Use um notebook para carregar dados em seu lakehouse
Nesse tutorial você vai aprender a ler/gravar os dados em seu Fabric lakehouse com um notebook. O Fabric oferece suporte à API do Spark e a API do Pandas é para atingir esse objetivo.
Carregar dados com uma API do Apache Spark
Na célula de código do notebook, use o exemplo de código a seguir para ler os dados da origem e carregá-los em Arquivos, Tabelas ou em ambas as seções do seu Lakehouse.
Para especificar o local de onde ler, você pode usar o caminho relativo se os dados forem do lakehouse padrão do notebook atual. Ou, se os dados forem de um lakehouse diferente, você poderá usar o caminho absoluto do Sistema de Arquivos de Blobs do Azure (ABFS). Copie esse caminho no menu de contexto dos dados.
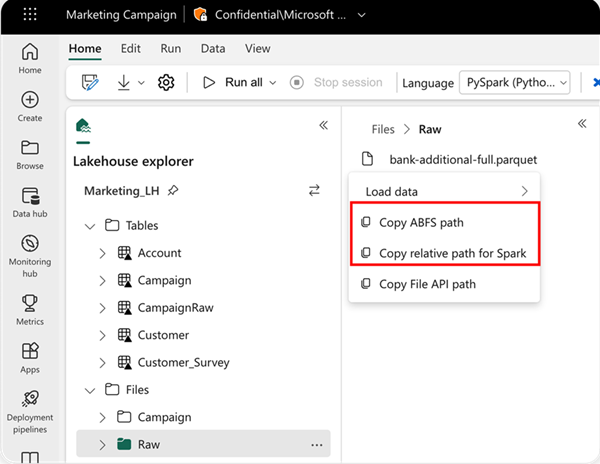
Copiar caminho ABFS: essa opção retorna o caminho absoluto do arquivo.
Copiar caminho relativo para o Spark: essa opção retorna o caminho relativo do arquivo no lakehouse padrão.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Carregue dados com a API do Pandas
Para dar suporte à API do Pandas, o lakehouse padrão é montado automaticamente no notebook. O ponto de montagem é "/lakehouse/default/". Você pode usar esse ponto de montagem para ler/gravar dados de/para o Lakehouse padrão. A opção "Copiar Caminho da API de Arquivo" do menu de contexto retorna o caminho da API de Arquivo desse ponto de montagem. O caminho retornado da opção Copiar caminho ABFS também funciona para a API do Pandas.
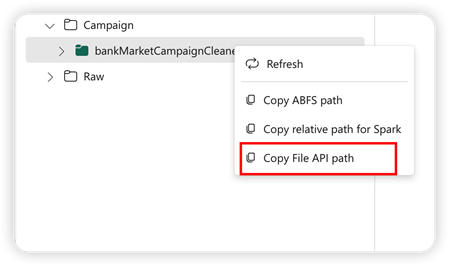
Copiar Caminho da API de Arquivo:essa opção retorna o caminho sob o ponto de montagem do lakehouse padrão.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Dica
Para a API do Spark, use a opção Copiar caminho ABFS ou Copiar caminho relativo para o Spark para obter o caminho do arquivo. Para a API do Pandas, use a opção Copiar caminho ABFS ou Copiar caminho da API de Arquivo para obter o caminho do arquivo.
A maneira mais rápida de fazer com que o código funcione com a API do Spark ou a API do Pandas é usar a opção Carregar dados e selecionar a API que você deseja usar. O código é gerado automaticamente em uma nova célula de código do notebook.
