Tutorial: Criar uma recomendação de filme usando a fatoração de matriz com ML.NET
Este tutorial mostra como criar uma recomendação de filme do ML.NET em um aplicativo de console do .NET Core. AS etapas usam C# e o Visual Studio 2019.
Neste tutorial, você aprenderá a:
- Selecionar um algoritmo de aprendizado de máquina
- Preparar e carregar os dados
- Criar e treinar um modelo
- Avaliar um modelo
- Implantar e consumir um modelo
Você pode encontrar o código-fonte para este tutorial no repositório dotnet/samples.
Fluxo de trabalho de aprendizado de máquina
Você usará as seguintes etapas para realizar sua tarefa, bem como qualquer outra tarefa do ML.NET:
Pré-requisitos
Selecionar a tarefa de aprendizado de máquina apropriada
Há várias maneiras de abordar problemas de recomendação, como recomendar uma lista de filmes ou uma lista de produtos relacionados, mas, nesse caso, você preverá qual classificação (1 a 5) um usuário dará a um filme específico e recomendará esse filme se ele for superior a um limite definido (quanto maior a classificação, maior a probabilidade de um usuário gostar de um filme específico).
Criar um aplicativo de console
Criar um projeto
Crie um Aplicativo de console C# chamado "MovieRecommender". Clique no botão Avançar.
Escolha o .NET 6 como a estrutura a ser usada. Selecione o botão Criar.
Crie um diretório chamado Data no projeto para armazenar o conjunto de dados:
No Gerenciador de Soluções, clique com o botão direito do mouse no projeto e selecione Adicionar>Nova Pasta. Digite "Dados" e pressione Enter.
Instale os pacotes NuGet Microsoft.ML e Microsoft.ML.Recommender:
Observação
Este exemplo usa a versão estável mais recente dos pacotes NuGet mencionados, salvo indicação em contrário.
No Gerenciador de Soluções, clique com o botão direito no projeto e escolha Gerenciar Pacotes NuGet. Escolha "nuget.org" como a origem do pacote, selecione a guia Procurar, pesquise por Microsoft.ML, selecione o pacote na lista e selecione o botão Instalar. Selecione o botão OK na caixa de diálogo Visualizar Alterações e selecione o botão Aceito na caixa de diálogo Aceitação da Licença, se concordar com o termos de licença para os pacotes listados. Repita essas etapas para o Microsoft.ML.Recommender.
Adicione as seguintes instruções
usingà parte superior do arquivo Program.cs:using Microsoft.ML; using Microsoft.ML.Trainers; using MovieRecommendation;
Baixar seus dados
Baixe os dois conjuntos de dados e salve-os na pasta Data criada anteriormente:
Clique com o botão direito do mouse em recommendation-ratings-train.csv e selecione "Salvar Link (ou Destino) como..."
Clique com o botão direito do mouse em recommendation-ratings-test.csv e selecione "Salvar Link (ou Destino) como..."
Salve os arquivos *.csv na pasta Data ou, depois de salvá-los em outro lugar, mova os arquivos *.csv para a pasta Data.
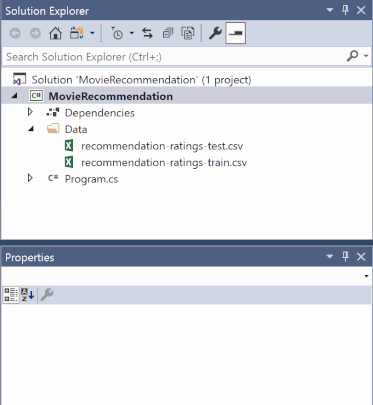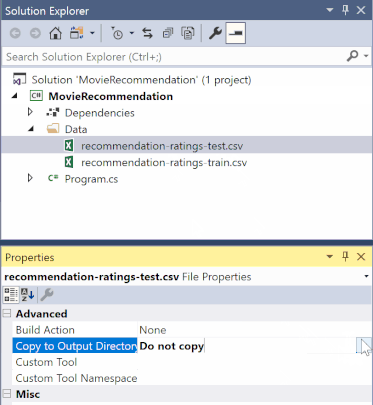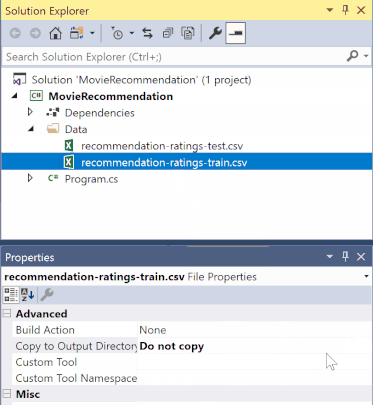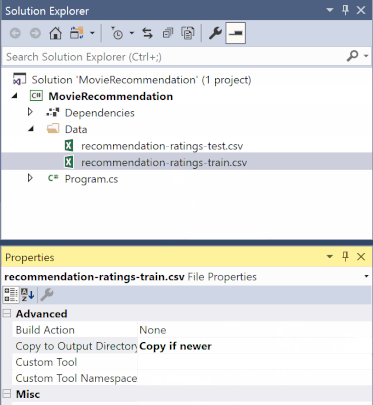
No Gerenciador de Soluções, clique com o botão direito do mouse em cada um dos arquivos *.csv e selecione Propriedades. Em Avançado, altere o valor de Copiar para Diretório de Saída para Copiar se for mais novo.
Carregar os dados
A primeira etapa no processo do ML.NET é preparar e carregar os dados de treinamento e teste de modelo.
Os dados de classificações de recomendação são divididos nos conjuntos de dados Train e Test. Os dados Train são usados para ajustar o modelo. Os dados Test são usados para fazer previsões com o modelo treinado e avaliar o desempenho do modelo. É comum ter uma divisão 80/20 com os dados Train e Test.
Segue abaixo uma visualização dos dados nos arquivos *.csv:
Nos arquivos *.csv, há quatro colunas:
userIdmovieIdratingtimestamp
No aprendizado de máquina, as colunas que são usadas para fazer uma previsão são chamadas Recursos e a coluna com a previsão retornada é chamada o Rótulo.
Você deseja prever as classificações de filmes, portanto, a coluna de classificação é o Label. As outras três colunas, userId, movieId e timestamp, são todos Features usados para prever o Label.
| Recursos | Rótulo |
|---|---|
userId |
rating |
movieId |
|
timestamp |
Cabe a você decidir quais Features são usados para prever o Label. Você também pode usar métodos como importância do recurso de permuta para ajudar a selecionar os melhores Features.
Nesse caso, você deve eliminar a coluna timestamp como um Feature porque o carimbo de data/hora não afeta como um usuário classifica determinado filme e, portanto, não contribui para uma previsão mais precisa:
| Recursos | Rótulo |
|---|---|
userId |
rating |
movieId |
Em seguida, é necessário definir a estrutura de dados para a classe de entrada.
Adicione uma nova classe ao seu projeto:
No Gerenciador de Soluções, clique com o botão direito do mouse no projeto e, em seguida, selecione Adicionar > Novo Item.
Na caixa de diálogo Adicionar Novo Item, selecione Classe e altere o campo Nome para MovieRatingData.cs. Em seguida, selecione o botão Adicionar.
O arquivo MovieRatingData.cs será aberto no editor de códigos. Adicione a seguinte instrução using acima de MovieRatingData.cs:
using Microsoft.ML.Data;
Crie uma classe chamada MovieRating removendo a definição de classe existente e adicionando o seguinte código a MovieRatingData.cs:
public class MovieRating
{
[LoadColumn(0)]
public float userId;
[LoadColumn(1)]
public float movieId;
[LoadColumn(2)]
public float Label;
}
MovieRating especifica uma classe de dados de entrada. O atributo LoadColumn especifica quais colunas (por índice de coluna) no conjunto de dados devem ser carregadas. As colunas userId e movieId são os Features (as entradas que você fornecerá ao modelo para prever o Label), e a coluna de classificação é o Label, que você preverá (a saída do modelo).
Crie outra classe, MovieRatingPrediction, para representar os resultados previstos adicionando o seguinte código após a classe MovieRating em MovieRatingData.cs:
public class MovieRatingPrediction
{
public float Label;
public float Score;
}
Em Program.cs, substitua o Console.WriteLine("Hello World!") pelo seguinte código:
MLContext mlContext = new MLContext();
A classe MLContext é um ponto de partida para todas as operações do ML.NET e a inicialização do mlContext cria um ambiente do ML.NET que pode ser compartilhado entre os objetos de fluxo de trabalho da criação de modelo. Ele é semelhante, conceitualmente, a DBContext no Entity Framework.
Na parte inferior do arquivo, crie um método chamado LoadData():
(IDataView training, IDataView test) LoadData(MLContext mlContext)
{
}
Observação
Esse método apresentará um erro até que você adicione uma instrução de retorno nas etapas a seguir.
Inicialize as variáveis do caminho de dados, carregue os dados nos arquivos *.csv e retorne os dados Train e Test como objetos IDataView adicionando o seguinte como a próxima linha de código em LoadData():
var trainingDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-train.csv");
var testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-test.csv");
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<MovieRating>(trainingDataPath, hasHeader: true, separatorChar: ',');
IDataView testDataView = mlContext.Data.LoadFromTextFile<MovieRating>(testDataPath, hasHeader: true, separatorChar: ',');
return (trainingDataView, testDataView);
Os dados do ML.NET são representados como uma interface IDataView. IDataView é uma maneira flexível e eficiente de descrever dados tabulares (numéricos e texto). Os dados podem ser carregados de um arquivo de texto ou em tempo real (por exemplo, banco de dados SQL ou arquivos de log) para um objeto IDataView.
O LoadFromTextFile() define o esquema de dados e lê o arquivo. Ele usa as variáveis de caminho de dados e retorna uma IDataView. Nesse caso, você fornece o caminho para os arquivos Test e Train e indica o cabeçalho do arquivo de texto (para que ele possa usar os nomes de coluna corretamente) e o separador de dados de caractere de vírgula (o separador padrão é uma guia).
Adicione o seguinte código para chamar o método LoadData() e retornar os dados Train e Test:
(IDataView trainingDataView, IDataView testDataView) = LoadData(mlContext);
Criar e treinar o modelo
Crie o método BuildAndTrainModel(), logo após o método LoadData(), usando o seguinte código:
ITransformer BuildAndTrainModel(MLContext mlContext, IDataView trainingDataView)
{
}
Observação
Esse método apresentará um erro até que você adicione uma instrução de retorno nas etapas a seguir.
Defina as transformações de dados adicionando o seguinte código a BuildAndTrainModel():
IEstimator<ITransformer> estimator = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "userIdEncoded", inputColumnName: "userId")
.Append(mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "movieIdEncoded", inputColumnName: "movieId"));
Como userId e movieId representam usuários e títulos de filmes, não valores reais, use o método MapValueToKey() para transformar cada userId e cada movieId em uma coluna Feature de tipo de chave numérica (um formato aceito pelos algoritmos de recomendação) e adicioná-los como novas colunas de conjunto de dados:
| userId | movieId | Rótulo | userIdEncoded | movieIdEncoded |
|---|---|---|---|---|
| 1 | 1 | 4 | userKey1 | movieKey1 |
| 1 | 3 | 4 | userKey1 | movieKey2 |
| 1 | 6 | 4 | userKey1 | movieKey3 |
Escolha o algoritmo de aprendizado de máquina e acrescente-o às definições de transformação de dados adicionando o seguinte como a próxima linha de código em BuildAndTrainModel():
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
var trainerEstimator = estimator.Append(mlContext.Recommendation().Trainers.MatrixFactorization(options));
O MatrixFactorizationTrainer é o algoritmo de treinamento de recomendação. A Fatoração de Matriz é uma abordagem comum de recomendação quando você tem dados sobre como os usuários classificaram produtos no passado, que é o caso para os conjuntos de dados deste tutorial. Há outros algoritmos de recomendação para quando você tem diferentes dados disponíveis (confira a seção Outros algoritmos de recomendação abaixo para saber mais).
Nesse caso, o algoritmo Matrix Factorization usa um método chamado "filtragem colaborativa", que supõe que, se o Usuário 1 tem a mesma opinião do Usuário 2 sobre determinada questão, é mais provável que o Usuário 1 sinta-se da mesma forma que o Usuário 2 sobre outra questão.
Por exemplo, se o Usuário 1 e o Usuário 2 classificam filmes de forma semelhante, é mais provável que o Usuário 2 goste de um filme que o Usuário 1 assistiu e forneceu uma classificação alta:
Incredibles 2 (2018) |
The Avengers (2012) |
Guardians of the Galaxy (2014) |
|
|---|---|---|---|
| Usuário 1 | Assistiu e gostou do filme | Assistiu e gostou do filme | Assistiu e gostou do filme |
| Usuário 2 | Assistiu e gostou do filme | Assistiu e gostou do filme | Não assistiu – RECOMENDAR o filme |
O treinador Matrix Factorization tem várias Opções, sobre as quais você pode ler mais na seção Hiperparâmetros de algoritmo abaixo.
Ajuste o modelo aos dados Train e retorne o modelo treinado adicionando o seguinte como a próxima linha de código no método BuildAndTrainModel():
Console.WriteLine("=============== Training the model ===============");
ITransformer model = trainerEstimator.Fit(trainingDataView);
return model;
O método Fit() treina o modelo com o conjunto de dados de treinamento fornecido. Tecnicamente, ele executa as definições Estimator transformando os dados e aplicando o treinamento e retorna o modelo treinado, que é um Transformer.
Para obter mais informações sobre o fluxo de trabalho de treinamento de modelo no ML.NET, consulte O que é ML.NET e como funciona?
Adicione o seguinte como a próxima linha de código abaixo da chamada ao método LoadData() para chamar o método BuildAndTrainModel() e retornar o modelo treinado:
ITransformer model = BuildAndTrainModel(mlContext, trainingDataView);
Avaliar o modelo
Depois de treinar o modelo, use os dados de teste para avaliar o desempenho do modelo.
Crie o método EvaluateModel(), logo após o método BuildAndTrainModel(), usando o seguinte código:
void EvaluateModel(MLContext mlContext, IDataView testDataView, ITransformer model)
{
}
Transforme os dados Test adicionando o seguinte código a EvaluateModel():
Console.WriteLine("=============== Evaluating the model ===============");
var prediction = model.Transform(testDataView);
O método Transform() faz previsões para várias linhas de entrada fornecidas de um conjunto de dados de teste.
Avalie o modelo adicionando o seguinte como a próxima linha de código no método EvaluateModel():
var metrics = mlContext.Regression.Evaluate(prediction, labelColumnName: "Label", scoreColumnName: "Score");
Depois que você define a previsão, o método Evaluate() avalia o modelo, que compara os valores previstos com os Labels reais no conjunto de dados de teste e retorna métricas sobre o desempenho do modelo.
Imprima as métricas de avaliação no console adicionando o seguinte como a próxima linha de código no método EvaluateModel():
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError.ToString());
Console.WriteLine("RSquared: " + metrics.RSquared.ToString());
Adicione o seguinte como a próxima linha de código abaixo da chamada ao método BuildAndTrainModel() para chamar o método EvaluateModel():
EvaluateModel(mlContext, testDataView, model);
Até agora, a saída deve ser semelhante ao seguinte texto:
=============== Training the model ===============
iter tr_rmse obj
0 1.5403 3.1262e+05
1 0.9221 1.6030e+05
2 0.8687 1.5046e+05
3 0.8416 1.4584e+05
4 0.8142 1.4209e+05
5 0.7849 1.3907e+05
6 0.7544 1.3594e+05
7 0.7266 1.3361e+05
8 0.6987 1.3110e+05
9 0.6751 1.2948e+05
10 0.6530 1.2766e+05
11 0.6350 1.2644e+05
12 0.6197 1.2541e+05
13 0.6067 1.2470e+05
14 0.5953 1.2382e+05
15 0.5871 1.2342e+05
16 0.5781 1.2279e+05
17 0.5713 1.2240e+05
18 0.5660 1.2230e+05
19 0.5592 1.2179e+05
=============== Evaluating the model ===============
Rms: 0.994051469730769
RSquared: 0.412556298844873
Nessa saída, há 20 iterações. Em cada iteração, a medida de erro diminui e é convergida para mais próximo de 0.
A root of mean squared error (RMS ou RMSE) é usada para medir as diferenças entre os valores previstos do modelo e os valores observados do conjunto de dados de teste. Tecnicamente, ela é a raiz quadrada da média dos quadrados dos erros. Quanto menor, melhor o modelo.
R Squared indica o quanto os dados se ajustam a um modelo. Varia de 0 a 1. Um valor de 0 significa que os dados são aleatórios ou não podem ser ajustados ao modelo. Um valor de 1 significa que o modelo corresponde exatamente aos dados. Você deseja que a pontuação R Squared esteja o mais próximo possível de 1.
A criação de modelos bem-sucedidos é um processo iterativo. Esse modelo tem qualidade inicial inferior, pois o tutorial usa conjuntos de dados pequenos para fornecer um treinamento rápido do modelo. Se você não estiver satisfeito com a qualidade do modelo, tente melhorá-lo fornecendo conjuntos de dados de treinamento maiores ou escolhendo diferentes algoritmos de treinamento com diferentes hiperparâmetros para cada algoritmo. Para obter mais informações, confira a seção Melhorar o modelo abaixo.
Usar o modelo
Agora você pode usar o modelo treinado para fazer previsões sobre novos dados.
Crie o método UseModelForSinglePrediction(), logo após o método EvaluateModel(), usando o seguinte código:
void UseModelForSinglePrediction(MLContext mlContext, ITransformer model)
{
}
Use o PredictionEngine para prever a classificação adicionando o seguinte código à UseModelForSinglePrediction():
Console.WriteLine("=============== Making a prediction ===============");
var predictionEngine = mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(model);
O PredictionEngine é uma API de conveniência, que permite executar uma previsão em uma instância individual de dados. PredictionEngine não é thread-safe. É aceitável usá-lo em ambientes de thread único ou de protótipo. Para aprimorar o desempenho e o acesso thread-safe em ambientes de produção, use o serviço PredictionEnginePool, que cria um ObjectPool de objetos PredictionEngine para uso em todo o aplicativo. Confira este guia sobre como usar o PredictionEnginePool em uma API Web ASP.NET Core.
Observação
A extensão de serviço PredictionEnginePool está atualmente em versão prévia.
Crie uma instância de MovieRating chamada testInput e passe-a para o Mecanismo de Previsão adicionando o seguinte como as próximas linhas do código no método UseModelForSinglePrediction():
var testInput = new MovieRating { userId = 6, movieId = 10 };
var movieRatingPrediction = predictionEngine.Predict(testInput);
A função Predict() faz uma previsão sobre uma única coluna de dados.
Em seguida, use a Score, ou a classificação prevista, para determinar se deseja recomendar o filme com a movieId 10 para o usuário 6. Quanto mais alta a Score, maior a probabilidade de um usuário gostar de um filme específico. Nesse caso, digamos que você recomende filmes com uma classificação prevista de > 3,5.
Para imprimir os resultados, adicione o seguinte como as próximas linhas de código no método UseModelForSinglePrediction():
if (Math.Round(movieRatingPrediction.Score, 1) > 3.5)
{
Console.WriteLine("Movie " + testInput.movieId + " is recommended for user " + testInput.userId);
}
else
{
Console.WriteLine("Movie " + testInput.movieId + " is not recommended for user " + testInput.userId);
}
Adicione o seguinte como a próxima linha de código após a chamada ao método EvaluateModel() para chamar o método UseModelForSinglePrediction():
UseModelForSinglePrediction(mlContext, model);
A saída desse método deve ser semelhante ao seguinte texto:
=============== Making a prediction ===============
Movie 10 is recommended for user 6
Salve seu modelo
Para usar o modelo para fazer previsões em aplicativos de usuário final, primeiro é necessário salvar o modelo.
Crie o método SaveModel(), logo após o método UseModelForSinglePrediction(), usando o seguinte código:
void SaveModel(MLContext mlContext, DataViewSchema trainingDataViewSchema, ITransformer model)
{
}
Salve o modelo treinado adicionando o seguinte código ao método SaveModel():
var modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "MovieRecommenderModel.zip");
Console.WriteLine("=============== Saving the model to a file ===============");
mlContext.Model.Save(model, trainingDataViewSchema, modelPath);
Esse método salva o modelo treinado em um arquivo .zip (na pasta "Data"), que pode ser usado em outros aplicativos .NET para fazer previsões.
Adicione o seguinte como a próxima linha de código após a chamada ao método UseModelForSinglePrediction() para chamar o método SaveModel():
SaveModel(mlContext, trainingDataView.Schema, model);
Usar o modelo salvo
Após salvar seu modelo treinado, você poderá consumir o modelo em diferentes ambientes. Consulte Salvar e carregar modelos treinados para saber como operacionalizar um modelo de machine learning treinado em aplicativos.
Resultados
Depois de seguir as etapas acima, execute o aplicativo de console (Ctrl + F5). Os resultados da previsão individual acima deverão ser semelhantes ao mostrado a seguir. Você poderá ver avisos ou mensagens de processamento, mas essas mensagens foram removidas dos resultados a seguir para maior clareza.
=============== Training the model ===============
iter tr_rmse obj
0 1.5382 3.1213e+05
1 0.9223 1.6051e+05
2 0.8691 1.5050e+05
3 0.8413 1.4576e+05
4 0.8145 1.4208e+05
5 0.7848 1.3895e+05
6 0.7552 1.3613e+05
7 0.7259 1.3357e+05
8 0.6987 1.3121e+05
9 0.6747 1.2949e+05
10 0.6533 1.2766e+05
11 0.6353 1.2636e+05
12 0.6209 1.2561e+05
13 0.6072 1.2462e+05
14 0.5965 1.2394e+05
15 0.5868 1.2352e+05
16 0.5782 1.2279e+05
17 0.5713 1.2227e+05
18 0.5637 1.2190e+05
19 0.5604 1.2178e+05
=============== Evaluating the model ===============
Rms: 0.977175077487166
RSquared: 0.43233349213192
=============== Making a prediction ===============
Movie 10 is recommended for user 6
=============== Saving the model to a file ===============
Parabéns! Você agora criou um modelo de machine learning para recomendação de filmes. Você pode encontrar o código-fonte para este tutorial no repositório dotnet/samples.
Melhorar o modelo
Há várias maneiras de melhorar o desempenho do modelo para obter previsões mais precisas.
Dados
A adição de mais dados de treinamento que tenham amostras suficientes para cada usuário e a ID de filme pode ajudar a melhorar a qualidade do modelo de recomendação.
A validação cruzada é uma técnica para avaliação de modelos que divide dados aleatoriamente em subconjuntos (em vez de extrair os dados de teste do conjunto de dados como você fez neste tutorial) e usa alguns dos grupos como dados de treinamento e alguns dos grupos como dados de teste. Esse método tem um melhor desempenho do que a divisão treinamento/teste em termos de qualidade do modelo.
Recursos
Neste tutorial, você só usará os três Features (user id, movie id e rating) fornecidos pelo conjunto de dados.
Embora esse seja um bom começo, na verdade, o ideal será adicionar outros atributos ou Features (por exemplo, idade, sexo, localização geográfica etc.) se eles forem incluídos no conjunto de dados. A adição de Features mais relevantes pode ajudar a melhorar o desempenho do modelo de recomendação.
Caso não tenha certeza sobre quais Features podem ser mais relevantes para sua tarefa de aprendizado de máquina, use também o FCC (Cálculo de Contribuição do Recurso) e a importância do recurso de permuta, fornecidos pelo ML.NET para descobrir Features mais influentes.
Hiperparâmetros de algoritmo
Embora o ML.NET forneça bons algoritmos de treinamento padrão, você pode ajustar ainda mais o desempenho alterando os hiperparâmetros do algoritmo.
Para a Matrix Factorization, você pode experimentar com hiperparâmetros, como NumberOfIterations e ApproximationRank para ver se ele oferece melhores resultados.
Por exemplo, neste tutorial, as opções de algoritmo são:
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
Outros algoritmos de recomendação
O algoritmo de fatoração de matriz com a filtragem colaborativa é apenas uma abordagem para fazer recomendações de filmes. Em muitos casos, talvez você não tenha os dados de classificações disponíveis e tenha apenas o histórico de filmes disponível dos usuários. Em outros casos, você pode ter mais do que apenas os dados de classificação do usuário.
| Algoritmo | Cenário | Amostra |
|---|---|---|
| Fatoração de Matriz de uma Classe | Use isso quando você tiver apenas userId e movieId. Esse estilo de recomendação é baseado no cenário de cocompra, ou produtos frequentemente comprados juntos, o que significa que ele recomendará aos clientes um conjunto de produtos de acordo com seu próprio histórico de ordens de compra. | >Experimente |
| Computadores de Fatoração com Reconhecimento de Campo | Use isso para fazer recomendações quando você tiver mais Recursos do que userId, productId e a classificação (como descrição ou preço do produto). Esse método também usa uma abordagem de filtragem colaborativa. | >Experimente |
Novo cenário de usuário
Um problema comum na filtragem colaborativa é o problema de inicialização a frio, que é quando você tem um novo usuário sem nenhum dado anterior do qual fazer inferências. Esse problema costuma ser resolvido com a solicitação da criação de um perfil aos novos usuários e, por exemplo, da classificação de filmes que assistiram no passado. Embora esse método seja um fardo para o usuário, ele fornece alguns dados iniciais para novos usuários sem nenhum histórico de classificação.
Recursos
Os dados usados neste tutorial foram obtidos do Conjunto de dados MovieLens.
Próximas etapas
Neste tutorial, você aprendeu a:
- Selecionar um algoritmo de aprendizado de máquina
- Preparar e carregar os dados
- Criar e treinar um modelo
- Avaliar um modelo
- Implantar e consumir um modelo
Avançar para o próximo tutorial para saber mais