Cenário de preços usando o fluxo de dados Gen2 para carregar 2 GB de dados Parquet em uma tabela do lakehouse
Nesse cenário, o fluxo de dados Gen2 foi usado para carregar 2 GB de dados Parquet armazenados no ADLS (Azure Data Lake Storage) Gen2 para uma tabela do Lakehouse no Microsoft Fabric. Usamos os dados de amostra da Taxi Green de NYC para os dados Parquet.
Os preços usados no exemplo a seguir são hipotéticos e não pretendem sugerir o preço real exato. Eles apenas demonstram como você pode estimar, planejar e gerenciar custos para projetos do Data Factory no Microsoft Fabric. Além disso, como as capacidades do Fabric são precificadas exclusivamente entre regiões, usamos o preço pago conforme o uso para uma capacidade do Fabric no Oeste dos EUA 2 (uma região típica do Azure), a US$ 0,18 por CU por hora. Consulte aqui os Preços do Microsoft Fabric para explorar outras opções de preços de capacidades do Fabric.
Configuração
Para realizar esse cenário, você precisa criar um fluxo de dados com as seguintes etapas:
- Inicializar o fluxo de dados: obtenha 2 GB de dados de arquivos Parquet da conta de armazenamento do ADLS Gen2.
- Configurar o Power Query:
- Navegue até o Power Query.
- Verifique se a opção do processo de preparo da consulta está habilitada.
- Prossiga para combinar os arquivos Parquet.
- Transformação de dados:
- Destaque cabeçalhos para maior clareza.
- Remova colunas desnecessárias.
- Ajuste os tipos de dados das colunas conforme necessário.
- Defina o destino dos dados de saída:
- Configure o Lakehouse como o destino de saída dos dados.
- Neste exemplo, um Lakehouse dentro do Fabric foi criado e utilizado.
Estimativa de custo usando o Aplicativo de Métricas do Fabric






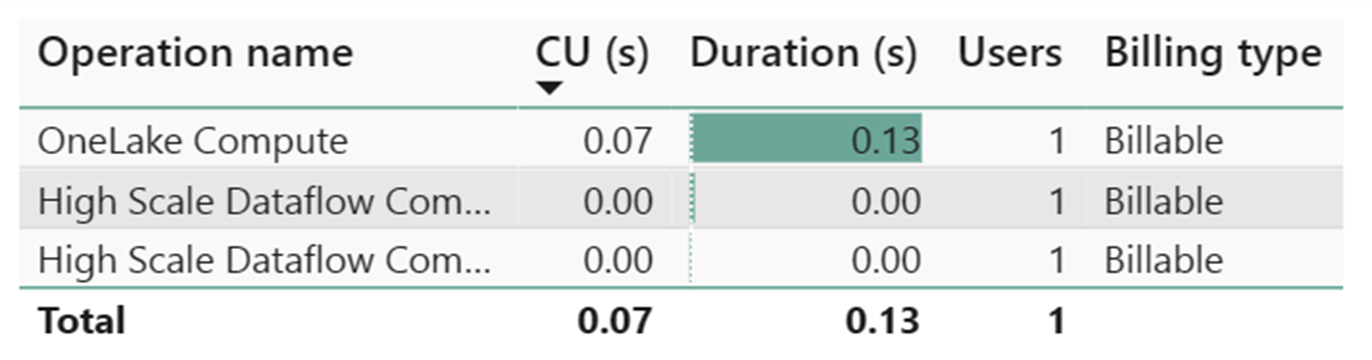
O medidor de computação de fluxo de dados de alta escala registrou atividade insignificante. O medidor de computação padrão para operações de atualização do Dataflow Gen2 consome 112.098.540 CUs (Unidades de Computação). É importante considerar que outras operações, inclusive a Consulta do Warehouse, a Consulta do Ponto de Extremidade do SQL e a Atualização sob Demanda do Conjunto de Dados, constituem aspectos detalhados da implementação do fluxo de dados Gen2 que são atualmente transparentes e necessárias para suas respectivas operações. No entanto, essas operações serão ocultadas em atualizações futuras e devem ser desconsideradas ao estimar os custos do fluxo de dados Gen2.
Observação
Embora relatado como uma métrica, a duração real da execução não é relevante ao calcular as horas efetivas de CU com o Aplicativo de Métricas do Fabric, uma vez que a métrica de segundos de CU que ele também relata já conta para sua duração.
| Metric | Computação Standard | Computação em alta escala |
|---|---|---|
| Total de segundos de CU | 112.098.54 segundos de CU | 0 segundos de CU |
| Horas-CU efetivas cobradas | 112,098.54 / (60*60) = 31,14 horas de CU | (0 + 60) / (60*0) = 1,32 hora de CU |
Custo total da execução a US$ 0,18/hora de CU = (31,14 horas de CU) * (US$ 0,18/hora de CU) ~= US$ 5,60