Início rápido: Crie seu primeiro fluxo de dados para obter e transformar dados
Os fluxos de dados são uma tecnologia de preparação de dados de autoatendimento baseada em nuvem. Neste artigo, você criará seu primeiro fluxo de dados, obterá dados para seu fluxo de dados, transformará os dados e publicará o fluxo de dados.
Pré-requisitos
Os seguintes pré-requisitos são necessários antes de começar:
- Uma conta de locatário do Microsoft Fabric com uma assinatura ativa. Criar uma conta gratuita.
- Certifique-se que você tenha um workspace habilitado para o Microsoft Fabric: Criar um workspace.
Criação de um fluxo de dados
Nesta seção, você criará seu primeiro fluxo de dados.
Alternar para a experiência do Data factory.
Navegue até seu workspace do Microsoft Fabric.
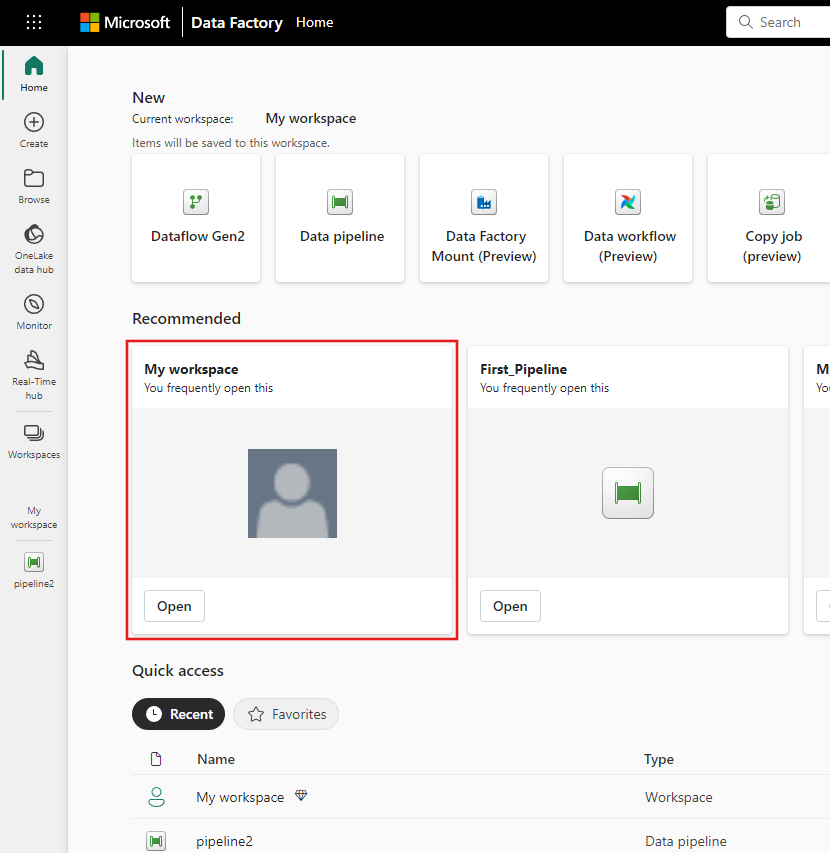
Selecione Novo e selecione Dataflow Gen2.
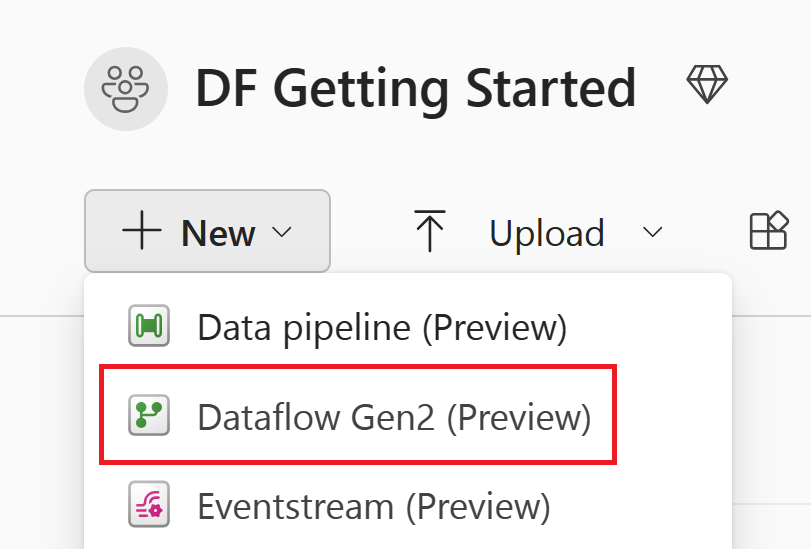

Obter dados
Vamos obter alguns dados! Nesse exemplo, você obterá dados de um serviço OData. Use as etapas a seguir para obter dados em seu fluxo de dados.
No editor de fluxo de dados, selecione Obter dados e, em seguida, selecione Mais.
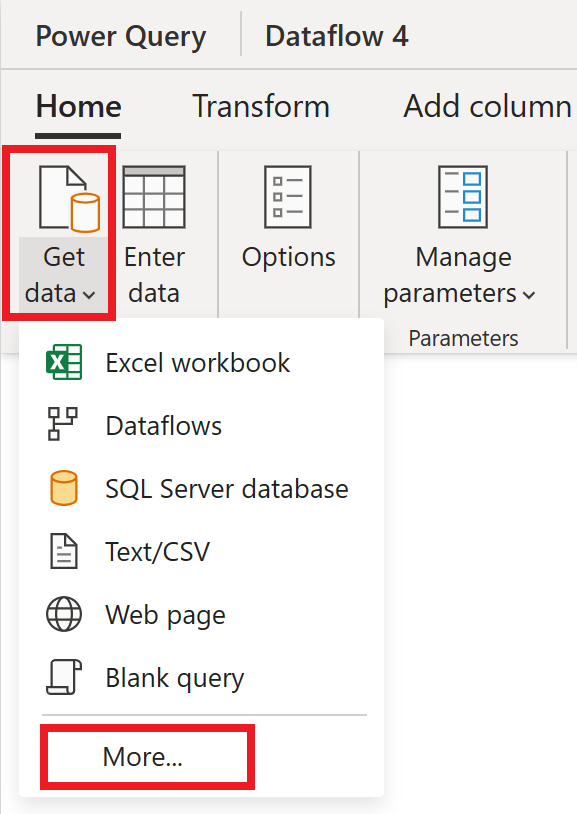
Em Escolher a fonte de dados, selecione Exibir mais.

Em Nova fonte, selecione Outro>OData como a fonte de dados.

Insira o URL
https://services.odata.org/v4/northwind/northwind.svc/e, em seguida, selecione Avançar.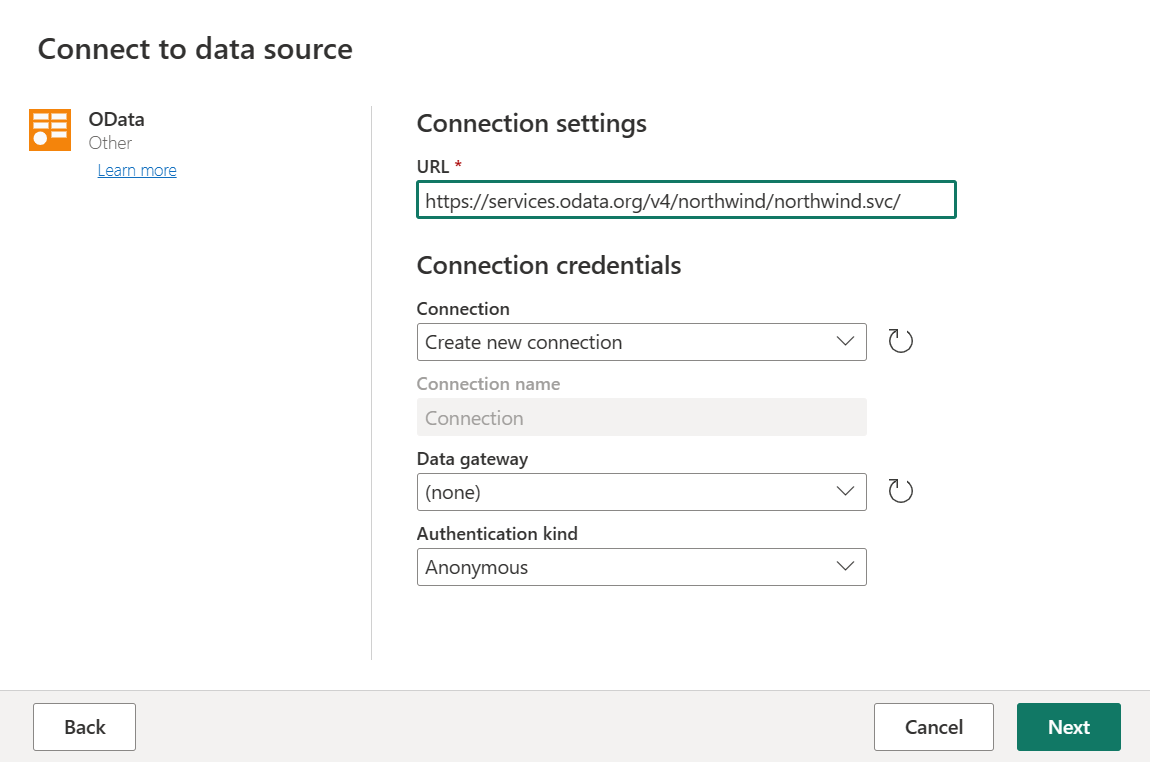
Selecione as tabelas Ordens e Clientes e, em seguida, selecione Criar.




Você pode aprender mais sobre a experiência e a funcionalidade de obtenção de dados em Obter visão geral de dados.
Aplicar transformações e publicar
Você acaba de carregar seus dados em seu primeiro fluxo de dados. Parabéns! Agora é hora de aplicar algumas transformações para deixar esses dados na forma desejada.
Você realiza essa tarefa no editor do Power Query. Você pode encontrar uma visão geral detalhada do editor do Power Query na interface do usuário do Power Query.
Siga estas etapas para aplicar transformações e publicar:
Confirme se as Ferramentas de criação de perfil de dados estejam habilitadas navegando para Página Inicial>Opções>Opções globais.
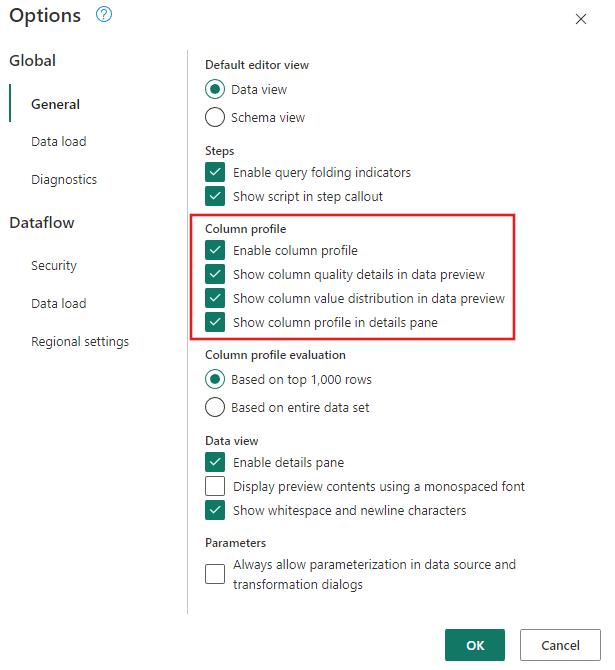
Além disso, ative a exibição de diagrama usando as opções na guia Exibir na faixa de opções do Editor do Power Query ou selecionando o ícone de exibição de diagrama no canto inferior direito da janela do Power Query.

Na tabela Ordens, você calculará o número total de ordens por cliente. Para atingir esse objetivo, selecione a coluna CustomerID na visualização de dados e, em seguida, selecione Agrupar por na guia Transformar na faixa de opções.

Você realizará uma contagem de linhas como a agregação em Agrupar por. Você pode aprender mais sobre os recursos de Agrupar por em Agrupando ou resumindo linhas.
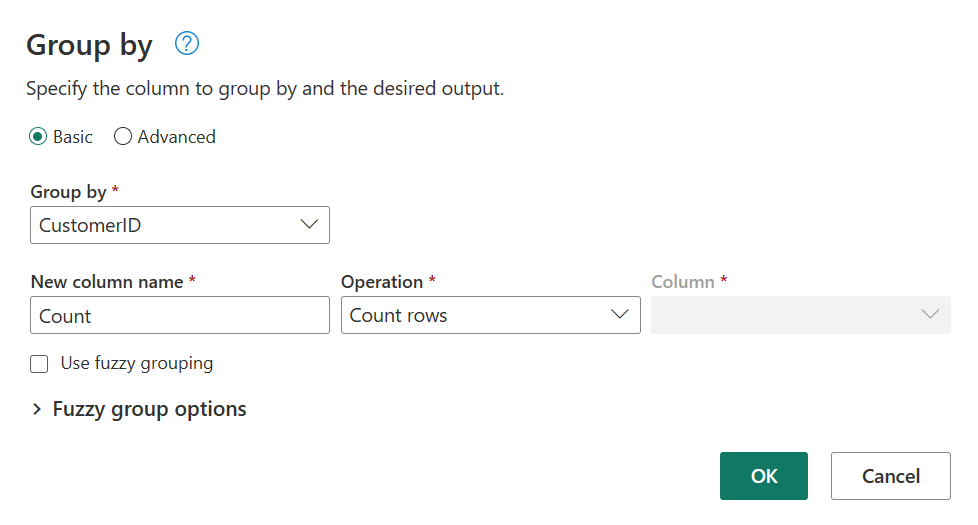
Após agrupar os dados na tabela Ordens, obteremos uma tabela de duas colunas com CustomerID e Contagem como colunas.

Em seguida, você deseja combinar os dados da tabela Clientes com a Contagem de ordens por cliente. Para combinar dados, selecione a consulta Clientes na Exibição do Diagrama e use o menu "⋮" para acessar a transformação Mesclar consultas como nova.
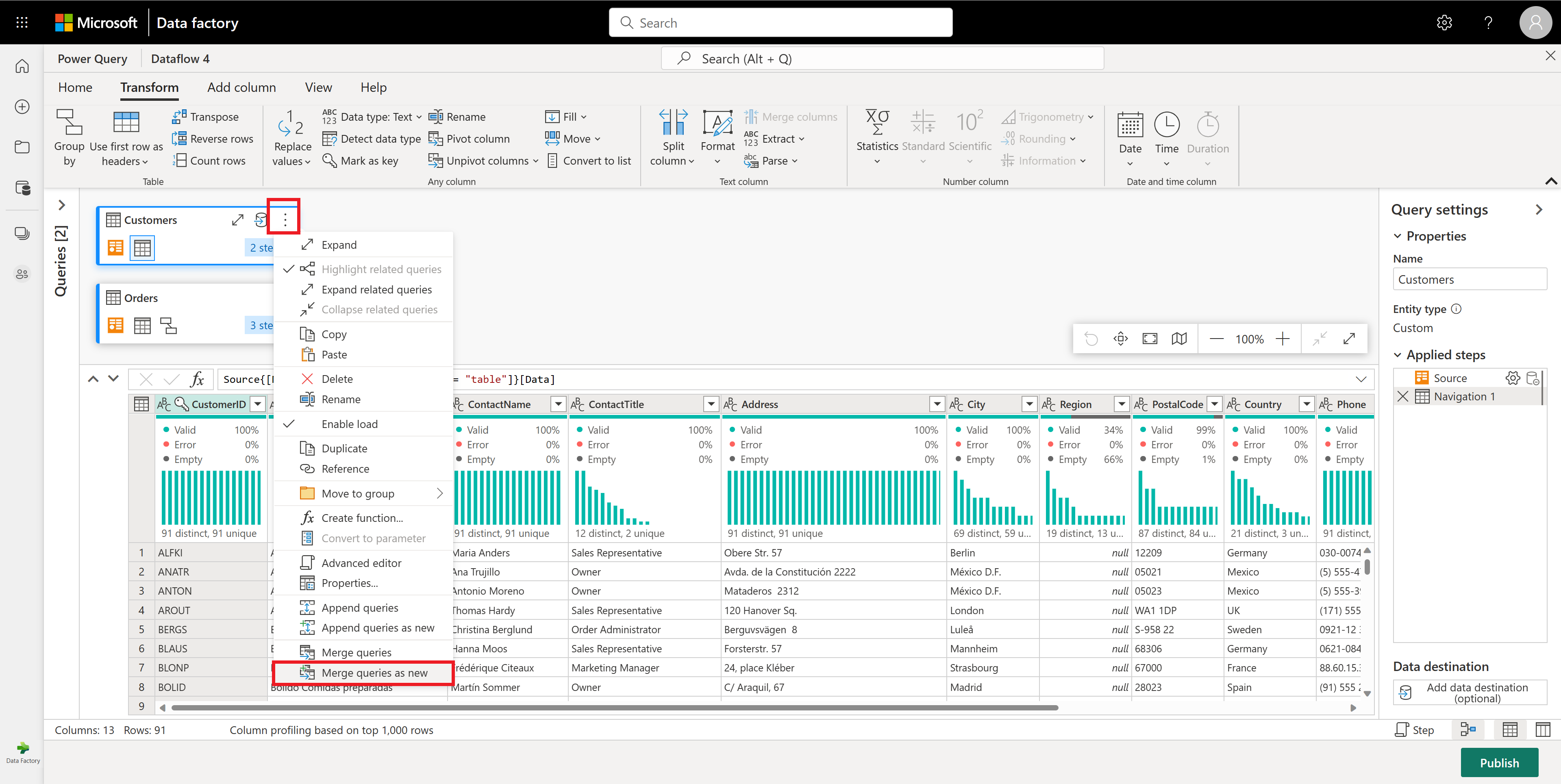
Configure a Operação de mesclagem conforme mostrado na captura de tela a seguir selecionando CustomerID como a coluna correspondente em ambas as tabelas. Depois, selecione Ok.
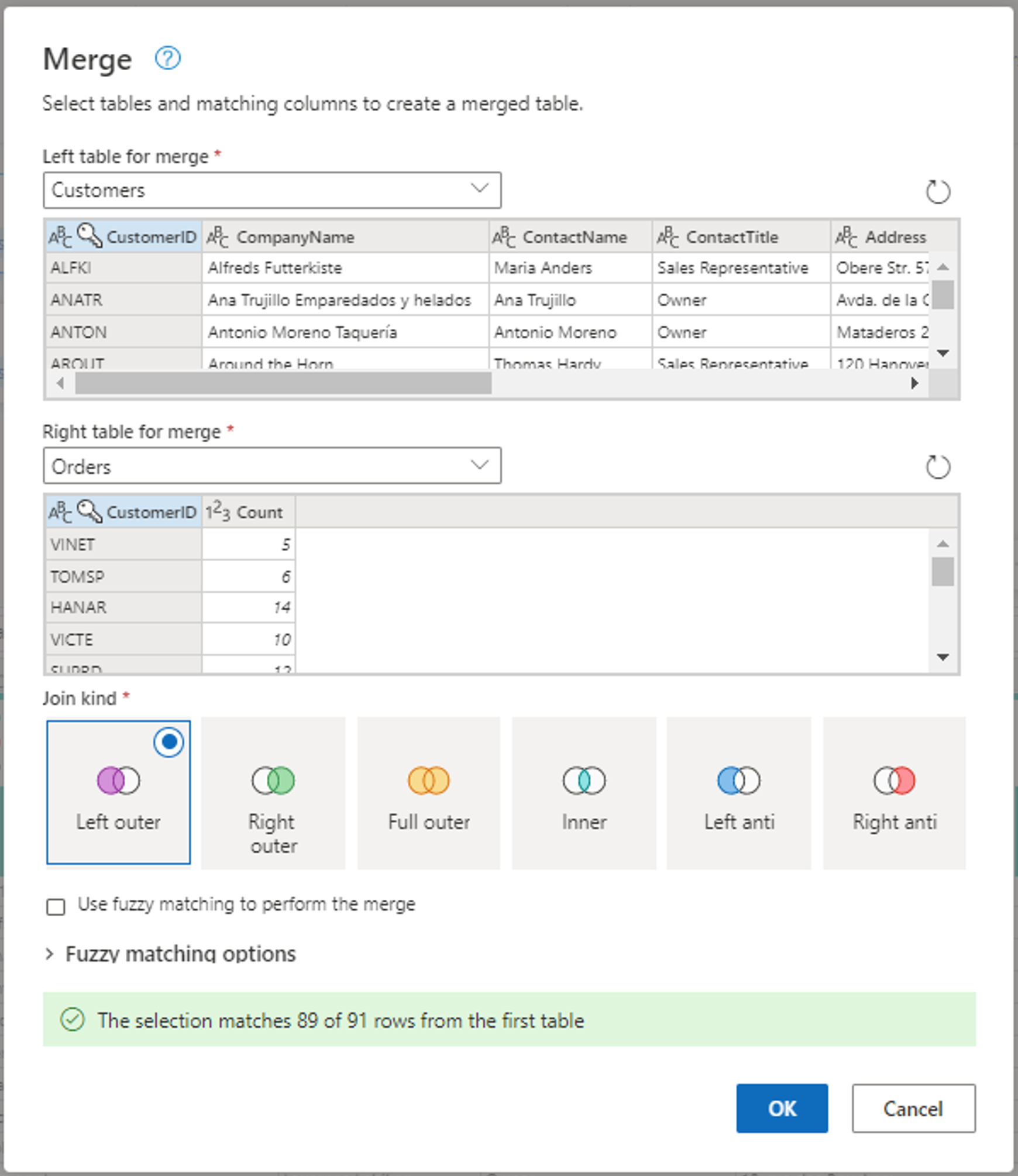
Captura de tela da janela Mesclar, com a tabela esquerda para mesclagem definida como a tabela Clientes e a tabela direita para mesclagem definida como a tabela Ordens. A coluna CustomerID é selecionada para as tabelas Clientes e Ordens. Além disso, o Variante de Junção é definido como Externo esquerdo. Todas as outras seleções são definidas com seu valor padrão.
Ao realizar a operação Mesclar consultas como novas, você obterá uma nova consulta com todas as colunas da tabela Clientes e uma coluna com os dados aninhados da tabela Ordens.

Nesse exemplo, você está interessado apenas em um subconjunto de colunas na tabela Clientes. Você selecionará essas colunas usando a exibição do esquema. Habilite a exibição do esquema no botão de alternância no canto inferior direito do editor de fluxos de dados.
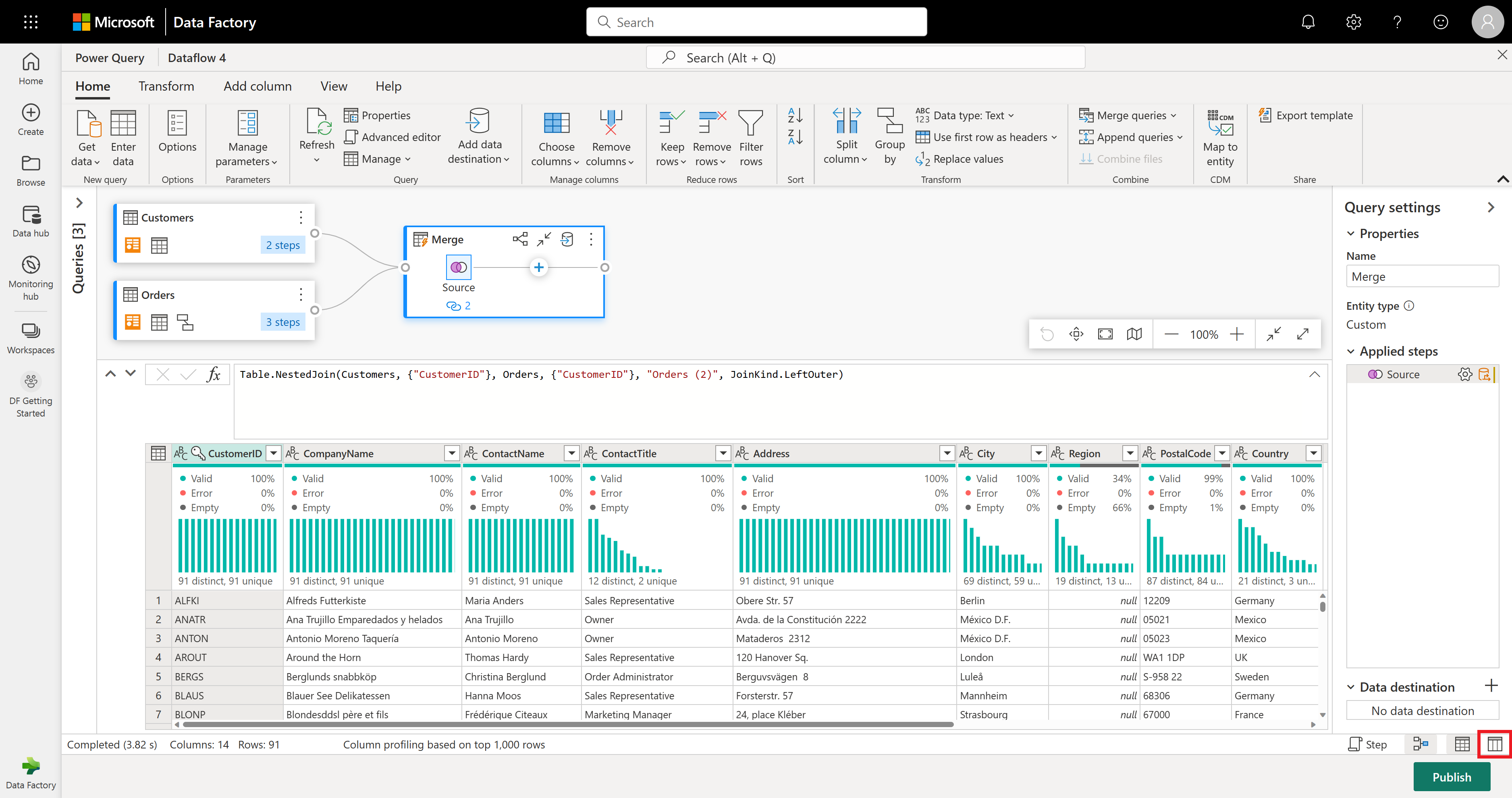
A exibição do esquema fornece uma exibição focada nas informações do esquema de uma tabela, incluindo nomes de colunas e tipos de dados. O modo de exibição de esquema tem um conjunto de ferramentas de esquema disponíveis por meio de uma guia de faixa de opções contextual. Nesse cenário, você selecionará as colunas CustomerID, CompanyName e Ordens (2) e, em seguida, selecionará o botão Remover colunas e selecionará Remover outras colunas na guia Ferramentas de esquema.

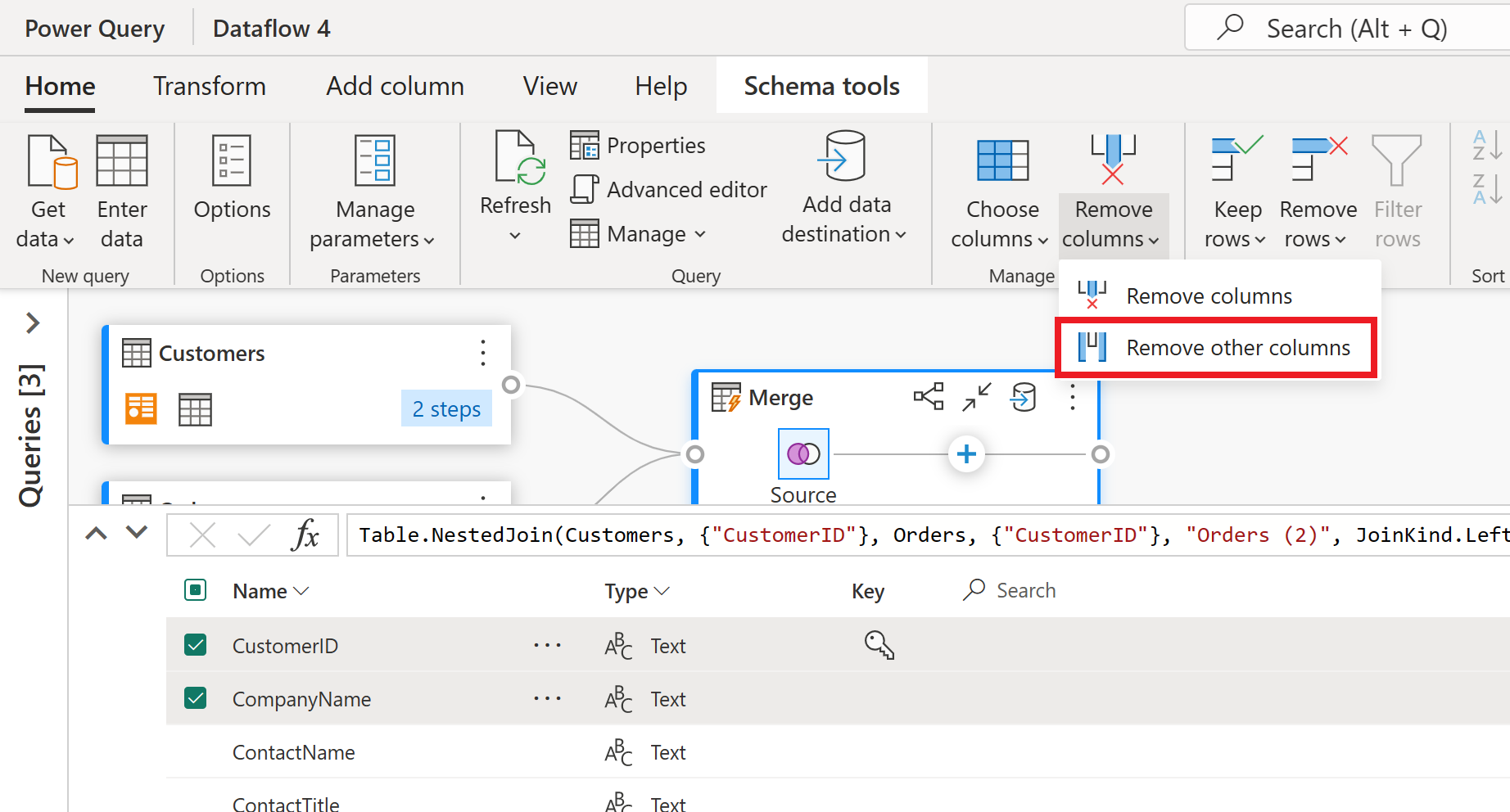
A coluna Ordens (2) contém informações aninhadas resultantes da operação de mesclagem que você executou algumas etapas atrás. Agora, volte para a exibição de dados selecionando o botão Mostrar exibição de dados ao lado do botão Mostrar exibição de esquema no canto inferior direito da interface do usuário. Em seguida, use a transformação Expandir coluna no cabeçalho da coluna Ordens (2) para selecionar a coluna Contagem.

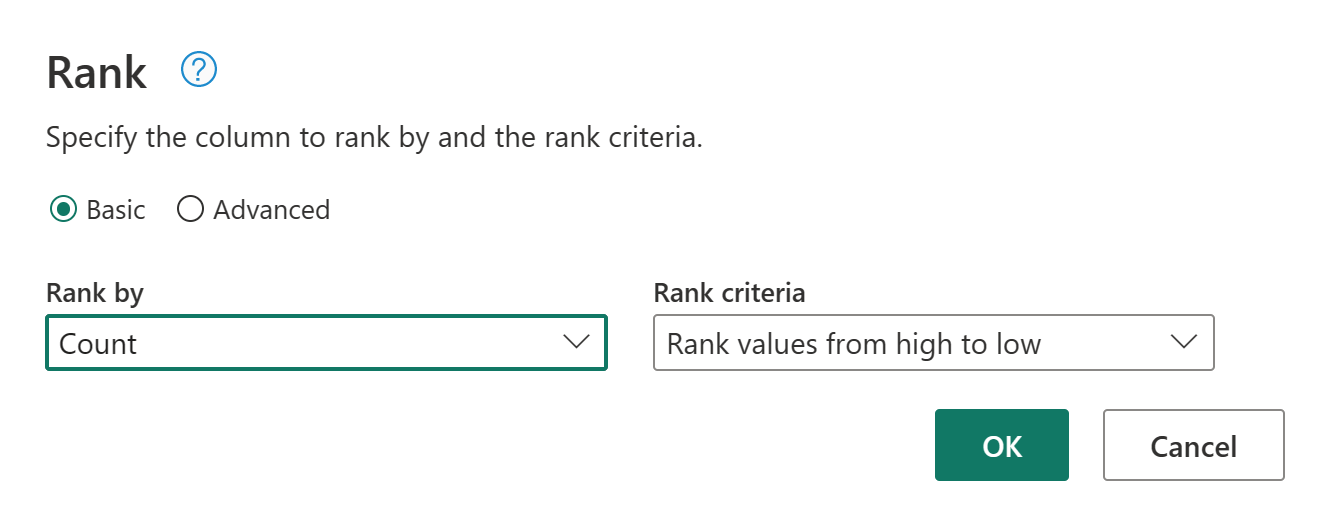
Como operação final, você deseja classificar seus clientes com base no número de ordens. Selecione a coluna Contagem e, em seguida, selecione o botão Classificar coluna na guia Adicionar Coluna na faixa de opções.

Mantenha as configurações padrão em Classificar coluna. Em seguida, selecione OK para aplicar essa transformação.
Agora renomeie a consulta resultante como Clientes classificados usando o painel Configurações da consulta no lado direito da tela.

Agora que você terminou de transformar e combinar os seus dados, você pode definir as suas configurações de destino de saída. Selecione Escolher destino de dados na parte inferior do painel Configurações da consulta.

Para esta etapa, configure uma saída para seu lakehouse se tiver um disponível ou ignore essa etapa se não tiver. Nessa experiência, você será capaz de configurar o lakehouse de destino e a tabela para os resultados de sua consulta, além do método de atualização (Anexar ou Substituir).


Seu fluxo de dados agora está pronto para ser publicado. Revise as consultas na exibição do diagrama e selecione Publicar.

Agora você retornará ao espaço de trabalho. Um ícone giratório ao lado do nome do fluxo de dados indica que a publicação está em andamento. Depois que a publicação for concluída, seu fluxo de dados estará pronto para ser atualizado!
Importante
Quando o primeiro Fluxo de Dados Gen2 for criado em um espaço de trabalho, os itens do Lakehouse e Warehouse serão provisionados junto com seus modelos semânticos e do ponto de extremidade de análise SQL relacionados. Esses itens são compartilhados por todos os fluxos de dados no espaço de trabalho e são necessários para a operação do Fluxo de Dados Gen2, não devem ser excluídos e não devem ser usados diretamente pelos usuários. Os itens são um detalhe de implementação do Fluxo de Dados Gen2. Os itens não são visíveis no espaço de trabalho, mas podem estar acessíveis em outras experiências, como as experiências de Notebook, ponto de extremidade de análise do SQL, Lakehouse e Warehouse. Você pode reconhecer os itens pelo prefixo no nome. O prefixo dos itens é "DataflowsStaging".
Em seu workspace, selecione o ícone Agendar Atualização.

Ative a atualização agendada, selecione Adicionar outro horário e configure a atualização conforme mostrado na captura de tela a seguir.
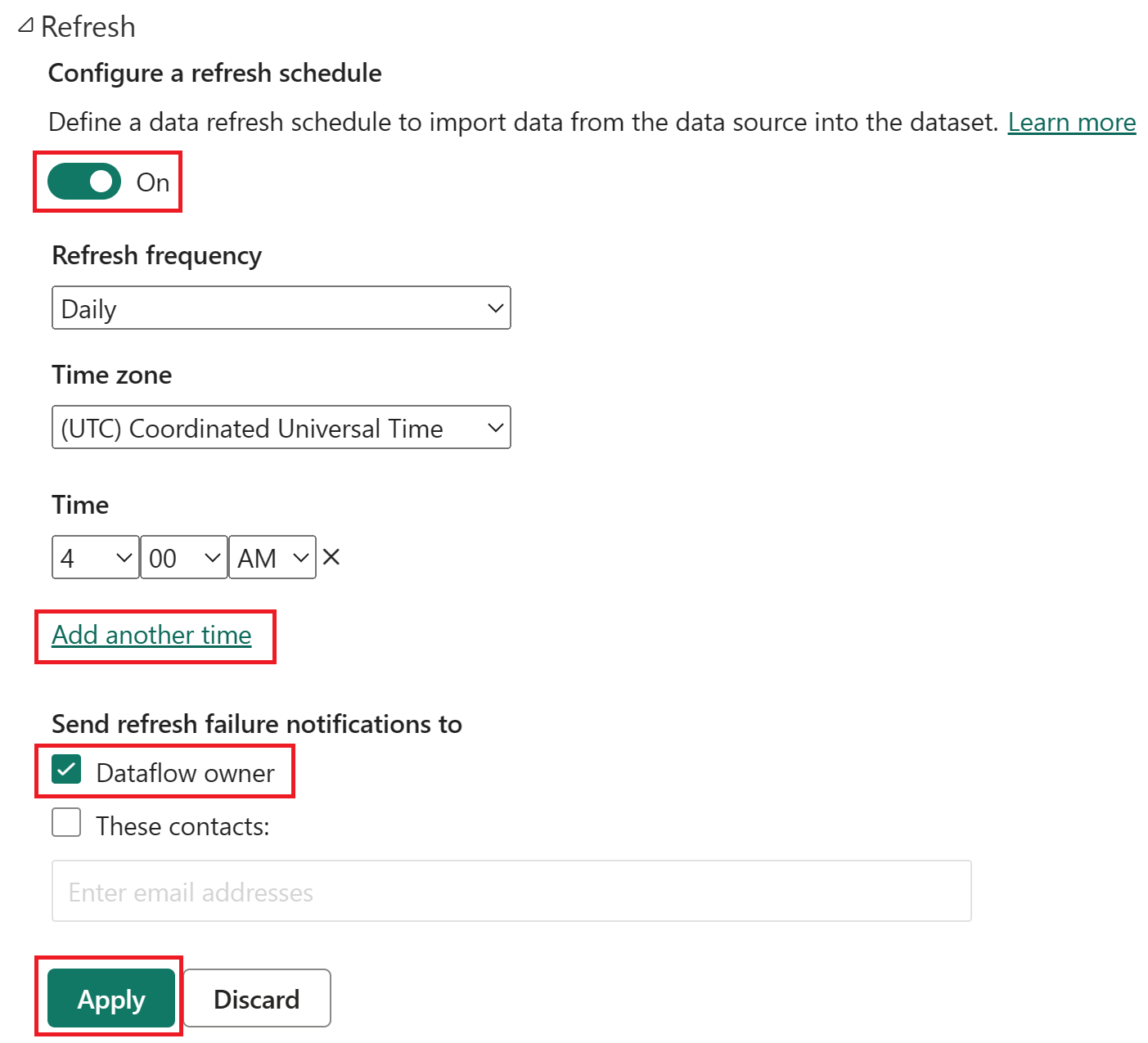
Captura de tela das opções de atualização agendada, com a atualização agendada ativada, a frequência de atualização definida como Diária, o Fuso horário definido como horário universal coordenado e a Hora definida como 4h. O botão Ativar, a seleção Adicionar outro horário, o proprietário do fluxo de dados e o botão Aplicar são enfatizados.













Limpar os recursos
Se você não pretende continuar usando esse fluxo de dados, exclua o fluxo de dados usando as etapas a seguir:
Navegue até seu workspace do Microsoft Fabric.
Selecione as reticências verticais ao lado do nome do fluxo de dados e selecione Excluir.
Selecione Excluir para confirmar a exclusão do seu fluxo de dados.
Conteúdo relacionado
O fluxo de dados neste exemplo mostra como carregar e transformar dados no Dataflow Gen2. Você aprendeu a:
- Criar um Dataflow Gen2.
- Transformar dados.
- Defina as configurações de destino para dados transformados.
- Executar e agendar seu pipeline de dados.
Prossiga para o próximo artigo para saber como criar seu primeiro pipeline de dados.