preliminar dos dados para garantir que a criação da fonte foi completa e precisa.
Transformar os dados do Dataverse
Depois de definir os dados exportados do Dataverse na conta do Azure Data Lake Storage Gen2 como uma fonte no fluxo de dados do Data Factory, há muitas possibilidades de transformar seus dados. Mais informações: Azure Data Factory
Siga estas instruções para criar uma classificação para cada linha pelo campo receita da tabela de contas.
Selecione + no canto inferior direito da transformação anterior e, depois, pesquise e selecione Classificação.
Na guia Configurações de classificação, você pode fazer o seguinte:
Nome do fluxo de saída: insira o nome que deseja, como Rank1.
Fluxo de Entrada: selecione o nome da fonte desejada. Nesse caso, o nome da fonte da etapa anterior.
Opções: deixe as opções desmarcadas.
Coluna de classificação: insira o nome da coluna de classificação gerada.
Condições de classificação: selecione a coluna receita e classifique por ordem Descendente.
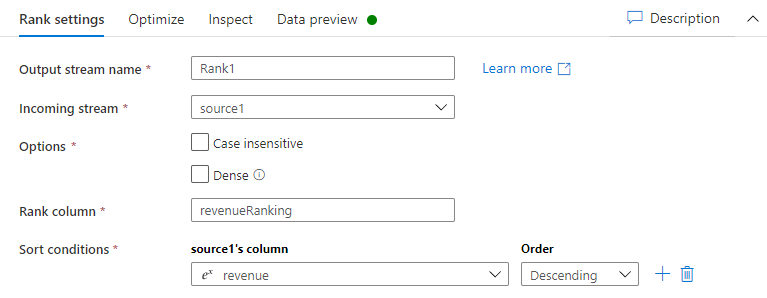
É possível ver os dados na guia versão preliminar dos dados, em que você encontrará a nova coluna revenueRank na posição mais à direita.
Definir a conta de armazenamento do Data Lake Storage Gen2 como um coletor
Por fim, você deve definir uma coletora para seu fluxo de dados. Siga estas instruções para colocar seus dados transformados como um arquivo de texto delimitado no data lake.
Selecione + no canto inferior direito da transformação anterior e, depois, pesquise e selecione Coletor.
Na guia Coletora, siga um destes procedimentos:
Nome do fluxo de saída: insira o nome desejado, como Sink1.
Fluxo de entrada: selecione o nome da fonte que você deseja. Nesse caso, o nome da fonte da etapa anterior.
Tipo de coletor: selecione DelimitedText.
Serviço vinculado: selecione seu contêiner de armazenamento do Data Lake Storage Gen2 que contém os dados que você exportou usando o serviço do Azure Synapse Link for Dataverse.
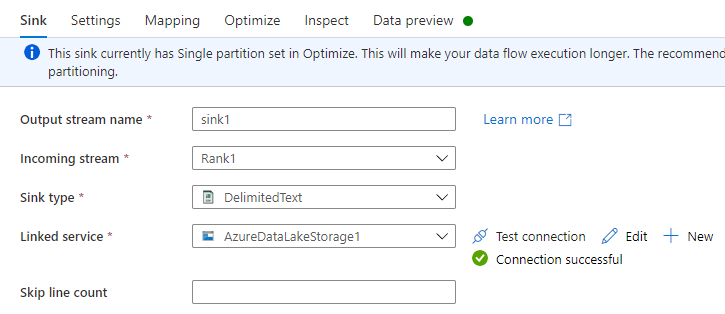
Na guia Configurações, faça o seguinte:
Caminho da pasta: insira o nome do contêiner na primeira caixa (Sistema de arquivos) ou opte por Procurar o nome do contêiner e selecione OK.
Opção de nome de arquivo: selecione saída para arquivo único.
Saída para arquivo único: insira um nome de arquivo, como ADFOutput
Deixe todas as outras configurações padrão.
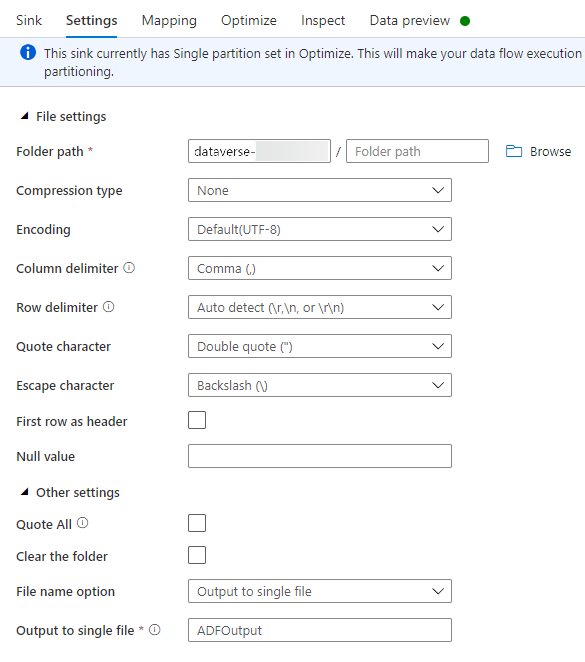
Na guia Otimizar, defina Opção de partição como Partição única.
É possível ver os dados na guia Versão preliminar dos dados.
Executar fluxo de dados
No painel esquerdo em Recursos do Factory, selecione + e Pipeline.

Em Atividades, selecione Mover e transformar e arraste Fluxo de dados para o espaço de trabalho.
Selecione Usar o fluxo de dados existente e selecione o fluxo de dados que você criou nas etapas anteriores.
Selecione Depurar na barra de comandos.
Deixe a execução de fluxo funcionar até que a exibição inferior mostre que foi concluída. Isso pode levar alguns minutos.
Vá para o contêiner de armazenamento de destino final e encontre o arquivo de dados da tabela transformada.
Consulte também
Configurar o Azure Synapse Link for Dataverse com o Azure Data Lake
Analisar os dados do Dataverse no Azure Data Lake Storage Gen2 com o Power BI
Observação
Você pode nos falar mais sobre suas preferências de idioma para documentação? Faça uma pesquisa rápida. (Observe que esta pesquisa está em inglês)
A pesquisa levará cerca de sete minutos. Nenhum dado pessoal é coletado (política de privacidade).