Arquitetura de dados e gerenciamento nas soluções de dados de serviços de saúde no Microsoft Fabric
A estrutura de soluções de dados de serviços de saúde usa uma arquitetura medallion especializada para simplificar a organização e o processamento dos dados. Esse design garante a melhoria contínua na qualidade e estrutura dos dados, permitindo que você gerencie os dados de saúde com mais eficiência. Este artigo explora os principais recursos e benefícios dessa arquitetura, fornecendo uma visão geral abrangente de como os dados são gerenciados nessa estrutura.
Design do lakehouse medallion
Conforme explicado na arquitetura da solução, as soluções de dados de serviços de saúde usam a arquitetura de lakehouse medallion para organizar e processar dados em várias camadas. À medida que os dados se movem pelas camadas, sua estrutura e qualidade são continuamente melhoradas. Em sua essência, o design do lakehouse medallion em soluções de dados de serviços de saúde consiste nas seguintes lakehouses-chave:
Lakehouse Bronze: também chamado de zona bruta, a lakehouse bronze é a primeira camada que organiza os dados de origem em seu formato de arquivo original. Ele ingere arquivos de origem no OneLake e/ou cria atalhos de fontes de armazenamento nativas. Ele também armazena dados estruturados e semiestruturados da fonte em tabelas delta, também conhecidas como tabelas de preparo. Essas tabelas são compactadas e indexadas por colunas para oferecer suporte a transformações eficientes e ao processamento de dados. Os dados nessa camada são normalmente somente acréscimo e imutáveis.
Arquivos no lakehouse bronze (sejam persistentes ou atalhos) servem como fonte de referência. Eles estabelecem a base para a linhagem de dados em todo o conjunto de dados em soluções de dados de serviços de saúde. As tabelas de preparo na camada bronze geralmente consistem em algumas colunas e são criadas para manter cada modalidade e formato de dados em uma única tabela (por exemplo, tabelas ClinicalFhir e ImagingDicom). Você não deve estender, personalizar ou criar dependências nessas tabelas de preparo no lakehouse bronze pelos seguintes motivos:
- Implementação interna: as tabelas de preparo são implementadas internamente especificamente para soluções de dados de serviços de saúde no Microsoft Fabric. Seu esquema foi criado especificamente para soluções de dados de serviços de saúde e não segue nenhum padrão de dados do setor ou da comunidade.
- Armazenamento transitório: depois que os dados são processados e transformados das tabelas de preparo do lakehouse bronze para as tabelas delta niveladas e normalizadas no lakehouse prata, os dados da tabela de preparo bronze são considerados prontos para serem eliminados. Esse modelo garante eficiência de custo e armazenamento e reduz a redundância de dados entre arquivos de origem e tabelas de preparo no lakehouse bronze.
Lakehouse prata: também chamado de zona enriquecida, o lakehouse prata refina os dados do lakehouse bronze. Ele inclui verificações de validação e técnicas de enriquecimento para melhorar a precisão dos dados para a análise downstream. Diferentemente da camada bronze, os dados do lakehouse prata usam regras baseadas em IDs determinísticas e carimbos de data/hora de modificação para gerenciar inserções e atualizações de registros.
Lakehouse ouro: também chamada de zona coletada, o lakehouse ouro refina ainda mais os dados do lakehouse prata para atender a requisitos específicos de negócios e análise. Essa camada serve como fonte primária para conjuntos de dados agregados de alta qualidade, prontos para análise abrangente e extração de insights. Enquanto as soluções de dados de serviços de saúde implantam um lakehouse bronze e um prata por implantação, você pode ter vários lakehouses ouro para atender a várias unidades de negócios e personas.
Lakehouse administrativo: o lakehouse administrativo contém arquivos para governança de dados e rastreabilidade nas camadas do lakehouse, incluindo configuração global e erros de validação armazenados na tabela BusinessEvent. Para saber mais, consulte Lakehouse administrativo.
Estrutura de pastas unificada
Os clientes de saúde e ciências biológicas lidam com grandes quantidades de dados de vários sistemas de origem, em várias modalidades de dados e formatos de arquivo, incluindo os seguintes formatos de arquivo:
- Modalidade clínica: arquivos FHIR NDJSON, pacotes FHIR e LH7.
- Modalidade de imagem: DICOM, NIFTI e NDPI.
- Modalidade genômica: BAM, BCL, FASTQ e VCF.
- Solicitações: CCLF e CSV.
Onde:
- FHIR: Fast Healthcare Interoperability Resources
- HL7: Health Level Seven International
- DICOM: Digital Imaging and Communications in Medicine
- NIFTI: Neuroimaging Informatics Technology Initiative
- NDPI: Nano-dimensional Pathology Imaging
- BAM: Mapa de Alinhamento Binário
- BCL: Chamada Base
- FASTQ: Um formato baseado em texto para armazenar uma sequência biológica e suas pontuações de qualidade correspondentes
- VCF: Variant Call Format
- CCLF: Claim and Claim Line Feed
- CSV: Valores separados por vírgula
O OneLake no Microsoft Fabric oferece um data lake lógico para sua organização. As soluções de dados de serviços de saúde no Microsoft Fabric fornecem uma estrutura de pastas unificada que ajuda a organizar os dados em várias modalidades e formatos. Essa estrutura simplifica a ingestão e o processamento de dados, mantendo a linhagem de dados nos níveis do arquivo de origem e do sistema de origem no lakehouse bronze.
As seis pastas de nível superior incluem:
- Externos
- Falhou
- Ingerir
- Processar
- ReferenceData
- SampleData
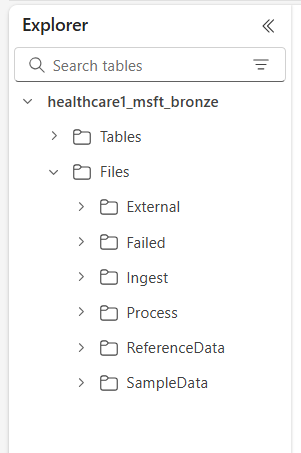
As subpastas são organizadas da seguinte forma:
Files\Ingest\[DataModality]\[DataFormat]\[Namespace]Files\External\[DataModality]\[DataFormat]\[Namespace]\[BYOSShortcutname]\Files\SampleData\[DataModality]\[DataFormat]\[Namespace]\Files\ReferenceData\[DataModality]\[DataFormat]\[Namespace]\Files\Failed\[DataModality]\[DataFormat]\[Namespace]\YYYY\MM\DDFiles\Process\[DataModality]\[DataFormat]\[Namespace]\YYYY\MM\DD
Descrições das pastas
Namespace (obrigatória): identifica o sistema de origem dos arquivos recebidos, essencial para garantir a exclusividade da ID por sistema de origem.
Pasta Ingerir: funciona como uma pasta de depósito ou de fila. Essa pasta permite que você solte os arquivos a serem ingeridos na modalidade apropriada e subpastas de formato. Após o início da ingestão, os arquivos são transferidos para a respectiva pasta Processar ou para a pasta Com Falha em caso de falhas.
Pasta Processar: o destino final de todos os arquivos processados com êxito dentro de cada modalidade e combinação de formato. Essa pasta segue o padrão
YYYY/MM/DDcom base na data de processamento. O particionamento de pastas segue as Melhores práticas para o uso do Azure Data Lake Storage para uma melhor organização, pesquisas filtradas, automação e potencial processamento paralelo.Pasta Externos: serve como a pasta pai para as pastas de atalho BYOS (Traga Seu Próprio Armazenamento). A implantação padrão fornece uma estrutura de pastas sugestiva para solicitações, modalidades clínicas, genômicas e de imagem. As modalidades de imagem e clínica têm formatos e namespaces padrão configurados para oferecer suporte aos serviços DICOM e FHIR nos Serviços de Dados de Saúde do Azure. Esse formato se aplica somente se você pretende usar atalho de dados para o OneLake. As soluções de dados de serviços de saúde no Microsoft Fabric têm acesso somente leitura a arquivos dentro dessas pastas de atalho.
Pasta Com Falha: se ocorrer uma falha ao mover ou processar arquivos nas pastas Ingerir ou Processar , os arquivos afetados serão movidos para a pasta Com Falha correspondente à sua combinação de modalidade e formato. Um erro é registrado em log na tabela BusinessEvent no lakehouse administrativo. Essa pasta usa o padrão
YYYY/MM/DDcom base na data de processamento/falha. Os arquivos nessa pasta não são removidos e continuam aqui até que você os corrija e faça a ingestão novamente usando o mesmo padrão de ingestão inicial.Pasta de dados de exemplo: inclui conjuntos de dados sintéticos, referenciais e/ou públicos. A implantação padrão fornece dados de exemplo para várias combinações de modalidades e formatos para facilitar a execução imediata de notebooks e pipelines após a implantação. Essa pasta não cria subpastas
YYYY/MM/DD.Pasta de dados de referência: contém conjuntos de dados referenciais e pai de fontes públicas ou específicas do usuário. Essa pasta não cria subpastas
YYYY/MM/DD. A implantação padrão fornece uma estrutura de pastas sugerida para vocabulários OMOP (Observational Medical Outcomes Partnership).
Padrões de ingestão de dados
Com base na estrutura de pastas unificada descrita anteriormente, as soluções de dados de serviços de saúde oferecem suporte a dois padrões de ingestão distintos no Microsoft Fabric. Em ambos os casos, as soluções usam streaming estruturado no Spark para processar arquivos de entrada nas respectivas pastas.
Padrão de ingestão
Esse padrão é uma abordagem simples em que os arquivos a serem ingeridos são colocados na pasta Ingerir na modalidade, formato e namespace apropriados. Os pipelines de ingestão monitoram essa pasta em busca de arquivos recém-colocados e os movem para a pasta Processar correspondente para processamento. Se a ingestão de dados do arquivo na tabela de preparo do lakehouse bronze tiver êxito, o arquivo será compactado e salvo com um prefixo de carimbo de data/hora na pasta Processar, seguindo o padrão YYYY/MM/DD com base em quando o processamento ocorre. Esse prefixo garante nomes de arquivo exclusivos. Você pode configurar ou desabilitar a compactação conforme necessário.
Se houver falha no processamento de arquivos s arquivos com falha serão movidos da pasta Ingerir para a pasta Com Falha para cada combinação de modalidade e formato, e um erro será registrado na tabela BusinessEvent no lakehouse administrativo.
Esse padrão de ingestão é ideal para ingestões incrementais diárias ou ao mover fisicamente dados para o Azure Data Lake Storage ou o OneLake.
Padrão BYOS (Traga Seu Próprio Armazenamento)
Às vezes, você pode ter dados e arquivos já presentes no Azure ou em outros serviços de armazenamento em nuvem, com implementações e dependências downstream existentes nesses arquivos. Na saúde e nas ciências biológicas, os volumes de dados podem atingir vários terabytes ou até petabytes, especialmente para imagens médicas e genômicas. Por esses motivos, o padrão de ingestão direta pode não ser viável.
Recomendamos o uso do padrão BYOS para ingestão de dados históricos quando você tiver volumes de dados substanciais já disponíveis no Azure ou em outro armazenamento local e na nuvem que ofereça suporte ao protocolo S3. Esse padrão usa atalhos do OneLake no Fabric e na pasta Externos no lakehouse bronze para habilitar o processamento in-loco de arquivos de origem. Ele elimina a necessidade de mover ou copiar arquivos e evita incorrer em encargos de saída e duplicação de dados.
Apesar das eficiências oferecidas pelo padrão de ingestão BYOS, você deve observar as seguintes considerações:
- As atualizações de arquivo in-loco (atualizações de conteúdo dentro do arquivo) não são monitoradas. Espera-se que você crie um novo arquivo (com um nome diferente) para quaisquer atualizações, já que o pipeline de ingestão monitora somente novos arquivos. Essa limitação está associada ao streaming estruturado no Spark.
- As compactações de dados não são aplicadas.
- O padrão BYOS não cria nenhuma estrutura de pastas otimizada com base no padrão
YYYY/MM/DD. - Se houver falha no processamento de arquivos, os arquivos com falha não serão movidos para a pasta Com Falha. No entanto, um erro será registrado em log na tabela BusinessEvent no lakehouse administrativo.
- Presume-se que os dados de origem sejam somente leitura.
- Não há controle sobre a linhagem ou a disponibilidade dos dados de origem após a ingestão.
Compactação de dados
As soluções de dados de serviços de saúde no Microsoft Fabric oferecem suporte à compactação por design em todo o design do lakehouse medallion. Os dados ingeridos nas tabelas delta em todo o lakehouse medallion são armazenados em um formato colunar compactado usando arquivos parquet. No padrão de ingestão, quando os arquivos são movidos da pasta Ingerir para a pasta Processar, eles são compactados por padrão após o processamento com êxito. Você pode configurar ou desabilitar a compactação conforme necessário. Para os recursos de geração de imagens e solicitações, os pipelines de ingestão também podem processar arquivos brutos em um formato compactado ZIP.
Modelo de dados de saúde
Conforme descrito no design do lakehouse medallion, as tabelas de preparo do lakehouse bronze implementam internamente tabelas criadas especificamente para soluções de dados de serviços de saúde e não seguem nenhum padrão de dados do setor ou da comunidade.
O modelo de dados de saúde no lakehouse prata é baseado no padrão FHIR R4. Ele fornece uma linguagem de dados comum para analistas de dados, cientistas de dados e desenvolvedores colaborarem e criarem soluções baseadas em dados que melhoram os resultados dos pacientes e o desempenho dos negócios. Ele oferece suporte a dados em diferentes domínios dos serviços de saúde, como clínico, administrativo, financeiro e social. O modelo de dados dos serviços de saúde captura dados definidos pelo padrão FHIR e organiza os recursos FHIR usando tabelas e colunas no lakehouse.
Ao nivelar dados FHIR em tabelas de parquet delta, você pode usar ferramentas familiares, como T-SQL e Spark SQL para exploração e análise de dados. Para dados não clínicos fora do escopo do FHIR, usamos esquemas dos modelos de banco de dados do Azure Synapse. Essa implementação permite a integração de informações não clínicas, como dados de envolvimento do paciente, no perfil do paciente.
O modelo de dados de saúde no lakehouse prata foi criado para representar uma visão corporativa completa dos dados de saúde entre unidades de negócios e domínios de pesquisa.

Linhagem de dados e rastreabilidade
Para garantir a linhagem e a rastreabilidade no nível do registro e do arquivo, as tabelas do modelo de dados de saúde incluem as seguintes colunas:
| Coluna | Descrição |
|---|---|
msftCreatedDatetime |
Carimbo de data/hora quando o registro foi criado pela primeira vez no lakehouse prata. |
msftModifiedDatetime |
O carimbo de data/hora da última modificação no registro. |
msftFilePath |
Caminho completo para o arquivo de origem no lakehouse bronze, incluindo atalhos. |
msftSourceSystem |
O sistema de origem do registro, correspondente ao Namespace especificado na estrutura de pastas unificada. |
Se um campo for normalizado, nivelado ou modificado, o valor original será preservado em uma coluna {columnName}Orig. Por exemplo, na tabela Paciente do lakehouse prata , você pode encontrar as seguintes colunas:
| Coluna | Descrição |
|---|---|
meta_lastUpdatedOrig |
Preserva o valor original em seu formato bruto (cadeia de caracteres ou data) e o armazena como datetime. |
idOrig e identifierOrig |
IDs e identificadores harmonizados no lakehouse prata. |
birthdateOrig e deceasedDateTimeOrig |
Preserva os valores de data originais com uma formatação de carimbo de data/hora diferente. |
Se uma coluna nivela (por exemplo, meta_lastUpdated) ou converte em uma cadeia de caracteres (por exemplo, meta_string), nós a denotamos usando um sufixo que começa com um sublinhado (_).
Tratamento de atualizações
Quando novos dados são ingeridos do lakehouse bronze para o prata, uma operação de atualização compara os registros de entrada com as tabelas de destino no lakehouse prata para cada recurso e tipo de tabela. Para as tabelas FHIR no lakehouse prata, essa comparação verifica ambos os valores de {FHIRResource}.id e {FHIRResource}.meta_lastUpdated em relação às colunas id e lastUpdated na tabela de preparo ClinicalFhir do lakehouse bronze.
- Se uma correspondência for identificada e o registro de entrada for novo, o registro do prata será atualizado.
- Se o registro de entrada for antigo, o registro do prata será ignorado.
- Se não houver nenhuma correspondência, o novo registro será inserido no lakehouse prata.
Lakehouse administrativo
O lakehouse administrativo gerencia a configuração entre lakehouses, a configuração global, o relatório de status e o rastreamento para soluções de dados de serviços de saúde no Microsoft Fabric.
Configuração global
A pasta system-configurations do lakehouse administrativo centraliza os parâmetros de configuração global. Os três arquivos de configuração contêm valores pré-configurados para a implantação padrão de todos os recursos de soluções de dados de serviços de saúde. Você não precisa reconfigurar nenhum desses valores para executar os dados de exemplo ou pipelines de dados para qualquer recurso.

O arquivo deploymentParametersConfiguration.json contém parâmetros globais em activitiesGlobalParameters e parâmetros específicos de atividade para notebooks e pipelines em activities. As respectivas orientações de recursos abrangem detalhes de configuração específicos para cada recurso. Os parâmetros do arquivo validation_config.json são explicados em Validação de dados.
A tabela a seguir lista todos os parâmetros de configuração global.
| Seção | Parâmetros de configuração |
|---|---|
activitiesGlobalParameters |
•administration_lakehouse_id: Identificador do lakehouse administrativo.• bronze_lakehouse_id: identificador do lakehouse bronze• silver_lakehouse_id: identificador do lakehouse prata• keyvault_name: valor do Azure Key Vault quando implantado com a oferta do Azure Marketplace.• enable_hds_logs: permite o registro em log; valor padrão definido como true.• movement_config_path: caminho para o arquivo file_orchestration_config.• bronze_imaging_delta_table_path: caminho do Fabric para a tabela de modalidade de imagem (se implantado).• bronze_imaging_table_schema_path: caminho do Fabric para o esquema de modalidade de imagem (se implantado).• omop_lakehouse_id: identificador lakehouse ouro (se implantado). |
| Atividades para healthcare#_msft_fhir_ndjson_bronze_ingestion | •source_path_pattern: o caminho do OneLake para a pasta Processar.• move_failed_files_enabled: sinalizador para determinar se um arquivo com falha deve ser movido da pasta Ingerir para a pasta Com Falha.• compression_enabled: sinalizador para determinar se os arquivos NDJSON brutos serão compactados após o processamento.• target_table_name: nome da tabela de ingestão clínica no lakehouse bronze.• target_tables_path: caminho do OneLake para todas as tabelas delta no lakehouse bronze.• max_files_per_trigger: número de arquivos processados a cada execução.• max_structured_streaming_queries: número de consultas de processamento que podem ser executadas em paralelo.• checkpoint_path: caminho do OneLake para a pasta do ponto de verificação.• schema_dir_path: caminho do OneLake para a pasta do esquema bronze.• validation_config_key: configuração de validação no nível pai. Para obter mais informações, consulte Validação de dados.• file_extension: a extensão do arquivo bruto ingerido. |
| Atividades para healthcare#_msft_bronze_silver_flatten | •source_table_name: nome da tabela de ingestão clínica no lakehouse bronze.• config_path: caminho do OneLake para o arquivo de configuração nivelado.• source_tables_path: caminho do OneLake para as tabelas delta de origem no lakehouse bronze.• target_tables_path: caminho do OneLake para as tabelas delta de destino no lakehouse prata.• checkpoint_path: caminho do OneLake para a pasta do ponto de verificação.• schema_dir_path: caminho do OneLake para a pasta do esquema bronze.• max_files_per_trigger: número de arquivos processados em cada execução.• max_bytes_per_trigger: número de bytes processados em cada execução.• max_structured_streaming_queries: número de consultas de processamento que podem ser executadas em paralelo. |
| Atividades para healthcare#_msft_imaging_dicom_extract_bronze_ingestion | •byos_enabled: sinalizador que determina se a ingestão do conjunto de dados de imagem DICOM no lakehouse bronze é originada de um local de armazenamento externo por meio de atalhos do OneLake. Nesse caso, os arquivos não são movidos para a pasta Processar como seriam de outra forma.• external_source_path: caminho do OneLake para o atalho da pasta Externos no lakehouse bronze.• process_source_path: caminho do OneLake para a pasta Processar no lakehouse bronze.• checkpoint_path: caminho do OneLake para a pasta do ponto de verificação.• move_failed_files: sinalizador que determina se um arquivo com falha é movido da pasta Ingerir para a pasta Com Falha.• compression_enabled: sinalizador que determina se os arquivos NDJSON brutos são compactados após o processamento.• max_files_per_trigger: número de arquivos processados em cada execução.• num_retries: número de novas tentativas para cada processamento de arquivo antes de um erro. |
| Atividades para healthcare#_msft_imaging_dicom_fhir_conversion | •fhir_ndjson_files_root_path: o caminho do OneLake para a pasta Processar.• avro_schema_path: caminho do OneLake para a pasta do esquema prata.• dicom_to_fhir_config_path: caminho do OneLake para configuração de mapeamento de metatags DICOM para o recurso FHIR ImagingStudy.• checkpoint_path: caminho do OneLake para a pasta do ponto de verificação.• max_records_per_ndjson: número de registros processados em um único arquivo NDJSON em cada execução.• subject_id_type_code: código de valor para o número médico do paciente nos metadados DICOM. O valor padrão é definido como MR, que corresponde a Medical Record Number no FHIR.• subject_id_type_code_system: o sistema de códigos para o número médico do paciente nos metadados DICOM.• subject_id_system: A ID do objeto para o sistema de códigos para o número médico do paciente nos metadados DICOM. |
| Atividades para healthcare#_msft_omop_silver_gold_transformation | •vocab_path: caminho do OneLake para a pasta de dados de referência no lakehouse bronze onde os conjuntos de dados de vocabulário OMOP são armazenados.• vocab_checkpoint_path: caminho do OneLake para a pasta do ponto de verificação.• omop_config_path: caminho do OneLake para a configuração de mapeamento do lakehouse prata para o lakehouse ouro OMOP. |
Tabela BusinessEvents
A tabela delta BusinessEvents captura todos os erros de validação, avisos e outras notificações ou exceções que podem ocorrer durante os processos de ingestão e transformação. Use esta tabela para monitorar o progresso da execução da ingestão nos níveis de usuário e funcional, em vez de somente no nível de log do sistema. Por exemplo, ele identifica quais arquivos brutos introduziram erros de validação ou avisos durante a ingestão. Para logs no nível do sistema e para monitorar atividades do Apache Spark em todos os lakehouses, você pode usar o Hub de Monitoramento do Fabric, com a opção de integrar o Azure Log Analytics.
A tabela a seguir lista as colunas na tabela BusinessEvent:
| Coluna | Descrição |
|---|---|
id |
Identificador exclusivo (GUID) para cada linha na tabela. |
activityName |
Nome da atividade/notebook que gerou a falha e/ou o erro ou aviso de validação. |
targetTableName |
Tabela de destino para a atividade de dados que gerou o evento. |
targetFilePath |
Caminho para o arquivo de destino para a atividade de dados que gerou o evento. |
sourceTableName |
Tabela de origem para a atividade de dados que gerou o evento. |
sourceLakehouseName |
Lakehouse de origem para a atividade de dados que gerou o evento. |
targetLakehouseName |
Lakehouse de destino para a atividade de dados que gerou o evento. |
sourceFilePath |
Caminho para o arquivo de origem para a atividade de dados que gerou o evento. |
runId |
ID de execução para a atividade de dados que gerou o evento. |
severity |
Nível de gravidade do evento, que pode ter um dos dois valores a seguir: Error ou Warning. Error significa que você deve resolver esse evento antes de continuar com a atividade de dados. Warning serve como uma notificação passiva, geralmente não exigindo nenhuma ação imediata. |
eventType |
Distingue entre eventos gerados pelo mecanismo de validação e eventos genéricos gerados por usuários ou exceções não tratadas/do sistema que os usuários desejam exibir na tabela BusinessEvent. |
recordIdentifier |
Identificador para o registro de origem. Essa coluna é diferente da coluna id, pois representa um identificador novo e exclusivo para cada evento na tabela BusinessEvents. |
recordIdentifierSource |
Sistema de origem para o identificador do registro de origem. Por exemplo, se o sistema de origem for o EMR, o nome ou a URL do EMR servirá como origem. |
active |
Sinalizador que indica se o evento (erro ou aviso) foi resolvido. |
message |
Mensagem descritiva para o evento, erro ou aviso. |
exception |
Mensagem de exceção não tratada/do sistema. |
customDimensions |
Aplicável quando os dados de origem da validação ou da exceção não são uma coluna discreta em uma tabela. Por exemplo, quando os dados de origem são um atributo dentro de um objeto JSON salvo como uma cadeia de caracteres dentro de uma única coluna, o objeto JSON completo é fornecido como a dimensão personalizada. |
eventDateTime |
Carimbo de data/hora no qual o evento ou a exceção é gerada. |
Validação de dados
O mecanismo de validação de dados dentro das soluções de dados de serviços de saúde no Microsoft Fabric garante que os dados brutos atendam a critérios predefinidos antes de serem ingeridos no lakehouse bronze. Você pode configurar as regras de validação nos níveis de tabela e coluna dentro do lakehouse bronze. No momento, essas regras são implementadas exclusivamente durante o processo de ingestão, desde arquivos brutos até tabelas delta no lakehouse bronze.
Quando um arquivo bruto é processado, as regras de validação se aplicam no nível de ingestão. Há dois níveis de gravidade para a validação: Error e Warning. Se uma regra de validação for definida como Error, o pipeline será interrompido quando a regra for violada e o arquivo com defeito será movido para a pasta Com Falha. Se a gravidade for definida Warning, o pipeline continuará o processamento e o arquivo será movido para a pasta Processar. Em ambos os casos, as entradas que refletem os erros ou avisos são criadas na tabela BusinessEvents dentro do lakehouse administrativo.
A tabela BusinessEvents captura logs e eventos no nível de negócios em todos os lakehouses para qualquer atividade, notebook ou pipeline de dados em soluções de dados de serviços de saúde. No entanto, a configuração atual só impõe regras de validação durante a ingestão, o que pode fazer com que algumas colunas na tabela BusinessEvents permaneçam não preenchidas para erros e avisos de validação.
Você pode configurar as regras de validação de dados no arquivo validation_config.json no lakehouse administrativo. Por padrão, as colunas meta.lastUpdated e id na tabela ClinicalFhir do lakehouse bronze são definidas conforme necessário. Essas colunas são essenciais para determinar como as atualizações e inserções são gerenciadas no lakehouse prata, conforme explicado em Tratamento de atualizações.
A tabela a seguir lista os parâmetros de configuração para a validação de dados:
| Tipo de configuração | Parâmetros |
|---|---|
| Nível do lakehouse | bronze: o escopo das validações e nós do identificador de registro. Nesse caso, o valor é definido para o lakehouse bronze. |
| Validações | •validationType: o tipo de validação exists verifica se um valor para o atributo configurado é fornecido no arquivo bruto (dados de origem).• attributeName: nome do atributo sendo validado.• validationMessage: mensagem descrevendo o erro ou aviso de validação.• severity: indica o nível do problema, que pode ser Error ou Warning.• tableName: nome da tabela sendo validada. Um asterisco (*) denota que essa regra se aplica a todas as tabelas no escopo desse lakehouse. |
recordIdentifier |
•attributeName: identificador do registro do arquivo de origem/bruto colocado na coluna recordIdentifier da tabela BusinessEvent.• jsonPath: valor opcional que representa o caminho JSON de uma coluna ou atributo para o valor a ser colocado na coluna recordIdentifier na tabela BusinessEvent. Esse valor se aplica quando os dados de origem para a validação não são uma coluna discreta em uma tabela. Por exemplo, se os dados de origem forem um atributo dentro de um objeto JSON armazenado como uma cadeia de caracteres dentro de uma única coluna, o caminho JSON direcionará para o atributo específico que serve como identificador de registro. |