Implementar a camada de persistência de infraestrutura com o Entity Framework Core
Dica
Esse conteúdo é um trecho do eBook da Arquitetura de Microsserviços do .NET para os Aplicativos .NET em Contêineres, disponível no .NET Docs ou como um PDF para download gratuito que pode ser lido offline.

Ao usar bancos de dados relacionais, como o SQL Server, o Oracle ou o PostgreSQL, uma abordagem recomendada é implementar a camada de persistência com base no EF (Entity Framework). O EF é compatível com LINQ e fornece objetos fortemente tipados para o modelo, bem como uma persistência simplificada no banco de dados.
O Entity Framework tem uma longa história de participação no .NET Framework. Ao usar o .NET, você também deve usar o Entity Framework Core, que é executado no Windows ou no Linux da mesma forma que no .NET. O EF Core é uma reformulação completa do Entity Framework implementada com uma superfície muito menor e aprimoramentos importantes no desempenho.
Introdução ao Entity Framework Core
O Entity Framework (EF) Core é uma versão de multiplaforma leve, extensível e de plataforma cruzada da popular tecnologia de acesso a dados do Entity Framework. Ele foi introduzido com o .NET Core em meados de 2016.
Como uma introdução ao EF Core já está disponível na documentação da Microsoft, aqui nós vamos fornecer apenas os links para as informações.
Recursos adicionais
Entity Framework Core
https://learn.microsoft.com/ef/core/Introdução ao ASP.NET Core e ao Entity Framework Core usando o Visual Studio
https://learn.microsoft.com/aspnet/core/data/ef-mvc/Classe DbContext
https://learn.microsoft.com/dotnet/api/microsoft.entityframeworkcore.dbcontextComparar o EF Core e o EF6.x
https://learn.microsoft.com/ef/efcore-and-ef6/index
Infraestrutura no Entity Framework Core da perspectiva do DDD
Do ponto de vista do DDD, um recurso importante do EF é a capacidade de usar as entidades de domínio POCO (objeto CRL básico), também conhecidas na terminologia do EF como entidades code-first POCO. Se você usar as entidades de domínio POCO, as classes de modelo de domínio ignorarão a persistência, seguindo os princípios de Ignorância de Persistência e de Ignorância de Infraestrutura.
De acordo com os padrões do DDD você deve encapsular o comportamento e as regras do domínio dentro da própria classe de entidade, assim ela poderá controlar as invariáveis, as validações e as regras ao acessar qualquer coleção. Portanto, não é uma prática recomendada no DDD permitir o acesso público a coleções de entidades filhas ou a objetos de valor. Em vez disso, é possível expor métodos que controlam como e quando as coleções de propriedade e os campos podem ser atualizados e qual comportamento e medidas deverão ser tomadas quando isso acontecer.
Desde o EF Core 1.1, para atender a esses requisitos de DDD, é possível ter campos simples nas entidades em vez de propriedades públicas. Se você não quiser que um campo de entidade fique acessível externamente, bastará criar o atributo ou o campo em vez de uma propriedade. Também é possível usar setters de propriedade privada.
Da mesma forma, agora é possível que haja acesso somente leitura a coleções usando uma propriedade pública tipada como IReadOnlyCollection<T>, com o apoio de um membro de campo privado para a coleção (como uma List<T>) na entidade, que se baseia no EF para persistência. As versões anteriores do Entity Framework exigiam que as propriedades da coleção fossem compatíveis com ICollection<T>, o que significava que qualquer desenvolvedor que usasse uma classe da entidade pai poderia adicionar ou remover itens por meio de suas coleções de propriedade. Essa possibilidade seria em relação aos padrões recomendados no DDD.
É possível usar uma coleção privada ao expor um objeto IReadOnlyCollection<T> somente leitura, como é mostrado no exemplo de código a seguir:
public class Order : Entity
{
// Using private fields, allowed since EF Core 1.1
private DateTime _orderDate;
// Other fields ...
private readonly List<OrderItem> _orderItems;
public IReadOnlyCollection<OrderItem> OrderItems => _orderItems;
protected Order() { }
public Order(int buyerId, int paymentMethodId, Address address)
{
// Initializations ...
}
public void AddOrderItem(int productId, string productName,
decimal unitPrice, decimal discount,
string pictureUrl, int units = 1)
{
// Validation logic...
var orderItem = new OrderItem(productId, productName,
unitPrice, discount,
pictureUrl, units);
_orderItems.Add(orderItem);
}
}
A propriedade OrderItems só pode ser acessada como somente leitura usando IReadOnlyCollection<OrderItem>. Esse tipo é somente leitura, portanto, ele está protegido contra as atualizações externas regulares.
O EF Core fornece uma maneira de mapear o modelo de domínio para o banco de dados físico sem "contaminar" o modelo de domínio. Trata-se de puro código POCO do .NET, pois a ação de mapeamento é implementada na camada de persistência. Nessa ação de mapeamento, você precisa configurar o mapeamento dos campos para o banco de dados. No exemplo a seguir do método OnModelCreating de OrderingContext e da classe OrderEntityTypeConfiguration, a chamada para SetPropertyAccessMode informa ao EF Core para acessar a propriedade OrderItems por meio de seu campo.
// At OrderingContext.cs from eShopOnContainers
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
// ...
modelBuilder.ApplyConfiguration(new OrderEntityTypeConfiguration());
// Other entities' configuration ...
}
// At OrderEntityTypeConfiguration.cs from eShopOnContainers
class OrderEntityTypeConfiguration : IEntityTypeConfiguration<Order>
{
public void Configure(EntityTypeBuilder<Order> orderConfiguration)
{
orderConfiguration.ToTable("orders", OrderingContext.DEFAULT_SCHEMA);
// Other configuration
var navigation =
orderConfiguration.Metadata.FindNavigation(nameof(Order.OrderItems));
//EF access the OrderItem collection property through its backing field
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
// Other configuration
}
}
Quando você usa campos em vez de propriedades, a entidade OrderItem é persistida como se tivesse uma propriedade List<OrderItem>. No entanto, ela expõe um único acessador, o método AddOrderItem, para adicionar novos itens ao pedido. Como resultado, o comportamento e os dados ficarão vinculados e serão consistentes em todos os códigos de aplicativo que usarem o modelo de domínio.
Implementar repositórios personalizados com o Entity Framework Core
No nível da implementação, um repositório é simplesmente uma classe com o código de persistência de dados, coordenada por uma unidade de trabalho (DBContext no EF Core) ao executar atualizações, como mostra a seguinte classe:
// using directives...
namespace Microsoft.eShopOnContainers.Services.Ordering.Infrastructure.Repositories
{
public class BuyerRepository : IBuyerRepository
{
private readonly OrderingContext _context;
public IUnitOfWork UnitOfWork
{
get
{
return _context;
}
}
public BuyerRepository(OrderingContext context)
{
_context = context ?? throw new ArgumentNullException(nameof(context));
}
public Buyer Add(Buyer buyer)
{
return _context.Buyers.Add(buyer).Entity;
}
public async Task<Buyer> FindAsync(string buyerIdentityGuid)
{
var buyer = await _context.Buyers
.Include(b => b.Payments)
.Where(b => b.FullName == buyerIdentityGuid)
.SingleOrDefaultAsync();
return buyer;
}
}
}
A interface IBuyerRepository vem da camada de modelo de domínio como um contrato. No entanto, a implementação do repositório é feita na camada de persistência e de infraestrutura.
O DbContext do EF é fornecido pelo construtor por meio de injeção de dependência. Ele é compartilhado entre vários repositórios no mesmo escopo de solicitação HTTP, graças ao seu tempo de vida padrão (ServiceLifetime.Scoped) no contêiner de IoC (inversão de controle) (que também pode ser definido explicitamente com services.AddDbContext<>).
Métodos a serem implementados em um repositório (atualizações ou transações em comparação com consultas)
Em cada classe de repositório, você deve colocar os métodos de persistência que atualizam o estado das entidades contidas na agregação relacionada. Lembre-se de que há uma relação um-para-um entre uma agregação e seu repositório relacionado. Leve em consideração que um objeto de entidade de raiz de agregação pode ter entidades filhas inseridas no grafo do EF. Por exemplo, um comprador pode ter vários métodos de pagamento como entidades filhas relacionadas.
Como a abordagem para o microsserviço de pedidos no eShopOnContainers também se baseia em CQS/CQRS, a maioria das consultas não são implementadas em repositórios personalizados. Os desenvolvedores têm a liberdade de criar as consultas e junções que precisam para a camada de apresentação sem as restrições impostas pelas agregações, pelos repositórios personalizados por agregação e pelo DDD em geral. A maioria dos repositórios personalizados sugeridos por este guia tem vários métodos de atualização ou transacionais, mas apenas os métodos de consulta necessários para fazer com que os dados sejam atualizados. Por exemplo, o repositório BuyerRepository implementa um método FindAsync, porque o aplicativo precisa saber se um comprador específico existe antes de criar um novo comprador relacionado ao pedido.
No entanto, os métodos de consulta reais para obter os dados a serem enviados à camada de apresentação ou aos aplicativos clientes são implementados, conforme mencionado, nas consultas de CQRS baseadas em consultas flexíveis usando Dapper.
Usando um repositório personalizado em vez de usar o DbContext EF diretamente
A classe DbContext do Entity Framework se baseia nos padrões de unidade de trabalho e de repositório e pode ser usada diretamente no código, como em um controlador do ASP.NET Core MVC. Os padrões de unidade trabalho e repositório resultam no código mais simples, como no microsserviço de catálogo CRUD em eShopOnContainers. Nos casos em que você deseja o código mais simples possível, é possível usar diretamente a classe DbContext, como muitos desenvolvedores fazem.
No entanto, a implementação de repositórios personalizados oferece vários benefícios ao implementar microsserviços ou aplicativos mais complexos. Os padrões de unidade de trabalho e de repositório são indicados para encapsular a camada de persistência da infraestrutura para que ela fique desacoplada das camadas de aplicativo e de modelo de domínio. A implementação desses padrões pode facilitar o uso de repositórios fictícios para simulação de acesso ao banco de dados.
Na Figura 7-18, veja as diferenças entre usar repositórios (direto, com o DbContext do EF) e não usar repositórios, o que facilita a simulação desses repositórios.
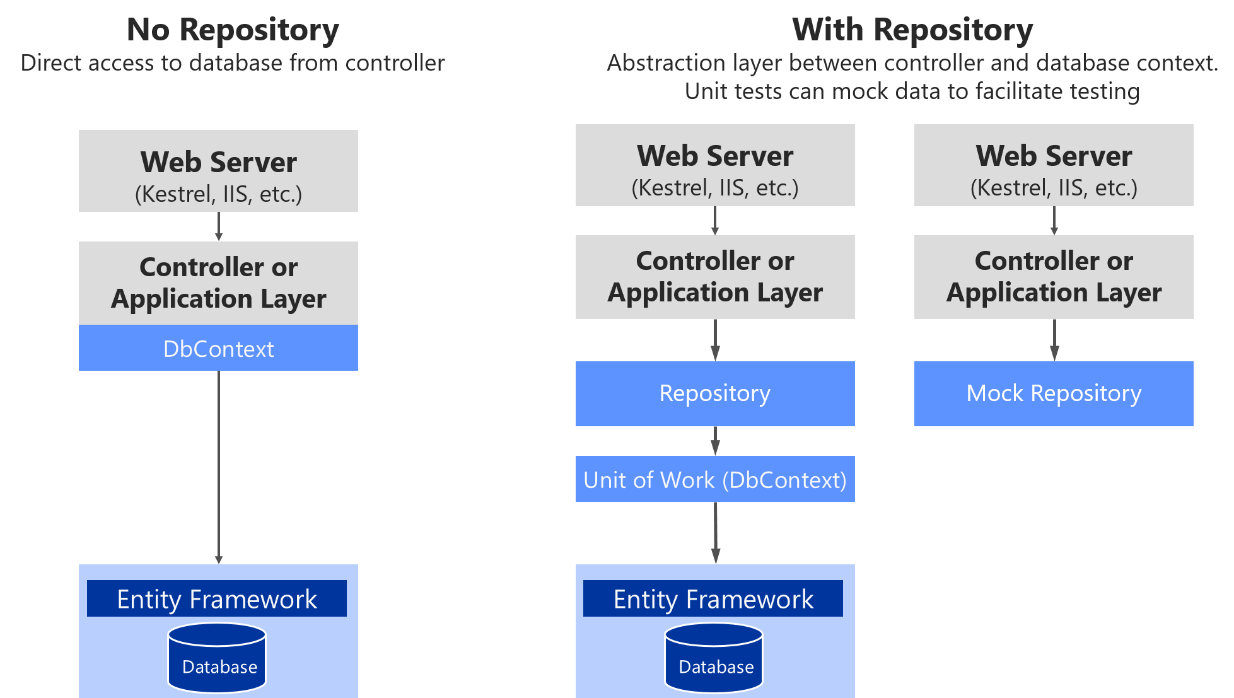
Figura 7-18. Usando repositórios personalizados em vez de um DbContext simples
A Figura 7-18 mostra que o uso de um repositório personalizado adiciona uma camada de abstração que pode ser usada para facilitar os testes simulando o repositório. Existem várias alternativas para simulação. Você pode simular apenas repositórios ou simular toda a unidade de trabalho. Geralmente, simular apenas os repositórios já é suficiente e a complexidade de abstrair e simular toda a unidade de trabalho, normalmente, não é necessária.
Mais adiante, quando nos concentramos na camada de aplicativo, você verá como funciona a injeção de dependência no ASP.NET Core e como ela é implementada ao usar repositórios.
Em resumo, os repositórios personalizados permitem que você teste o código mais facilmente com testes de unidade que não são afetados pelo estado da camada de dados. Se você executar testes que também acessem o banco de dados real por meio do Entity Framework, eles não serão testes de unidade, mas sim testes de integração, que são muito mais lentos.
Se estivesse usando o DbContext diretamente, você precisaria simulá-lo ou executar testes de unidade usando um SQL Server na memória, com os dados previsíveis para testes de unidade. Mas simular o DbContext ou controlar dados falsos requer mais trabalho do que a simulação no nível do repositório. Obviamente, sempre é possível testar os controladores MVC.
Tempo de vida da instância de DbContext e de IUnitOfWork do EF no contêiner de IoC
O objeto DbContext (exposto como um objeto IUnitOfWork) deve ser compartilhado entre vários repositórios dentro do mesmo escopo de solicitação HTTP. Por exemplo, isso é verdadeiro quando a operação que está sendo executada precisa lidar com várias agregações ou simplesmente porque você está usando várias instâncias do repositório. Também é importante mencionar que a interface IUnitOfWork faz parte da camada de domínio, ela não é um tipo do EF Core.
Para isso, o tempo de vida de serviço da instância do objeto DbContext precisa ser definido como ServiceLifetime.Scoped. Este é o tempo de vida padrão ao registrar um DbContext com builder.Services.AddDbContext no contêiner de IoC do arquivo Program.cs, no projeto de API Web ASP.NET Core. O código a seguir ilustra isso.
// Add framework services.
builder.Services.AddMvc(options =>
{
options.Filters.Add(typeof(HttpGlobalExceptionFilter));
}).AddControllersAsServices();
builder.Services.AddEntityFrameworkSqlServer()
.AddDbContext<OrderingContext>(options =>
{
options.UseSqlServer(Configuration["ConnectionString"],
sqlOptions => sqlOptions.MigrationsAssembly(typeof(Startup).GetTypeInfo().
Assembly.GetName().Name));
},
ServiceLifetime.Scoped // Note that Scoped is the default choice
// in AddDbContext. It is shown here only for
// pedagogic purposes.
);
O modo de criação de instância do DbContext não deve ser configurado como ServiceLifetime.Transient ou ServiceLifetime.Singleton.
O tempo de vida da instância de repositório no contêiner de IoC
Da mesma forma, o tempo de vida do repositório deve ser definido como escopo (InstancePerLifetimeScope no Autofac). Ele também pode ser transitório (InstancePerDependency no Autofac), mas o serviço será mais eficiente em relação à memória ao usar o tempo de vida no escopo.
// Registering a Repository in Autofac IoC container
builder.RegisterType<OrderRepository>()
.As<IOrderRepository>()
.InstancePerLifetimeScope();
O uso do tempo de vida singleton para o repositório pode causar sérios problemas de simultaneidade quando o DbContext é definido como tempo de vida com escopo (InstancePerLifetimeScope) (os tempos de vida padrão de um DBContext). Desde que seus tempos de vida de serviço para seus repositórios e seu DbContext estejam no escopo, você evitará esses problemas.
Recursos adicionais
Implementando os padrões de repositório e de unidade de trabalho em um aplicativo ASP.NET MVC
https://www.asp.net/mvc/overview/older-versions/getting-started-with-ef-5-using-mvc-4/implementing-the-repository-and-unit-of-work-patterns-in-an-asp-net-mvc-applicationJonathan Allen. Estratégias de implementação para o padrão de repositório com o Entity Framework, o Dapper e o Chain
https://www.infoq.com/articles/repository-implementation-strategiesCesar de la Torre. Comparando os tempos de vida do serviço de contêiner de IoC do ASP.NET Core com os escopos de instância de contêiner de IoC do Autofac
https://devblogs.microsoft.com/cesardelatorre/comparing-asp-net-core-ioc-service-life-times-and-autofac-ioc-instance-scopes/
Mapeamento de tabela
O mapeamento de tabela identifica os dados de tabela a serem consultados e salvos no banco de dados. Você já viu como as entidades de domínio (por exemplo, um domínio de produto ou de pedido) podem ser usadas para gerar um esquema de banco de dados relacionado. O EF foi projetado rigidamente de acordo com o conceito de convenções. As convenções abordam perguntas como "Qual será o nome de uma tabela?" ou "Qual propriedade é a chave primária?" e normalmente são baseadas em nomes convencionais. Por exemplo, é comum que a chave primária seja uma propriedade que termina com Id.
Por convenção, cada entidade será configurada para ser mapeada para uma tabela com o mesmo nome que a propriedade DbSet<TEntity> que expõe a entidade no contexto derivado. Se nenhum valor de DbSet<TEntity> for fornecido para a entidade especificada, o nome da classe será usado.
Anotações de dados em comparação com a API fluente
Existem muitas convenções do EF Core adicionais e a maioria delas pode ser alterada usando anotações de dados ou a API fluente, implementada no método OnModelCreating.
As anotações de dados devem ser usadas nas próprias classes de modelo de entidade, o que é uma maneira mais invasiva do ponto de vista de DDD. Isso ocorre porque você está contaminando o modelo com anotações de dados relacionadas ao banco de dados de infraestrutura. Por outro lado, a API fluente é uma maneira conveniente de alterar a maioria das convenções e dos mapeamentos dentro da camada de infraestrutura de persistência de dados, para que o modelo de entidade fique limpo e desacoplado da infraestrutura de persistência.
API fluente e o método OnModelCreating
Conforme mencionado, para alterar as convenções e os mapeamentos, você pode usar o método OnModelCreating na classe DbContext.
O microsserviço de pedidos no eShopOnContainers implementa o mapeamento e configuração explícitos, quando necessário, conforme é mostrado no código a seguir.
// At OrderingContext.cs from eShopOnContainers
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
// ...
modelBuilder.ApplyConfiguration(new OrderEntityTypeConfiguration());
// Other entities' configuration ...
}
// At OrderEntityTypeConfiguration.cs from eShopOnContainers
class OrderEntityTypeConfiguration : IEntityTypeConfiguration<Order>
{
public void Configure(EntityTypeBuilder<Order> orderConfiguration)
{
orderConfiguration.ToTable("orders", OrderingContext.DEFAULT_SCHEMA);
orderConfiguration.HasKey(o => o.Id);
orderConfiguration.Ignore(b => b.DomainEvents);
orderConfiguration.Property(o => o.Id)
.UseHiLo("orderseq", OrderingContext.DEFAULT_SCHEMA);
//Address value object persisted as owned entity type supported since EF Core 2.0
orderConfiguration
.OwnsOne(o => o.Address, a =>
{
a.WithOwner();
});
orderConfiguration
.Property<int?>("_buyerId")
.UsePropertyAccessMode(PropertyAccessMode.Field)
.HasColumnName("BuyerId")
.IsRequired(false);
orderConfiguration
.Property<DateTime>("_orderDate")
.UsePropertyAccessMode(PropertyAccessMode.Field)
.HasColumnName("OrderDate")
.IsRequired();
orderConfiguration
.Property<int>("_orderStatusId")
.UsePropertyAccessMode(PropertyAccessMode.Field)
.HasColumnName("OrderStatusId")
.IsRequired();
orderConfiguration
.Property<int?>("_paymentMethodId")
.UsePropertyAccessMode(PropertyAccessMode.Field)
.HasColumnName("PaymentMethodId")
.IsRequired(false);
orderConfiguration.Property<string>("Description").IsRequired(false);
var navigation = orderConfiguration.Metadata.FindNavigation(nameof(Order.OrderItems));
// DDD Patterns comment:
//Set as field (New since EF 1.1) to access the OrderItem collection property through its field
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
orderConfiguration.HasOne<PaymentMethod>()
.WithMany()
.HasForeignKey("_paymentMethodId")
.IsRequired(false)
.OnDelete(DeleteBehavior.Restrict);
orderConfiguration.HasOne<Buyer>()
.WithMany()
.IsRequired(false)
.HasForeignKey("_buyerId");
orderConfiguration.HasOne(o => o.OrderStatus)
.WithMany()
.HasForeignKey("_orderStatusId");
}
}
Você pode definir todos os mapeamentos de API do Fluent no mesmo método OnModelCreating, mas é aconselhável particionar esse código e ter várias classes de configuração, uma por entidade, como é mostrado no exemplo. Principalmente para modelos grandes, é aconselhável ter classes de configuração separadas para configurar diferentes tipos de entidade.
O código no exemplo mostra algumas declarações e mapeamentos explícitos. No entanto, as convenções do EF Core fazem muitos desses mapeamentos automaticamente, portanto, o código real necessário para o seu caso poderá ser menor.
O algoritmo Hi/Lo no EF Core
Um aspecto interessante de código no exemplo anterior é que ele usa o algoritmo Hi/Lo como a estratégia de geração de chave.
O algoritmo Hi/Lo é útil quando você precisa de chaves exclusivas antes de confirmar as alterações. Em resumo, o algoritmo Hi-Lo atribui identificadores exclusivos às linhas da tabela, embora ele não dependa de armazenar a linha no banco de dados imediatamente. Isso permite começar a usar os identificadores imediatamente, como acontece com as IDs de banco de dados sequenciais regulares.
O algoritmo Hi/Lo descreve um mecanismo para obter um lote de IDs exclusivas de uma sequência de banco de dados relacionado. Essas IDs são seguras usar porque o banco de dados garante a exclusividade, portanto, não haverá nenhuma colisão entre usuários. Esse algoritmo é interessante por estes motivos:
Ele não interrompe o padrão de unidade de trabalho.
Ele obtém as IDs da sequência em lotes, para minimizar as viagens de ida e para o banco de dados.
Ele gera um identificador legível por pessoas, ao contrário das técnicas que usam GUIDs.
O EF Core dá suporte ao HiLo com o método UseHiLo, conforme mostrado no exemplo anterior.
Mapear campos em vez de propriedades
Com esse recurso, disponível desde o EF Core 1.1, você pode mapear colunas para campos diretamente. É possível não usar as propriedades na classe de entidade e apenas mapear as colunas de uma tabela para os campos. Um caso de uso comum para isso seria os campos privados de algum estado interno que não precisam ser acessados de fora da entidade.
Você pode fazer isso com campos únicos ou também com coleções, como um campo List<>. Esse ponto já foi mencionado quando discutimos a modelagem das classes de modelo de domínio, mas aqui você pode ver como esse mapeamento é realizado com a configuração PropertyAccessMode.Field realçada no código anterior.
Usar propriedades de sombra no EF Core, ocultas no nível da infraestrutura
As propriedades de sombra no EF Core são propriedades que não existem no modelo de classe de entidade. Os valores e os estados dessas propriedades são mantidos unicamente na classe ChangeTracker no nível da infraestrutura.
Implementar o padrão de especificação de consulta
Conforme já foi apresentado na seção sobre design, o padrão de especificação de consulta é um padrão de design orientado por domínio projetado para ser o local em que você pode colocar a definição de uma consulta com uma lógica opcional de classificação e paginação.
O padrão de especificação de consulta define uma consulta em um objeto. Por exemplo, para encapsular uma consulta paginada que procura por alguns produtos, você poderia criar uma especificação PagedProduct que usasse os parâmetros de entrada necessários (pageNumber, pageSize, filtro, etc.). Então, qualquer método de repositório [geralmente uma sobrecarga List()] aceitaria uma IQuerySpecification e executaria a consulta esperada com base nessa especificação.
Um exemplo de interface de especificação genérica é o código a seguir, que é semelhante ao código usado no aplicativo de referência eShopOnWeb.
// GENERIC SPECIFICATION INTERFACE
// https://github.com/dotnet-architecture/eShopOnWeb
public interface ISpecification<T>
{
Expression<Func<T, bool>> Criteria { get; }
List<Expression<Func<T, object>>> Includes { get; }
List<string> IncludeStrings { get; }
}
Assim, a implementação de uma classe base de especificação genérica seria a seguinte.
// GENERIC SPECIFICATION IMPLEMENTATION (BASE CLASS)
// https://github.com/dotnet-architecture/eShopOnWeb
public abstract class BaseSpecification<T> : ISpecification<T>
{
public BaseSpecification(Expression<Func<T, bool>> criteria)
{
Criteria = criteria;
}
public Expression<Func<T, bool>> Criteria { get; }
public List<Expression<Func<T, object>>> Includes { get; } =
new List<Expression<Func<T, object>>>();
public List<string> IncludeStrings { get; } = new List<string>();
protected virtual void AddInclude(Expression<Func<T, object>> includeExpression)
{
Includes.Add(includeExpression);
}
// string-based includes allow for including children of children
// e.g. Basket.Items.Product
protected virtual void AddInclude(string includeString)
{
IncludeStrings.Add(includeString);
}
}
A seguinte especificação carrega uma só entidade de cesta de acordo com a ID da cesta ou com a ID do comprador ao qual a cesta pertence. Ela fará o carregamento adiantado da cesta Items.
// SAMPLE QUERY SPECIFICATION IMPLEMENTATION
public class BasketWithItemsSpecification : BaseSpecification<Basket>
{
public BasketWithItemsSpecification(int basketId)
: base(b => b.Id == basketId)
{
AddInclude(b => b.Items);
}
public BasketWithItemsSpecification(string buyerId)
: base(b => b.BuyerId == buyerId)
{
AddInclude(b => b.Items);
}
}
E, finalmente, veja abaixo como um repositório do EF genérico pode usar uma especificação desse tipo para filtrar e fazer o carregamento adiantado dos dados relacionados a um determinado tipo de entidade T.
// GENERIC EF REPOSITORY WITH SPECIFICATION
// https://github.com/dotnet-architecture/eShopOnWeb
public IEnumerable<T> List(ISpecification<T> spec)
{
// fetch a Queryable that includes all expression-based includes
var queryableResultWithIncludes = spec.Includes
.Aggregate(_dbContext.Set<T>().AsQueryable(),
(current, include) => current.Include(include));
// modify the IQueryable to include any string-based include statements
var secondaryResult = spec.IncludeStrings
.Aggregate(queryableResultWithIncludes,
(current, include) => current.Include(include));
// return the result of the query using the specification's criteria expression
return secondaryResult
.Where(spec.Criteria)
.AsEnumerable();
}
Além de encapsular a lógica de filtragem, a especificação pode especificar a forma dos dados a serem retornados, incluindo quais propriedades devem ser populadas.
Embora não seja recomendado retornar IQueryable de um repositório, é perfeitamente normal usá-lo no repositório para criar um conjunto de resultados. Veja esta abordagem usada no método List acima, que usa expressões IQueryable intermediárias para criar a lista de inclusões da consulta antes de executar a consulta com os critérios da especificação na última linha.
Saiba como o padrão de especificação é aplicado no exemplo eShopOnWeb.
Recursos adicionais
Mapeamento de Tabela
https://learn.microsoft.com/ef/core/modeling/relational/tablesUsar HiLo para gerar chaves com o Entity Framework Core
https://www.talkingdotnet.com/use-hilo-to-generate-keys-with-entity-framework-core/Campos de Backup
https://learn.microsoft.com/ef/core/modeling/backing-fieldSteve Smith. Coleções encapsuladas no Entity Framework Core
https://ardalis.com/encapsulated-collections-in-entity-framework-corePropriedades de Sombra
https://learn.microsoft.com/ef/core/modeling/shadow-propertiesO padrão de especificação
https://deviq.com/specification-pattern/Pacote NuGet Ardalis.Specification Usado pelo eShopOnWeb. \ https://www.nuget.org/packages/Ardalis.Specification