Use a API Livy para enviar e executar trabalhos em lote Livy
Observação
A API Livy para a Engenharia de Dados do Fabric está em versão prévia.
Aplica-se a:✅ Engenharia e Ciência de Dados no Microsoft Fabric
Envie trabalhos em lote do Spark usando a API Livy para a Engenharia de Dados do Fabric.
Pré-requisitos
Fabric Premium ou Capacidade de Avaliação com um Lakehouse.
Um cliente remoto como Visual Studio Code com Jupyter Notebooks, PySpark e a Biblioteca de Autenticação da Microsoft (MSAL) para Python.
Um token de aplicativo do Microsoft Entra é necessário para acessar a API Rest do Fabric. Registrar um aplicativo na plataforma de identidade da Microsoft.
Alguns dados no seu lakehouse, este exemplo usa NYC Taxi & Limousine Commission green_tripdata_2022_08, um arquivo parquet carregado no lakehouse.
A API Livy define um ponto de extremidade unificado para operações. Substitua os espaços reservados {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID} e {Fabric_LakehouseID} pelos seus valores apropriados ao seguir os exemplos neste artigo.
Configure o Visual Studio Code para seu Lote de API Livy
Selecione Configurações do Lakehouse no seu Fabric Lakehouse.

Navegue até a seção ponto de extremidade Livy.
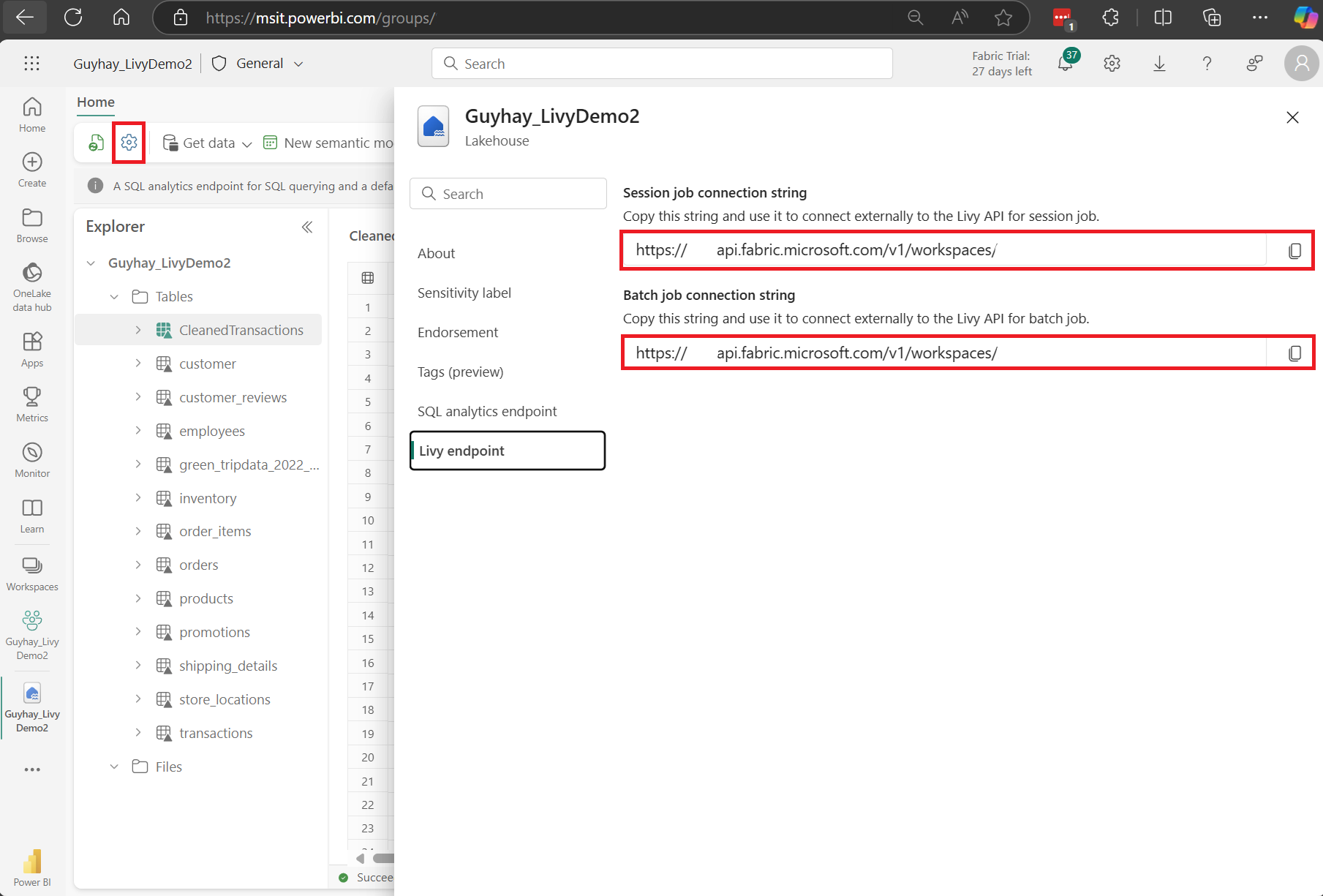
Copie a cadeia de conexão do Trabalho em lote (segundo quadro vermelho na imagem) para o seu código.
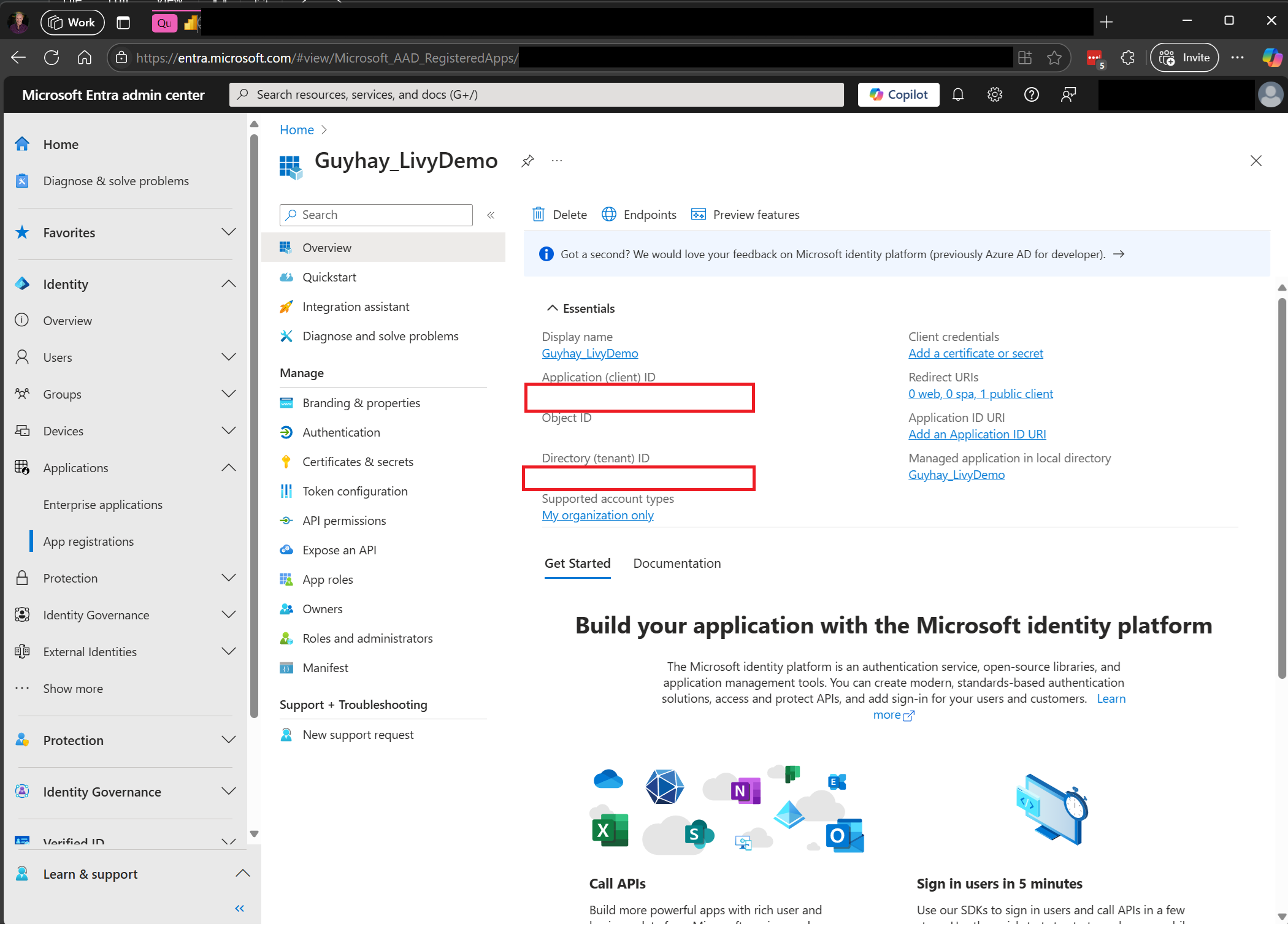
Navegue até o centro de administração do Microsoft Entra e copie tanto a ID do Aplicativo (cliente) quanto a ID do Diretório (locatário) para o seu código.



Crie um conteúdo do Spark e carregue no seu Lakehouse
Crie um notebook
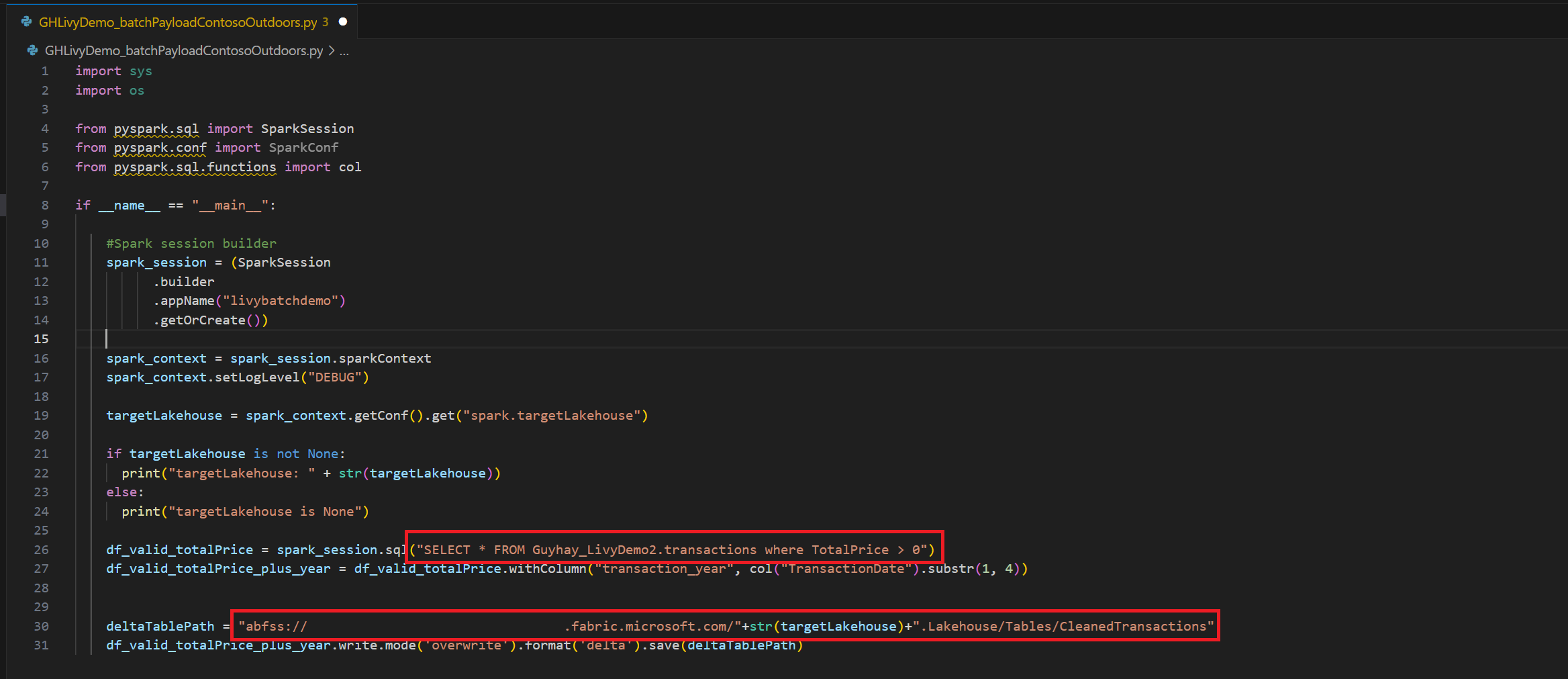
.ipynbno Visual Studio Code e insira o seguinte códigoimport sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("livybatchdemo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") targetLakehouse = spark_context.getConf().get("spark.targetLakehouse") if targetLakehouse is not None: print("targetLakehouse: " + str(targetLakehouse)) else: print("targetLakehouse is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM <YourLakeHouseDataTableName>.transactions where TotalPrice > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("TransactionDate").substr(1, 4)) deltaTablePath = "abfss:<YourABFSSpath>"+str(targetLakehouse)+".Lakehouse/Tables/CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)Salve o arquivo Python localmente. Este conteúdo de código Python contém duas instruções Spark que trabalham com dados em um Lakehouse e precisam ser carregadas no seu Lakehouse. Você precisará do caminho ABFS do conteúdo para fazer referência ao trabalho em lotes da API Livy no Visual Studio Code e ao nome da tabela Lakehouse na instrução Select SQL.
Carregue o conteúdo Python na seção de arquivos do seu Lakehouse. Obter dados > Carregar arquivos > clique na caixa de entrada de Arquivos >.
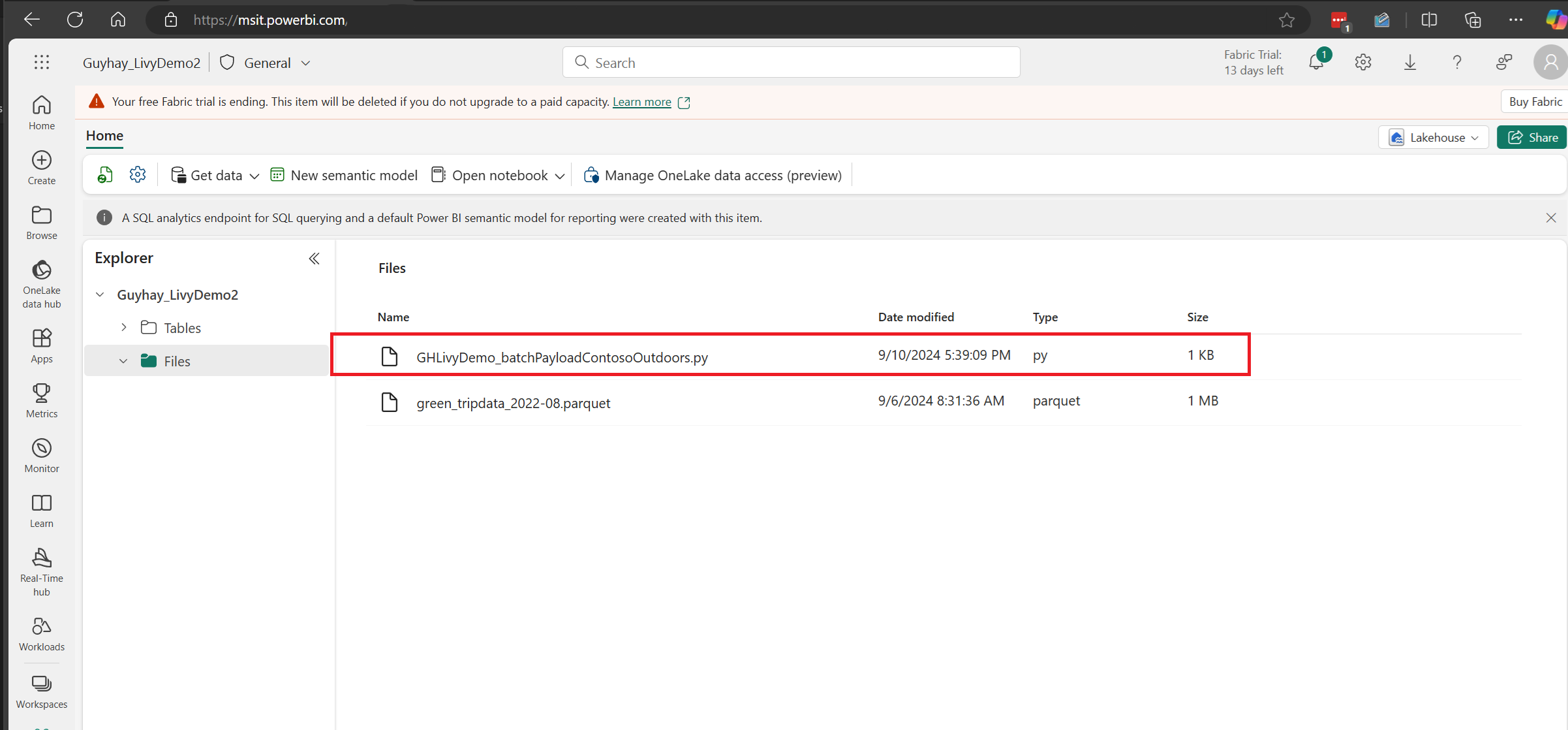
Depois que o arquivo estiver na seção de Arquivos do seu Lakehouse, clique nos três pontos à direita do nome do arquivo de conteúdo e selecione Propriedades.
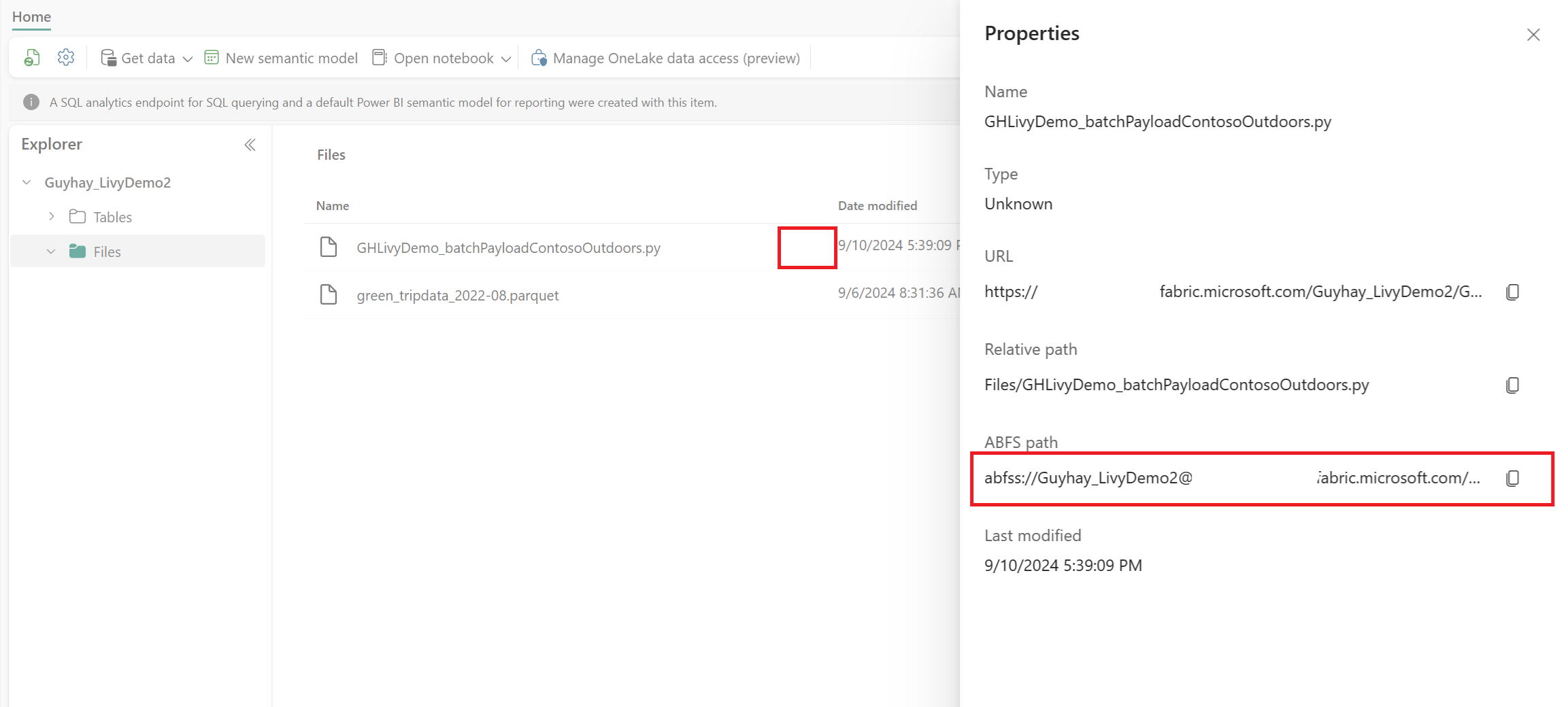
Copie este caminho ABFS para a célula do seu Notebook na etapa 1.



Crie uma sessão em lote do Spark da API Livy
Crie um notebook
.ipynbno Visual Studio Code e insira o seguinte código.from msal import PublicClientApplication import requests import time tenant_id = "<Entra_TenantID>" client_id = "<Entra_ClientID>" workspace_id = "<Fabric_WorkspaceID>" lakehouse_id = "<Fabric_LakehouseID>" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/batches" headers = {"Authorization": "Bearer " + access_token}Execute a célula do notebook, um pop-up deve aparecer no seu navegador permitindo que você escolha a identidade para entrar.
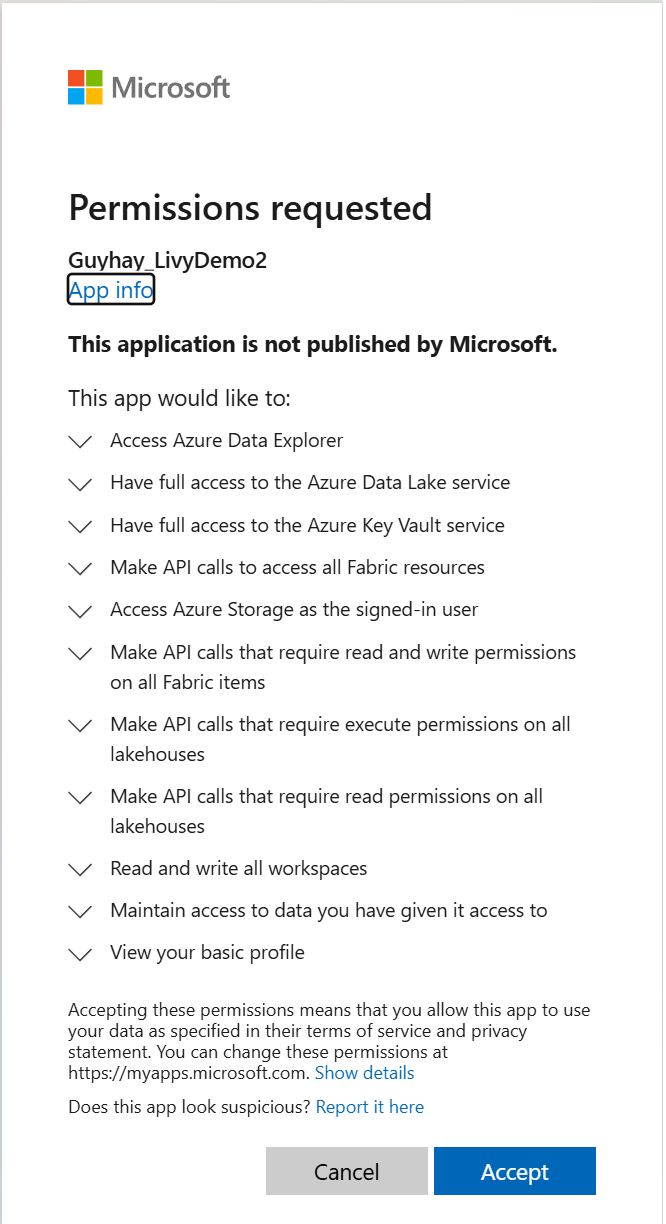
Depois de escolher a identidade para fazer login, você também será solicitado a aprovar as permissões da API de registro do aplicativo Microsoft Entra.
Feche a janela do navegador após concluir a autenticação.

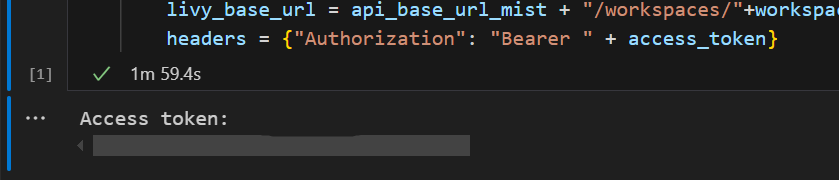
No Visual Studio Code, você deve ver o token do Microsoft Entra retornado.
Adicione outra célula de notebook e insira este código.
# call get batch API get_livy_get_batch = livy_base_url get_batch_response = requests.get(get_livy_get_batch, headers=headers) if get_batch_response.status_code == 200: print("API call successful") print(get_batch_response.json()) else: print(f"API call failed with status code: {get_batch_response.status_code}") print(get_batch_response.text)Execute a célula do notebook, você deve ver duas linhas impressas enquanto o trabalho em lote Livy é criado.
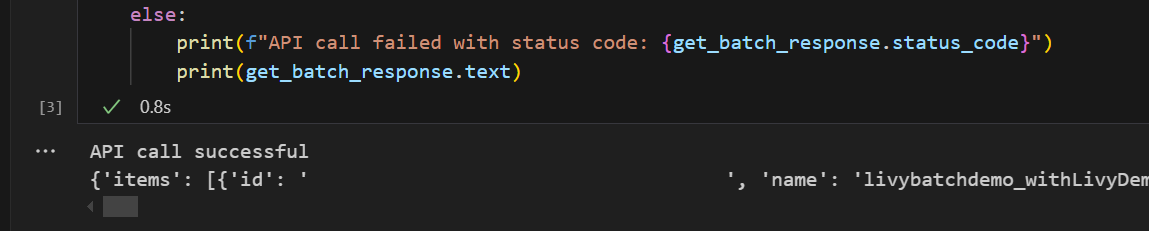





Envie uma instrução spark.sql usando a sessão em lote da API Livy
Adicione outra célula de notebook e insira este código.
# submit payload to existing batch session print('Submit a spark job via the livy batch API to ') newlakehouseName = "YourNewLakehouseName" create_lakehouse = api_base_url_mist + "/workspaces/" + workspace_id + "/items" create_lakehouse_payload = { "displayName": newlakehouseName, "type": 'Lakehouse' } create_lakehouse_response = requests.post(create_lakehouse, headers=headers, json=create_lakehouse_payload) print(create_lakehouse_response.json()) payload_data = { "name":"livybatchdemo_with"+ newlakehouseName, "file":"abfss://YourABFSPathToYourPayload.py", "conf": { "spark.targetLakehouse": "Fabric_LakehouseID" } } get_batch_response = requests.post(get_livy_get_batch, headers=headers, json=payload_data) print("The Livy batch job submitted successful") print(get_batch_response.json())Execute a célula do notebook, você deve ver várias linhas impressas enquanto o Trabalho em lote Livy é criado e executado.

Navegue de volta para o seu Lakehouse para ver as alterações.

Exibir seus trabalhos no hub de Monitoramento
Você pode acessar o hub de Monitoramento para visualizar várias atividades do Apache Spark selecionando Monitorar nos links de navegação à esquerda.
Quando o trabalho em lote estiver no estado concluído, você pode visualizar o status da sessão navegando até Monitorar.
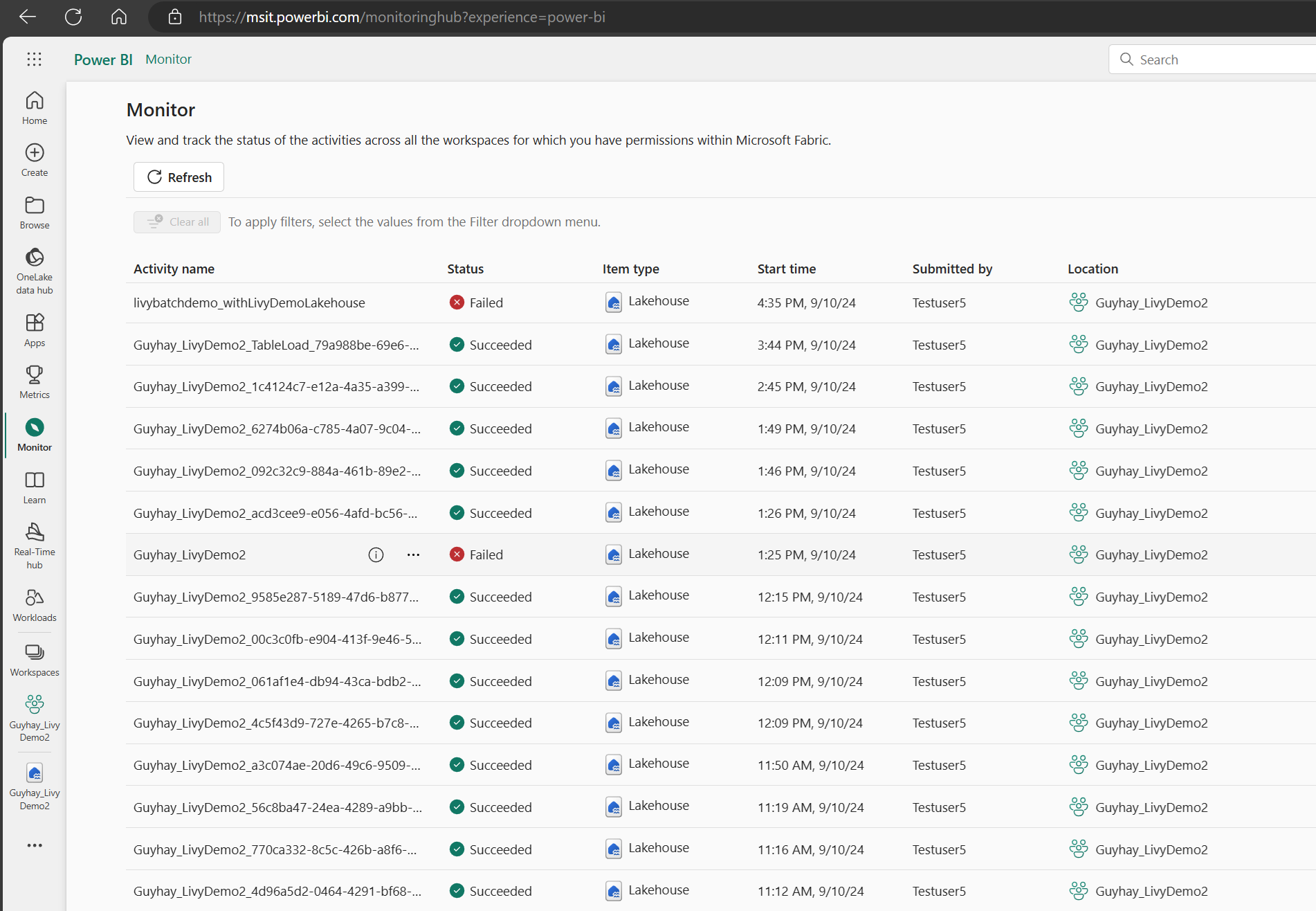
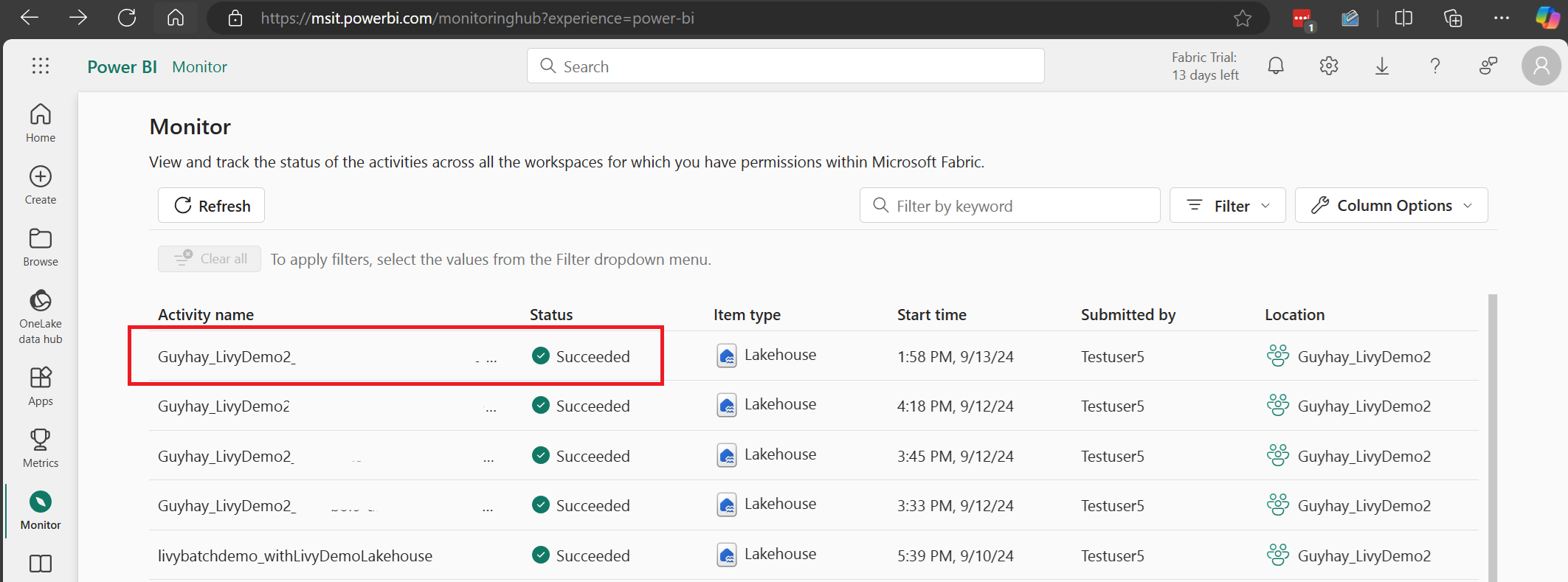
Selecione e abra o nome da atividade mais recente.
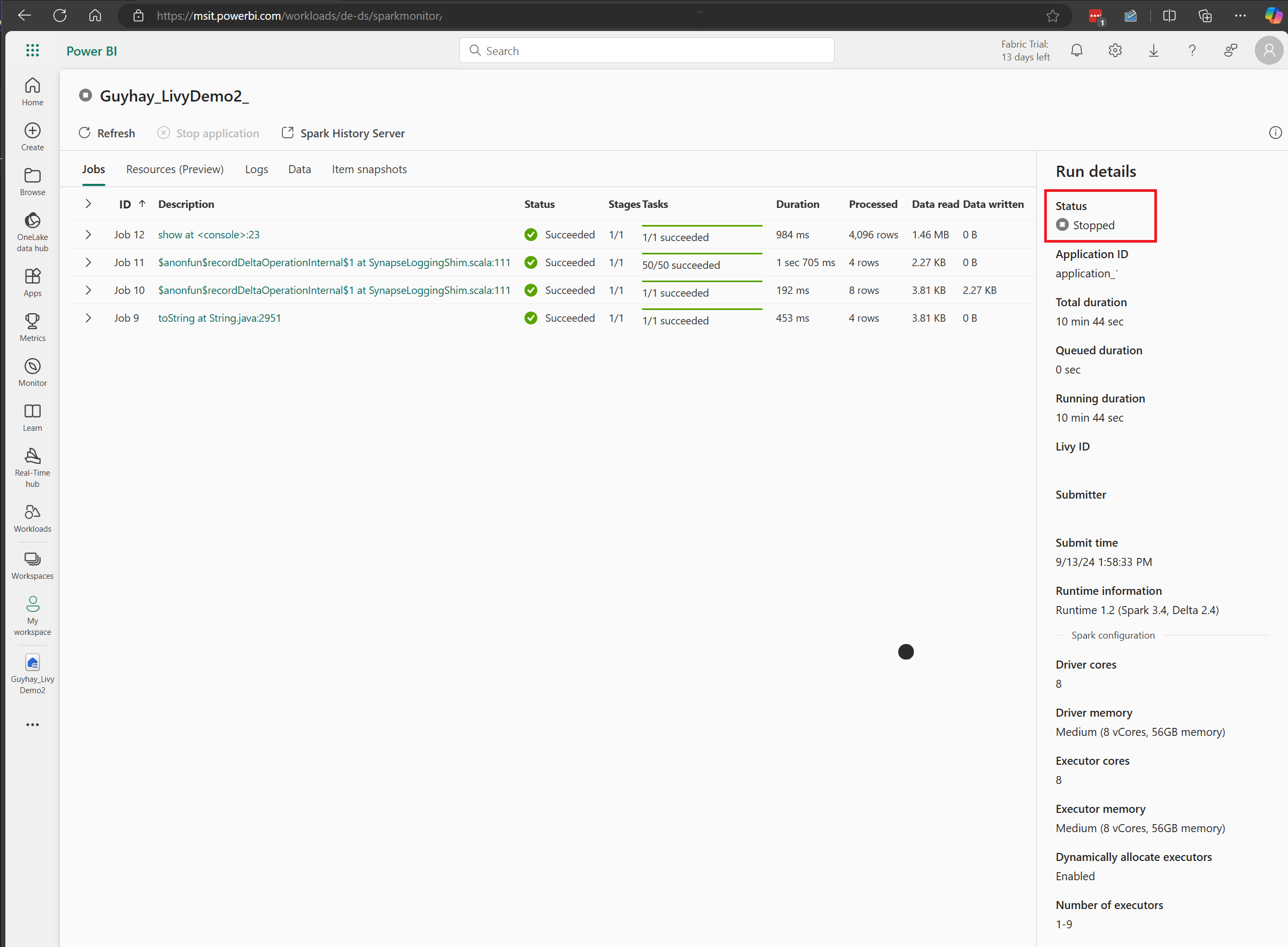
Neste caso de sessão da API Livy, você pode ver seu envio de lote anterior, detalhes da execução, versões do Spark e configuração. Observe o status interrompido no canto superior direito.
Para recapitular todo o processo, você precisa de um cliente remoto como Visual Studio Code, um token de aplicativo do Microsoft Entra, URL do ponto de extremidade da API Livy, autenticação contra seu Lakehouse, um conteúdo do Spark no seu Lakehouse e, finalmente, uma sessão em lote da API Livy.