Módulo 1: criar um pipeline com o Data Factory
Esse módulo leva 10 minutos, ingerindo dados brutos do armazenamento de origem na tabela Bronze de um data lakehouse usando a atividade Copy em um pipeline.
As etapas de alto nível no módulo 1 são as seguintes:
- Crie um pipeline de dados.
- Usar uma atividade Copy no pipeline para carregar dados de exemplo em um data lakehouse.
Criar um pipeline de dados
Uma conta de locatário do Microsoft Fabric com uma assinatura ativa é necessária. Criar uma conta gratuita.
Verifique se você tem um Workspace habilitado para o Microsoft Fabric: Criar um workspace.
Selecione o ícone padrão do Power BI na parte inferior esquerda da tela e selecione Fabric.
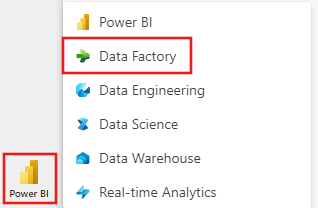
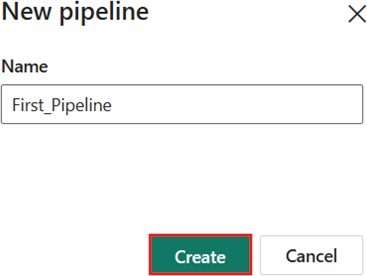
Selecione um workspace na guia workspaces, selecione + Novo item e escolha Pipeline de dados. Dê um nome ao pipeline. Em seguida, selecione Criar.
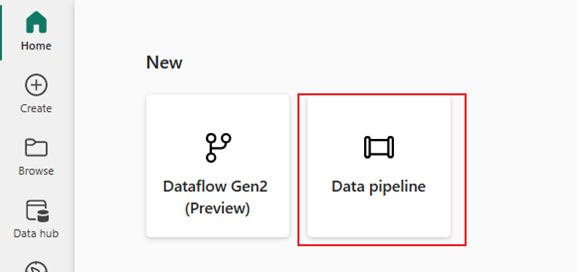
Use uma atividade Copy no pipeline para carregar dados de exemplo em um data lakehouse
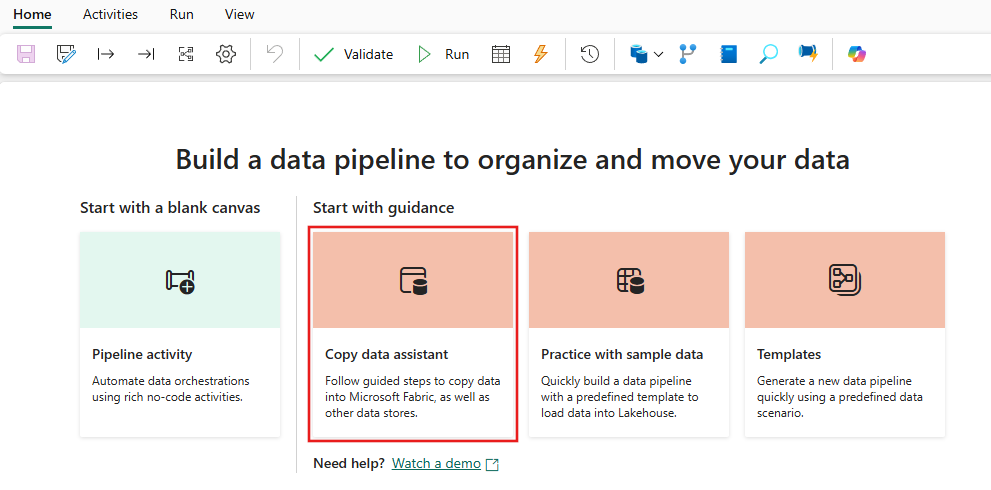
Etapa 1: use o assistente de cópia para configurar uma atividade de cópia.
Selecione Assistente de cópia de dados para abrir a ferramenta do assistente de cópia.
Etapa 2: definir suas configurações no assistente de cópia.
A caixa de diálogo Copiar dados é exibida com a primeira etapa, Escolher fonte de dados, realçada. Selecione Dados de exemplo nas opções na parte superior da caixa de diálogo e selecione Táxi de NYC – Verde.

A visualização da fonte de dados é exibida em seguida, na página Conectar à fonte de dados. Revise e selecione Avançar.
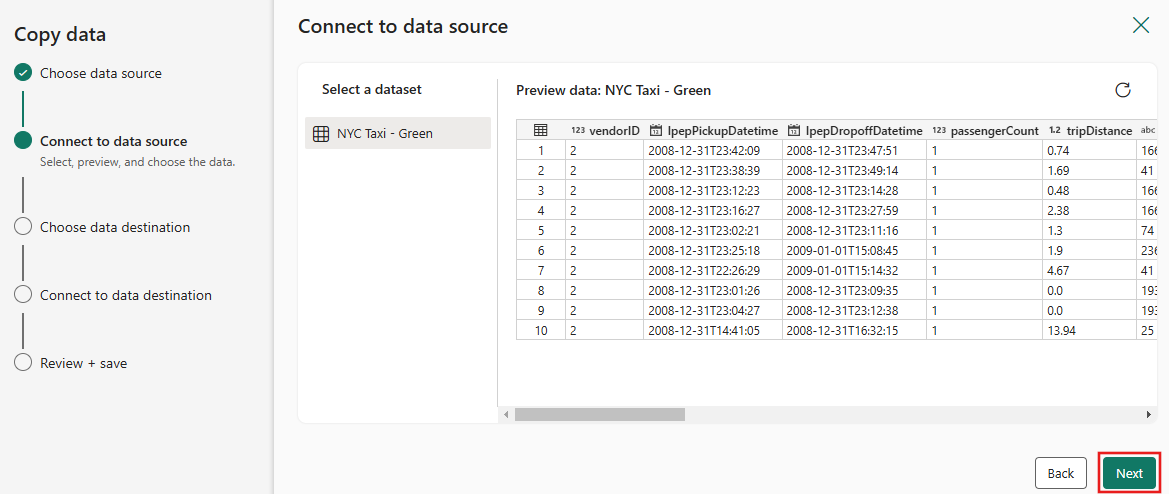
Na etapa Escolher destino dos dados do assistente de cópia, selecione Lakehouse e, em seguida, Avançar.
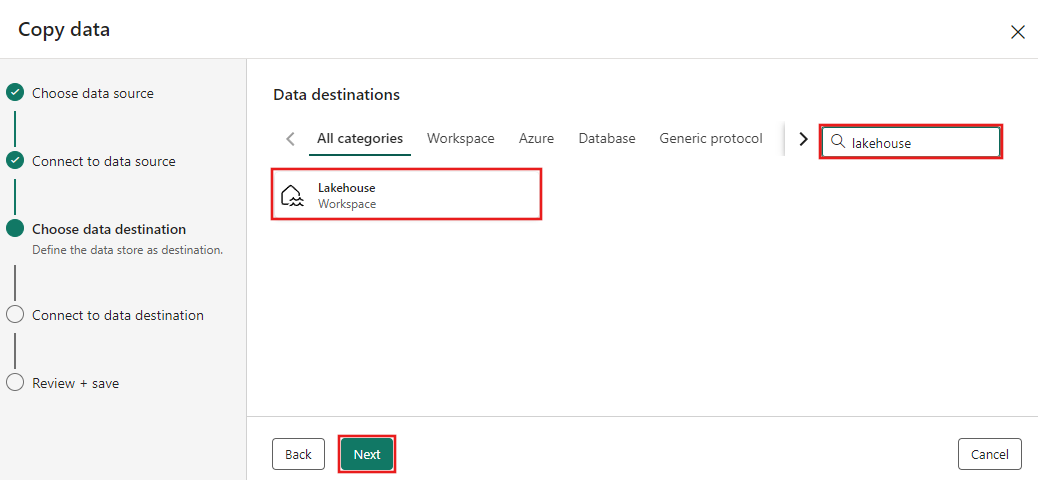
Selecione Criar nova Lakehouse na página de configuração de destino de dados exibida e insira um nome para o novo Lakehouse. Em seguida, selecione Próximo novamente.
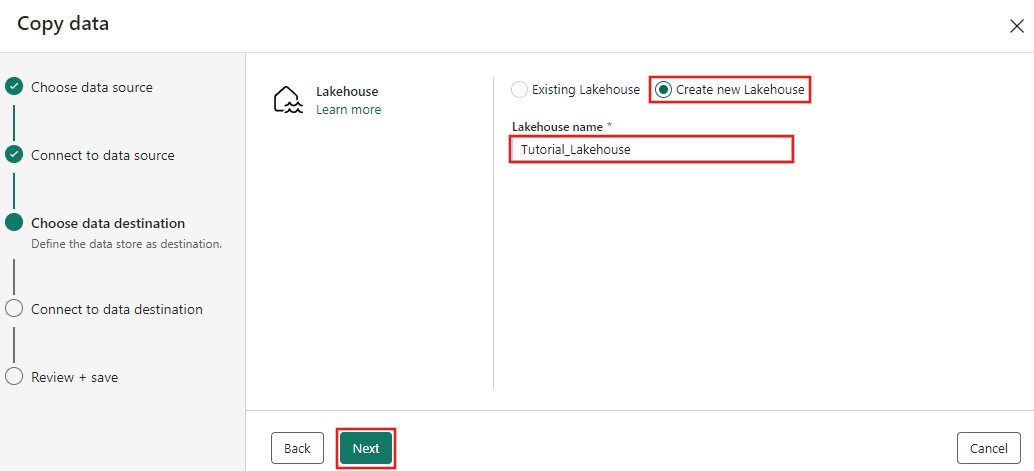
Agora configure os detalhes do destino Lakehouse na página Selecionar e mapear para o caminho da pasta ou tabela. Selecione Tabelas para a Pasta raiz, forneça um nome de tabela e escolha a ação Substituir. Não marque a caixa de seleção Habilitar partição que aparece depois que você seleciona a ação de tabela Substituir.
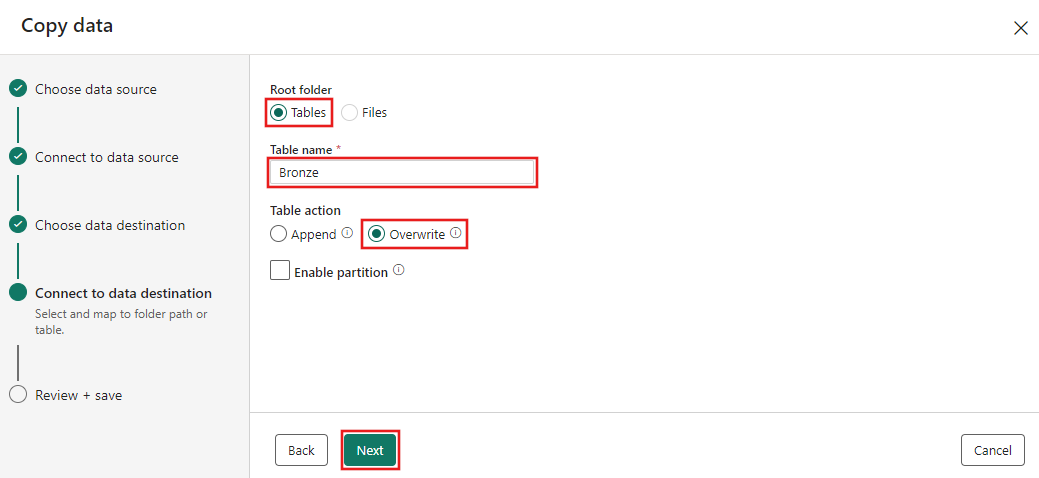
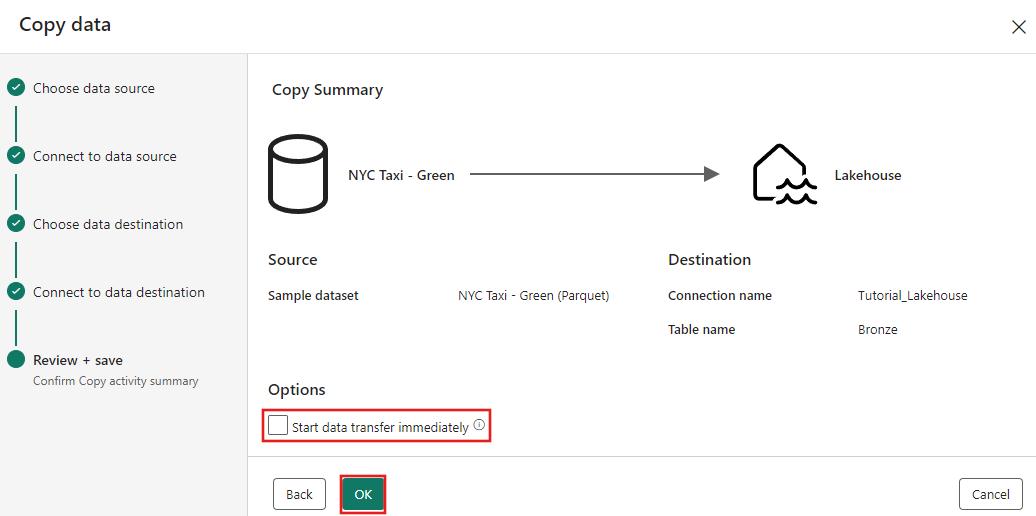
Por fim, na página Revisar + salvar do assistente de cópia de dados, revise a configuração. Para este tutorial, desmarque a caixa de seleção Iniciar transferência de dados imediatamente, já que executamos a atividade manualmente na próxima etapa. Em seguida, selecione OK.
Etapa 3: Executar e exibir os resultados da atividade de cópia.
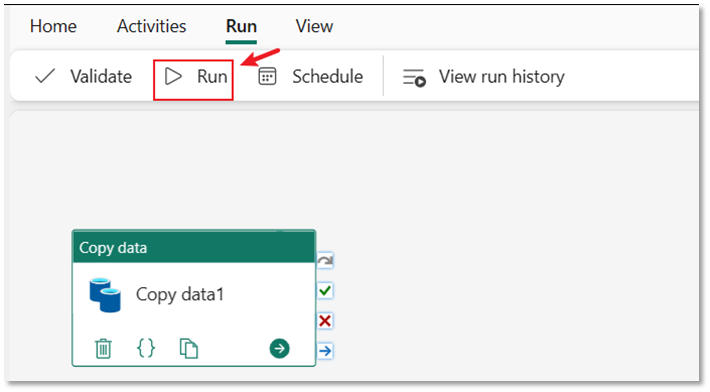
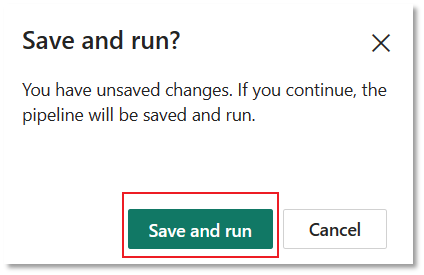
Selecione a guia Executar no editor do pipeline. Em seguida, selecione o botão Executar e, em seguida, Salvar e executar no prompt, para executar a atividade Copiar.
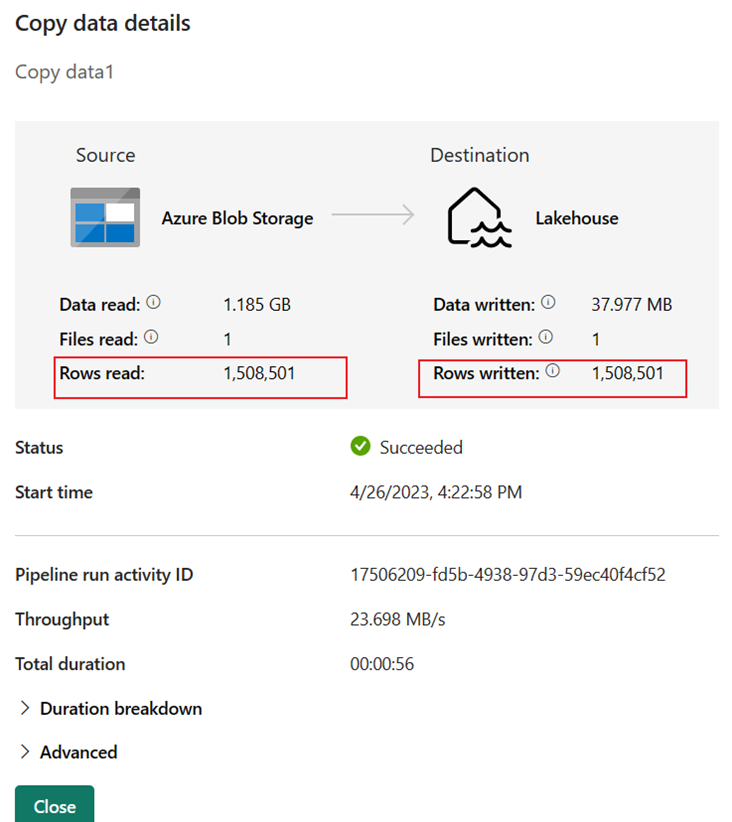
Você pode monitorar a execução e verificar os resultados na guia Saída abaixo da tela do pipeline. Selecione o botão de detalhes da execução (o ícone de "óculos" que aparece quando você passa o mouse sobre a execução do pipeline em andamento) para exibir os detalhes da execução.
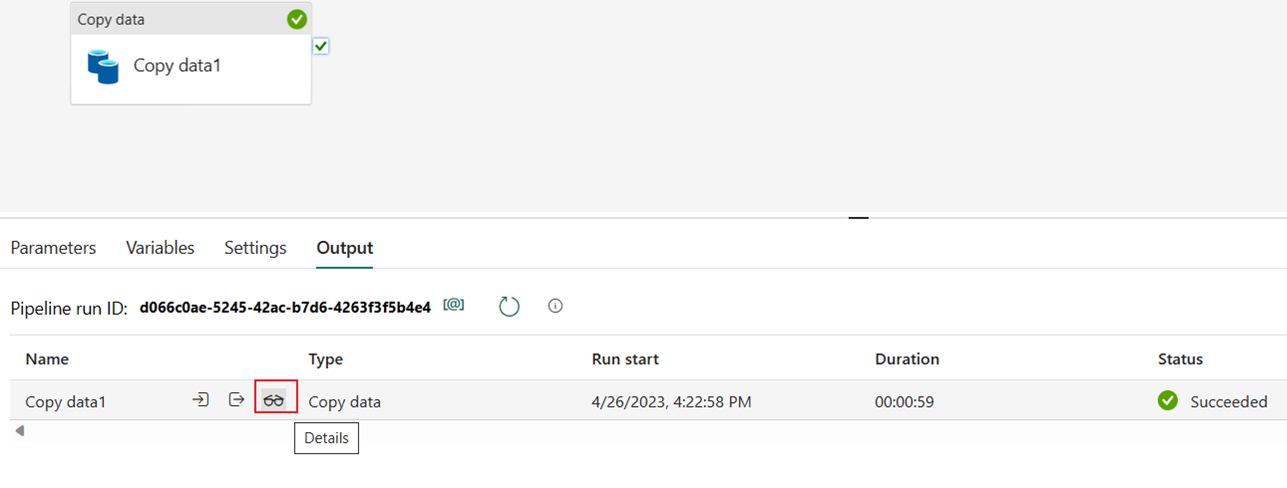
Os detalhes da execução mostram 1.508.501 linhas lidas e gravadas.
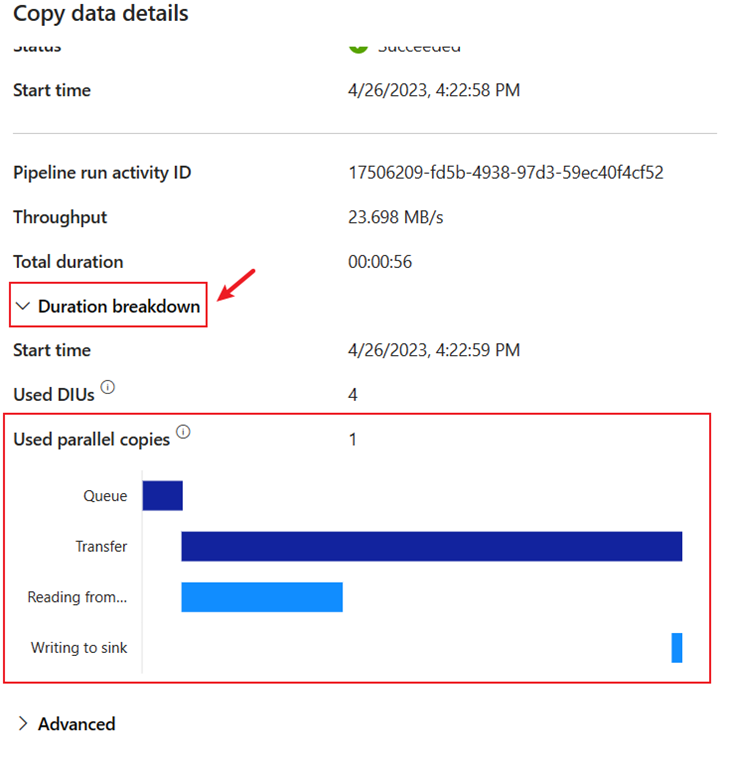
Expanda a seção Detalhamento da duração para ver a duração de cada fase da atividade Copy. Após revisar os detalhes da cópia, selecione Fechar.
Conteúdo relacionado
Neste primeiro módulo para nosso tutorial de ponta a ponta para sua primeira integração de dados usando o Data Factory no Microsoft Fabric, você aprendeu a:
- Crie um pipeline de dados.
- Adicione uma atividade Copy ao seu pipeline.
- Use dados de exemplo e crie um data Lakehouse para armazenar os dados em uma nova tabela.
- Execute o pipeline e exiba seus detalhes e o detalhamento da duração.
Continue para a próxima seção agora para criar seu fluxo de dados.