Tutorial: Inspeção visual automatizada usando o aprendizado de transferência com a API de Classificação de Imagem ML.NET
Saiba como treinar um modelo de aprendizado profundo personalizado usando o aprendizado de transferência, um modelo tensorFlow pré-treinado e a API de Classificação de Imagem ML.NET para classificar imagens de superfícies concretas como rachadas ou não rachadas.
Neste tutorial, você aprenderá a:
- Entender o problema
- Saiba mais sobre ML.NET API de Classificação de Imagens
- Entender o modelo pré-treinado
- Usar aprendizado por transferência para treinar um modelo de classificação de imagem TensorFlow personalizado
- Classificar imagens com o modelo personalizado
Pré-requisitos
Entender o problema
A classificação de imagem é um problema de visão computacional. A classificação de imagem usa uma imagem como entrada e a categoriza em uma classe prescrita. Os modelos de classificação de imagem geralmente são treinados usando redes neurais e de aprendizado profundo. Para obter mais informações, consulte Aprendizado profundo versusde aprendizado de máquina.
Alguns cenários em que a classificação de imagem é útil incluem:
- Reconhecimento facial
- Detecção de emoções
- Diagnóstico médico
- Detecção de ponto de referência
Este tutorial treina um modelo de classificação de imagem personalizado para executar a inspeção visual automatizada de decks de ponte para identificar estruturas danificadas por rachaduras.
API de Classificação de Imagem ML.NET
ML.NET fornece várias maneiras de executar a classificação de imagem. Este tutorial aplica o aprendizado de transferência usando a API de Classificação de Imagem. A API de Classificação de Imagem usa TensorFlow.NET, uma biblioteca de nível baixo que fornece associações C# para a API C++do TensorFlow.
O que é aprendizado de transferência?
A transferência de aprendizado aplica o conhecimento obtido com a resolução de um problema para outro problema relacionado.
Treinar um modelo de aprendizado profundo do zero requer a definição de vários parâmetros, uma grande quantidade de dados de treinamento rotulados e uma grande quantidade de recursos de computação (centenas de horas de GPU). O uso de um modelo pré-treinado junto com a transferência de aprendizado permite que você encurte o processo de treinamento.
Processo de treinamento
A API de Classificação de Imagem inicia o processo de treinamento carregando um modelo tensorFlow pré-treinado. O processo de treinamento consiste em duas etapas:
- Fase de gargalo.
- Fase de treinamento.
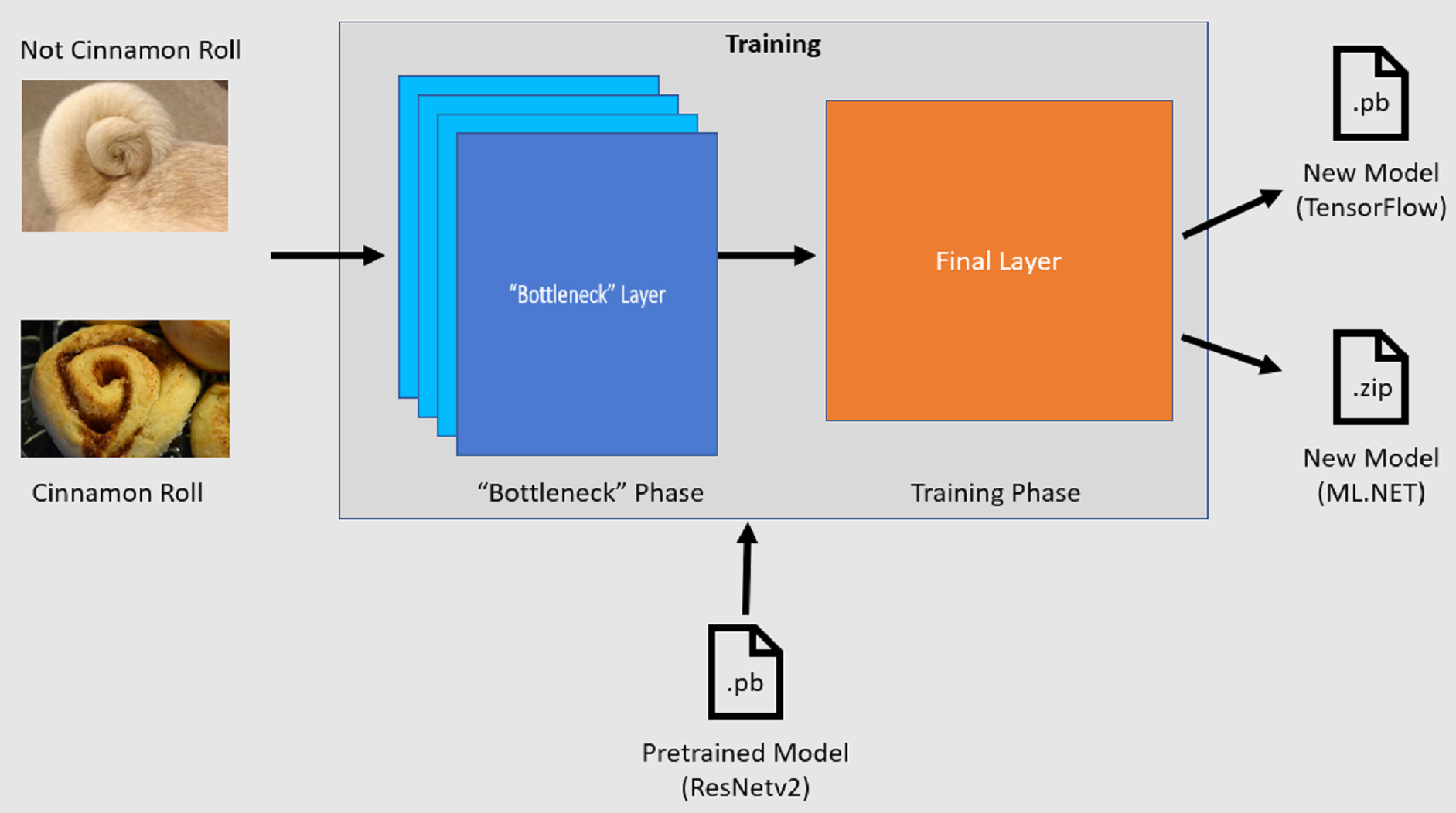
Fase de gargalo
Durante a fase de gargalo, o conjunto de imagens de treinamento é carregado e os valores de pixel são usados como entrada ou recursos para as camadas congeladas do modelo pré-treinado. As camadas congeladas incluem todas as camadas na rede neural até a penúltima camada, informalmente conhecida como camada de gargalo. Essas camadas são conhecidas como congeladas porque nenhum treinamento ocorrerá nelas e as operações são transmitidas diretamente. É nessas camadas congeladas em que os padrões de nível inferior que ajudam um modelo a diferenciar entre as diferentes classes são computados. Quanto maior o número de camadas, mais intensiva será essa etapa. Felizmente, como esse é um cálculo único, os resultados podem ser armazenados em cache e usados em execuções posteriores ao experimentar parâmetros diferentes.
Fase de treinamento
Depois que os valores de saída da fase de gargalo são computados, eles são usados como entrada para treinar novamente a camada final do modelo. Esse processo é iterativo e é executado pelo número de vezes especificado por parâmetros de modelo. Durante cada execução, a perda e a precisão são avaliadas. Em seguida, os ajustes apropriados são feitos para melhorar o modelo com o objetivo de minimizar a perda e maximizar a precisão. Depois que o treinamento for concluído, dois formatos de modelo serão gerados. Uma delas é a versão .pb do modelo e a outra é a versão serializada .zip ML.NET do modelo. Ao trabalhar em ambientes compatíveis com ML.NET, é recomendável usar a versão .zip do modelo. No entanto, em ambientes em que não há suporte para ML.NET, você tem a opção de usar a versão .pb.
Entender o modelo pré-treinado
O modelo pré-treinado usado neste tutorial é a variante de 101 camadas do modelo de Rede Residual (ResNet) v2. O modelo original é treinado para classificar imagens em mil categorias. O modelo usa como entrada uma imagem de tamanho 224 x 224 e gera as probabilidades para cada classe em que foi treinado. Parte desse modelo é usada para treinar um novo modelo usando imagens personalizadas para fazer previsões entre duas classes.
Criar aplicativo de console
Agora que você tem uma compreensão geral do aprendizado de transferência e da API de Classificação de Imagem, é hora de criar o aplicativo.
Crie um Aplicativo de Console C# chamado "DeepLearning_ImageClassification_Binary". Clique no botão Avançar.
Escolha o .NET 8 como a estrutura a ser usada e selecione Criar.
Instale o pacote NuGet Microsoft.ML:
Nota
Este exemplo usa a versão estável mais recente dos pacotes NuGet mencionados, a menos que indicado de outra forma.
- No Gerenciador de Soluções, clique com o botão direito do mouse em seu projeto e selecione Gerenciar Pacotes NuGet.
- Escolha "nuget.org" como a origem do pacote.
- Selecione a guia Procurar.
- Marque a caixa de seleção Incluir pré-lançamento.
- Pesquise Microsoft.ML.
- Selecione o botão Instalar.
- Selecione o botão Aceito na caixa de diálogo Aceitação de Licença se você concordar com os termos de licença para os pacotes listados.
- Repita estes passos para os pacotes NuGet Microsoft.ML.Vision, SciSharp.TensorFlow.Redist (versão 2.3.1)e Microsoft.ML.ImageAnalytics.
Preparar e entender os dados
Nota
Os conjuntos de dados deste tutorial são de Maguire, Marc; Dorafshan, Sattar; e Thomas, Robert J., "SDNET2018: um conjunto de dados de imagens de fissuras em concreto para aplicações de aprendizado de máquina" (2018). Navegue por todos os conjuntos de dados. Papel 48. https://digitalcommons.usu.edu/all_datasets/48
SDNET2018 é um conjunto de imagens que contém anotações para estruturas de concreto rachadas e não rachadas (tabuleiros de ponte, paredes e pavimento).

Os dados são organizados em três subdiretórios:
- D contém imagens do tabuleiro de ponte
- P contém imagens de pavimento
- W contém imagens de parede
Cada um desses subdiretórios contém dois subdiretórios prefixados adicionais:
- C é o prefixo usado para superfícies rachadas
- U é o prefixo usado para superfícies sem falhas
Neste tutorial, apenas imagens do tabuleiro da ponte são usadas.
- Baixe o conjunto de dados e descompacte.
- Crie um diretório chamado "Ativos" em seu projeto para salvar os arquivos do conjunto de dados.
- Copie os subdiretórios CD e UD do diretório descompactado recentemente para o diretório Assets.
Criar classes de entrada e saída
Abra o arquivo Program.cs e substitua o conteúdo existente pelas seguintes diretivas de
using:using Microsoft.ML; using Microsoft.ML.Vision; using static Microsoft.ML.DataOperationsCatalog;Criar uma classe chamada
ImageData. Essa classe é usada para representar os dados carregados inicialmente.class ImageData { public string? ImagePath { get; set; } public string? Label { get; set; } }ImageDatacontém as seguintes propriedades:ImagePathé o caminho totalmente qualificado em que a imagem é armazenada.Labelé a categoria à qual a imagem pertence. Esse é o valor a ser previsto.
Crie classes para seus dados de entrada e saída.
Abaixo da classe
ImageData, defina o esquema dos dados de entrada em uma nova classe chamadaModelInput.class ModelInput { public byte[]? Image { get; set; } public uint LabelAsKey { get; set; } public string? ImagePath { get; set; } public string? Label { get; set; } }ModelInputcontém as seguintes propriedades:Imageé a representaçãobyte[]da imagem. O modelo espera que os dados de imagem sejam desse tipo para treinamento.LabelAsKeyé a representação numérica doLabel.ImagePathé o caminho totalmente qualificado em que a imagem é armazenada.Labelé a categoria à qual a imagem pertence. Esse é o valor a ser previsto.
Somente
ImageeLabelAsKeysão usados para treinar o modelo e fazer previsões. As propriedadesImagePatheLabelsão mantidas por conveniência para acessar o nome e a categoria do arquivo de imagem original.Em seguida, abaixo da classe
ModelInput, defina o esquema dos dados de saída em uma nova classe chamadaModelOutput.class ModelOutput { public string? ImagePath { get; set; } public string? Label { get; set; } public string? PredictedLabel { get; set; } }ModelOutputcontém as seguintes propriedades:ImagePathé o caminho totalmente qualificado em que a imagem é armazenada.Labelé a categoria original à qual a imagem pertence. Esse é o valor a ser previsto.PredictedLabelé o valor previsto pelo modelo.
Semelhante a
ModelInput, somente oPredictedLabelé necessário para fazer previsões, pois contém a previsão feita pelo modelo. As propriedadesImagePatheLabelsão retidas por conveniência para acessar o nome e a categoria do arquivo de imagem original.
Definir caminhos e inicializar variáveis
Nas diretivas
using, adicione o seguinte código a:Defina o local dos ativos.
Inicialize a variável
mlContextcom uma nova instância de MLContext.A classe MLContext é um ponto de partida para todas as operações de ML.NET e a inicialização do mlContext cria um novo ambiente ML.NET que pode ser compartilhado entre os objetos de fluxo de trabalho de criação de modelo. É semelhante, conceitualmente, a
DbContextno Entity Framework.
var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var assetsRelativePath = Path.Combine(projectDirectory, "Assets"); MLContext mlContext = new();
Carregar os dados
Criar método de utilitário de carregamento de dados
As imagens são armazenadas em dois subdiretórios. Antes de carregar os dados, ele precisa ser formatado em uma lista de objetos ImageData. Para fazer isso, crie o método LoadImagesFromDirectory:
static IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
var files = Directory.GetFiles(folder, "*",
searchOption: SearchOption.AllDirectories);
foreach (var file in files)
{
if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png"))
continue;
var label = Path.GetFileName(file);
if (useFolderNameAsLabel)
label = Directory.GetParent(file)?.Name;
else
{
for (int index = 0; index < label.Length; index++)
{
if (!char.IsLetter(label[index]))
{
label = label[..index];
break;
}
}
}
yield return new ImageData()
{
ImagePath = file,
Label = label
};
}
}
O método LoadImagesFromDirectory:
- Obtém todos os caminhos de arquivo dos subdiretórios.
- Itera em cada um dos arquivos usando uma instrução
foreache verifica se as extensões de arquivo são compatíveis. A API de Classificação de Imagem dá suporte a formatos JPEG e PNG. - Obtém o rótulo do arquivo. Se o parâmetro
useFolderNameAsLabelestiver definido comotrue, o diretório pai em que o arquivo é salvo será usado como o rótulo. Caso contrário, ele espera que o rótulo seja um prefixo do nome do arquivo ou do próprio nome do arquivo. - Cria uma nova instância de
ModelInput.
Preparar os dados
Adicione o código a seguir após a linha em que você cria a nova instância de MLContext.
IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);
IDataView imageData = mlContext.Data.LoadFromEnumerable(images);
IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey(
inputColumnName: "Label",
outputColumnName: "LabelAsKey")
.Append(mlContext.Transforms.LoadRawImageBytes(
outputColumnName: "Image",
imageFolder: assetsRelativePath,
inputColumnName: "ImagePath"));
IDataView preProcessedData = preprocessingPipeline
.Fit(shuffledData)
.Transform(shuffledData);
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3);
TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);
IDataView trainSet = trainSplit.TrainSet;
IDataView validationSet = validationTestSplit.TrainSet;
IDataView testSet = validationTestSplit.TestSet;
O código anterior:
Chama o método utilitário
LoadImagesFromDirectorypara obter a lista de imagens usadas para treinamento depois de inicializar a variávelmlContext.Carrega as imagens em um
IDataViewusando o métodoLoadFromEnumerable.Embaralha os dados usando o método
ShuffleRows. Os dados são carregados na ordem em que foram lidos dos diretórios. O embaralhamento é executado para equilibrá-lo.Executa alguns pré-processamentos nos dados antes do treinamento. Isso é feito porque os modelos de machine learning esperam que a entrada esteja em formato numérico. O código de pré-processamento cria uma
EstimatorChainconstituída pelas transformaçõesMapValueToKeyeLoadRawImageBytes. A transformaçãoMapValueToKeyusa o valor categórico na colunaLabel, converte-o em um valor deKeyTypenumérico e o armazena em uma nova coluna chamadaLabelAsKey. OLoadImagesusa os valores da colunaImagePathjunto com o parâmetroimageFolderpara carregar imagens para treinamento.Usa o método
Fitpara aplicar os dados aopreprocessingPipelineEstimatorChainseguido pelo métodoTransform, que retorna umIDataViewque contém os dados pré-processados.Divide os dados em conjuntos de treinamento, validação e teste.
Para treinar um modelo, é importante ter um conjunto de dados de treinamento, bem como um conjunto de dados de validação. O modelo é treinado no conjunto de treinamento. O quão bem ele faz previsões em dados não vistos é medido pelo desempenho em relação ao conjunto de validação. Com base nos resultados desse desempenho, o modelo faz ajustes no que aprendeu em um esforço para melhorar. O conjunto de validação pode vir da divisão do conjunto de dados original ou de outra fonte que já foi reservada para essa finalidade.
O exemplo de código executa duas divisões. Primeiro, os dados pré-processados são divididos e 70% são usados para treinamento enquanto os 30% restantes são usados para validação. Em seguida, o conjunto de validação de 30% é dividido em conjuntos de validação e teste em que 90% são usados para validação e 10% são usados para teste.
Uma maneira de pensar sobre a finalidade dessas partições de dados é fazer um exame. Ao estudar para um exame, você revisa suas anotações, livros ou outros recursos para entender os conceitos que estão no exame. É para isso que serve o conjunto de trens. Então, você pode fazer um exame simulado para validar seu conhecimento. É aqui que o conjunto de validação é útil. Você deseja verificar se você tem uma boa compreensão dos conceitos antes de fazer o exame real. Com base nesses resultados, você anota o que errou ou não entendeu bem e incorpora suas alterações à medida que revisa para o exame real. Finalmente, você faz o exame. É para isso que o conjunto de testes é usado. Você nunca viu as perguntas que estão no exame e agora usa o que aprendeu com o treinamento e a validação para aplicar seu conhecimento à tarefa em questão.
Atribui às partições seus respectivos valores para os dados de treinamento, validação e teste.
Definir o pipeline de treinamento
O treinamento de modelo consiste em duas etapas. Primeiro, a API de Classificação de Imagem é usada para treinar o modelo. Em seguida, os rótulos codificados na coluna PredictedLabel são convertidos novamente em seu valor categórico original usando a transformação MapKeyToValue.
var classifierOptions = new ImageClassificationTrainer.Options()
{
FeatureColumnName = "Image",
LabelColumnName = "LabelAsKey",
ValidationSet = validationSet,
Arch = ImageClassificationTrainer.Architecture.ResnetV2101,
MetricsCallback = (metrics) => Console.WriteLine(metrics),
TestOnTrainSet = false,
ReuseTrainSetBottleneckCachedValues = true,
ReuseValidationSetBottleneckCachedValues = true
};
var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions)
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
ITransformer trainedModel = trainingPipeline.Fit(trainSet);
O código anterior:
Cria uma nova variável para armazenar um conjunto de parâmetros obrigatórios e opcionais para um ImageClassificationTrainer. Um ImageClassificationTrainer usa vários parâmetros opcionais:
FeatureColumnNameé a coluna usada como entrada para o modelo.LabelColumnNameé a coluna para o valor a ser previsto.ValidationSeté oIDataViewque contém os dados de validação.Archdefine qual das arquiteturas de modelo pré-treinadas usar. Este tutorial usa a variante de 101 camadas do modelo ResNetv2.MetricsCallbackassocia uma função para acompanhar o progresso durante o treinamento.TestOnTrainSetinstrui o modelo a medir o desempenho em relação ao conjunto de treinamento quando nenhum conjunto de validação está presente.ReuseTrainSetBottleneckCachedValuesinforma ao modelo se os valores armazenados em cache devem ser usados da fase de gargalo em execuções subsequentes. A fase de gargalo é uma computação de passagem única que é computacionalmente intensiva na primeira vez que é executada. Se os dados de treinamento não forem alterados e você quiser experimentar usando um número diferente de épocas ou tamanho de lote, usar os valores armazenados em cache reduzirá significativamente o tempo necessário para treinar um modelo.ReuseValidationSetBottleneckCachedValuesé semelhante aReuseTrainSetBottleneckCachedValuessomente que, nesse caso, é para o conjunto de dados de validação.
Define o pipeline de treinamento
EstimatorChainque consiste nomapLabelEstimatore no ImageClassificationTrainer.Usa o método
Fitpara treinar o modelo.
Usar o modelo
Agora que você treinou o modelo, é hora de usá-lo para classificar imagens.
Crie um novo método de utilitário chamado OutputPrediction para exibir informações de previsão no console.
static void OutputPrediction(ModelOutput prediction)
{
string? imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
Classificar uma única imagem
Crie um método chamado
ClassifySingleImagepara fazer e gerar uma única previsão de imagem.static void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel); ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data, reuseRowObject: true).First(); ModelOutput prediction = predictionEngine.Predict(image); Console.WriteLine("Classifying single image"); OutputPrediction(prediction); }O método
ClassifySingleImage:- Cria um
PredictionEnginedentro do métodoClassifySingleImage. OPredictionEngineé uma API de conveniência que permite inserir e executar uma previsão em uma só instância de dados. - Para acessar uma única instância de
ModelInput, converte odataIDataViewem umIEnumerableusando o métodoCreateEnumerablee, em seguida, obtém a primeira observação. - Usa o método
Predictpara classificar a imagem. - Gera a previsão para o console com o método
OutputPrediction.
- Cria um
Chame
ClassifySingleImagedepois de chamar o métodoFitusando o conjunto de imagens de teste.ClassifySingleImage(mlContext, testSet, trainedModel);
Classificar várias imagens
Crie um método chamado
ClassifyImagespara fazer e gerar várias previsões de imagem.static void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { IDataView predictionData = trainedModel.Transform(data); IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10); Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); } }O método
ClassifyImages:- Cria um
IDataViewque contém as previsões usando o métodoTransform. - Para iterar sobre as previsões, converte o
predictionDataIDataViewem umIEnumerableusando o métodoCreateEnumerablee, em seguida, obtém as primeiras 10 observações. - Itera e gera os rótulos originais e previstos para as previsões.
- Cria um
Chame
ClassifyImagesdepois de chamar o métodoClassifySingleImage()usando o conjunto de imagens de teste.ClassifyImages(mlContext, testSet, trainedModel);
Executar o aplicativo
Execute seu aplicativo de console. A saída deve ser semelhante à saída a seguir.
Nota
Você pode ver avisos ou mensagens de processamento; essas mensagens foram removidas dos seguintes resultados para maior clareza. Para ser breve, o resultado foi condensado.
Fase de gargalo
Nenhum valor é impresso para o nome da imagem porque as imagens são carregadas como um byte[] portanto, não há nenhum nome de imagem a ser exibido.
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
Fase de treinamento
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
Classificar a saída de imagens
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
Após a inspeção da imagem 7001-220.jpg, você pode verificar se ela não está rachada, como o modelo previu.

Parabéns! Agora você criou com êxito um modelo de aprendizado profundo para classificar imagens.
Melhorar o modelo
Se você não estiver satisfeito com os resultados do modelo, poderá tentar melhorar seu desempenho tentando algumas das seguintes abordagens:
- Mais Dados: Quanto mais exemplos um modelo aprender, melhor ele desempenha. Baixe o conjunto de dados SDNET2018 completo e use-o para treinar.
- Aumentar os dados: uma técnica comum para adicionar variedade aos dados é aumentar os dados usando uma imagem e aplicando diferentes transformações (girar, inverter, mudar, cortar). Isso adiciona exemplos mais variados para o modelo aprender.
- Treinar por mais tempo: quanto mais tempo você treinar, mais ajustado ficará o modelo. Aumentar o número de épocas pode melhorar o desempenho do modelo.
- Teste com os hipermetrâmetros: além dos parâmetros usados neste tutorial, outros parâmetros podem ser ajustados para potencialmente melhorar o desempenho. Alterar a taxa de aprendizado, que determina a magnitude das atualizações feitas no modelo após cada época, pode melhorar o desempenho.
- Usar uma arquitetura de modelo diferente: dependendo da aparência dos dados, o modelo que pode aprender melhor seus recursos pode ser diferente. Se você não estiver satisfeito com o desempenho do modelo, tente alterar a arquitetura.
Próximas etapas
Neste tutorial, você aprendeu a criar um modelo de aprendizado profundo personalizado usando o aprendizado de transferência, um modelo tensorFlow de classificação de imagem pré-treinado e a API de Classificação de Imagem ML.NET para classificar imagens de superfícies concretas como rachadas ou desfeitas.
Avance para o próximo tutorial para saber mais.