Instruções passo a passo: multiplicação de matrizes
Este passo a passo demonstra como usar C++ AMP para acelerar a execução da multiplicação de matriz. Dois algoritmos são apresentados, um sem blocos e outro com blocos.
Pré-requisitos
Antes de começar:
- Leia Visão Geral do C++ AMP.
- Leia Usando blocos.
- Verifique se você está executando pelo menos o Windows 7 ou o Windows Server 2008 R2.
Observação
Os cabeçalhos C++ AMP foram preteridos a partir do Visual Studio 2022 versão 17.0.
Incluir todos os cabeçalhos AMP gerará erros de build. Defina _SILENCE_AMP_DEPRECATION_WARNINGS antes de incluir qualquer cabeçalho AMP para silenciar os avisos.
Para criar o projeto
As instruções para criar um novo projeto variam dependendo da versão do Visual Studio instalada. Para ver a documentação da sua versão preferencial do Visual Studio, use o controle seletor de Versão. Ele é encontrado na parte superior da tabela de conteúdo nesta página.
Para criar o projeto no Visual Studio:
Na barra de menus, escolha Arquivo>Novo>Projeto para abrir a caixa de diálogo Criar um projeto.
Na parte superior da caixa de diálogo, defina Linguagem como C++, Plataforma como Windows e Tipo de projeto como Console.
Na lista filtrada de tipos de projeto, escolha Projeto Vazio e, em seguida, escolha Avançar. Na próxima página, insira MatrixMultiply no Nome para especificar um nome para o projeto e, se quiser, especificar o local do projeto, se desejado.
Escolha o botão Criar para criar o projeto do cliente.
No Gerenciador de Soluções, abra o menu de atalho da Arquivos de Origem e, em seguida, escolha Adicionar>Novo Item.
Na caixa de diálogo Adicionar Novo Item, selecione Arquivo C++ (.cpp), insira MatrixMultiply.cpp na caixa Nome e escolha o botão Adicionar.
Para criar um projeto no Visual Studio 2017 ou 2015
Na barra de menus no Visual Studio, escolha Arquivo>Novo>Projeto.
Em Instalado no painel modelos, selecione Visual C++.
Selecione Projeto Vazio, insira MatrixMultiply na caixa Nome e escolha o botão OK.
Escolha o botão Avançar.
No Gerenciador de Soluções, abra o menu de atalho da Arquivos de Origem e, em seguida, escolha Adicionar>Novo Item.
Na caixa de diálogo Adicionar Novo Item, selecione Arquivo C++ (.cpp), insira MatrixMultiply.cpp na caixa Nome e escolha o botão Adicionar.
Multiplicação sem blocos
Nesta seção, considere a multiplicação de duas matrizes, A e B, que são definidas da seguinte maneira:
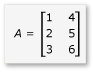

A é uma matriz de 3 por 2 e B é uma matriz 2 por 3. O produto da multiplicação de A por B é a seguinte matriz de 3 por 3. O produto é calculado multiplicando as linhas de A pelas colunas do elemento B por elemento.

Para multiplicar sem usar C++ AMP
Abra MatrixMultiply.cpp e use o código a seguir para substituir o código existente.
#include <iostream> void MultiplyWithOutAMP() { int aMatrix[3][2] = {{1, 4}, {2, 5}, {3, 6}}; int bMatrix[2][3] = {{7, 8, 9}, {10, 11, 12}}; int product[3][3] = {{0, 0, 0}, {0, 0, 0}, {0, 0, 0}}; for (int row = 0; row < 3; row++) { for (int col = 0; col < 3; col++) { // Multiply the row of A by the column of B to get the row, column of product. for (int inner = 0; inner < 2; inner++) { product[row][col] += aMatrix[row][inner] * bMatrix[inner][col]; } std::cout << product[row][col] << " "; } std::cout << "\n"; } } int main() { MultiplyWithOutAMP(); getchar(); }O algoritmo é uma implementação simples da definição de multiplicação de matriz. Ele não usa algoritmos paralelos ou com thread para reduzir o tempo de computação.
Na barra de menus, escolha Arquivo>Salvar Todos.
Escolha o atalho de teclado F5 para iniciar a depuração e verifique se a saída está correta.
Escolha Enter para sair do aplicativo.
Para multiplicar usando C++ AMP
Em MatrixMultiply.cpp, adicione o código a seguir antes do método
main.void MultiplyWithAMP() { int aMatrix[] = { 1, 4, 2, 5, 3, 6 }; int bMatrix[] = { 7, 8, 9, 10, 11, 12 }; int productMatrix[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0 }; array_view<int, 2> a(3, 2, aMatrix); array_view<int, 2> b(2, 3, bMatrix); array_view<int, 2> product(3, 3, productMatrix); parallel_for_each(product.extent, [=] (index<2> idx) restrict(amp) { int row = idx[0]; int col = idx[1]; for (int inner = 0; inner <2; inner++) { product[idx] += a(row, inner)* b(inner, col); } }); product.synchronize(); for (int row = 0; row <3; row++) { for (int col = 0; col <3; col++) { //std::cout << productMatrix[row*3 + col] << " "; std::cout << product(row, col) << " "; } std::cout << "\n"; } }O código AMP é semelhante ao código não AMP. A chamada para
parallel_for_eachinicia um thread para cada elemento noproduct.extente substitui os loopsforde linha e coluna. O valor da célula na linha e coluna está disponível emidx. Você pode acessar os elementos de um objetoarray_viewusando o operador[]e uma variável de índice ou o operador()e as variáveis de linha e coluna. O exemplo demonstra ambos os métodos. O métodoarray_view::synchronizecopia os valores da variávelproductde volta para a variávelproductMatrix.Adicione as seguintes instruções
includeeusingna parte superior de MatrixMultiply.cpp.#include <amp.h> using namespace concurrency;Modifique o método
mainpara chamar o métodoMultiplyWithAMP.int main() { MultiplyWithOutAMP(); MultiplyWithAMP(); getchar(); }Pressione o atalho de teclado Ctrl+F5 para iniciar a depuração e verifique se a saída está correta.
Pressione a barra de espaço para sair do aplicativo.
Multiplicação com blocos
O bloco é uma técnica na qual você parte dados em subconjuntos de tamanho igual, que são conhecidos como blocos. Três itens mudam quando você usa o bloco.
Você pode criar variáveis
tile_static. O acesso aos dados no espaçotile_staticpode ser muitas vezes mais rápido do que o acesso aos dados no espaço global. Uma instância de uma variáveltile_staticé criada para cada bloco e todos os threads no bloco têm acesso à variável. O principal benefício do bloco é o ganho de desempenho devido ao acessotile_static.Você pode chamar o método tile_barrier::wait para interromper todos os threads em um bloco em uma linha de código especificada. Você não pode garantir a ordem em que os threads serão executados, somente que todos os threads em um bloco serão interrompidos na chamada antes que
tile_barrier::waitcontinuem em execução.Você tem acesso ao índice do thread em relação ao objeto inteiro
array_viewe ao índice relativo ao bloco. Usando o índice local, você pode facilitar a leitura e a depuração do código.
Para aproveitar o bloco na multiplicação de matriz, o algoritmo deve particionar a matriz em blocos e copiar os dados do bloco em variáveis tile_static para acesso mais rápido. Neste exemplo, a matriz é particionada em submatrizes de tamanho igual. O produto é encontrado multiplicando as submatrizes. As duas matrizes e seu produto neste exemplo são:
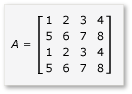
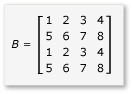
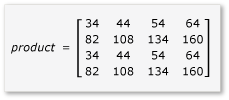
As matrizes são particionadas em quatro matrizes 2x2, que são definidas da seguinte maneira:


O produto de A e B agora pode ser gravado e calculado da seguinte forma:
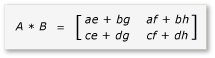
Como as matrizes a até h são matrizes 2x2, todos os produtos e somas deles também são matrizes 2x2. Ele também diz que o produto de A e B é uma matriz 4x4, conforme esperado. Para verificar rapidamente o algoritmo, calcule o valor do elemento na primeira linha, primeira coluna do produto. No exemplo, esse seria o valor do elemento na primeira linha e na primeira coluna de ae + bg. Você só precisa calcular a primeira coluna, a primeira linha de ae e bg para cada termo. Esse valor para ae é (1 * 1) + (2 * 5) = 11. O valor para bg é (3 * 1) + (4 * 5) = 23. O valor final é 11 + 23 = 34, o que está correto.
Para implementar esse algoritmo, o código:
Usa um objeto
tiled_extentem vez de um objetoextentna chamadaparallel_for_each.Usa um objeto
tiled_indexem vez de um objetoindexna chamadaparallel_for_each.Cria variáveis
tile_staticpara manter as submatrizes.Usa o método
tile_barrier::waitpara interromper os threads para o cálculo dos produtos das submatrizes.
Para multiplicar usando AMP e blocos
Em MatrixMultiply.cpp, adicione o código a seguir antes do método
main.void MultiplyWithTiling() { // The tile size is 2. static const int TS = 2; // The raw data. int aMatrix[] = { 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8 }; int bMatrix[] = { 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8 }; int productMatrix[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 }; // Create the array_view objects. array_view<int, 2> a(4, 4, aMatrix); array_view<int, 2> b(4, 4, bMatrix); array_view<int, 2> product(4, 4, productMatrix); // Call parallel_for_each by using 2x2 tiles. parallel_for_each(product.extent.tile<TS, TS>(), [=] (tiled_index<TS, TS> t_idx) restrict(amp) { // Get the location of the thread relative to the tile (row, col) // and the entire array_view (rowGlobal, colGlobal). int row = t_idx.local[0]; int col = t_idx.local[1]; int rowGlobal = t_idx.global[0]; int colGlobal = t_idx.global[1]; int sum = 0; // Given a 4x4 matrix and a 2x2 tile size, this loop executes twice for each thread. // For the first tile and the first loop, it copies a into locA and e into locB. // For the first tile and the second loop, it copies b into locA and g into locB. for (int i = 0; i < 4; i += TS) { tile_static int locA[TS][TS]; tile_static int locB[TS][TS]; locA[row][col] = a(rowGlobal, col + i); locB[row][col] = b(row + i, colGlobal); // The threads in the tile all wait here until locA and locB are filled. t_idx.barrier.wait(); // Return the product for the thread. The sum is retained across // both iterations of the loop, in effect adding the two products // together, for example, a*e. for (int k = 0; k < TS; k++) { sum += locA[row][k] * locB[k][col]; } // All threads must wait until the sums are calculated. If any threads // moved ahead, the values in locA and locB would change. t_idx.barrier.wait(); // Now go on to the next iteration of the loop. } // After both iterations of the loop, copy the sum to the product variable by using the global location. product[t_idx.global] = sum; }); // Copy the contents of product back to the productMatrix variable. product.synchronize(); for (int row = 0; row <4; row++) { for (int col = 0; col <4; col++) { // The results are available from both the product and productMatrix variables. //std::cout << productMatrix[row*3 + col] << " "; std::cout << product(row, col) << " "; } std::cout << "\n"; } }Este exemplo é significativamente diferente do exemplo sem blocos. O código usa estas etapas conceituais:
Copie os elementos do bloco [0,0] de
aemlocA. Copie os elementos do bloco [0,0] debemlocB. Observe queproductestá em bloco, nãoaeb. Portanto, você usa índices globais para acessara, beproduct. A chamada paratile_barrier::waité essencial. Ele interrompe todos os threads no bloco até que amboslocAelocBsejam preenchidos.Multiplique
locAelocBe coloque os resultados emproduct.Copie os elementos do bloco [0,1] de
aemlocA. Copie os elementos do bloco [1,0] debemlocB.Multiplique
locAelocBadicione-os aos resultados que já estão emproduct.A multiplicação do bloco[0,0] está concluída.
Repita para os outros quatro blocos. Não há indexação especificamente para os blocos e os threads podem ser executados em qualquer ordem. À medida que cada thread é executado, as variáveis
tile_staticsão criadas para cada bloco adequadamente e a chamada paratile_barrier::waitcontrola o fluxo do programa.Ao examinar o algoritmo de perto, observe que cada submatriz é carregada em uma memória
tile_staticduas vezes. Essa transferência de dados leva tempo. No entanto, depois que os dados estiverem na memóriatile_static, o acesso aos dados será muito mais rápido. Como calcular os produtos requer acesso repetido aos valores nas submatrizes, há um ganho geral de desempenho. Para cada algoritmo, a experimentação é necessária para localizar o algoritmo ideal e o tamanho do bloco.
Nos exemplos não AMP e não bloco, cada elemento de A e B é acessado quatro vezes da memória global para calcular o produto. No exemplo de bloco, cada elemento é acessado duas vezes da memória global e quatro vezes da memória
tile_static. Esse não é um ganho de desempenho significativo. No entanto, se A e B fossem 1024x1024 matrizes e o tamanho do bloco fosse 16, haveria um ganho de desempenho significativo. Nesse caso, cada elemento seria copiado na memóriatile_staticapenas 16 vezes e acessado da memóriatile_static1024 vezes.Modifique o método principal para chamar o método
MultiplyWithTilingconforme mostrado.int main() { MultiplyWithOutAMP(); MultiplyWithAMP(); MultiplyWithTiling(); getchar(); }Pressione o atalho de teclado Ctrl+F5 para iniciar a depuração e verifique se a saída está correta.
Pressione a barra de espaço para sair do aplicativo.
Confira também
C++ AMP (C++ Accelerated Massive Parallelism)
Passo a passo: depurando um aplicativo C++ AMP