Migrações do Code First em ambientes de equipe
Observação
Este artigo pressupõe que você saiba usar as Migrações do Code First em cenários básicos. Caso contrário, será necessário ler Migrações do Code First antes de continuar.
Pegue um café, pois você precisa ler este artigo inteiro
Os problemas em ambientes de equipe se relacionam principalmente à mesclagem de migrações quando dois desenvolvedores geram migrações em suas bases de código locais. Embora as etapas para resolvê-los sejam muito simples, elas exigem que você tenha uma compreensão sólida de como as migrações funcionam. Não vá direto para o final – reserve um tempo para ler todo o artigo para garantir que você tenha sucesso.
Algumas diretrizes gerais
Antes de analisarmos como gerenciar migrações de mesclagem geradas por vários desenvolvedores, aqui estão algumas diretrizes gerais para que você tenha sucesso.
Cada membro da equipe deve ter um banco de dados de desenvolvimento local
As migrações usam a tabela __MigrationsHistory para armazenar quais migrações foram aplicadas ao banco de dados. Se você tiver vários desenvolvedores gerando migrações diferentes ao tentar direcionar o mesmo banco de dados (e, portanto, compartilhar uma tabela __MigrationsHistory), as migrações ficarão muito confusas.
É claro que, se você tiver membros da equipe que não estão gerando migrações, não haverá problema em tê-los compartilhando um banco de dados de desenvolvimento central.
Evitar migrações automáticas
A questão é que as migrações automáticas inicialmente parecem boas em ambientes de equipe, mas na realidade elas simplesmente não funcionam. Se você quiser saber por quê, continue lendo – caso contrário, poderá pular para a próxima seção.
As migrações automáticas permitem que você tenha seu esquema de banco de dados atualizado para corresponder ao modelo atual sem a necessidade de gerar arquivos de código (migrações baseadas em código). As migrações automáticas funcionariam muito bem em um ambiente de equipe se você as usasse raramente e nunca gerasse migrações baseadas em código. O problema é que as migrações automáticas são limitadas e não lidam com várias operações – renomeações de propriedade/coluna, movimentação de dados para outra tabela, etc. Para lidar com esses cenários, você acaba gerando migrações baseadas em código (e editando o código com scaffolding) que são misturadas entre as alterações tratadas por migrações automáticas. Isso torna quase impossível mesclar alterações quando dois desenvolvedores fazem check-in de migrações.
Noções básicas sobre como as migrações funcionam
A chave para usar migrações com êxito em um ambiente de equipe é uma compreensão básica de como as migrações rastreiam e usam informações sobre o modelo para detectar alterações de modelo.
A primeira migração
Ao adicionar a primeira migração ao seu projeto, você executa algo como Adicionar migração primeiro no Console do Gerenciador de Pacotes. As etapas de alto nível executadas por esse comando são retratadas abaixo.
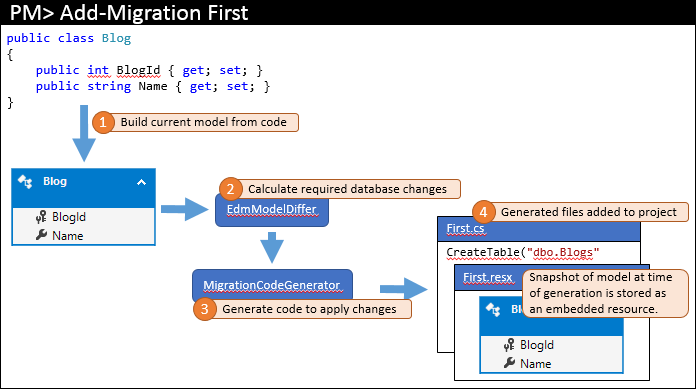
O modelo atual é calculado com base no código (1). Os objetos de banco de dados necessários são calculados pela diferença do modelo (2) – como essa é a primeira migração, a diferença do modelo apenas usa um modelo vazio para a comparação. As alterações necessárias são passadas para o gerador de código para criar o código de migração necessário (3) que, em seguida, é adicionado à sua solução do Visual Studio (4).
Além do código de migração real armazenado no arquivo de código principal, as migrações também geram alguns arquivos code-behind adicionais. Esses arquivos são metadados usados por migrações e não são algo que você deve editar. Um desses arquivos é um arquivo de recurso (.resx) que contém um instantâneo do modelo no momento em que a migração foi gerada. Você verá como isso é usado na próxima etapa.
Neste ponto, você provavelmente executaria Update-Database para aplicar suas alterações ao banco de dados e, em seguida, implementaria outras áreas do seu aplicativo.
Migrações subsequentes
Mais tarde, você volta e faz algumas alterações em seu modelo – em nosso exemplo, adicionaremos uma propriedade Url ao Blog. Em seguida, você emitiria um comando como Add-Migration AddUrl para estruturar uma migração para aplicar as alterações de banco de dados correspondentes. As etapas de alto nível executadas por esse comando são retratadas abaixo.
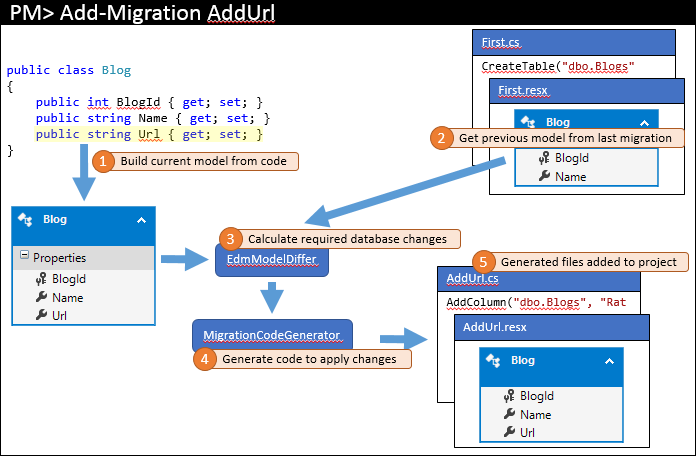
Assim como na última vez, o modelo atual é calculado a partir do código (1). No entanto, desta vez há migrações existentes para que o modelo anterior seja recuperado da migração mais recente (2). Esses dois modelos são diferenciados para localizar as alterações necessárias no banco de dados (3) e, em seguida, o processo é concluído como antes.
Esse mesmo processo é usado para quaisquer migrações adicionais que você adicionar ao projeto.
Por que se preocupar com o instantâneo do modelo?
Talvez você esteja se perguntando por que o EF se preocupa com o instantâneo do modelo – por que não apenas examinar o banco de dados? Em caso afirmativo, continue. Se você não estiver interessado, ignore esta seção.
Há várias razões pelas quais o EF mantém o instantâneo do modelo por perto:
- Ele permite que o banco de dados se afaste do modelo EF. Essas alterações podem ser feitas diretamente no banco de dados ou você pode alterar o código com scaffolding em suas migrações para fazer as alterações. Aqui estão alguns exemplos disso na prática:
- Você deseja adicionar uma coluna Inserida e Atualizada a uma ou mais de suas tabelas, mas não deseja incluir essas colunas no modelo EF. Se as migrações analisassem o banco de dados, ele tentaria remover essas colunas continuamente sempre que você criasse uma migração. Usando o instantâneo do modelo, o EF detectará apenas alterações legítimas no modelo.
- Você deseja alterar o corpo de um procedimento armazenado usado para atualizações para incluir alguns logs. Se as migrações analisassem esse procedimento armazenado do banco de dados, ele tentaria redefini-lo continuamente para a definição esperada pelo EF. Usando o instantâneo de modelo, o EF só fará scaffolding do código para alterar o procedimento armazenado quando você alterar a forma do procedimento no modelo EF.
- Esses mesmos princípios se aplicam à adição de índices extras, incluindo tabelas extras em seu banco de dados, mapeamento de EF para uma exibição de banco de dados que fica sobre uma tabela, etc.
- O modelo EF contém mais do que apenas a forma do banco de dados. Ter todo o modelo permite que as migrações examinem informações sobre as propriedades e classes em seu modelo e como elas são mapeadas para as colunas e tabelas. Essas informações permitem que as migrações sejam mais inteligentes no código em que é feito scaffolding. Por exemplo, se você alterar o nome da coluna que uma propriedade mapeia para migrações, poderá detectar a renomeação vendo que ela é a mesma propriedade – algo que não pode ser feito se você tiver apenas o esquema de banco de dados.
O que causa problemas em ambientes de equipe
O fluxo de trabalho abordado na seção anterior funciona muito bem quando você é um único desenvolvedor trabalhando em um aplicativo. Ele também funcionará bem em um ambiente de equipe se você for a única pessoa a fazer alterações no modelo. Nesse cenário, você pode fazer alterações de modelo, gerar migrações e enviá-las para o controle do código-fonte. Outros desenvolvedores podem sincronizar suas alterações e executar Update-Database para que as alterações de esquema sejam aplicadas.
Problemas começam a surgir quando você tem vários desenvolvedores fazendo alterações no modelo EF e enviando para o controle do código-fonte ao mesmo tempo. O que falta no EF é uma maneira de primeira classe para mesclar suas migrações locais com migrações que outro desenvolvedor enviou ao controle do código-fonte desde a última sincronização.
Um exemplo de conflito de mesclagem
Primeiro, vamos examinar um exemplo concreto desse conflito de mesclagem. Continuaremos com o exemplo que analisamos anteriormente. Como ponto de partida, vamos supor que as alterações da seção anterior foram verificadas pelo desenvolvedor original. Acompanharemos dois desenvolvedores à medida que eles fizerem alterações na base de código.
Acompanharemos o modelo EF e as migrações por meio de várias alterações. Para um ponto de partida, ambos os desenvolvedores sincronizaram com o repositório de controle do código-fonte, conforme descrito no gráfico a seguir.
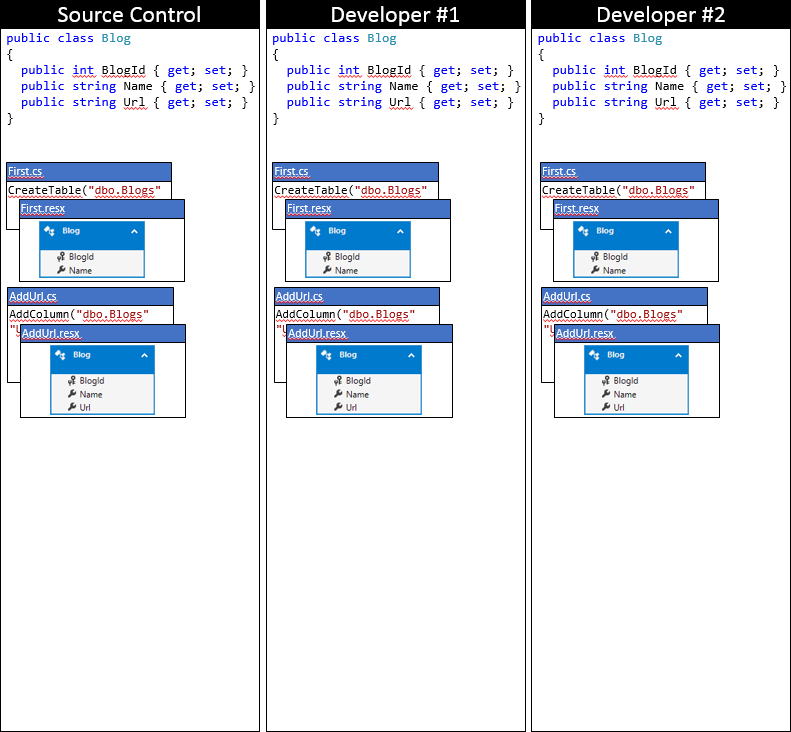
O desenvolvedor nº 1 e o desenvolvedor nº 2 agora fazem algumas alterações no modelo EF em sua base de código local. O desenvolvedor nº 1 adiciona uma propriedade Classificação ao Blog e gera uma migração AddRating para aplicar as alterações ao banco de dados. O desenvolvedor nº 2 adiciona uma propriedade Leitores ao Blog e gera a migração correspondente AddReaders. Ambos os desenvolvedores executam Update-Database, para aplicar as alterações aos bancos de dados locais e continuar desenvolvendo o aplicativo.
Observação
As migrações são prefixadas com um carimbo de data/hora, portanto, nosso gráfico representa que a migração de AddReaders do desenvolvedor nº 2 vem após a migração de AddRating do desenvolvedor nº 1. Se o desenvolvedor nº 1 ou nº 2 gerou a migração primeiro não faz diferença para a questão de trabalhar em uma equipe ou o processo para mesclá-las que examinaremos na próxima seção.
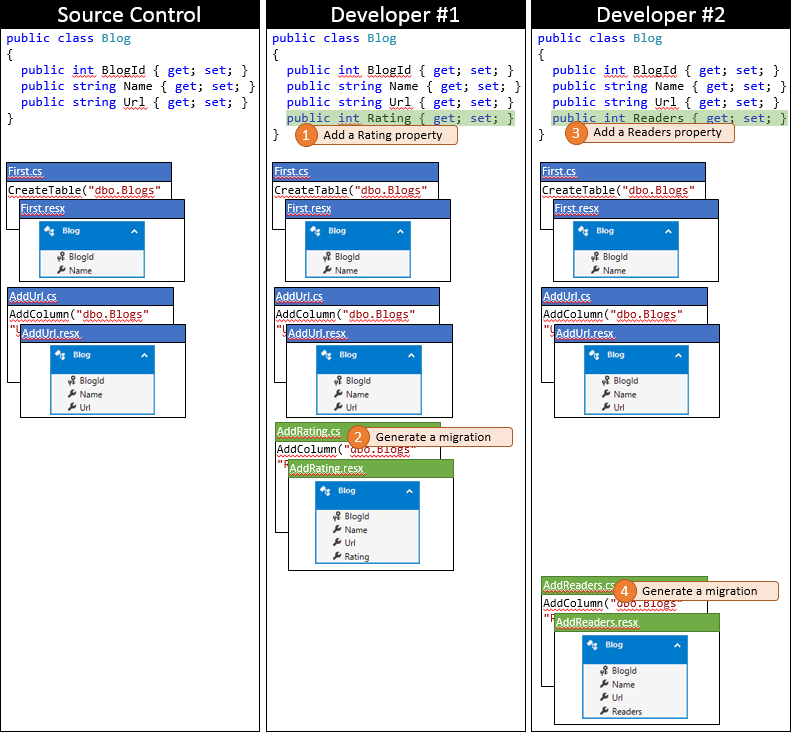
É um dia de sorte para o desenvolvedor nº 1, pois ele enviou suas alterações primeiro. Como ninguém mais fez check-in desde que ele sincronizou o seu repositório, ele pode simplesmente enviar suas alterações sem executar nenhuma mesclagem.
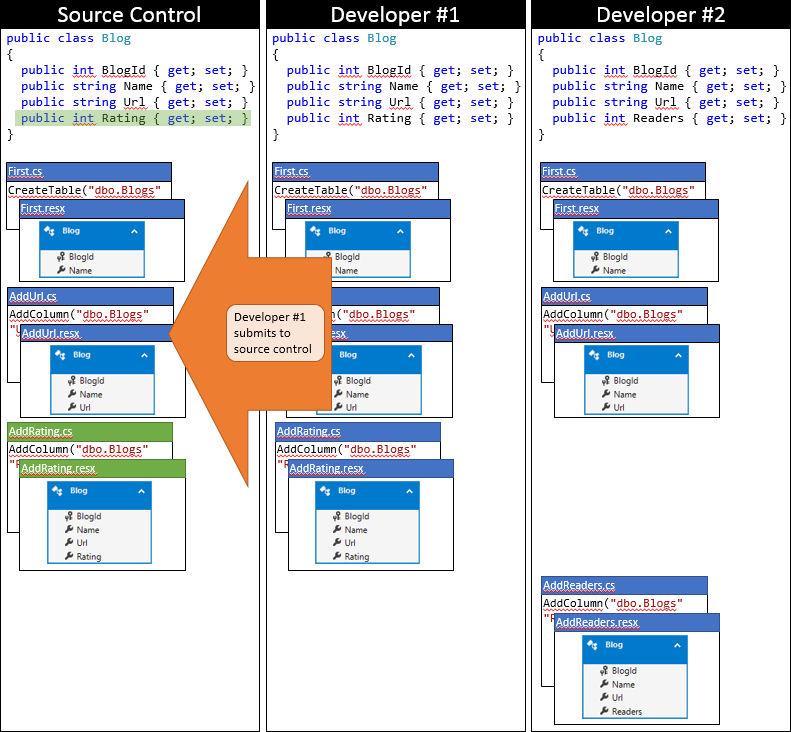
Agora é hora do desenvolvedor nº 2 fazer o envio. Ele não tem tanta sorte. Como outra pessoa enviou alterações desde a sincronização, ele precisará efetuar pull das alterações e mesclar. O sistema de controle do código-fonte provavelmente será capaz de mesclar automaticamente as alterações no nível do código, pois elas são muito simples. O estado do repositório local do desenvolvedor nº 2 após a sincronização é descrito no gráfico a seguir.
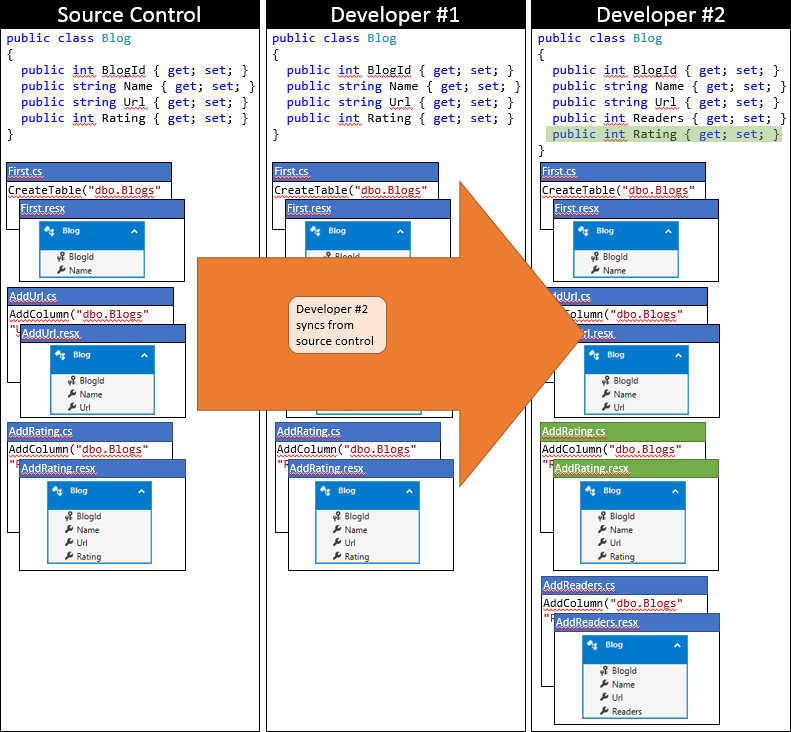
Neste estágio, o desenvolvedor nº 2 pode executar Update-Database, que detectará a nova migração de AddRating (que não foi aplicada ao banco de dados do desenvolvedor nº 2) e a aplicará. Agora, a coluna Classificação é adicionada à tabela Blogs e o banco de dados está sincronizado com o modelo.
No entanto, há alguns problemas:
- Embora o Update-Database aplique a migração AddRating, ele também gerará um aviso: Não é possível atualizar o banco de dados para corresponder ao modelo atual porque há alterações pendentes e a migração automática está desabilitada... O problema é que o instantâneo do modelo armazenado na última migração (AddReader) está sem a propriedade Classificação no Blog (já que ele não fazia parte do modelo quando a migração foi gerada). O Code First detecta que o modelo na última migração não corresponde ao modelo atual e gera o aviso.
- A execução do aplicativo resultaria em um InvalidOperationException informando que "O modelo que faz backup do contexto "BloggingContext" foi alterado desde que o banco de dados foi criado. Considere usar as Migrações do Code First para atualizar o banco de dados..." Novamente, o problema é que o instantâneo do modelo armazenado na última migração não corresponde ao modelo atual.
- Por fim, esperamos que a execução de Add-Migration agora gere uma migração vazia (já que não há alterações a serem aplicadas ao banco de dados). No entanto, como as migrações comparam o modelo atual com o da última migração (em que está faltando a propriedade Classificação), na verdade, elas criarão outra chamada AddColumn para adicionar a coluna Classificação. É claro que essa migração falharia durante Update-Database porque a coluna Classificação já existe.
Resolver o conflito de mesclagem
A boa notícia é que não é muito difícil lidar com a mesclagem manualmente, desde que você tenha uma compreensão de como as migrações funcionam. Então, se você pulou para esta seção… Desculpe, você precisa voltar e ler o resto do artigo primeiro!
Há duas opções; a mais fácil é gerar uma migração em branco que tenha o modelo atual correto como um instantâneo. A segunda opção é atualizar o instantâneo na última migração para ter o instantâneo do modelo correto. A segunda opção é um pouco mais difícil e não pode ser usada em todos os cenários, mas também é mais limpa porque não envolve a adição de uma migração extra.
Opção 1: Adicionar uma migração "merge" em branco
Nesta opção, geramos uma migração em branco apenas com a finalidade de garantir que a migração mais recente tenha o instantâneo de modelo correto armazenado nela.
Essa opção pode ser usada independentemente de quem gerou a última migração. No exemplo, vimos que o desenvolvedor nº 2 está cuidando da mesclagem e ele gerou a última migração. Mas essas mesmas etapas podem ser usadas se o desenvolvedor nº 1 tiver gerado a última migração. As etapas também se aplicam se houver várias migrações envolvidas – estamos examinando somente duas para simplicidade.
O processo a seguir pode ser usado para essa abordagem, a partir do momento em que você percebe que há alterações que precisam ser sincronizadas do controle do código-fonte.
- Verifique se todas as alterações de modelo pendentes em sua base de código local foram gravadas em uma migração. Esta etapa garante que você não perca nenhuma alteração legítima quando chegar a hora de gerar a migração em branco.
- Sincronizar com o controle do código-fonte.
- Execute Update-Database para aplicar as novas migrações para as quais outros desenvolvedores fizeram check-in. Observação:se você não receber avisos do comando Update-Database, não haverá novas migrações de outros desenvolvedores e não há necessidade de executar nenhuma mesclagem adicional.
- Execute Add-Migration <pick_a_name> –IgnoreChanges (por exemplo, Add-Migration Merge –IgnoreChanges). Isso gera uma migração com todos os metadados (incluindo um instantâneo do modelo atual), mas ignorará todas as alterações detectadas ao comparar o modelo atual com o instantâneo nas últimas migrações (o que significa que você obtém um método em branco Up e Down).
- Execute Update-Database para aplicar novamente a migração mais recente com os metadados atualizados.
- Continue desenvolvendo ou envie para o controle do código-fonte (depois de executar os testes de unidade, é claro).
Aqui está o estado da base de código local do desenvolvedor nº 2 depois de usar essa abordagem.
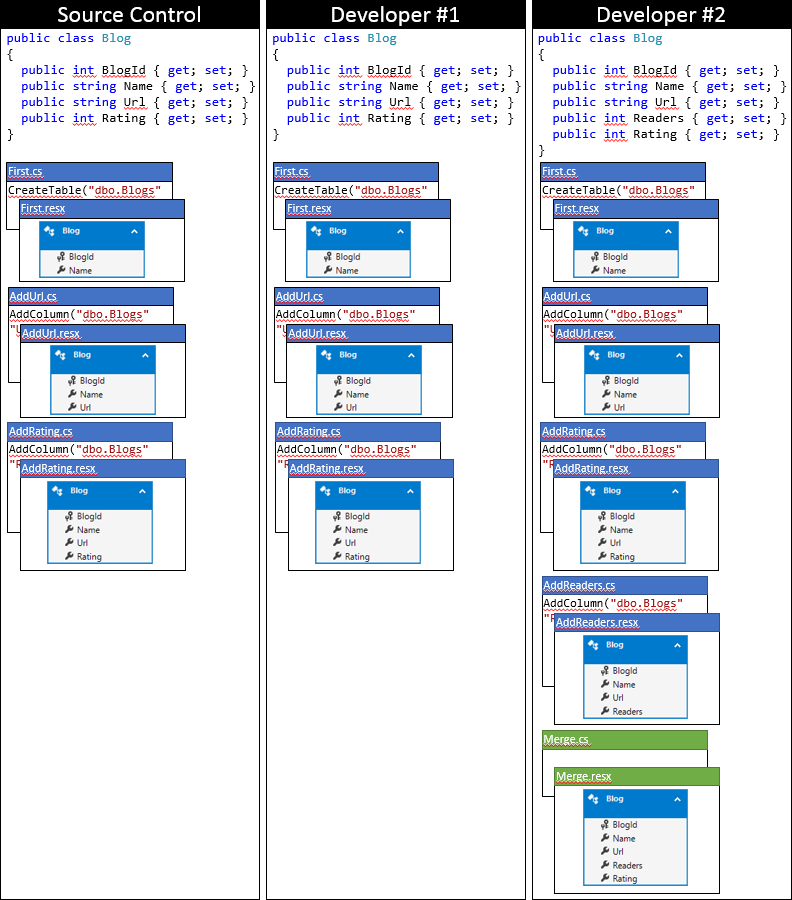
Opção 2: atualizar o instantâneo do modelo na última migração
Essa opção é muito semelhante à opção 1, mas remove a migração extra em branco – afinal, vamos encarar: quem deseja arquivos de código extras em sua solução?
Essa abordagem só será viável se a migração mais recente existir apenas em sua base de código local e ainda não tiver sido enviada ao controle do código-fonte (por exemplo, se a última migração tiver sido gerada pelo usuário que está fazendo a mesclagem). Editar os metadados de migrações que outros desenvolvedores podem já ter aplicado ao banco de dados de desenvolvimento – ou, pior, aplicado a um banco de dados de produção – pode resultar em efeitos colaterais inesperados. Durante o processo, reverteremos a última migração em nosso banco de dados local e a aplicaremos novamente com metadados atualizados.
Embora a última migração precise estar apenas na base de código local, não há restrições para o número ou a ordem das migrações que a prossiga. Pode haver várias migrações de vários desenvolvedores diferentes e as mesmas etapas se aplicam: estamos apenas analisando duas para mantê-la simples.
O processo a seguir pode ser usado para essa abordagem, a partir do momento em que você percebe que há alterações que precisam ser sincronizadas do controle do código-fonte.
- Verifique se todas as alterações de modelo pendentes em sua base de código local foram gravadas em uma migração. Esta etapa garante que você não perca nenhuma alteração legítima quando chegar a hora de gerar a migração em branco.
- Sincronizar com o controle do código-fonte.
- Execute Update-Database para aplicar as novas migrações para as quais outros desenvolvedores fizeram check-in. Observação:se você não receber avisos do comando Update-Database, não haverá novas migrações de outros desenvolvedores e não há necessidade de executar nenhuma mesclagem adicional.
- Execute Update-Database –TargetMigration <second_last_migration> (no exemplo que estamos seguindo, isso seria Update-Database –TargetMigration AddRating). Isso reverte o banco de dados para o estado da penúltima migração – efetivamente "desaplicando" a última migração do banco de dados. Observação:essa etapa é necessária para tornar seguro editar os metadados da migração, pois os metadados também são armazenados no __MigrationsHistoryTable do banco de dados. É por isso que você só deve usar essa opção se a última migração estiver apenas em sua base de código local. Se outros bancos de dados tivessem a última migração aplicada, você também teria que revertê-los e aplicar novamente a última migração para atualizar os metadados.
- Execute Add-Migration <full_name_including_timestamp_of_last_migration> (no exemplo que estamos seguindo, isso seria algo como Add-Migration 201311062215252_AddReaders). Observação:você precisa incluir o carimbo de data/hora para que as migrações saibam que você deseja editar a migração existente em vez de fazer scaffolding de uma nova. Isso atualizará os metadados da última migração para corresponder ao modelo atual. Você receberá o seguinte aviso quando o comando for concluído, mas isso é exatamente o que você deseja. "Foi feito novo scaffolding somente do Código de Designer da migração "201311062215252_AddReaders". Para fazer um novo scaffolding de toda a migração, use o parâmetro -Force."
- Execute Update-Database para aplicar novamente a migração mais recente com os metadados atualizados.
- Continue desenvolvendo ou envie para o controle do código-fonte (depois de executar os testes de unidade, é claro).
Aqui está o estado da base de código local do desenvolvedor nº 2 depois de usar essa abordagem.
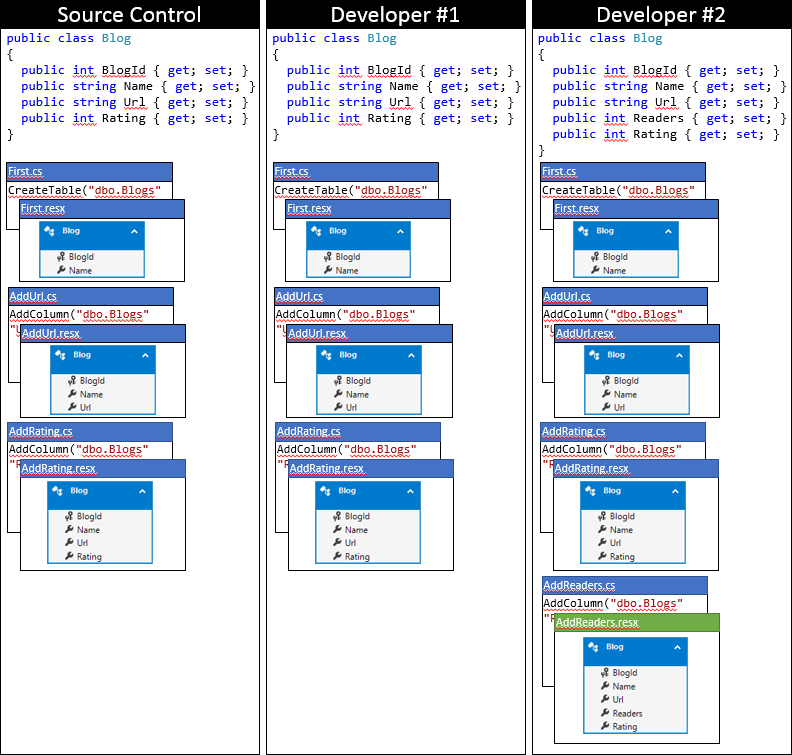
Resumo
Há alguns desafios ao usar as Migrações do Code First em um ambiente de equipe. No entanto, uma compreensão básica de como as migrações funcionam e algumas abordagens simples para resolver conflitos de mesclagem facilitam a superação desses desafios.
O problema fundamental são os metadados incorretos armazenados na migração mais recente. Isso faz com que o Code First detecte incorretamente que o modelo atual e o esquema de banco de dados não correspondem e faça scaffolding de código incorreto na próxima migração. Essa situação pode ser superada gerando uma migração em branco com o modelo correto ou atualizando os metadados na migração mais recente.