Use tabelas Iceberg com OneLake
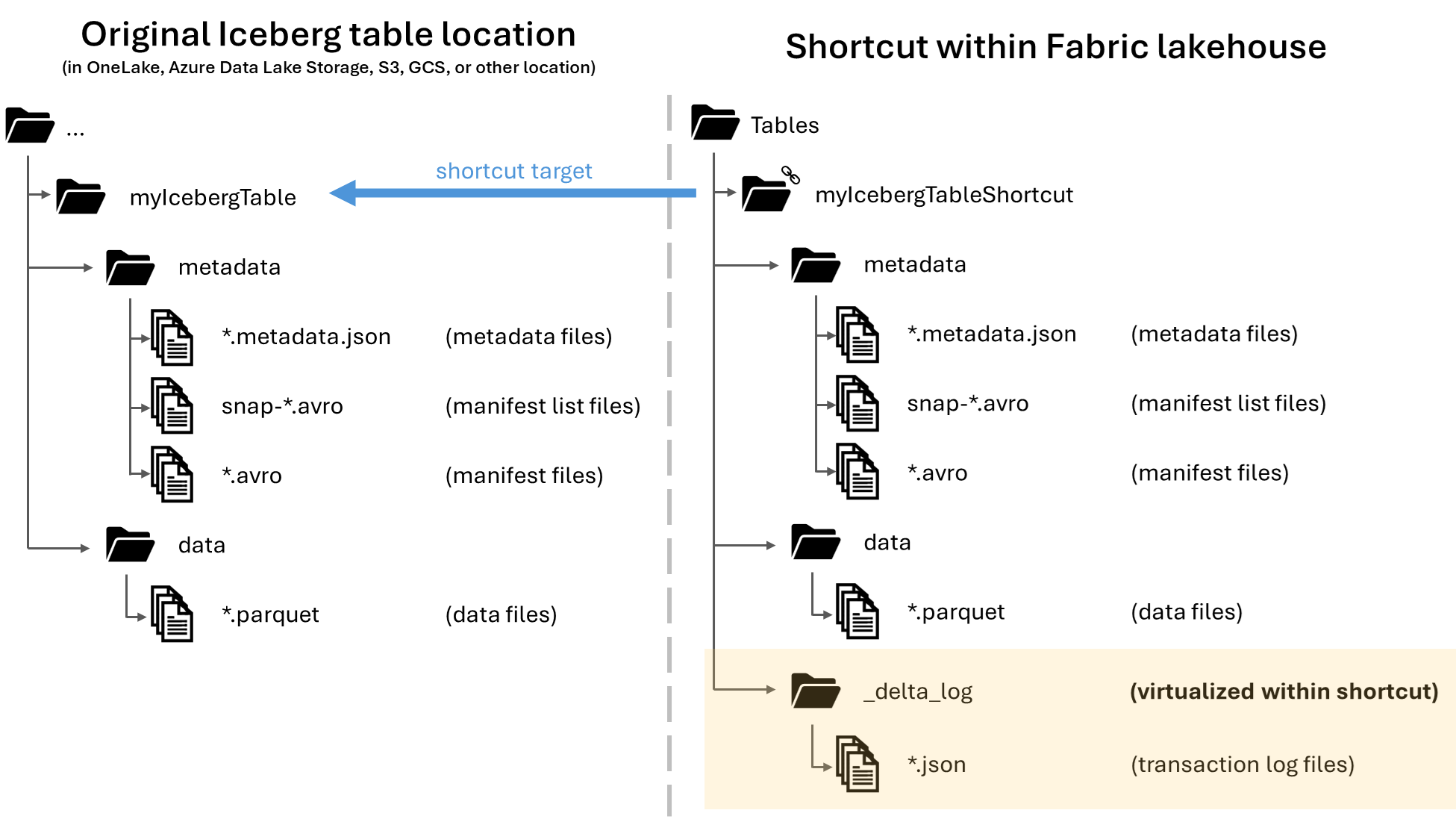
No Microsoft OneLake, você pode criar atalhos para suas tabelas do Apache Iceberg, permitindo seu uso em uma ampla variedade de cargas de trabalho do Fabric. Essa funcionalidade é possível por meio de um recurso chamado virtualização de metadados, que permite que tabelas Iceberg sejam interpretadas como tabelas Delta Lake da perspectiva do atalho. Quando você cria um atalho para uma pasta de tabela Iceberg, o OneLake gera automaticamente os metadados correspondentes do Delta Lake (o log do Delta) para essa tabela, tornando os metadados do Delta Lake acessíveis por meio do atalho.
Importante
Esse recurso está em preview.
Embora esse artigo inclua orientações para escrever tabelas Iceberg do Snowflake para o OneLake, esse recurso foi criado para funcionar com qualquer tabela Iceberg com arquivos de dados Parquet.
Crie um atalho de tabela para uma tabela Iceberg
Se você já tiver uma tabela Iceberg em um local de armazenamento compatível com atalhos do OneLake, siga essas etapas para criar um atalho e fazer com que sua tabela Iceberg apareça com o formato Delta Lake.
Localize sua mesa Iceberg. Descubra onde sua tabela Iceberg está armazenada, o que pode ser no Azure Data Lake Storage, OneLake, Amazon S3, Google Cloud Storage ou um serviço de armazenamento compatível com S3.
Observação
Se você estiver usando o Snowflake e não tiver certeza de onde sua tabela Iceberg está armazenada, você pode executar a seguinte instrução para ver o local de armazenamento da sua tabela Iceberg.
SELECT SYSTEM$GET_ICEBERG_TABLE_INFORMATION('<table_name>');A execução dessa instrução retorna um caminho para o arquivo de metadados da tabela Iceberg. Esse caminho informa qual conta de armazenamento contém a tabela Iceberg. Por exemplo, aqui estão as informações relevantes para encontrar o caminho de uma tabela Iceberg armazenada no Azure Data Lake Storage:
{"metadataLocation":"azure://<storage_account_path>/<path_within_storage>/<table_name>/metadata/00001-389700a2-977f-47a2-9f5f-7fd80a0d41b2.metadata.json","status":"success"}A pasta da sua tabela Iceberg precisa conter uma pasta
metadata, que contém pelo menos um arquivo terminado em.metadata.json.No seu lakehouse do Fabric, crie um novo atalho na área Tabelas de um lakehouse não habilitado para esquema.
Observação
Se você vir esquemas como
dbona pasta Tabelas do seu lakehouse, então o lakehouse está habilitado para esquemas e ainda não é compatível com esse recurso.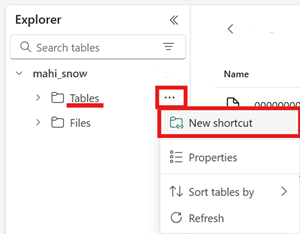
Para o caminho de destino do seu atalho, selecione a pasta da tabela Iceberg. A pasta da tabela Iceberg contém as pastas
metadataedata.Depois que seu atalho for criado, você verá automaticamente essa tabela refletida como uma tabela Delta Lake em seu lakehouse, pronta para uso em todo o Fabric.
Se o seu novo atalho de tabela Iceberg não aparecer como uma tabela utilizável, verifique a seção Solução de problemas.
Escreva uma tabela Iceberg para OneLake usando Snowflake
Se você usar o Snowflake no Azure, poderá gravar tabelas Iceberg no OneLake seguindo essas etapas:
Certifique-se de que sua capacidade do Fabric esteja no mesmo local do Azure que sua instância do Snowflake.
Identifique a localização da capacidade do Fabric associada ao seu lakehouse do Fabric. Abra as configurações do espaço de trabalho do Fabric que contém sua casa no lago.
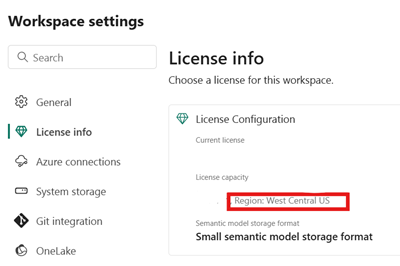
No canto inferior esquerdo da interface da sua conta do Snowflake no Azure, verifique a região do Azure da conta do Snowflake.
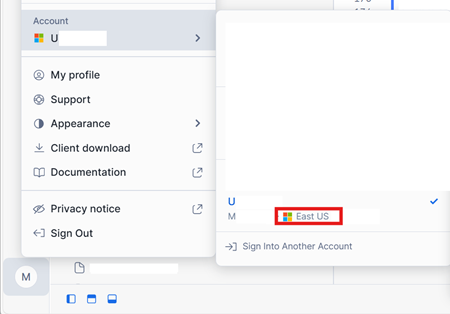
Se essas regiões forem diferentes, você precisará usar uma capacidade de Fabric diferente na mesma região da sua conta Snowflake.
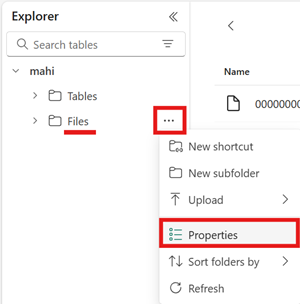
Abra o menu da área Arquivos do seu lakehouse, selecione Propriedades e copie a URL (o caminho HTTPS) dessa pasta.
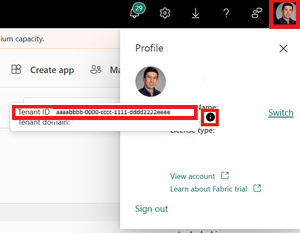
Identifique seu ID de locatário do Fabric. Selecione seu perfil de usuário no canto superior direito da IU do Fabric e passe o mouse sobre o balão de informações ao lado do seu Nome do locatário. Copie a ID do Locatário.
No Snowflake, configure seu
EXTERNAL VOLUMEusando o caminho para a pasta Arquivos em sua casa no lago. Mais informações sobre como configurar volumes externos do Snowflake podem ser encontradas aqui.Observação
O Snowflake exige que o esquema de URL seja
azure://, portanto, certifique-se de alterarhttps://paraazure://.CREATE OR REPLACE EXTERNAL VOLUME onelake_exvol STORAGE_LOCATIONS = ( ( NAME = 'onelake_exvol' STORAGE_PROVIDER = 'AZURE' STORAGE_BASE_URL = 'azure://<path_to_Files>/icebergtables' AZURE_TENANT_ID = '<Tenant_ID>' ) );Nesse exemplo, todas as tabelas criadas usando esse volume externo são armazenadas no Fabric lakehouse, dentro da pasta
Files/icebergtables.Agora que seu volume externo foi criado, execute o seguinte comando para recuperar a URL de consentimento e o nome do aplicativo que o Snowflake usa para gravar no OneLake. Esse aplicativo é usado por qualquer outro volume externo na sua conta Snowflake.
DESC EXTERNAL VOLUME onelake_exvol;A saída desse comando retorna as propriedades
AZURE_CONSENT_URLeAZURE_MULTI_TENANT_APP_NAME. Tome nota de ambos os valores. O nome do aplicativo multilocatário do Azure se parece com<name>_<number>, mas você só precisa capturar a parte<name>.Abra o URL de consentimento da etapa anterior em uma nova guia do navegador. Se desejar prosseguir, consinta com as permissões necessárias do aplicativo, se solicitado.
De volta ao Fabric, abra seu espaço de trabalho e selecione Gerenciar acesso, depois Adicionar pessoas ou grupos. Conceda ao aplicativo usado pelo seu volume externo Snowflake as permissões necessárias para gravar dados em lakehouses no seu espaço de trabalho. Recomendamos conceder a função Contribuidor.
De volta ao Snowflake, use seu novo volume externo para criar uma tabela Iceberg.
CREATE OR REPLACE ICEBERG TABLE MYDATABASE.PUBLIC.Inventory ( InventoryId int, ItemName STRING ) EXTERNAL_VOLUME = 'onelake_exvol' CATALOG = 'SNOWFLAKE' BASE_LOCATION = 'Inventory/';Com essa instrução, uma nova pasta de tabela Iceberg chamada Inventory é criada dentro do caminho da pasta definido no volume externo.
Adicione alguns dados à sua tabela Iceberg.
INSERT INTO MYDATABASE.PUBLIC.Inventory VALUES (123456,'Amatriciana');Por fim, na área de Tabelas do mesmo lakehouse, você pode criar um atalho OneLake para sua mesa Iceberg. Por meio desse atalho, sua tabela Iceberg aparece como uma tabela Delta Lake para consumo em todas as cargas de trabalho do Fabric.
Solução de problemas
As dicas a seguir podem ajudar a garantir que suas mesas Iceberg sejam compatíveis com esse recurso:
Verifique a estrutura de pastas da sua tabela Iceberg
Abra sua pasta Iceberg na sua ferramenta de armazenamento preferida e verifique a listagem de diretórios da sua pasta Iceberg em seu local original. Você deverá ver uma estrutura de pastas como no exemplo a seguir.
../
|-- MyIcebergTable123/
|-- data/
|-- snow_A5WYPKGO_2o_APgwTeNOAxg_0_1_002.parquet
|-- snow_A5WYPKGO_2o_AAIBON_h9Rc_0_1_003.parquet
|-- metadata/
|-- 00000-1bdf7d4c-dc90-488e-9dd9-2e44de30a465.metadata.json
|-- 00001-08bf3227-b5d2-40e2-a8c7-2934ea97e6da.metadata.json
|-- 00002-0f6303de-382e-4ebc-b9ed-6195bd0fb0e7.metadata.json
|-- 1730313479898000000-Kws8nlgCX2QxoDHYHm4uMQ.avro
|-- 1730313479898000000-OdsKRrRogW_PVK9njHIqAA.avro
|-- snap-1730313479898000000-9029d7a2-b3cc-46af-96c1-ac92356e93e9.avro
|-- snap-1730313479898000000-913546ba-bb04-4c8e-81be-342b0cbc5b50.avro
Se você não vir a pasta de metadados ou se não vir arquivos com as extensões mostradas nesse exemplo, talvez você não tenha uma tabela Iceberg gerada corretamente.
Verifique o log de conversão
Quando uma tabela Iceberg é virtualizada como uma tabela Delta Lake, uma pasta chamada _delta_log/ pode ser encontrada dentro da pasta de atalho. Essa pasta contém os metadados do formato Delta Lake (o log Delta) após a conversão bem-sucedida.
Essa pasta também inclui o arquivo latest_conversion_log.txt, que contém os detalhes do sucesso ou falha da última tentativa de conversão.
Para ver o conteúdo desse arquivo após criar seu atalho, abra o menu do atalho da tabela Iceberg na área Tabelas do seu lakehouse e selecione Exibir arquivos.
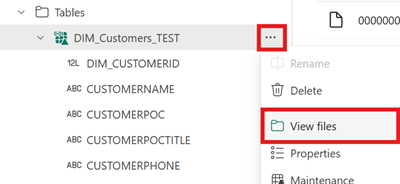
Você deverá ver uma estrutura como o exemplo a seguir:
Tables/
|-- MyIcebergTable123/
|-- data/
|-- <data files>
|-- metadata/
|-- <metadata files>
|-- _delta_log/ <-- Virtual folder. This folder doesn't exist in the original location.
|-- 00000000000000000000.json
|-- latest_conversion_log.txt <-- Conversion log with latest success/failure details.
Abra o arquivo de log de conversão para ver o horário da conversão mais recente ou os detalhes da falha. Se você não vir um arquivo de log de conversão, a conversão não foi tentada.
Se a conversão não foi tentada
Se você não vir um arquivo de log de conversão, a conversão não foi tentada. Aqui estão dois motivos comuns pelos quais a conversão não é tentada:
O atalho não foi criado no lugar certo.
Para que um atalho para uma tabela Iceberg seja convertido para o formato Delta Lake, o atalho deve ser colocado diretamente na pasta Tabelas de um lakehouse não habilitado para esquema. Você não deve colocar o atalho na seção Arquivos ou em outra pasta se quiser que a tabela seja virtualizada automaticamente como uma tabela Delta Lake.
O caminho de destino do atalho não é o caminho da pasta Iceberg.
Ao criar o atalho, o caminho da pasta selecionado no local de armazenamento de destino deve ser somente a pasta da tabela Iceberg. Essa pasta contém as pastas
metadataedata.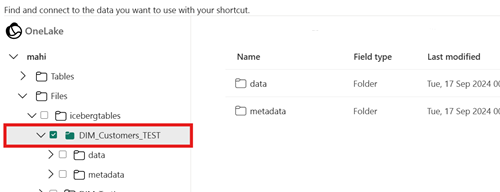
Limitações e considerações
Tenha em mente as seguintes limitações temporárias ao usar esse recurso:
Tipos de dados com suporte
Os seguintes tipos de dados da coluna Iceberg são mapeados para seus tipos Delta Lake correspondentes usando esse recurso.
Tipo de coluna iceberg Tipo de coluna Delta Lake Comentários intintegerlonglongVeja Problema de largura de tipo. floatfloatdoubledoubleVeja Problema de largura de tipo. decimal(P, S)decimal(P, S)Veja Problema de largura de tipo. booleanbooleandatedatetimestamptimestamp_ntzO tipo de dados timestampIceberg não contém informações de fuso horário. O tipotimestamp_ntzDelta Lake não é totalmente suportado em cargas de trabalho do Fabric. Recomendamos o uso de carimbos de data/hora com fusos horários incluídos.timestamptztimestampNo Snowflake, para usar esse tipo, especifique timestamp_ltzcomo o tipo de coluna durante a criação da tabela Iceberg. Mais informações sobre os tipos de dados Iceberg suportados no Snowflake podem ser encontradas aqui.stringstringbinarybinaryProblema de largura de tipo
Se você usar o Snowflake para escrever sua tabela Iceberg e a tabela contiver tipos de coluna
INT64,doubleouDecimalcom precisão >= 10, a tabela virtual Delta Lake resultante poderá não ser consumível por todos os mecanismos do Fabric. Você pode ver erros como:Parquet column cannot be converted in file ... Column: [ColumnA], Expected: decimal(18,4), Found: INT32.Estamos trabalhando para corrigir esse problema.
Solução alternativa: Se você estiver usando a interface de visualização de tabela do Lakehouse e observar esse problema, poderá resolver esse erro alternando para a exibição do SQL Endpoint (canto superior direito, selecione a exibição do Lakehouse, alterne para o SQL Endpoint) e visualizando a tabela a partir daí. Se você retornar para a visualização Lakehouse, a visualização da tabela deverá ser exibida corretamente.
Se você estiver executando um notebook ou trabalho do Spark e encontrar esse problema, poderá resolver esse erro definindo a configuração
spark.sql.parquet.enableVectorizedReaderSpark comofalse. Aqui está um exemplo de comando PySpark para executar em um notebook Spark:spark.conf.set("spark.sql.parquet.enableVectorizedReader","false")O armazenamento de metadados da tabela Iceberg não é portátil
Os arquivos de metadados de uma tabela Iceberg referem-se uns aos outros usando referências de caminho absolutas. Se você copiar ou mover o conteúdo da pasta de uma tabela Iceberg para outro local sem reescrever os arquivos de metadados do Iceberg, a tabela se tornará ilegível para os leitores Iceberg, incluindo esse recurso do OneLake.
Solução alternativa:
Se você precisar mover sua tabela Iceberg para outro local para usar esse recurso, use a ferramenta que escreveu originalmente a tabela Iceberg para escrever uma nova tabela Iceberg no local desejado.
As tabelas de iceberg devem ser mais profundas que o nível da raiz
A pasta da tabela Iceberg no armazenamento deve estar localizada em um diretório mais profundo que o nível do bucket ou do contêiner. As tabelas Iceberg armazenadas diretamente no diretório raiz de um bucket ou contêiner podem não ser virtualizadas para o formato Delta Lake.
Estamos trabalhando em uma melhoria para remover esse requisito.
Solução alternativa:
Certifique-se de que todas as tabelas Iceberg sejam armazenadas em um diretório mais profundo que o diretório raiz de um bucket ou contêiner.
As pastas da tabela Iceberg devem conter apenas um conjunto de arquivos de metadados
Se você remover e recriar uma tabela Iceberg no Snowflake, os arquivos de metadados não serão limpos. Esse comportamento é compatível com o recurso
UNDROPno Snowflake. Entretanto, como seu atalho aponta diretamente para uma pasta e essa pasta agora tem vários conjuntos de arquivos de metadados dentro dela, não podemos converter a tabela até que você remova os arquivos de metadados da tabela antiga.Atualmente, a conversão é tentada nesse cenário, o que pode resultar em conteúdo de tabela antigo e informações de esquema sendo mostradas na tabela Delta Lake virtualizada.
Estamos trabalhando em uma correção na qual a conversão falha se mais de um conjunto de arquivos de metadados for encontrado na pasta de metadados da tabela Iceberg.
Solução alternativa:
Para garantir que a tabela convertida reflita a versão correta da tabela:
- Certifique-se de não armazenar mais de uma tabela Iceberg na mesma pasta.
- Limpe todo o conteúdo de uma pasta de tabela Iceberg após removê-la, antes de recriá-la.
As alterações de metadados não são imediatamente refletidas
Se você fizer alterações de metadados na sua tabela Iceberg, como adicionar uma coluna, excluir uma coluna, renomear uma coluna ou alterar um tipo de coluna, a tabela poderá não ser reconvertida até que uma alteração de dados seja feita, como adicionar uma linha de dados.
Estamos trabalhando em uma correção que coleta o arquivo de metadados mais recente e correto que inclui a alteração de metadados mais recente.
Solução alternativa:
Depois de fazer a alteração de esquema na sua tabela Iceberg, adicione uma linha de dados ou faça qualquer outra alteração nos dados. Após essa alteração, você poderá atualizar e ver a visualização mais recente da sua tabela no Fabric.
Espaços de trabalho habilitados para esquema ainda não são suportados
Se você criar um atalho do Iceberg em um lakehouse habilitado para esquema, a conversão não ocorrerá para esse atalho.
Estamos trabalhando em uma melhoria para remover essa limitação.
Solução alternativa:
Use um lakehouse não habilitado para esquema com esse recurso. Você pode configurar essa configuração durante a criação do lakehouse.
Limitação de disponibilidade da região
O recurso ainda não está disponível nas seguintes regiões:
- Catar Central
- Oeste da Noruega
Solução alternativa:
Espaços de trabalho anexados às capacidades do Fabric em outras regiões podem usar esse recurso. Veja a lista completa de regiões onde o Microsoft Fabric está disponível.
Links privados não suportados
Atualmente, esse recurso não é compatível com locatários ou espaços de trabalho que tenham links privados habilitados.
Estamos trabalhando em uma melhoria para remover essa limitação.
Limitação do tamanho da tabela
Temos uma limitação temporária no tamanho da tabela Iceberg suportada por esse recurso. O número máximo suportado de arquivos de dados Parquet é de cerca de 5.000 arquivos de dados, ou aproximadamente 1 bilhão de linhas, o que for atingido primeiro.
Estamos trabalhando em uma melhoria para remover essa limitação.
Os atalhos do OneLake devem ser da mesma região
Temos uma limitação temporária no uso desse recurso com atalhos que apontam para locais do OneLake: o local de destino do atalho deve estar na mesma região que o próprio atalho.
Estamos trabalhando em uma melhoria para remover esse requisito.
Solução alternativa:
Se você tiver um atalho do OneLake para uma mesa Iceberg em outro lakehouse, certifique-se de que o outro lakehouse esteja associado a uma capacidade na mesma região.
Comutador do locatário permitindo acesso externo
Temos uma limitação temporária que requer que a configuração de locatário "Os usuários podem acessar dados armazenados no OneLake com aplicativos externos ao Fabric" esteja habilitada.
Se essa configuração de locatário estiver desabilitada, a virtualização das tabelas Iceberg para o formato Delta Lake não terá êxito.
Solução alternativa:
Faça com que o administrador do locatário do Fabric habilite a configuração de locatário "Os usuários podem acessar dados armazenados no OneLake com aplicativos externos ao Fabric", se possível.
Tabelas Iceberg precisam ser do tipo "copiar ao gravar" (e não "mesclar ao ler")
Atualmente, as tabelas Iceberg precisam ser copiar ao gravar. Isso significa que elas não podem conter arquivos de exclusão ou serem do tipo mesclar ao ler.
O Snowflake atualmente produz tabelas Iceberg do tipo copiar ao gravar, mas outros gravadores Iceberg podem seguir uma abordagem diferente.
Estamos trabalhando no suporte para tabelas Iceberg mesclar ao ler.
Conteúdo relacionado
- Saiba mais sobre a segurança do Fabric e do OneLake.
- Saiba mais sobre atalhos OneLake.