Criar um bot RAG no Teams
Os chatbots avançados do Q&A são aplicações avançadas criadas com a ajuda de Modelos de Linguagem Grande (LLMs). Os chatbots respondem a perguntas ao extrair informações de origens específicas através de um método chamado geração de Retrieval-Augmented (RAG). A arquitetura RAG tem dois fluxos de main:
Ingestão de dados: um pipeline para ingerir dados de uma origem e indexá-lo. Normalmente, isto acontece offline.
Obtenção e geração: a cadeia RAG, que utiliza a consulta do utilizador no tempo de execução e obtém os dados relevantes do índice, passa-a para o modelo.
O Microsoft Teams permite-lhe criar um bot de conversação com o RAG para criar uma experiência melhorada para maximizar a produtividade. O Teams Toolkit fornece uma série de modelos de aplicações prontos a utilizar na categoria Conversar com os Seus Dados que combina as funcionalidades da pesquisa de IA do Azure, do Microsoft 365 SharePoint e da API personalizada como origens de dados e LLMs diferentes para criar uma experiência de pesquisa de conversação no Teams.
Pré-requisitos
| Instalar | Para usar... |
|---|---|
| Visual Studio Code | Ambientes de compilação JavaScript, TypeScript ou Python. Utilize a versão mais recente. |
| Kit de ferramentas do Teams | O Microsoft Visual Studio Code extensão que cria um projeto estruturado para a sua aplicação. Utilize a versão mais recente. |
| Node.js | Ambiente de runtime do JavaScript de back-end. Para obter mais informações, veja Node.js tabela de compatibilidade de versões para o tipo de projeto. |
| Microsoft Teams | Microsoft Teams para colaborar com todas as pessoas com quem trabalha através de aplicações para chat, reuniões e chamadas num único local. |
| Azure OpenAI | Primeiro, crie a chave da API OpenAI para utilizar o Transformador Pré-preparado Gerador (GPT) da OpenAI. Se quiser alojar a sua aplicação ou aceder a recursos no Azure, tem de criar um serviço Azure OpenAI. |
Criar um novo projeto de chatbot de IA básico
Abra o Visual Studio Code.
Selecione o ícone Do Teams Toolkit
 na Barra de Atividade do Visual Studio Code.
na Barra de Atividade do Visual Studio Code.Selecione Criar uma Nova Aplicação.
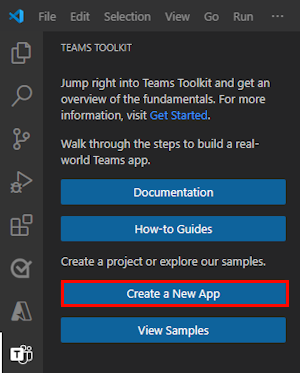
Selecione Agente do Motor Personalizado.
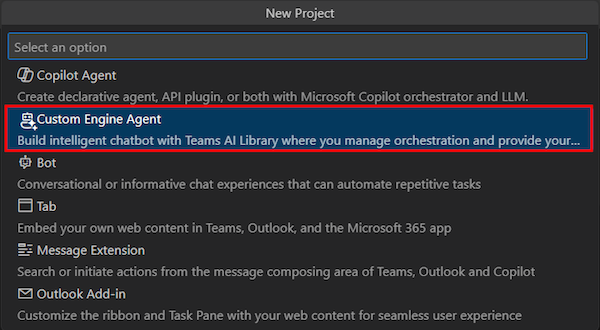
Selecione Conversar com os Seus Dados.
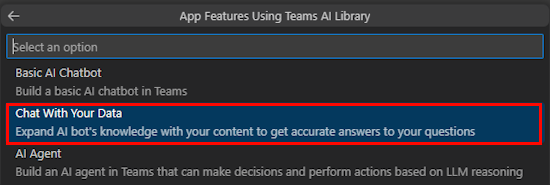
Selecione Personalizar.
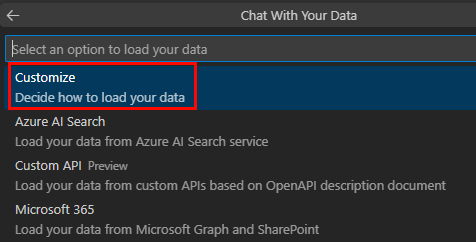
Selecione JavaScript.
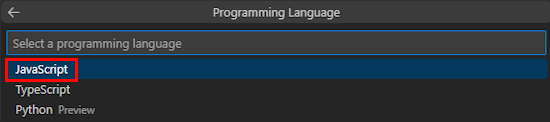
Selecione Azure OpenAI ou OpenAI.
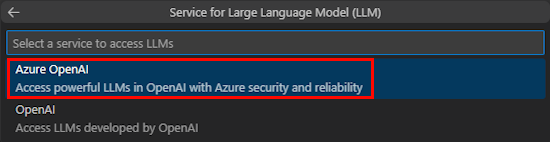
Introduza as credenciais do Azure OpenAI ou OpenAI com base no serviço que selecionar. Selecione Enter.

Selecione Pasta predefinida.

Para alterar a localização predefinida, siga estes passos:
- Selecione Procurar.
- Selecione a localização da área de trabalho do projeto.
- Selecione Selecionar Pasta.
Introduza um nome de aplicação para a sua aplicação e, em seguida, selecione a tecla Enter .

Criou com êxito a área de trabalho do projeto Chat With Your Data .
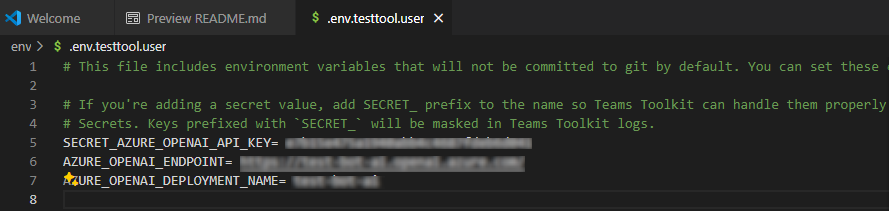
Em EXPLORADOR, aceda ao ficheiro env.env.testtool.user>.
Atualize os seguintes valores:
SECRET_AZURE_OPENAI_API_KEY=<your-key>AZURE_OPENAI_ENDPOINT=<your-endpoint>AZURE_OPENAI_DEPLOYMENT_NAME=<your-deployment>
Para depurar a sua aplicação, selecione a tecla F5 ou no painel esquerdo, selecione Executar e Depurar (Ctrl+Shift+D) e, em seguida, selecione Depurar na Ferramenta de Teste (Pré-visualização) na lista pendente.
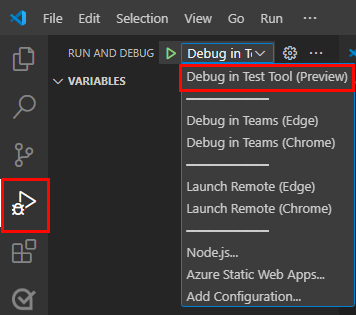
A Ferramenta de Teste abre o bot numa página Web.

Veja uma apresentação do código fonte da aplicação bot
| Pasta | Conteúdos |
|---|---|
.vscode |
Visual Studio Code ficheiros para depuração. |
appPackage |
Modelos para o manifesto da aplicação Teams. |
env |
Ficheiros de ambiente. |
infra |
Modelos para aprovisionar recursos do Azure. |
src |
O código fonte da aplicação. |
src/index.js |
Configura o servidor da aplicação de bot. |
src/adapter.js |
Configura o adaptador de bot. |
src/config.js |
Define as variáveis de ambiente. |
src/prompts/chat/skprompt.txt |
Define o pedido. |
src/prompts/chat/config.json |
Configura o pedido. |
src/app/app.js |
Processa lógicas de negócio para o bot RAG. |
src/app/myDataSource.js |
Define a origem de dados. |
src/data/*.md |
Origens de dados de texto não processado. |
teamsapp.yml |
Este é o main ficheiro de projeto do Teams Toolkit. O ficheiro de projeto define as propriedades e as definições da fase de configuração. |
teamsapp.local.yml |
Isto substitui teamsapp.yml por ações que permitem a execução local e a depuração. |
teamsapp.testtool.yml |
Isto substitui teamsapp.yml por ações que permitem a execução local e a depuração na Ferramenta de Teste de Aplicações do Teams. |
Cenários RAG para IA do Teams
No contexto de IA, as bases de dados de vetores são amplamente utilizadas como armazenamentos RAG, que armazenam dados de incorporação e fornecem pesquisa de vetor-semelhança. A biblioteca de IA do Teams fornece utilitários para ajudar a criar incorporações para as entradas fornecidas.
Dica
A biblioteca de IA do Teams não fornece a implementação da base de dados de vetor, pelo que tem de adicionar a sua própria lógica para processar as incorporações criadas.
// create OpenAIEmbeddings instance
const model = new OpenAIEmbeddings({ ... endpoint, apikey, model, ... });
// create embeddings for the given inputs
const embeddings = await model.createEmbeddings(model, inputs);
// your own logic to process embeddings
O diagrama seguinte mostra como a biblioteca de IA do Teams fornece funcionalidades para facilitar cada passo do processo de obtenção e geração:
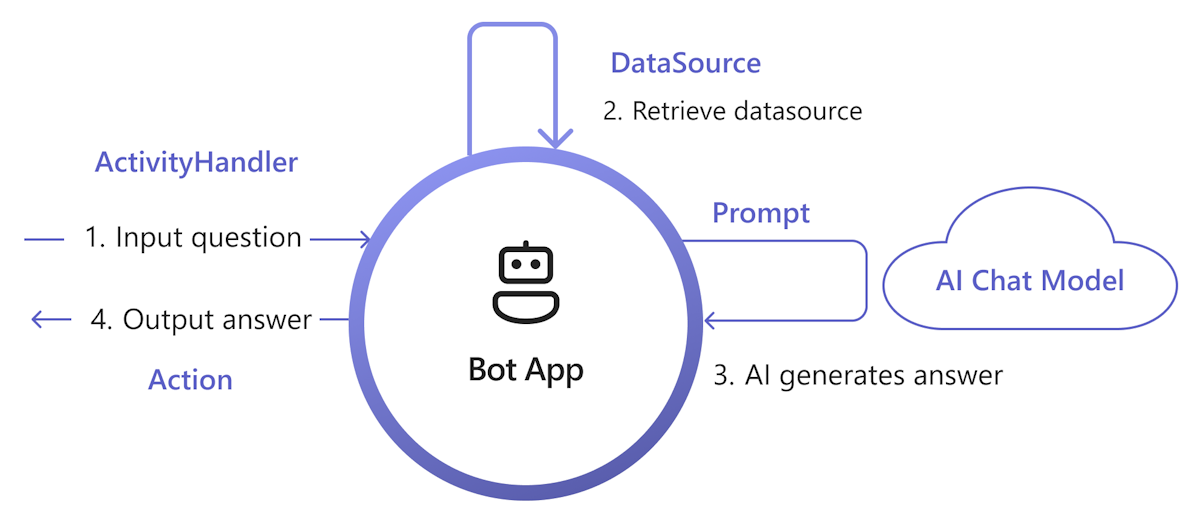
Processar entrada: a forma mais direta é transmitir a entrada do utilizador para a obtenção sem qualquer alteração. No entanto, se quiser personalizar a entrada antes da obtenção, pode adicionar um processador de atividade a determinadas atividades recebidas.
Obter DataSource: a biblioteca de IA do Teams fornece
DataSourceinterface para lhe permitir adicionar a sua própria lógica de obtenção. Tem de criar a sua própriaDataSourceinstância e a biblioteca de IA do Teams chama-a a pedido.class MyDataSource implements DataSource { /** * Name of the data source. */ public readonly name = "my-datasource"; /** * Renders the data source as a string of text. * @param context Turn context for the current turn of conversation with the user. * @param memory An interface for accessing state values. * @param tokenizer Tokenizer to use when rendering the data source. * @param maxTokens Maximum number of tokens allowed to be rendered. * @returns The text to inject into the prompt as a `RenderedPromptSection` object. */ renderData( context: TurnContext, memory: Memory, tokenizer: Tokenizer, maxTokens: number ): Promise<RenderedPromptSection<string>> { ... } }Chamar IA com aviso: no sistema de pedidos de IA do Teams, pode injetar facilmente uma
DataSourceao ajustar aaugmentation.data_sourcessecção de configuração. Esta ação liga a linha de comandos aoDataSourceorquestrador da biblioteca e para injetar oDataSourcetexto na linha de comandos final. Para obter mais informações, veja authorprompt. Por exemplo, no ficheiro doconfig.jsonpedido:{ "schema": 1.1, ... "augmentation": { "data_sources": { "my-datasource": 1200 } } }Resposta da criação: por predefinição, a biblioteca de IA do Teams responde à resposta gerada pela IA como uma mensagem de texto ao utilizador. Se quiser personalizar a resposta, pode substituir as ações SAY predefinidas ou chamar explicitamente o Modelo de IA para criar as suas respostas, por exemplo, com Cartões Ajustáveis.
Eis um conjunto mínimo de implementações para adicionar RAG à sua aplicação. Em geral, implementa DataSource para injetar o seu knowledge pedido, para que a IA possa gerar resposta com base no knowledge.
Criar
myDataSource.tsficheiro para implementarDataSourcea interface:export class MyDataSource implements DataSource { public readonly name = "my-datasource"; public async renderData( context: TurnContext, memory: Memory, tokenizer: Tokenizer, maxTokens: number ): Promise<RenderedPromptSection<string>> { const input = memory.getValue('temp.input') as string; let knowledge = "There's no knowledge found."; // hard-code knowledge if (input?.includes("shuttle bus")) { knowledge = "Company's shuttle bus may be 15 minutes late on rainy days."; } else if (input?.includes("cafe")) { knowledge = "The Cafe's available time is 9:00 to 17:00 on working days and 10:00 to 16:00 on weekends and holidays." } return { output: knowledge, length: knowledge.length, tooLong: false } } }Registe o
DataSourceficheiro emapp.ts:// Register your data source to prompt manager planner.prompts.addDataSource(new MyDataSource());
Crie o
prompts/qa/skprompt.txtficheiro e adicione o seguinte texto:The following is a conversation with an AI assistant. The assistant is helpful, creative, clever, and very friendly to answer user's question. Base your answer off the text below:Crie o
prompts/qa/config.jsonficheiro e adicione o seguinte código para se ligar à origem de dados:{ "schema": 1.1, "description": "Chat with QA Assistant", "type": "completion", "completion": { "model": "gpt-35-turbo", "completion_type": "chat", "include_history": true, "include_input": true, "max_input_tokens": 2800, "max_tokens": 1000, "temperature": 0.9, "top_p": 0.0, "presence_penalty": 0.6, "frequency_penalty": 0.0, "stop_sequences": [] }, "augmentation": { "data_sources": { "my-datasource": 1200 } } }
Selecionar origens de dados
Nos cenários Chat With Your Data ou RAG, o Teams Toolkit fornece os seguintes tipos de origens de dados:
Personalizar: permite-lhe controlar totalmente a ingestão de dados para criar o seu próprio índice de vetor e utilizá-lo como origem de dados. Para obter mais informações, veja Build your own data ingestion (Criar a sua própria ingestão de dados).
Também pode utilizar a Extensão de Base de Dados de Vetores do Azure Cosmos DB ou a Extensão de vetor do Servidor PostgreSQL do Azure como bases de dados de vetores ou a API de Pesquisa na Web do Bing para obter o conteúdo Web mais recente para implementar qualquer instância de origem de dados para se ligar à sua própria origem de dados.
Pesquisa de IA do Azure: fornece um exemplo para adicionar os seus documentos ao Serviço de Pesquisa de IA do Azure e, em seguida, utiliza o índice de pesquisa como origem de dados.
API Personalizada: permite que o chatbot invoque a API definida no documento de descrição de OpenAPI para obter dados de domínio do serviço de API.
Microsoft Graph e SharePoint: fornece um exemplo para utilizar conteúdos do Microsoft 365 da API de Pesquisa do Microsoft Graph como origem de dados.
Criar a sua própria ingestão de dados
Para criar a ingestão de dados, siga estes passos:
Carregar os documentos de origem: certifique-se de que o documento tem um texto significativo, uma vez que o modelo de incorporação utiliza apenas texto como entrada.
Dividir em segmentos: certifique-se de que divide o documento para evitar falhas de chamadas à API, uma vez que o modelo de incorporação tem uma limitação de token de entrada.
Chamar modelo de incorporação: chame as APIs do modelo de incorporação para criar incorporações para as entradas especificadas.
Armazenar incorporações: armazene as incorporações criadas numa base de dados de vetor. Inclua também metadados úteis e conteúdo não processado para referência adicional.
Código de exemplo
loader.ts: texto simples como entrada de origem.import * as fs from "node:fs"; export function loadTextFile(path: string): string { return fs.readFileSync(path, "utf-8"); }splitter.ts: divida texto em segmentos, com uma sobreposição.// split words by delimiters. const delimiters = [" ", "\t", "\r", "\n"]; export function split(content: string, length: number, overlap: number): Array<string> { const results = new Array<string>(); let cursor = 0, curChunk = 0; results.push(""); while(cursor < content.length) { const curChar = content[cursor]; if (delimiters.includes(curChar)) { // check chunk length while (curChunk < results.length && results[curChunk].length >= length) { curChunk ++; } for (let i = curChunk; i < results.length; i++) { results[i] += curChar; } if (results[results.length - 1].length >= length - overlap) { results.push(""); } } else { // append for (let i = curChunk; i < results.length; i++) { results[i] += curChar; } } cursor ++; } while (curChunk < results.length - 1) { results.pop(); } return results; }embeddings.ts: utilize a bibliotecaOpenAIEmbeddingsde IA do Teams para criar incorporações.import { OpenAIEmbeddings } from "@microsoft/teams-ai"; const embeddingClient = new OpenAIEmbeddings({ azureApiKey: "<your-aoai-key>", azureEndpoint: "<your-aoai-endpoint>", azureDeployment: "<your-embedding-deployment, e.g., text-embedding-ada-002>" }); export async function createEmbeddings(content: string): Promise<number[]> { const response = await embeddingClient.createEmbeddings(content); return response.output[0]; }searchIndex.ts: Criar Índice de Pesquisa de IA do Azure.import { SearchIndexClient, AzureKeyCredential, SearchIndex } from "@azure/search-documents"; const endpoint = "<your-search-endpoint>"; const apiKey = "<your-search-key>"; const indexName = "<your-index-name>"; const indexDef: SearchIndex = { name: indexName, fields: [ { type: "Edm.String", name: "id", key: true, }, { type: "Edm.String", name: "content", searchable: true, }, { type: "Edm.String", name: "filepath", searchable: true, filterable: true, }, { type: "Collection(Edm.Single)", name: "contentVector", searchable: true, vectorSearchDimensions: 1536, vectorSearchProfileName: "default" } ], vectorSearch: { algorithms: [{ name: "default", kind: "hnsw" }], profiles: [{ name: "default", algorithmConfigurationName: "default" }] }, semanticSearch: { defaultConfigurationName: "default", configurations: [{ name: "default", prioritizedFields: { contentFields: [{ name: "content" }] } }] } }; export async function createNewIndex(): Promise<void> { const client = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey)); await client.createIndex(indexDef); }searchIndexer.ts: carregue incorporações criadas e outros campos para o Índice de Pesquisa de IA do Azure.import { AzureKeyCredential, SearchClient } from "@azure/search-documents"; export interface Doc { id: string, content: string, filepath: string, contentVector: number[] } const endpoint = "<your-search-endpoint>"; const apiKey = "<your-search-key>"; const indexName = "<your-index-name>"; const searchClient: SearchClient<Doc> = new SearchClient<Doc>(endpoint, indexName, new AzureKeyCredential(apiKey)); export async function indexDoc(doc: Doc): Promise<boolean> { const response = await searchClient.mergeOrUploadDocuments([doc]); return response.results.every((result) => result.succeeded); }index.ts: orquestrar os componentes acima.import { createEmbeddings } from "./embeddings"; import { loadTextFile } from "./loader"; import { createNewIndex } from "./searchIndex"; import { indexDoc } from "./searchIndexer"; import { split } from "./splitter"; async function main() { // Only need to call once await createNewIndex(); // local files as source input const files = [`${__dirname}/data/A.md`, `${__dirname}/data/A.md`]; for (const file of files) { // load file const fullContent = loadTextFile(file); // split into chunks const contents = split(fullContent, 1000, 100); let partIndex = 0; for (const content of contents) { partIndex ++; // create embeddings const embeddings = await createEmbeddings(content); // upload to index await indexDoc({ id: `${file.replace(/[^a-z0-9]/ig, "")}___${partIndex}`, content: content, filepath: file, contentVector: embeddings, }); } } } main().then().finally();
Azure AI Search como origem de dados
Nesta secção, irá aprender a:
- Adicione o seu documento à Pesquisa de IA do Azure através do Serviço OpenAI do Azure.
- Utilize o índice da Pesquisa de IA do Azure como origem de dados na aplicação RAG.
Adicionar documento à Pesquisa de IA do Azure
Observação
Esta abordagem cria uma API de chat ponto a ponto chamada modelo de IA. Também pode utilizar o índice criado anteriormente como uma origem de dados e utilizar a biblioteca de IA do Teams para personalizar a obtenção e o pedido.
Pode ingerir os seus documentos de conhecimento no Serviço de Pesquisa de IA do Azure e criar um índice de vetor com o Azure OpenAI nos seus dados. Após a ingestão, pode utilizar o índice como uma origem de dados.
Prepare os seus dados no Armazenamento de Blobs do Azure.
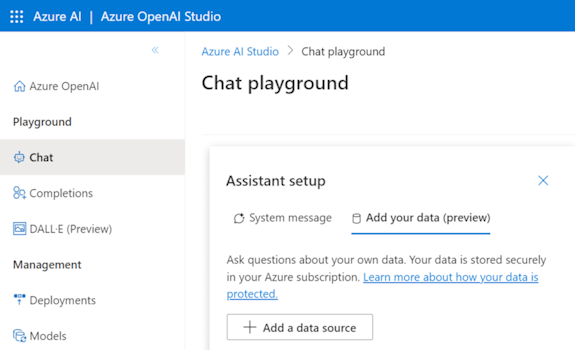
No Azure OpenAI Studio, selecione Adicionar uma origem de dados.
Atualize os campos necessários.
Selecione Avançar.
É apresentada a página Gestão de dados.
Atualize os campos necessários.
Selecione Avançar.
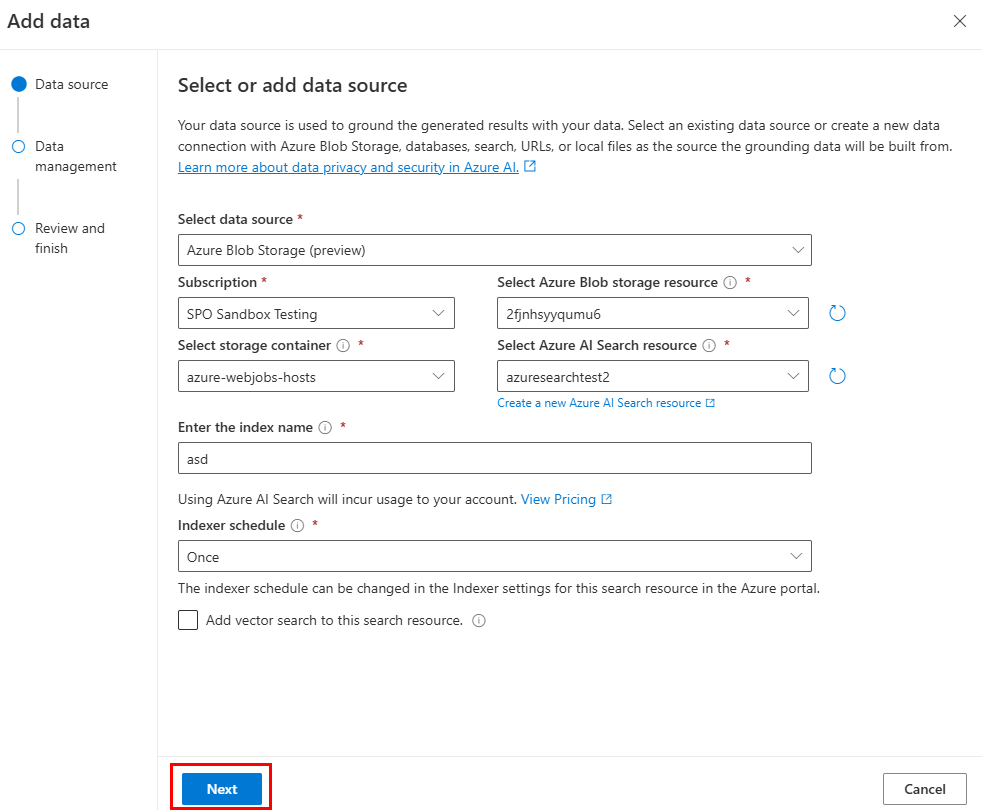
Atualize os campos necessários. Selecione Avançar.
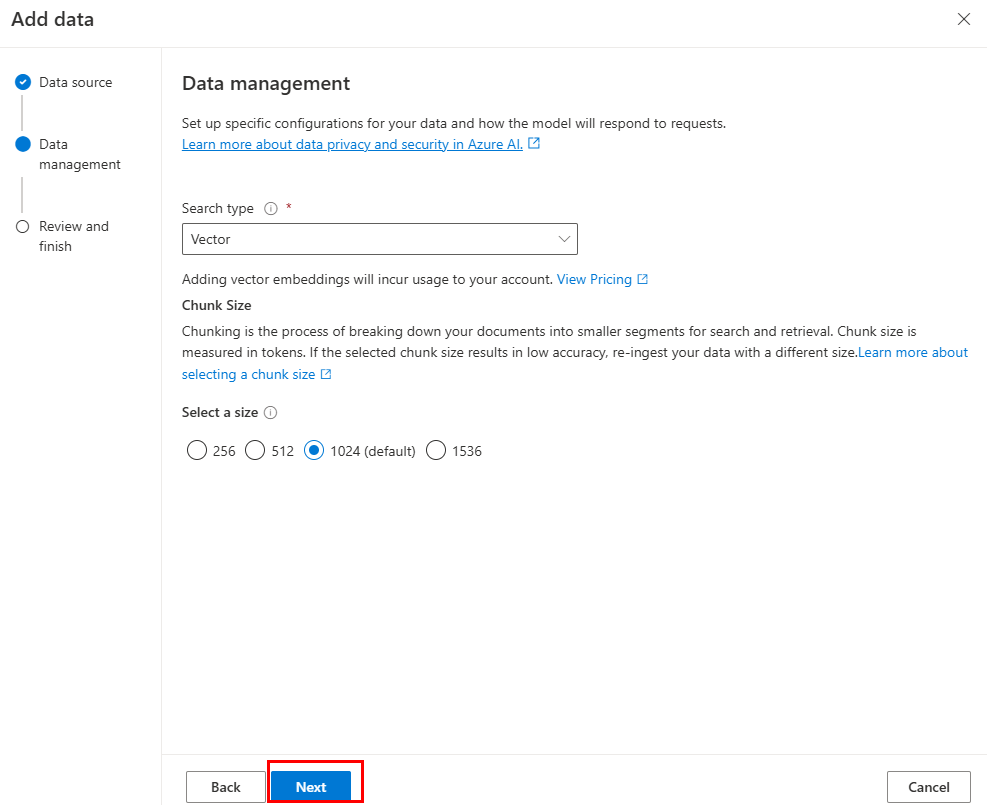
Selecione Guardar e fechar.
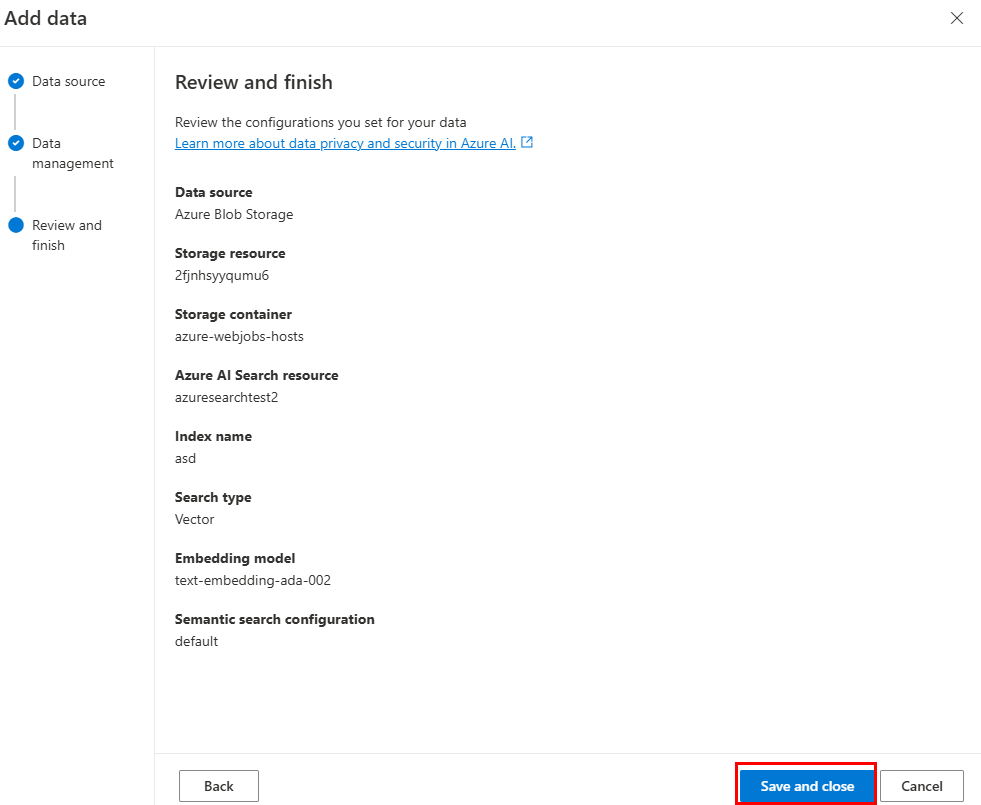
Utilizar a origem de dados do índice do Azure AI Search
Depois de ingerir dados no Azure AI Search, pode implementar os seus próprios DataSource dados para obter dados do índice de pesquisa.
const { AzureKeyCredential, SearchClient } = require("@azure/search-documents");
const { DataSource, Memory, OpenAIEmbeddings, Tokenizer } = require("@microsoft/teams-ai");
const { TurnContext } = require("botbuilder");
// Define the interface for document
class Doc {
constructor(id, content, filepath) {
this.id = id;
this.content = content; // searchable
this.filepath = filepath;
}
}
// Azure OpenAI configuration
const aoaiEndpoint = "<your-aoai-endpoint>";
const aoaiApiKey = "<your-aoai-key>";
const aoaiDeployment = "<your-embedding-deployment, e.g., text-embedding-ada-002>";
// Azure AI Search configuration
const searchEndpoint = "<your-search-endpoint>";
const searchApiKey = "<your-search-apikey>";
const searchIndexName = "<your-index-name>";
// Define MyDataSource class implementing DataSource interface
class MyDataSource extends DataSource {
constructor() {
super();
this.name = "my-datasource";
this.embeddingClient = new OpenAIEmbeddings({
azureEndpoint: aoaiEndpoint,
azureApiKey: aoaiApiKey,
azureDeployment: aoaiDeployment
});
this.searchClient = new SearchClient(searchEndpoint, searchIndexName, new AzureKeyCredential(searchApiKey));
}
async renderData(context, memory, tokenizer, maxTokens) {
// use user input as query
const input = memory.getValue("temp.input");
// generate embeddings
const embeddings = (await this.embeddingClient.createEmbeddings(input)).output[0];
// query Azure AI Search
const response = await this.searchClient.search(input, {
select: [ "id", "content", "filepath" ],
searchFields: ["rawContent"],
vectorSearchOptions: {
queries: [{
kind: "vector",
fields: [ "contentVector" ],
vector: embeddings,
kNearestNeighborsCount: 3
}]
},
queryType: "semantic",
top: 3,
semanticSearchOptions: {
// your semantic configuration name
configurationName: "default",
}
});
// Add documents until you run out of tokens
let length = 0, output = '';
for await (const result of response.results) {
// Start a new doc
let doc = `${result.document.content}\n\n`;
let docLength = tokenizer.encode(doc).length;
const remainingTokens = maxTokens - (length + docLength);
if (remainingTokens <= 0) {
break;
}
// Append doc to output
output += doc;
length += docLength;
}
return { output, length, tooLong: length > maxTokens };
}
}
Adicionar mais API para a API Personalizada como origem de dados
Siga estes passos para expandir o agente do motor personalizado a partir do modelo de API Personalizada com mais APIs.
Atualizar
./appPackage/apiSpecificationFile/openapi.*.Copie a parte correspondente da API que pretende adicionar a partir da sua especificação e acrescente a
./appPackage/apiSpecificationFile/openapi.*.Atualizar
./src/prompts/chat/actions.json.Atualize as informações e propriedades necessárias para o caminho, a consulta e o corpo da API no seguinte objeto:
{ "name": "${{YOUR-API-NAME}}", "description": "${{YOUR-API-DESCRIPTION}}", "parameters": { "type": "object", "properties": { "query": { "type": "object", "properties": { "${{YOUR-PROPERTY-NAME}}": { "type": "${{YOUR-PROPERTY-TYPE}}", "description": "${{YOUR-PROPERTY-DESCRIPTION}}", } // You can add more query properties here } }, "path": { // Same as query properties }, "body": { // Same as query properties } } } }Atualizar
./src/adaptiveCards.Crie um novo ficheiro com o nome
${{YOUR-API-NAME}}.jsone preencha o Cartão Ajustável para a resposta da API da sua API.Atualize o
./src/app/app.jsficheiro.Adicione o seguinte código antes de
module.exports = app;:app.ai.action(${{YOUR-API-NAME}}, async (context: TurnContext, state: ApplicationTurnState, parameter: any) => { const client = await api.getClient(); const path = client.paths[${{YOUR-API-PATH}}]; if (path && path.${{YOUR-API-METHOD}}) { const result = await path.${{YOUR-API-METHOD}}(parameter.path, parameter.body, { params: parameter.query, }); const card = generateAdaptiveCard("../adaptiveCards/${{YOUR-API-NAME}}.json", result); await context.sendActivity({ attachments: [card] }); } else { await context.sendActivity("no result"); } return "result"; });
Microsoft 365 como origem de dados
Saiba como utilizar a API de Pesquisa do Microsoft Graph para consultar conteúdos do Microsoft 365 como uma origem de dados para a aplicação RAG. Para saber mais sobre a API de Pesquisa do Microsoft Graph, pode consultar utilizar a API de Pesquisa da Microsoft para procurar conteúdos do OneDrive e do SharePoint.
Pré-requisito: tem de criar um cliente API do Graph e conceder-lhe o Files.Read.All âmbito de permissão para aceder a ficheiros, pastas, páginas e notícias do SharePoint e do OneDrive.
Ingestão de dados
A API de Pesquisa do Microsoft Graph, que pode pesquisar conteúdos do SharePoint, está disponível. Por conseguinte, só tem de garantir que o seu documento é carregado para o SharePoint ou OneDrive, sem necessidade de ingestão de dados extra.
Observação
O servidor do SharePoint indexa um ficheiro apenas se a respetiva extensão de ficheiro estiver listada na página gerir tipos de ficheiro. Para obter uma lista completa das extensões de ficheiro suportadas, veja as extensões de nome de ficheiro indexadas predefinidas e os tipos de ficheiro analisados no servidor sharePoint e no SharePoint no Microsoft 365.
Implementação da origem de dados
Um exemplo de pesquisa dos ficheiros de texto no SharePoint e no OneDrive é o seguinte:
import {
DataSource,
Memory,
RenderedPromptSection,
Tokenizer,
} from "@microsoft/teams-ai";
import { TurnContext } from "botbuilder";
import { Client, ResponseType } from "@microsoft/microsoft-graph-client";
export class GraphApiSearchDataSource implements DataSource {
public readonly name = "my-datasource";
public readonly description =
"Searches the graph for documents related to the input";
public client: Client;
constructor(client: Client) {
this.client = client;
}
public async renderData(
context: TurnContext,
memory: Memory,
tokenizer: Tokenizer,
maxTokens: number
): Promise<RenderedPromptSection<string>> {
const input = memory.getValue("temp.input") as string;
const contentResults = [];
const response = await this.client.api("/search/query").post({
requests: [
{
entityTypes: ["driveItem"],
query: {
// Search for markdown files in the user's OneDrive and SharePoint
// The supported file types are listed here:
// https://learn.microsoft.com/sharepoint/technical-reference/default-crawled-file-name-extensions-and-parsed-file-types
queryString: `${input} filetype:txt`,
},
// This parameter is required only when searching with application permissions
// https://learn.microsoft.com/graph/search-concept-searchall
// region: "US",
},
],
});
for (const value of response?.value ?? []) {
for (const hitsContainer of value?.hitsContainers ?? []) {
contentResults.push(...(hitsContainer?.hits ?? []));
}
}
// Add documents until you run out of tokens
let length = 0,
output = "";
for (const result of contentResults) {
const rawContent = await this.downloadSharepointFile(
result.resource.webUrl
);
if (!rawContent) {
continue;
}
let doc = `${rawContent}\n\n`;
let docLength = tokenizer.encode(doc).length;
const remainingTokens = maxTokens - (length + docLength);
if (remainingTokens <= 0) {
break;
}
// Append do to output
output += doc;
length += docLength;
}
return { output, length, tooLong: length > maxTokens };
}
// Download the file from SharePoint
// https://docs.microsoft.com/en-us/graph/api/driveitem-get-content
private async downloadSharepointFile(
contentUrl: string
): Promise<string | undefined> {
const encodedUrl = this.encodeSharepointContentUrl(contentUrl);
const fileContentResponse = await this.client
.api(`/shares/${encodedUrl}/driveItem/content`)
.responseType(ResponseType.TEXT)
.get();
return fileContentResponse;
}
private encodeSharepointContentUrl(webUrl: string): string {
const byteData = Buffer.from(webUrl, "utf-8");
const base64String = byteData.toString("base64");
return (
"u!" + base64String.replace("=", "").replace("/", "_").replace("+", "_")
);
}
}