Obter dados de streaming no lakehouse e acessar com o ponto de extremidade de análise do SQL
Este início rápido explica como criar uma Definição de Trabalho do Spark que contém código Python com o Streaming Estruturado do Spark para obter dados em um lakehouse e, em seguida, servi-los por meio de um ponto de extremidade de análise do SQL. Depois de concluir este início rápido, você terá uma Definição de Trabalho do Spark que é executada continuamente e o ponto de extremidade de análise do SQL pode exibir os dados de entrada.
Executar um script do Python
Use o código Python a seguir que usa o streaming estruturado do Spark para obter dados em uma tabela lakehouse.
import sys from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession.builder.appName("MyApp").getOrCreate() tableName = "streamingtable" deltaTablePath = "Tables/" + tableName df = spark.readStream.format("rate").option("rowsPerSecond", 1).load() query = df.writeStream.outputMode("append").format("delta").option("path", deltaTablePath).option("checkpointLocation", deltaTablePath + "/checkpoint").start() query.awaitTermination()Salve o script como arquivo Python (.py) no computador local.
Criar um lakehouse
Use as seguintes etapas para criar um lakehouse:
Entre no portal do Microsoft Fabric.
Alterne para a experiência de Engenharia de Dados.
Navegue até o workspace desejado ou crie um novo, se necessário.
Para criar uma lakehouse, selecione Novo item no workspace e selecione Lakehouse.
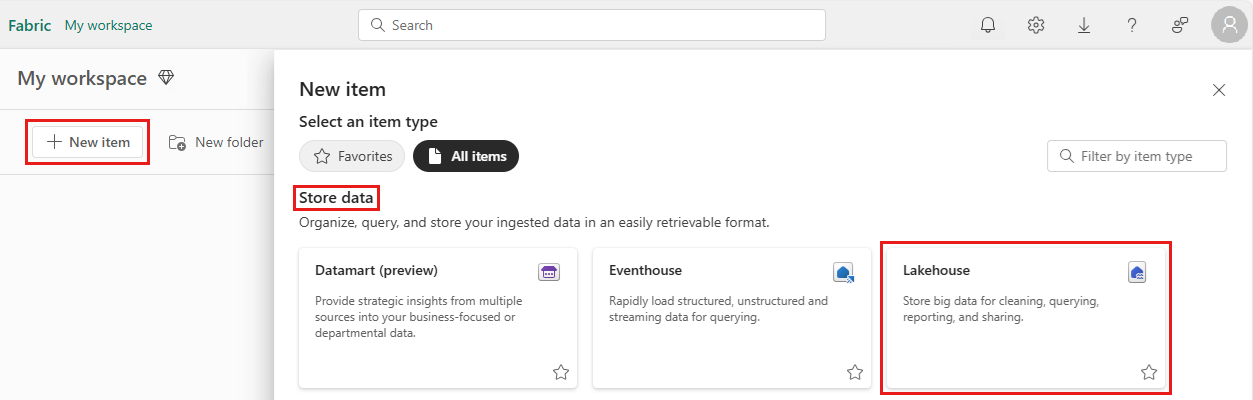
Insira o nome do lakehouse e selecione Criar.
Criar uma Definição de Trabalho do Spark
Execute as etapas a seguir para criar uma Definição de Trabalho do Spark:
No mesmo workspace em que você criou um lakehouse, selecione o ícone Criar no menu à esquerda.
Em "Engenharia de Dados", selecione Definição de Trabalho do Spark.
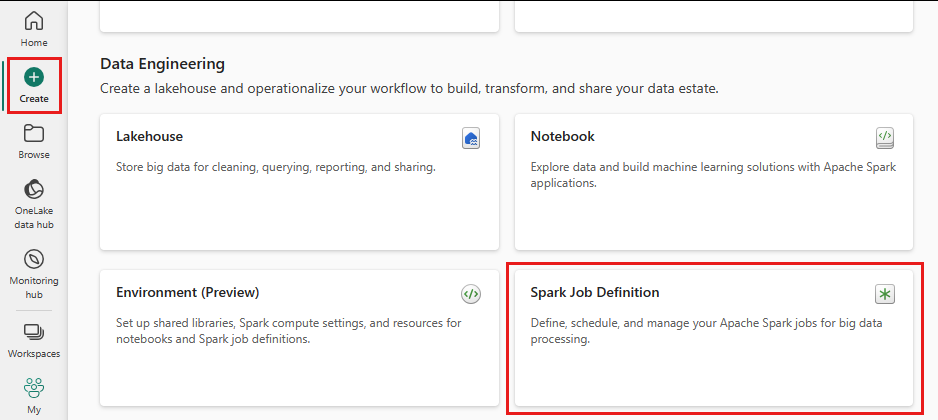
Insira o nome da Definição de Trabalho do Spark e selecione Criar.
Selecione Carregar e, então, selecione o arquivo Python que você criou na etapa anterior.
Em Referência do Lakehouse , escolha o lakehouse que você criou.
Definir política de repetição para Definição de Trabalho do Spark
Use as seguintes etapas para definir a política de repetição para sua Definição de Trabalho do Spark:
No menu superior, selecione o ícone Configuração .
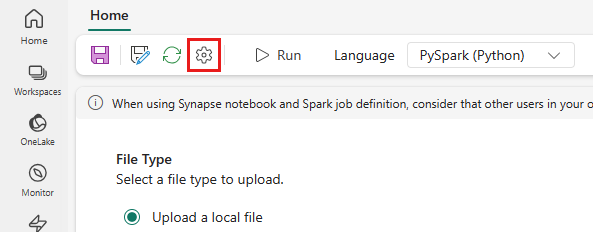
Abra a guia Otimização e defina o gatilho Política de Repetição como Ativado.
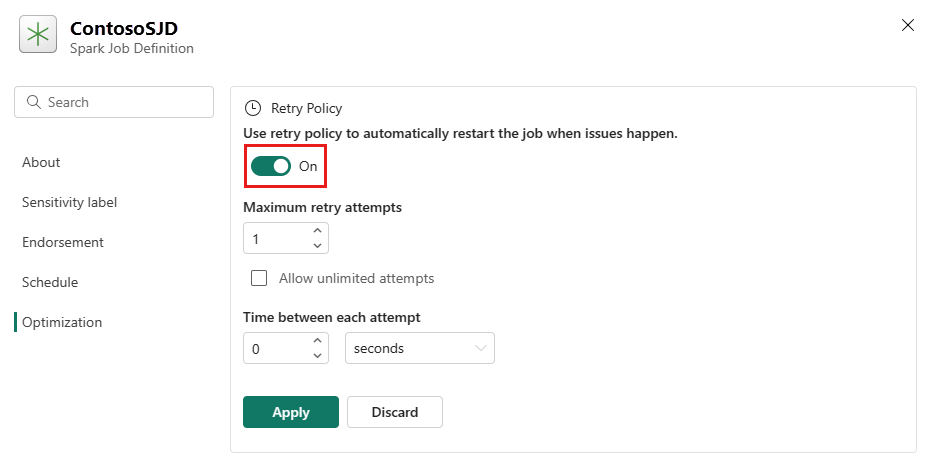
Defina o máximo de tentativas de repetição ou marcar Permitir tentativas ilimitadas.
Especifique o tempo entre cada tentativa de repetição e selecione Aplicar.
Observação
Há um limite de tempo de vida de 90 dias para a configuração da política de repetição. Depois que a política de repetição estiver habilitada, o trabalho será reiniciado de acordo com a política dentro de 90 dias. Após esse período, a política de repetição deixará de funcionar automaticamente e o trabalho será encerrado. Em seguida, os usuários precisarão reiniciar manualmente o trabalho, o que, por sua vez, reabilitará a política de repetição.
Executar e monitorar a Definição de Trabalho do Spark
No menu superior, selecione o ícone Executar.
Verifique se a Definição do Trabalho do Spark foi enviada com êxito e em execução.
Exibir dados usando um ponto de extremidade de análise do SQL
No modo de exibição do workspace, selecione o Lakehouse.
No canto direito, selecione Lakehouse e selecione Ponto de extremidade de análise do SQL.
Na exibição ponto de extremidade de análise do SQL em Tabelas, selecione a tabela que o script usa para obter dados. Em seguida, você pode visualizar seus dados do ponto de extremidade de análise do SQL.