Transformar dados executando uma atividade de Definição de Trabalho do Spark
A atividade de Definição de Trabalho do Spark no Data Factory para Microsoft Fabric permite que você crie conexões com suas Definições de Trabalho do Spark e execute-as em um pipeline de dados.
Pré-requisitos
Para começar, você deve concluir os seguintes pré-requisitos:
- Uma conta de locatário com uma assinatura ativa. Crie uma conta gratuitamente.
- Um workspace é criado.
Adicionar uma atividade de definição de trabalho do Spark a um pipeline com a interface do usuário
Crie um novo pipeline de dados no seu ambiente de trabalho.
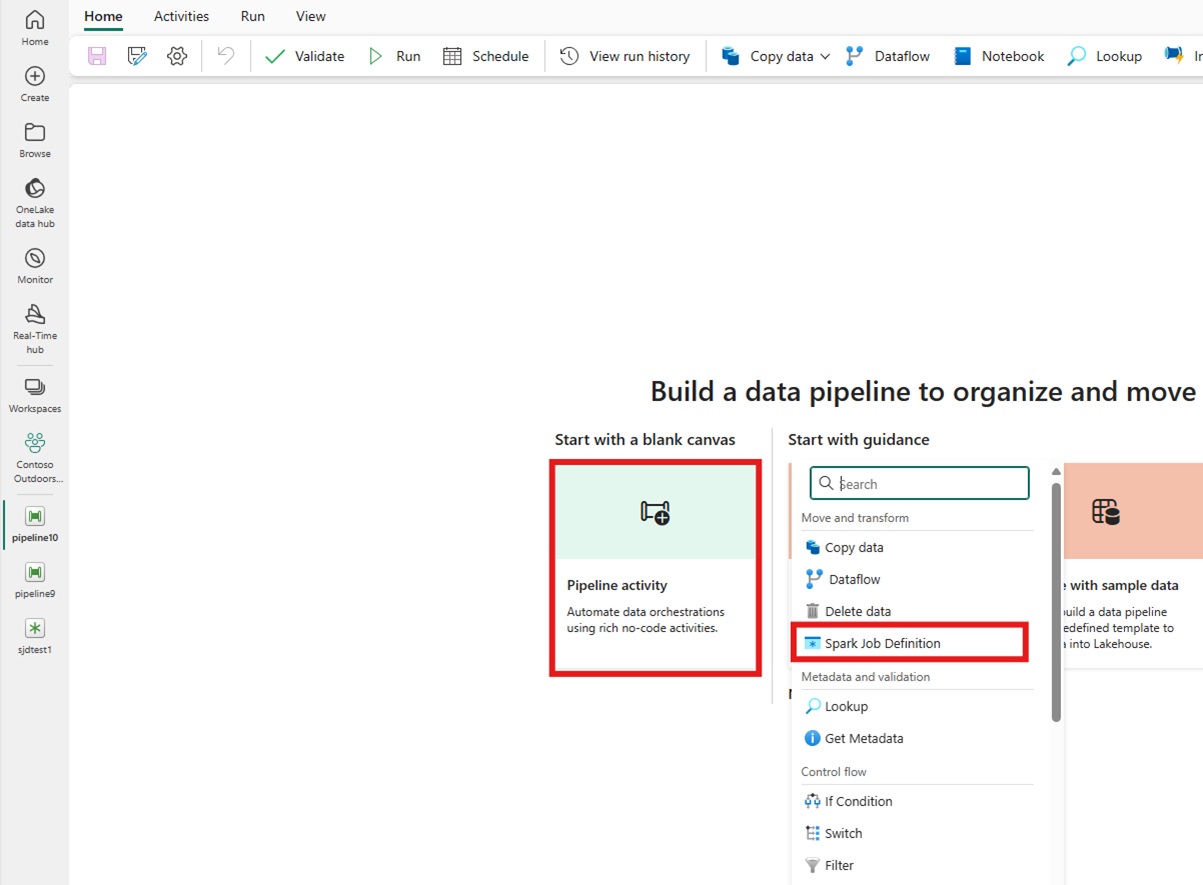
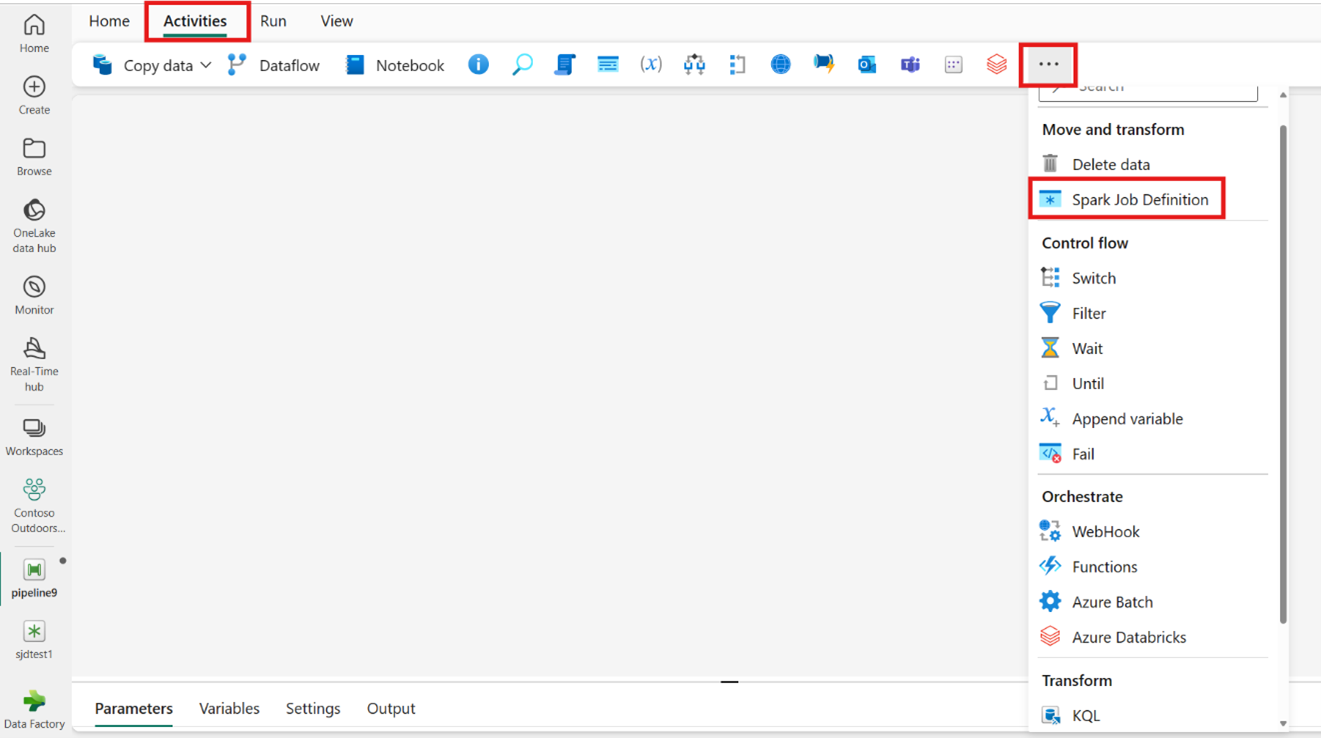
Pesquise a definição de trabalho do Spark no cartão da tela de início e selecione essa opção ou escolha a atividade na barra Atividades para adicioná-la à tela do pipeline.
Criando a atividade no cartão da tela inicial:
Criando a atividade a partir da barra de atividades:
Selecione a nova atividade de Definição de Trabalho do Spark na tela do editor de pipeline se ela ainda não estiver selecionada.
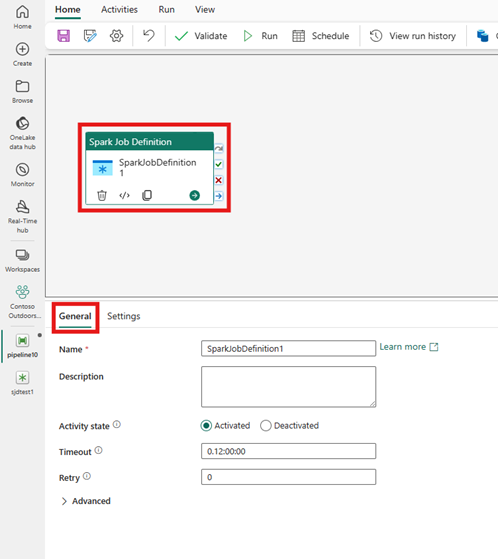
Consulte as diretrizes de Configurações gerais para definir as opções encontradas na guia Configurações gerais.



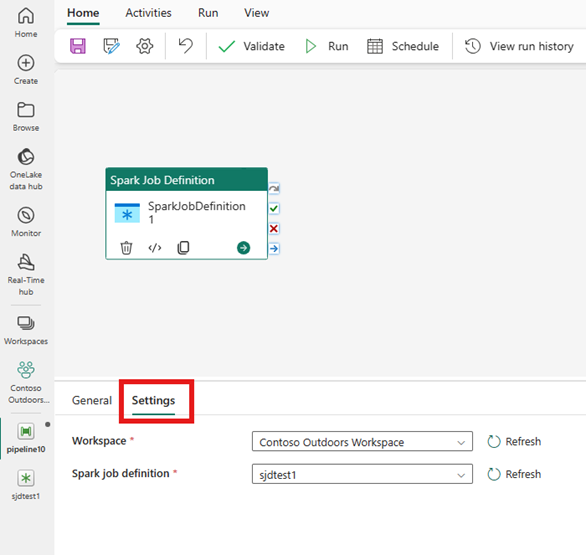
Configurações da atividade de Definição de Tarefa do Spark
Selecione a guia Configurações no painel de propriedades da atividade e, em seguida, selecione o Workspace do Fabric que contém a Definição de Trabalho do Spark que você deseja executar.
Limitações conhecidas
As limitações atuais na atividade definição de trabalho do Spark para Fabric Data Factory estão listadas aqui. Esta seção está sujeita a alterações.
- Atualmente, não há suporte para a criação de uma nova atividade de Definição de Trabalho do Spark dentro da atividade (em Configurações)
- O suporte à parametrização não está disponível.
- Embora dêmos suporte ao monitoramento da atividade por meio da guia de saída, ainda não é possível monitorar a Definição de Trabalho do Spark em um nível mais granular. Por exemplo, links para a página de monitoramento, status, duração e execuções anteriores da Definição de Trabalho do Spark não estão disponíveis diretamente no Data Factory. No entanto, você pode ver mais detalhes granulares na página de monitoramento da Definição de Trabalho do Spark.
Salvar e executar ou agendar o pipeline
Depois de configurar outras atividades necessárias para o pipeline, alterne para a guia Página Inicial na parte superior do editor de pipeline e selecione o botão Salvar para salvar o pipeline. Selecione Executar para executá-lo diretamente ou Agendar para agendá-lo. Você também pode exibir o histórico de execuções aqui ou definir outras configurações.
