Tutorial: Usar funções de agregação
Aplica-se a: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
As funções de agregação permitem agrupar e combinar dados de várias linhas em um valor de resumo. O valor de resumo depende da função escolhida, por exemplo, um valor de contagem, máximo ou médio.
Neste tutorial, você aprenderá como:
Os exemplos neste tutorial usam a StormEvents tabela, que está disponível publicamente no cluster de ajuda. Para explorar com seus próprios dados, crie seu próprio cluster gratuito.
Os exemplos neste tutorial usam a StormEvents tabela, que está disponível publicamente nos dados de exemplo da análise meteorológica.
Este tutorial se baseia na base do primeiro tutorial, Aprenda operadores comuns.
Pré-requisitos
Para executar as consultas a seguir, você precisa de um ambiente de consulta com acesso aos dados de exemplo. Você pode usar um dos itens a seguir:
- Uma conta da Microsoft ou identidade de usuário do Microsoft Entra para entrar no cluster de ajuda
- Uma conta da Microsoft ou identidade de usuário do Microsoft Entra
- Um espaço de trabalho do Fabric com uma capacidade habilitada para o Microsoft Fabric
Usar o operador summarize
O operador summarize é essencial para realizar agregações em seus dados. O summarize operador agrupa by linhas com base na cláusula e, em seguida, usa a função de agregação fornecida para combinar cada grupo em uma única linha.
Encontre o número de eventos por estado usando summarize com a função de agregação de contagem .
StormEvents
| summarize TotalStorms = count() by State
Saída
| Estado | Tempestades totais |
|---|---|
| TEXAS | 4701 |
| KANSAS | 3166 |
| IOWA | 2337 |
| ILLINOIS | 2022 |
| MISSOURI | 2016 |
| ... | ... |
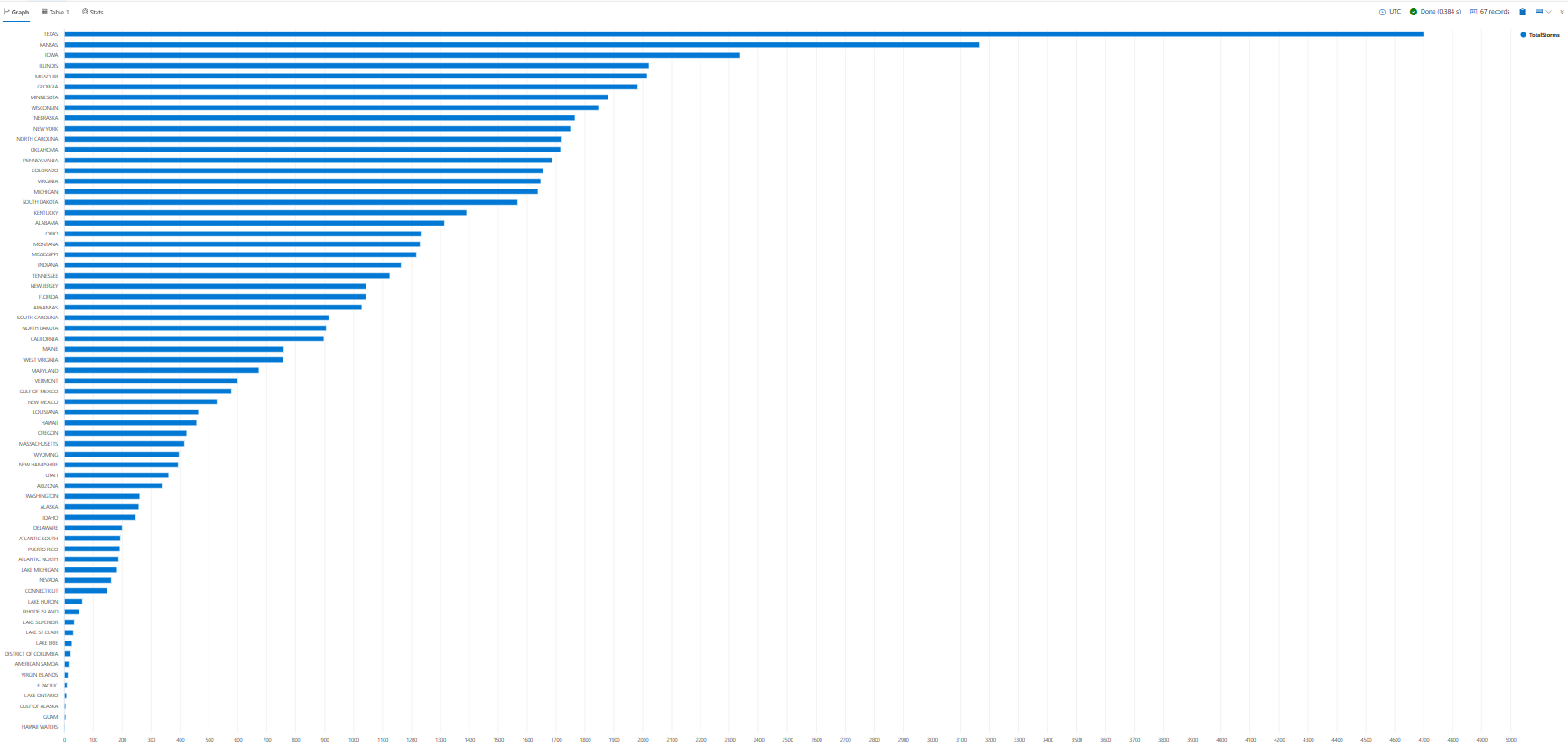
Visualizar resultados da consulta
A visualização dos resultados da consulta em um gráfico pode ajudá-lo a identificar padrões, tendências e discrepâncias em seus dados. Você pode fazer isso com o operador de renderização .
Ao longo do tutorial, você verá exemplos de como usar render para exibir seus resultados. Por enquanto, vamos usar render para ver os resultados da consulta anterior em um gráfico de barras.
StormEvents
| summarize TotalStorms = count() by State
| render barchart
Contar linhas condicionalmente
Ao analisar seus dados, use countif() para contar linhas com base em uma condição específica para entender quantas linhas atendem aos critérios fornecidos.
A consulta a seguir usa countif() a contagem de tempestades que causaram danos. Em seguida, a consulta usa o top operador para filtrar os resultados e exibir os estados com a maior quantidade de danos à cultura causados por tempestades.
StormEvents
| summarize StormsWithCropDamage = countif(DamageCrops > 0) by State
| top 5 by StormsWithCropDamage
Saída
| Estado | TempestadesComCropDamage |
|---|---|
| IOWA | 359 |
| NEBRASKA | 201 |
| MISSISSIPI | 105 |
| NORTH CAROLINA | 82 |
| MISSOURI | 78 |
Agrupar dados em compartimentos
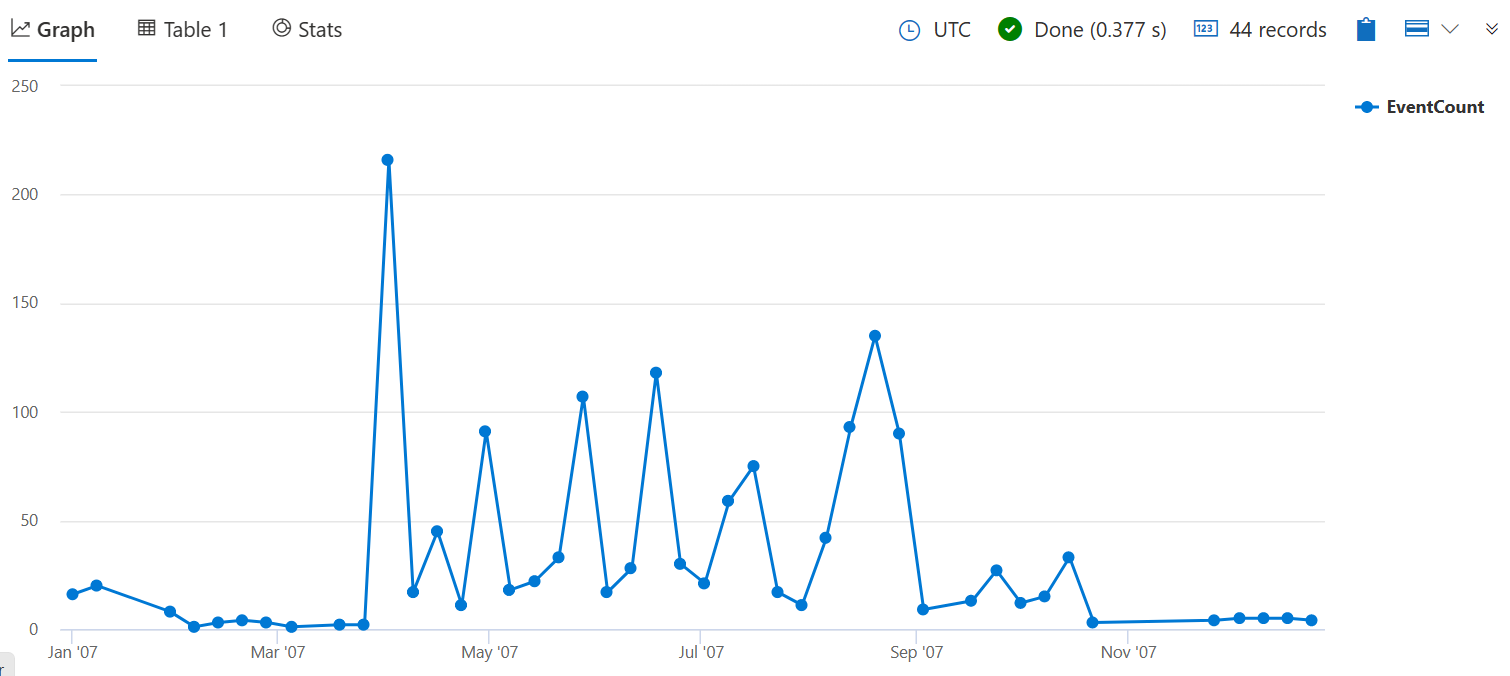
Para agregar por valores numéricos ou de tempo, primeiro você deve agrupar os dados em compartimentos usando a função bin( ). O uso bin() pode ajudá-lo a entender como os valores são distribuídos dentro de um determinado intervalo e fazer comparações entre diferentes períodos.
A consulta a seguir conta o número de tempestades que causaram danos à cultura em cada semana de 2007. O 7d argumento representa uma semana, pois a função requer um valor de intervalo de tempo válido.
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize EventCount = count() by bin(StartTime, 7d)
Saída
| StartTime | EventCount |
|---|---|
| 2007-01-01T00:00:00Z | 16 |
| 2007-01-08T00:00:00Z | 20 |
| 2007-01-29T00:00:00Z | 8 |
| 2007-02-05T00:00:00Z | 1 |
| 2007-02-12T00:00:00Z | 3 |
| ... | ... |
Adicione | render timechart ao final da consulta para visualizar os resultados.
Observação
bin() é semelhante à floor() função em outras linguagens de programação. Ele reduz cada valor ao múltiplo mais próximo do módulo que você fornece e permite summarize atribuir as linhas aos grupos.
Calcule o mínimo, máximo, médio e soma
Para saber mais sobre os tipos de tempestades que causam danos à cultura, calcule os danos à colheita min(), max() e avg() para cada tipo de evento e classifique o resultado pelo dano médio.
Observe que você pode usar várias funções de agregação em um único summarize operador para produzir várias colunas computadas.
StormEvents
| where DamageCrops > 0
| summarize
MaxCropDamage=max(DamageCrops),
MinCropDamage=min(DamageCrops),
AvgCropDamage=avg(DamageCrops)
by EventType
| sort by AvgCropDamage
Saída
| EventType | MaxCropDamage | MinCropDamage | Dano médio |
|---|---|---|---|
| Geada/Frio | 568600000 | 3000 | 9106087.5954198465 |
| Wildfire | 21000000 | 10000 | 7268333.333333333 |
| Seca | 700000000 | 2000 | 6763977.8761061952 |
| Saturação | 500000000 | 1000 | 4844925.23364486 |
| Thunderstorm Wind | 22000000 | 100 | 920328.36538461538 |
| ... | ... | ... | ... |
Os resultados da consulta anterior indicam que os eventos de geada/congelamento resultaram na maioria dos danos à cultura, em média. No entanto, a consulta bin() mostrou que os eventos com danos às culturas ocorreram principalmente nos meses de verão.
Use sum() para verificar o número total de culturas danificadas em vez da quantidade de eventos que causaram algum dano, como feito na count() consulta bin() anterior.
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize CropDamage = sum(DamageCrops) by bin(StartTime, 7d)
| render timechart
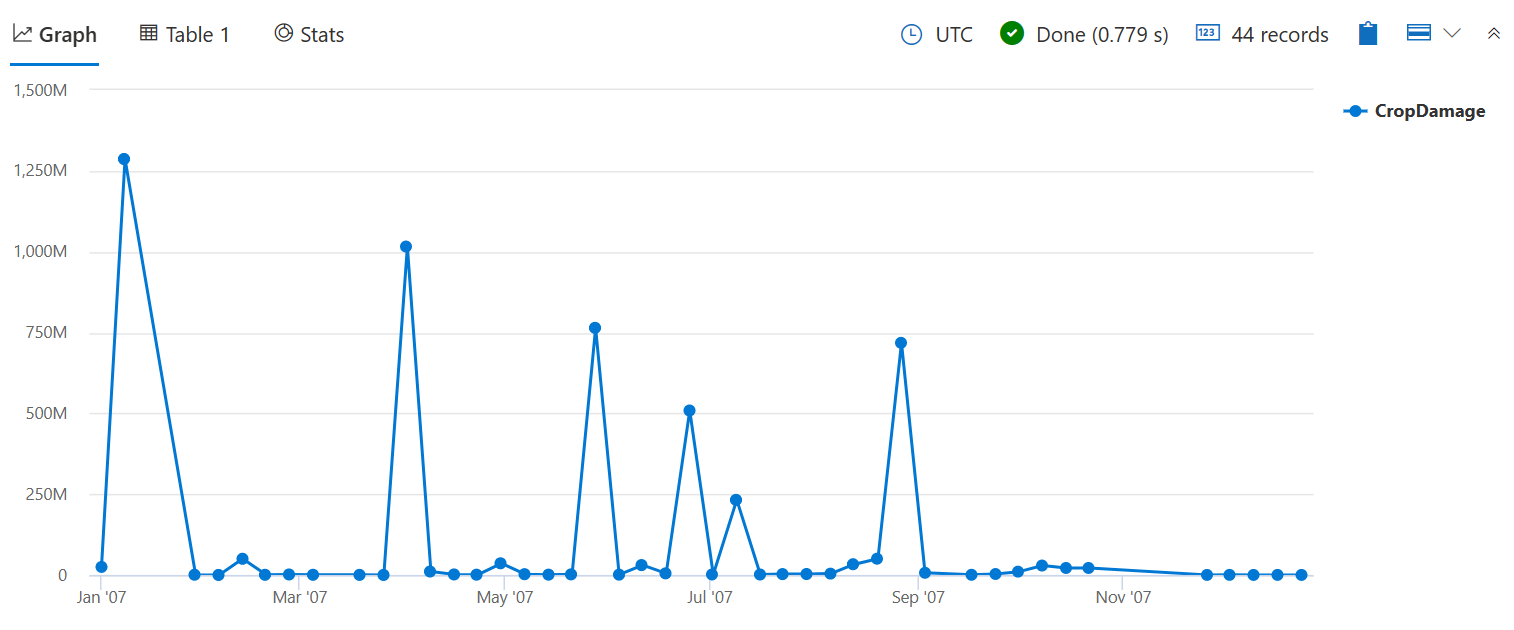
Agora você pode ver um pico nos danos às colheitas em janeiro, que provavelmente foi devido ao Frost / Freeze.
Dica
Use minif(), maxif(), avgif() e sumif() para realizar agregações condicionais, como fizemos quando na seção de contagem condicional de linhas .
Calcular porcentagens
O cálculo de porcentagens pode ajudá-lo a entender a distribuição e a proporção de diferentes valores em seus dados. Esta seção aborda dois métodos comuns para calcular porcentagens com a KQL (Linguagem de Consulta Kusto).
Calcular porcentagem com base em duas colunas
Use count() e countif para encontrar a porcentagem de eventos de tempestade que causaram danos às culturas em cada estado. Primeiro, conte o número total de tempestades em cada estado. Em seguida, conte o número de tempestades que causaram danos às plantações em cada estado.
Em seguida, use extend para calcular a porcentagem entre as duas colunas dividindo o número de tempestades com danos à cultura pelo número total de tempestades e multiplicando por 100.
Para garantir que você obtenha um resultado decimal, use a função todouble() para converter pelo menos um dos valores de contagem de inteiros em um double antes de realizar a divisão.
StormEvents
| summarize
TotalStormsInState = count(),
StormsWithCropDamage = countif(DamageCrops > 0)
by State
| extend PercentWithCropDamage =
round((todouble(StormsWithCropDamage) / TotalStormsInState * 100), 2)
| sort by StormsWithCropDamage
Saída
| Estado | TotalStormsInState | TempestadesComCropDamage | PercentWithCropDamage |
|---|---|---|---|
| IOWA | 2337 | 359 | 15.36 |
| NEBRASKA | 1766 | 201 | 11.38 |
| MISSISSIPI | 1218 | 105 | 8,62 |
| NORTH CAROLINA | 1721 | 82 | 4.76 |
| MISSOURI | 2016 | 78 | 3.87 |
| ... | ... | ... | ... |
Observação
Ao calcular porcentagens, converta pelo menos um dos valores inteiros na divisão com todouble() ou toreal(). Isso garantirá que você não obtenha resultados truncados devido à divisão de inteiros. Para obter mais informações, consulte Regras de tipo para operações aritméticas.
Calcular porcentagem com base no tamanho da tabela
Para comparar o número de tempestades por tipo de evento com o número total de tempestades no banco de dados, primeiro salve o número total de tempestades no banco de dados como uma variável. As instruções let são usadas para definir variáveis em uma consulta.
Como as instruções de expressão tabular retornam resultados tabulares, use a função toscalar() para converter o count() resultado tabular da função em um valor escalar. Em seguida, o valor numérico pode ser usado no cálculo da porcentagem.
let TotalStorms = toscalar(StormEvents | summarize count());
StormEvents
| summarize EventCount = count() by EventType
| project EventType, EventCount, Percentage = todouble(EventCount) / TotalStorms * 100.0
Saída
| EventType | EventCount | Percentual |
|---|---|---|
| Thunderstorm Wind | 13015 | 22.034673077574237 |
| Granizo | 12711 | 21.519994582331627 |
| Saturação de Flash | 3688 | 6.2438627975485055 |
| Seca | 3616 | 6.1219652592015716 |
| Clima de Inverno | 3349 | 5.669928554498358 |
| ... | ... | ... |
Extrair valores exclusivos
Use make_set() para transformar uma seleção de linhas em uma tabela em uma matriz de valores exclusivos.
A consulta a seguir usa make_set() para criar uma matriz dos tipos de evento que causam mortes em cada estado. A tabela resultante é então classificada pelo número de tipos de tempestade em cada matriz.
StormEvents
| where DeathsDirect > 0 or DeathsIndirect > 0
| summarize StormTypesWithDeaths = make_set(EventType) by State
| project State, StormTypesWithDeaths
| sort by array_length(StormTypesWithDeaths)
Saída
| Estado | Tipos de TempestadeComMortes |
|---|---|
| CALIFÓRNIA | ["Vento de Tempestade","Surf Alto","Frio/Vento Frio","Vento Forte","Corrente de Retorno","Calor","Calor Excessivo","Incêndio","Tempestade de Poeira","Maré Baixa Astronômica","Neblina Densa","Clima de Inverno"] |
| TEXAS | ["Inundação Repentina","Vento Tempestuoso","Tornado","Relâmpago","Inundação","Tempestade de Gelo","Clima de Inverno","Corrente de Retorno","Calor Excessivo","Neblina Densa","Furacão (Tufão)","Frio/Vento Frio"] |
| OKLAHOMA | ["Inundação Repentina","Tornado","Frio/Vento Frio","Tempestade de Inverno","Neve Pesada","Calor Excessivo","Calor","Tempestade de Gelo","Clima de Inverno","Neblina Densa"] |
| NEW YORK | ["Inundação","Relâmpago","Tempestade de vento","Inundação repentina","Clima de inverno","Tempestade de gelo","Frio extremo","Tempestade de inverno","Neve pesada"] |
| KANSAS | ["Tempestade de vento","Chuva forte","Tornado","Inundação","Inundação repentina","Relâmpago","Neve pesada","Clima de inverno","Nevasca"] |
| ... | ... |
Dados do bucket por condição
A função case() agrupa dados em buckets com base em condições especificadas. A função retorna a expressão de resultado correspondente para o primeiro predicado satisfeito ou a expressão else final se nenhum dos predicados for atendido.
Este exemplo agrupa os estados com base no número de ferimentos relacionados à tempestade que seus cidadãos sofreram.
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| sort by State asc
Saída
| Estado | Contagem de lesões | Balde de Lesões |
|---|---|---|
| ALABAMA | 494 | Grande |
| ALASCA | 0 | Sem ferimentos |
| AMERICAN SAMOA | 0 | Sem ferimentos |
| ARIZONA | 6 | Pequeno |
| ARKANSAS | 54 | Grande |
| ATLANTIC NORTH | 15 | Médio |
| ... | ... | ... |
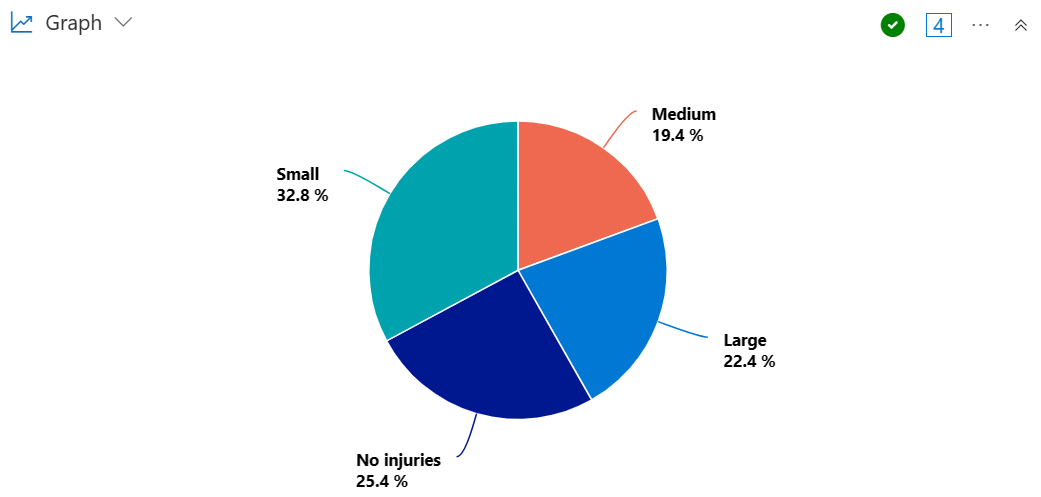
Crie um gráfico de pizza para visualizar a proporção de estados que sofreram tempestades resultando em um grande, médio ou pequeno número de feridos.
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| summarize InjuryBucketByState=count() by InjuriesBucket
| render piechart
Executar agregações em uma janela deslizante
O exemplo a seguir mostra como resumir colunas usando uma janela deslizante.
A consulta calcula os danos materiais mínimos, máximos e médios de tornados, inundações e incêndios florestais usando uma janela deslizante de sete dias. Cada registro agregará os sete dias anteriores no conjunto de resultados. Além disso, os resultados conterão um registro por dia no período de análise.
Aqui está uma explicação passo a passo da consulta:
- Agrupe cada registro em um único dia em relação a
windowStart. - Adicione sete dias ao valor do compartimento para definir o final do intervalo para cada registro. Se o valor estiver fora do intervalo de
windowStartewindowEnd, ajuste o valor de acordo. - Crie uma matriz de sete dias para cada registro, a partir do dia atual do registro.
- Expanda a matriz da etapa 3 com mv-expand para duplicar cada registro para sete registros com intervalos de um dia entre eles.
- Execute as agregações para cada dia. Devido à etapa 4, esta etapa realmente resume os sete dias anteriores.
- Exclua os primeiros sete dias do resultado final, pois não há um período de lookback de sete dias para eles.
let windowStart = datetime(2007-07-01);
let windowEnd = windowStart + 13d;
StormEvents
| where EventType in ("Tornado", "Flood", "Wildfire")
| extend bin = bin_at(startofday(StartTime), 1d, windowStart) // 1
| extend endRange = iff(bin + 7d > windowEnd, windowEnd,
iff(bin + 7d - 1d < windowStart, windowStart,
iff(bin + 7d - 1d < bin, bin, bin + 7d - 1d))) // 2
| extend range = range(bin, endRange, 1d) // 3
| mv-expand range to typeof(datetime) // 4
| summarize min(DamageProperty), max(DamageProperty), round(avg(DamageProperty)) by Timestamp=bin_at(range, 1d, windowStart), EventType // 5
| where Timestamp >= windowStart + 7d; // 6
Saída
A tabela de resultados a seguir é truncada. Para ver a saída completa, execute a consulta.
| Timestamp | EventType | min_DamageProperty | max_DamageProperty | avg_DamageProperty |
|---|---|---|---|---|
| 2007-07-08T00:00:00Z | Tornado | 0 | 30000 | 6905 |
| 2007-07-08T00:00:00Z | Saturação | 0 | 200000 | 9261 |
| 2007-07-08T00:00:00Z | Wildfire | 0 | 200000 | 14033 |
| 2007-07-09T00:00:00Z | Tornado | 0 | 100000 | 14783 |
| 2007-07-09T00:00:00Z | Saturação | 0 | 200000 | 12529 |
| 2007-07-09T00:00:00Z | Wildfire | 0 | 200000 | 14033 |
| 2007-07-10T00:00:00Z | Tornado | 0 | 100000 | 31400 |
| 2007-07-10T00:00:00Z | Saturação | 0 | 200000 | 12,263 |
| 2007-07-10T00:00:00Z | Wildfire | 0 | 200000 | 11694 |
| ... | ... | ... |
Próxima etapa
Agora que você está familiarizado com operadores de consulta comuns e funções de agregação, vá para o próximo tutorial para saber como unir dados de várias tabelas.