Recomendações para resposta a incidentes de segurança
Aplica-se à recomendação da lista de verificação do Azure Well-Architected Framework Security:
| SE:12 | Defina e teste procedimentos eficazes de resposta a incidentes que abranjam um espectro de incidentes, desde problemas localizados até recuperação de desastres. Defina claramente qual equipe ou indivíduo executa um procedimento. |
|---|
Este guia descreve as recomendações para implementar uma resposta a incidentes de segurança para uma carga de trabalho. Se houver um comprometimento de segurança em um sistema, uma abordagem sistemática de resposta a incidentes ajuda a reduzir o tempo necessário para identificar, gerenciar e mitigar incidentes de segurança. Esses incidentes podem ameaçar a confidencialidade, integridade e disponibilidade de sistemas e dados de software.
A maioria das empresas tem uma equipe central de operações de segurança (também conhecida como Centro de Operações de Segurança (SOC) ou SecOps). A responsabilidade da equipe de operação de segurança é detectar, priorizar e fazer a triagem rapidamente de possíveis ataques. A equipe também monitora dados de telemetria relacionados à segurança e investiga violações de segurança.
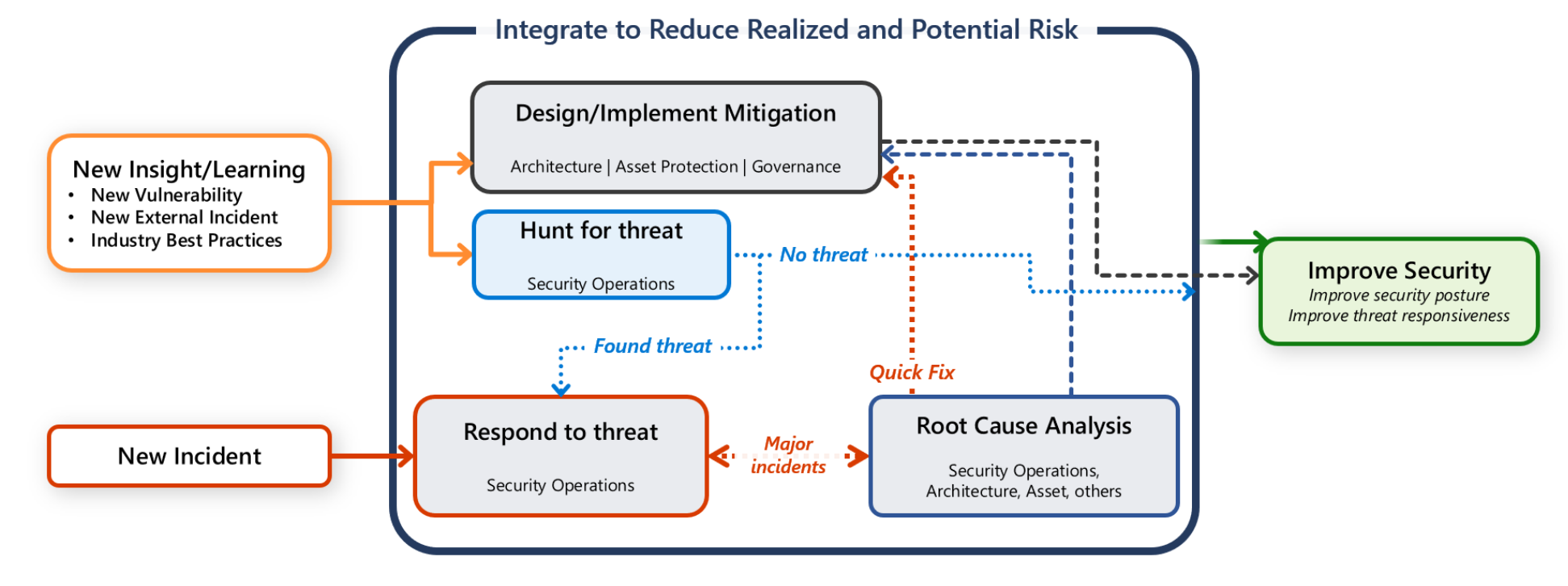
No entanto, você também tem a responsabilidade de proteger sua carga de trabalho. É importante que todas as atividades de comunicação, investigação e busca sejam um esforço colaborativo entre a equipe de carga de trabalho e a equipe de SecOps.
Este guia fornece recomendações para você e sua equipe de carga de trabalho para ajudá-lo a detectar, fazer a triagem e investigar ataques rapidamente.
Definições
| Termo | Definição |
|---|---|
| Alerta | Uma notificação que contém informações sobre um incidente. |
| Fidelidade de alerta | A precisão dos dados que determinam um alerta. Os alertas de alta fidelidade contêm o contexto de segurança necessário para executar ações imediatas. Alertas de baixa fidelidade carecem de informações ou contêm ruído. |
| Falso positivo | Um alerta que indica um incidente que não aconteceu. |
| Incident | Um evento que indica acesso não autorizado a um sistema. |
| Resposta a incidente | Um processo que detecta, responde e mitiga os riscos associados a um incidente. |
| Triagem | Uma operação de resposta a incidentes que analisa problemas de segurança e prioriza sua mitigação. |
Principais estratégias de design
Você e sua equipe executam operações de resposta a incidentes quando há um sinal ou alerta para um possível comprometimento. Os alertas de alta fidelidade contêm amplo contexto de segurança que facilita a tomada de decisões pelos analistas. Alertas de alta fidelidade resultam em um baixo número de falsos positivos. Este guia pressupõe que um sistema de alerta filtre sinais de baixa fidelidade e se concentre em alertas de alta fidelidade que podem indicar um incidente real.
Designar contatos de notificação de incidentes
Os alertas de segurança precisam chegar às pessoas apropriadas em sua equipe e em sua organização. Estabeleça um ponto de contato designado em sua equipe de carga de trabalho para receber notificações de incidentes. Essas notificações devem incluir o máximo de informações possível sobre o recurso comprometido e o sistema. O alerta deve incluir as próximas etapas, para que sua equipe possa agilizar as ações.
Recomendamos que você registre e gerencie notificações e ações de incidentes usando ferramentas especializadas que mantêm uma trilha de auditoria. Usando ferramentas padrão, você pode preservar evidências que podem ser necessárias para possíveis investigações legais. Procure oportunidades para implementar a automação que possa enviar notificações com base nas responsabilidades das partes responsáveis. Mantenha uma cadeia clara de comunicação e relatórios durante um incidente.
Aproveite as soluções de gerenciamento de eventos de informações de segurança (SIEM) e as soluções de resposta automatizada de orquestração de segurança (SOAR) que sua organização fornece. Como alternativa, você pode adquirir ferramentas de gerenciamento de incidentes e incentivar sua organização a padronizá-las para todas as equipes de carga de trabalho.
Investigue com uma equipe de triagem
O membro da equipe que recebe uma notificação de incidente é responsável por configurar um processo de triagem que envolve as pessoas apropriadas com base nos dados disponíveis. A equipe de triagem, muitas vezes chamada de equipe de ponte, deve concordar com o modo e o processo de comunicação. Este incidente requer discussões assíncronas ou chamadas de ponte? Como a equipe deve acompanhar e comunicar o andamento das investigações? Onde a equipe pode acessar os ativos de incidentes?
A resposta a incidentes é um motivo crucial para manter a documentação atualizada, como o layout arquitetônico do sistema, informações em um nível de componente, classificação de privacidade ou segurança, proprietários e principais pontos de contato. Se as informações forem imprecisas ou desatualizadas, a equipe da ponte perde um tempo valioso tentando entender como o sistema funciona, quem é responsável por cada área e qual pode ser o efeito do evento.
Para investigações adicionais, envolva as pessoas apropriadas. Você pode incluir um gerente de incidentes, um oficial de segurança ou leads centrados na carga de trabalho. Para manter a triagem focada, exclua as pessoas que estão fora do escopo do problema. Às vezes, equipes separadas investigam o incidente. Pode haver uma equipe que inicialmente investiga o problema e tenta mitigar o incidente, e outra equipe especializada que pode realizar perícia para uma investigação profunda para verificar problemas amplos. Você pode colocar em quarentena o ambiente de carga de trabalho para permitir que a equipe forense faça suas investigações. Em alguns casos, a mesma equipe pode lidar com toda a investigação.
Na fase inicial, a equipe de triagem é responsável por determinar o vetor potencial e seu efeito na confidencialidade, integridade e disponibilidade (também chamada de CIA) do sistema.
Dentro das categorias de CIA, atribua um nível de gravidade inicial que indique a profundidade do dano e a urgência da correção. Espera-se que esse nível mude com o tempo, à medida que mais informações forem descobertas nos níveis de triagem.
Na fase de descoberta, é importante determinar um curso de ação imediato e planos de comunicação. Há alguma alteração no estado de execução do sistema? Como o ataque pode ser contido para impedir mais exploração? A equipe precisa enviar comunicação interna ou externa, como uma divulgação responsável? Considere o tempo de detecção e resposta. Você pode ser legalmente obrigado a relatar alguns tipos de violações a uma autoridade reguladora dentro de um período de tempo específico, que geralmente é de horas ou dias.
Se você decidir desligar o sistema, as próximas etapas levarão ao processo de recuperação de desastre (DR) da carga de trabalho.
Se você não desligar o sistema, determine como corrigir o incidente sem afetar a funcionalidade do sistema.
Recuperar-se de um incidente
Trate um incidente de segurança como um desastre. Se a correção exigir recuperação completa, use mecanismos de DR adequados de uma perspectiva de segurança. O processo de recuperação deve evitar chances de recorrência. Caso contrário, a recuperação de um backup corrompido reintroduz o problema. A reimplantação de um sistema com a mesma vulnerabilidade leva ao mesmo incidente. Valide as etapas e processos de failover e failback.
Se o sistema permanecer funcionando, avalie o efeito nas partes em execução do sistema. Continue monitorando o sistema para garantir que outras metas de confiabilidade e desempenho sejam atendidas ou reajustadas pela implementação de processos de degradação adequados. Não comprometa a privacidade devido à mitigação.
O diagnóstico é um processo interativo até que o vetor e uma possível correção e fallback sejam identificados. Após o diagnóstico, a equipe trabalha na remediação, que identifica e aplica a correção necessária dentro de um período aceitável.
As métricas de recuperação medem quanto tempo leva para corrigir um problema. No caso de um desligamento, pode haver uma urgência em relação aos tempos de correção. Para estabilizar o sistema, leva tempo para aplicar correções, patches e testes e implantar atualizações. Determine estratégias de contenção para evitar mais danos e a propagação do incidente. Desenvolver procedimentos de erradicação para remover completamente a ameaça do ambiente.
Compensação: há uma compensação entre metas de confiabilidade e tempos de correção. Durante um incidente, é provável que você não atenda a outros requisitos não funcionais ou funcionais. Por exemplo, talvez seja necessário desabilitar partes do sistema enquanto investiga o incidente ou até mesmo colocar todo o sistema offline até determinar o escopo do incidente. Os tomadores de decisão de negócios precisam decidir explicitamente quais são os alvos aceitáveis durante o incidente. Especifique claramente a pessoa responsável por essa decisão.
Aprenda com um incidente
Um incidente revela lacunas ou pontos vulneráveis em um projeto ou implementação. É uma oportunidade de melhoria impulsionada por lições sobre aspectos técnicos de design, automação, processos de desenvolvimento de produtos que incluem testes e a eficácia do processo de resposta a incidentes. Mantenha registros detalhados de incidentes, incluindo ações tomadas, cronogramas e descobertas.
É altamente recomendável que você conduza revisões estruturadas pós-incidente, como análise de causa raiz e retrospectivas. Acompanhe e priorize o resultado dessas revisões e considere usar o que você aprendeu em projetos de carga de trabalho futuros.
Os planos de melhoria devem incluir atualizações para simulações e testes de segurança, como simulações de BCDR (continuidade dos negócios e recuperação de desastres). Use o comprometimento de segurança como um cenário para executar uma análise de BCDR. Os drills podem validar como os processos documentados funcionam. Não deve haver vários manuais de resposta a incidentes. Use uma única fonte que você possa ajustar com base no tamanho do incidente e na extensão ou localização do efeito. Os exercícios são baseados em situações hipotéticas. Realize exercícios em um ambiente de baixo risco e inclua a fase de aprendizado nos exercícios.
Realize revisões pós-incidentes, ou post-mortems, para identificar pontos fracos no processo de resposta e áreas de melhoria. Com base nas lições aprendidas com o incidente, atualize o IRP (plano de resposta a incidentes) e os controles de segurança.
Definir um plano de comunicação
Implemente um plano de comunicação para notificar os usuários sobre uma interrupção e informar as partes interessadas internas sobre a correção e as melhorias. Outras pessoas em sua organização precisam ser notificadas sobre quaisquer alterações na linha de base de segurança da carga de trabalho para evitar incidentes futuros.
Gere relatórios de incidentes para uso interno e, se necessário, para conformidade regulatória ou fins legais. Além disso, adote um relatório de formato padrão (um modelo de documento com seções definidas) que a equipe do SOC usa para todos os incidentes. Certifique-se de que cada incidente tenha um relatório associado a ele antes de encerrar a investigação.
Facilitação do Azure
O Microsoft Sentinel é uma solução SIEM e SOAR. É uma solução única para detecção de alertas, visibilidade de ameaças, busca proativa e resposta a ameaças. Para obter mais informações, consulte O que é o Microsoft Sentinel?
Verifique se o portal de registro do Azure inclui informações de contato do administrador para que as operações de segurança possam ser notificadas diretamente por meio de um processo interno. Para obter mais informações, consulte Atualizar configurações de notificação.
Para saber mais sobre como estabelecer um ponto de contato designado que recebe notificações de incidentes do Azure do Microsoft Defender para Nuvem, consulte Configurar notificações por email para alertas de segurança.
Alinhamento da organização
O Cloud Adoption Framework para Azure fornece diretrizes sobre o planejamento de resposta a incidentes e operações de segurança. Para obter mais informações, consulte Operações de segurança.
Links relacionados
- Crie incidentes automaticamente com base em alertas de segurança da Microsoft
- Realize a busca de ameaças de ponta a ponta usando o recurso de busca
- Configurar notificações por e-mail para alertas de segurança
- Visão geral da resposta a incidentes
- Preparação para incidentes do Microsoft Azure
- Navegar e investigar incidentes no Microsoft Sentinel
- Controle de segurança: resposta a incidentes
- Soluções SOAR no Microsoft Sentinel
- Treinamento: Introdução à preparação para incidentes do Azure
- Atualizar as configurações de notificação do portal do Azure
- O que é um SOC?
- O que é o Microsoft Sentinel?
Lista de verificação de segurança
Consulte o conjunto completo de recomendações.