Formato Parquet no Data Factory no Microsoft Fabric
Este artigo descreve como configurar o formato Parquet no pipeline de dados do Data Factory no Microsoft Fabric.
Funcionalidades com suporte
O formato Parquet tem suporte para as seguintes atividades e conectores como origem e destino.
| Categoria | Conector/Atividade |
|---|---|
| Conector compatível | Amazon S3 |
| Amazon S3 Compatible | |
| Armazenamento de Blobs do Azure | |
| Azure Data Lake Storage Gen1 | |
| Azure Data Lake Storage Gen2 | |
| Arquivos do Azure | |
| Sistema de arquivos | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Arquivos do Lakehouse | |
| Oracle Cloud Storage | |
| SFTP | |
| Atividade com suporte | atividade Copy (Origem/Destino) |
| Atividade de pesquisa | |
| Atividade GetMetadata | |
| Excluir atividade |
Formato Parquet na atividade de cópia
Para configurar o formato binário, escolha sua conexão na origem ou no destino da atividade de cópia do pipeline de dados e selecioneBinário na lista suspensa de Formato de arquivo. Selecione Configurações para ver mais configurações desse formato.
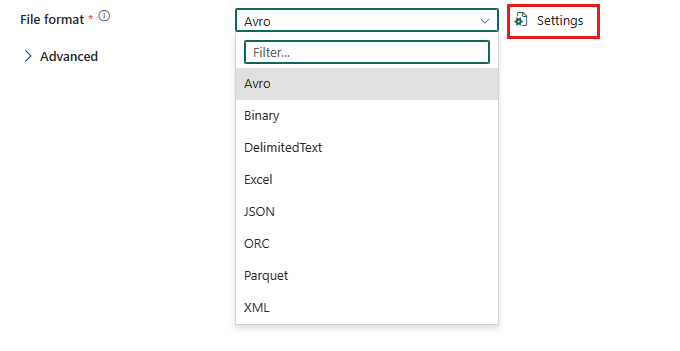
Formato Parquet como origem
Depois de selecionar Configurações na seção Formato de arquivo, as seguintes propriedades são mostradas na caixa de diálogo pop-up Configurações de formato de arquivo.
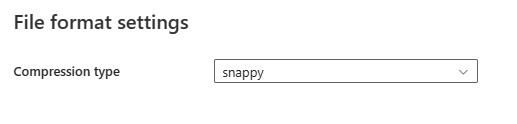
- Tipo de compactação: escolha o codec de compactação usado para ler arquivos Parquet na lista suspensa. Você pode escolher entre None, gzip (.gz), snappy, lzo, Brotli (.br), Zstandard, lz4, lz4frame, bzip2 (.bz2)ou lz4hadoop.
Formato Parquet como destino
Depois de selecionar Configurações, as seguintes propriedades são mostradas na caixa de diálogo pop-up Configurações de formato de arquivo.
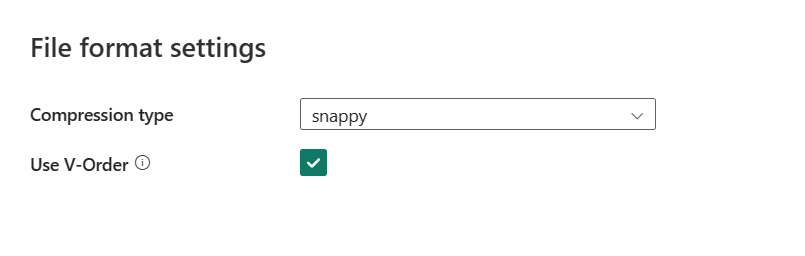
Tipo de compactação: escolha o codec de compactação usado para ler arquivos Parquet na lista suspensa. Você pode escolher entre None, gzip (.gz), snappy, lzo, Brotli (.br), Zstandard, lz4, lz4frame, bzip2 (.bz2)ou lz4hadoop.
Usar Ordem V: habilite uma otimização de tempo de gravação para o formato de arquivo parquet. Para obter mais informações, consulte Otimização de tabela do Delta Lake e V-Order. Ele é habilitado por padrão.
Em Configurações avançadas na guia Destino , as seguintes propriedades relacionadas ao formato Parquet são exibidas.
- Máximo de linhas por arquivo: ao gravar dados em uma pasta, você pode optar por gravar em vários arquivos e especificar o máximo de linhas por arquivo. Especifique as linhas máximas que você deseja gravar por arquivo.
- Prefixo de nome de arquivo: aplicável quando o máximo de linhas por arquivo é configurado. Especifique o prefixo do nome do arquivo ao gravar dados em vários arquivos, resultando neste padrão:
<fileNamePrefix>_00000.<fileExtension>. Se não for especificado, o prefixo de nome de arquivo será gerado automaticamente. Essa propriedade não se aplica quando a origem é um repositório baseado em arquivo ou um armazenamento de dados habilitado para uma opção de partição.
Resumo da tabela
Parquet como fonte
As propriedades a seguir têm suporte na seção Origem da atividade de cópia ao usar o formato de texto delimitado.
| Nome | Descrição | Valor | Obrigatório | Propriedade de script JSON |
|---|---|---|---|---|
| Formato de arquivo | O formato de arquivo que você deseja usar. | Parquet | Sim | tipo (em datasetSettings):Parquet |
| Tipo de compactação | O codec de compactação usado para ler/gravar arquivos binários. | Escolha entre: Nenhuma gzip (.gz) snappy lzo Brotli (.br) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
Não | compressionCodec: gzip snappy lzo brotli zstd lz4 lz4frame bz2 lz4hadoop |
Parquet como destino
As propriedades a seguir são compatíveis na seção Destino da atividade de cópia ao usar o formato de texto delimitado.
| Nome | Descrição | Valor | Obrigatório | Propriedade de script JSON |
|---|---|---|---|---|
| Formato de arquivo | O formato de arquivo que você deseja usar. | Parquet | Sim | tipo (em datasetSettings):Parquet |
| Usar ordem V | Uma otimização de tempo de gravação para o formato de arquivo parquet. | Selecionado ou não selecionado | Não | enableVertiParquet |
| Tipo de compactação | O codec de compactação usado para ler/gravar arquivos binários. | Escolha entre: Nenhuma gzip (.gz) snappy lzo Brotli (.br) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
Não | compressionCodec: gzip snappy lzo brotli zstd lz4 lz4frame bz2 lz4hadoop |
| Máximo de linhas por arquivo | Ao gravar dados em uma pasta, você pode optar por gravar em vários arquivos e especificar o máximo de linhas por arquivo. Especifique as linhas máximas que você deseja gravar por arquivo. | <suas linhas máximas por arquivo > | Não | maxRowsPerFile |
| Prefixo de nome de arquivo | Aplicável quando o Máximo de linhas por arquivo é configurado. Especifique o prefixo do nome do arquivo ao gravar dados em vários arquivos, resultando neste padrão: <fileNamePrefix>_00000.<fileExtension>. Se não for especificado, o prefixo de nome de arquivo será gerado automaticamente. Essa propriedade não se aplica quando a origem é um repositório baseado em arquivo ou um armazenamento de dados habilitado para uma opção de partição. |
<o prefixo do seu nome de arquivo > | Não | fileNamePrefix |