IA responsável em cargas de trabalho do Azure
O objetivo da IA responsável no design da carga de trabalho é garantir que o uso de algoritmos de IA seja justo, transparente e inclusivo. Os princípios do Well-Architected Security estão inter-relacionados com o foco na confidencialidade e integridade. Medidas de segurança devem estar em vigor para manter a privacidade do usuário, proteger os dados e salvaguardar a integridade do design, que não deve ser mal utilizado para fins não intencionais.
Nas cargas de trabalho de IA, as decisões são tomadas por modelos que geralmente usam lógica opaca. Os usuários devem confiar na funcionalidade do sistema e se sentir confiantes de que as decisões são tomadas com responsabilidade. Comportamentos antiéticos, como manipulação, toxicidade de conteúdo, violação de IP e respostas fabricadas, devem ser evitados.
Considere um caso de uso em que uma empresa de entretenimento de mídia deseja fornecer recomendações usando modelos de IA. Deixar de implementar IA responsável e segurança adequada pode levar um agente mal-intencionado a assumir o controle dos modelos. O modelo pode potencialmente recomendar conteúdo de mídia que pode levar a resultados prejudiciais. Para a organização, esse comportamento pode levar a danos à marca, ambientes inseguros e problemas legais. Portanto, manter a vigilância ética durante todo o ciclo de vida do sistema é essencial e inegociável.
As decisões éticas devem priorizar a segurança e o gerenciamento da carga de trabalho com os resultados humanos em mente. Familiarize-se com a estrutura de IA responsável da Microsoft e certifique-se de que os princípios sejam refletidos e medidos em seu design. Esta imagem mostra os principais conceitos da estrutura.
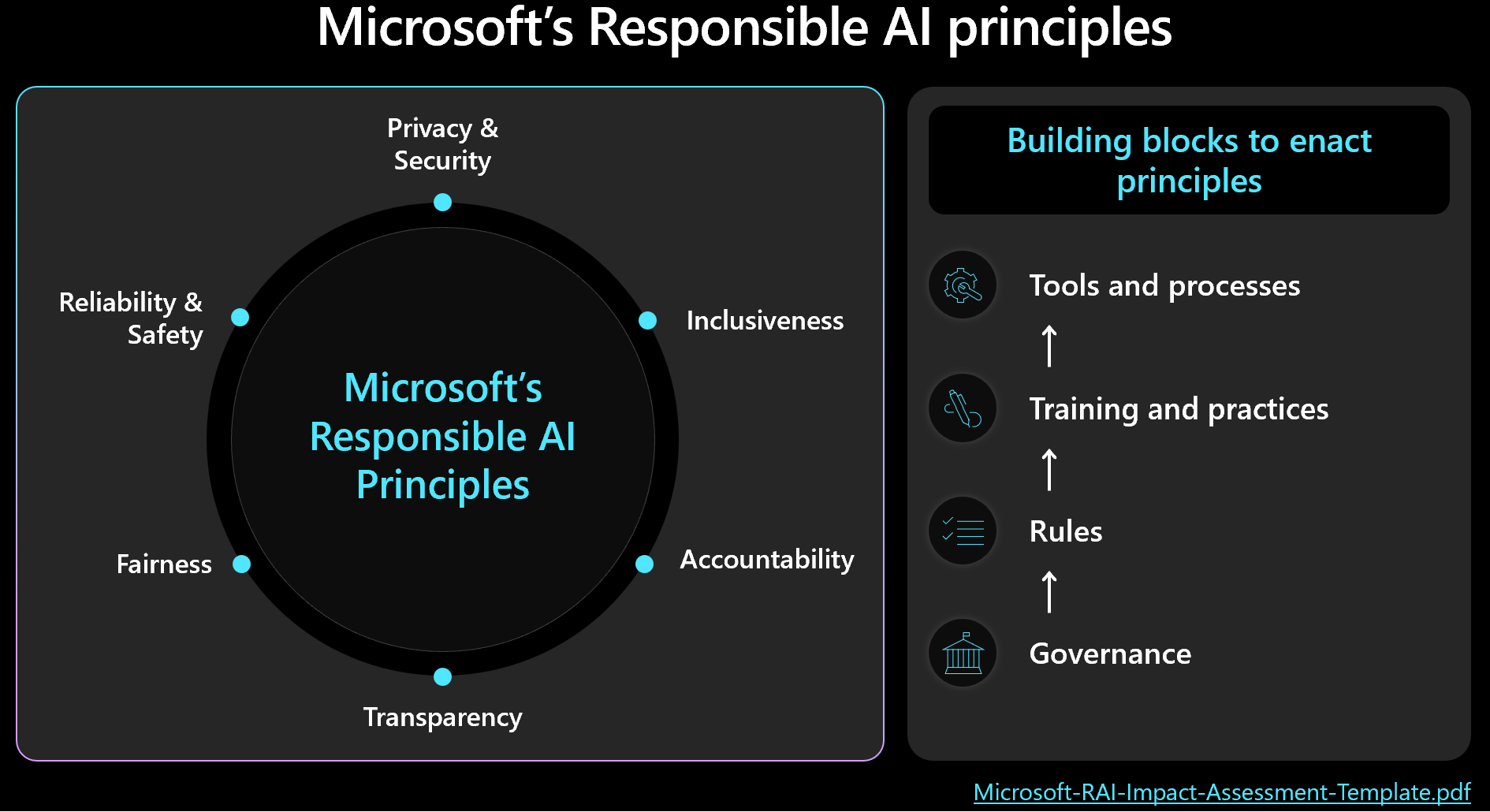
Importante
A precisão da previsão e as métricas de IA responsável geralmente estão interconectadas. Melhorar a precisão de um modelo pode aumentar sua imparcialidade e alinhamento com a realidade. No entanto, embora a IA ética frequentemente se alinhe com a precisão, a precisão por si só não inclui todas as considerações éticas. É crucial validar esses princípios éticos com responsabilidade.
Este artigo fornece recomendações sobre tomada de decisão ética, validação da entrada do usuário e garantia de uma experiência segura do usuário. Ele também fornece orientações sobre segurança de dados para garantir que os dados do usuário estejam protegidos.
Recomendações
Aqui está o resumo das recomendações fornecidas neste artigo.
| Recomendação | Descrição |
|---|---|
| Desenvolver políticas que apliquem práticas éticas em cada estágio do ciclo de vida. | Inclua itens de lista de verificação que declarem explicitamente os requisitos éticos, adaptados ao contexto da carga de trabalho. Os exemplos incluem transparência de dados do usuário, configuração de consentimento e procedimentos para lidar com o "Direito de ser esquecido". ▪ Desenvolva suas políticas de IA responsável ▪ Aplique a governança nas políticas de IA responsável |
| Proteja os dados do usuário com o objetivo de maximizar a privacidade. | Colete apenas o necessário e com o devido consentimento do usuário. Aplique controles técnicos para proteger os perfis de usuário, seus dados e o acesso a esses dados. ▪ Lidar com os dados do usuário de forma ética ▪ Inspecionar dados de entrada e saída |
| Mantenha as decisões de IA claras e compreensíveis. | Mantenha explicações claras de como os algoritmos de recomendação funcionam e ofereça aos usuários insights sobre o uso de dados e a tomada de decisões algorítmicas para garantir que eles entendam e confiem no processo. ▪ Torne a experiência do usuário segura |
Desenvolver políticas de IA responsável
Documente sua abordagem ao uso ético e responsável da IA. Declare explicitamente as políticas aplicadas em cada estágio do ciclo de vida para que a equipe de carga de trabalho entenda suas responsabilidades. Embora os padrões de IA responsável da Microsoft forneçam diretrizes, você deve definir o que eles significam especificamente para o seu contexto.
Por exemplo, as políticas devem incluir itens de lista de verificação para mecanismos de transparência de dados do usuário e configuração de consentimento, idealmente permitindo que os usuários optem por não incluir dados. Pipelines de dados, análises, treinamento de modelos e outros estágios devem respeitar essa escolha. Outro exemplo são os procedimentos para lidar com o "Direito de ser esquecido". Consulte o departamento de ética e a equipe jurídica da sua organização para tomar decisões informadas.
Crie políticas transparentes sobre o uso de dados e a tomada de decisões algorítmicas para garantir que os usuários entendam e confiem no processo. Documente essas decisões para manter um histórico claro para possíveis litígios futuros.
A implementação da IA ética envolve três funções principais: a equipe de pesquisa, a equipe de políticas e a equipe de engenharia. A colaboração entre essas equipes deve ser operacionalizada. Se sua organização já possui uma equipe, aproveite o trabalho dela; caso contrário, estabeleça você mesmo essas práticas.
Ter responsabilidades sobre a separação de funções:
A equipe de pesquisa conduz a descoberta de riscos consultando diretrizes organizacionais, padrões do setor, leis, regulamentos e táticas conhecidas da equipe vermelha.
A equipe de políticas desenvolve políticas específicas para a carga de trabalho, incorporando diretrizes da organização matriz e regulamentos governamentais.
A equipe de engenharia implementa as políticas em seus processos e entregas, garantindo que eles validem e testem a adesão.
Cada equipe formaliza suas diretrizes, mas a equipe de carga de trabalho deve ser responsável por suas próprias práticas documentadas. A equipe deve documentar claramente quaisquer etapas adicionais ou desvios intencionais, certificando-se de que não haja ambiguidade sobre o que é permitido. Além disso, seja transparente sobre possíveis deficiências ou resultados inesperados na solução.
Aplique a governança nas políticas de IA responsável
Projete sua carga de trabalho para estar em conformidade com a governança organizacional e regulatória. Por exemplo, se a transparência for um requisito organizacional, determine como ela se aplica à sua carga de trabalho. Identifique áreas em seu design, ciclo de vida, código ou outros componentes, onde os recursos de transparência devem ser introduzidos para atender a esse padrão.
Entenda a governança, a responsabilidade, os conselhos de revisão e os mandatos de relatórios necessários. Certifique-se de que os designs de carga de trabalho sejam aprovados e assinados pelo seu conselho de governança para evitar reformulações e mitigar preocupações éticas ou de privacidade. Talvez seja necessário passar por várias camadas de aprovação. Aqui está uma estrutura típica de governança.
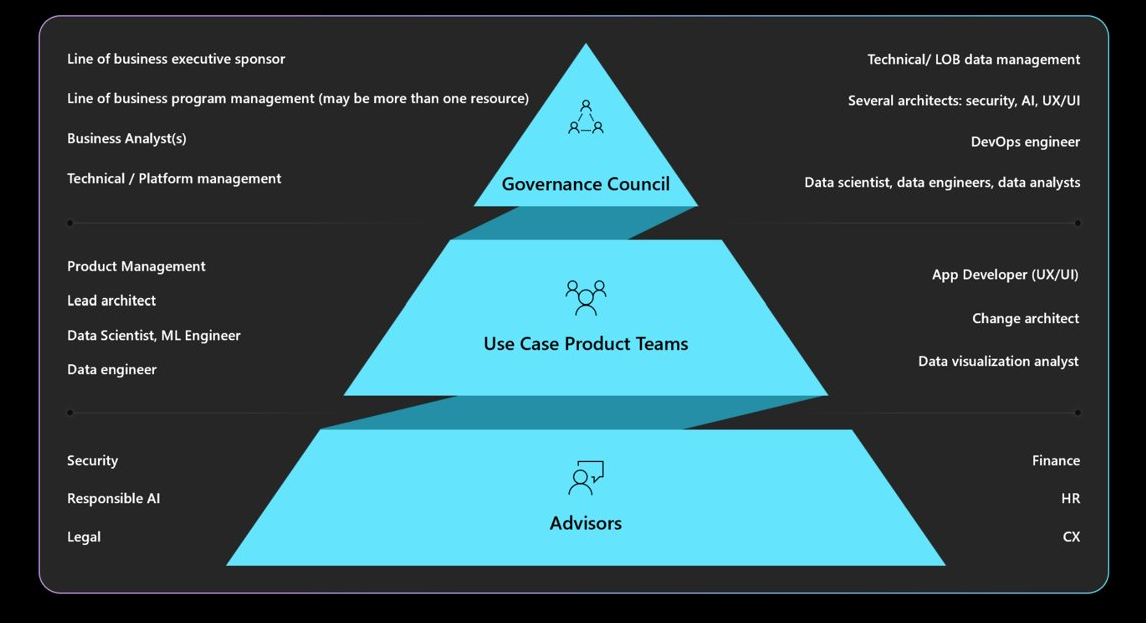
Para obter informações sobre políticas organizacionais e aprovadores, consulte Cloud Adoption Framework: definir uma estratégia de IA responsável.
Torne a experiência do usuário segura
As experiências do usuário devem ser baseadas nas diretrizes do setor. Aproveite a Biblioteca de Design de experiências de IA humana da Microsoft, que inclui princípios e fornece o que fazer e o que não fazer na implementação, com exemplos de produtos da Microsoft e outras fontes do setor.
Há responsabilidades de carga de trabalho em todo o ciclo de vida da interação do usuário, começando pela intenção do usuário de usar o sistema, durante uma sessão e interrupções devido a erros do sistema. Aqui estão algumas práticas a serem consideradas:
Crie transparência. Informe os usuários sobre como o sistema gerou a resposta à consulta.
Inclua links para fontes de dados consultadas pelo modelo para previsões para aumentar a confiança do usuário, mostrando as origens das informações. O design de dados deve garantir que essas fontes sejam incluídas nos metadados. Quando o orquestrador em um aplicativo de recuperação aumentada executa uma pesquisa, ele recupera, por exemplo, 20 partes de documentos e envia as 10 partes principais, pertencentes a três documentos diferentes, para o modelo como contexto. A interface do usuário pode fazer referência a esses três documentos de origem ao exibir a resposta do modelo, aumentando a transparência e a confiança do usuário.
A transparência torna-se mais importante ao usar agentes, que atuam como intermediários entre interfaces front-end e sistemas back-end. Por exemplo, em um sistema de tíquetes, o código de orquestração interpreta a intenção do usuário e faz chamadas de API aos agentes para recuperar as informações necessárias. Expor essas interações pode tornar o usuário ciente das ações do sistema.
Para fluxos de trabalho automatizados com vários agentes envolvidos, crie arquivos de log que registrem cada etapa. Esse recurso ajuda a identificar e corrigir erros. Além disso, pode fornecer aos usuários explicações para as decisões, o que operacionaliza a transparência.
Cuidado
Ao implementar recomendações de transparência, evite sobrecarregar o usuário com muitas informações. Use uma abordagem gradual, em que você começa com métodos de interface do usuário minimamente disruptivos.
Por exemplo, exiba uma dica de ferramenta com uma pontuação de confiança do modelo. Você pode incorporar um link no qual os usuários podem clicar para obter mais detalhes, como links para documentos de origem. Esse método iniciado pelo usuário mantém a interface do usuário sem interrupções e permite que os usuários busquem informações adicionais somente se assim o desejarem.
Colete comentários. Implemente mecanismos de feedback.
Evite sobrecarregar os usuários com questionários extensos após cada resposta. Em vez disso, use mecanismos de feedback simples e rápidos, como polegares para cima/para baixo, ou sistemas de classificação para aspectos específicos da resposta em uma escala de 1 a 5. Esse método permite feedback granular sem ser intrusivo, ajudando a melhorar o sistema ao longo do tempo. Esteja atento a possíveis vieses no feedback, pois pode haver razões secundárias por trás das respostas do usuário.
A implementação de um mecanismo de feedback afeta a arquitetura devido à necessidade de armazenamento de dados. Trate isso como dados do usuário e aplique níveis de controle de privacidade, conforme necessário.
Além do feedback de resposta, colete feedback sobre a eficácia da experiência do usuário. Isso pode ser feito coletando métricas de engajamento por meio de sua pilha de monitoramento do sistema.
Operacionalizar medidas de segurança de conteúdo
Integre a segurança de conteúdo em todos os estágios do ciclo de vida da IA usando código de solução personalizado, ferramentas apropriadas e práticas de segurança eficazes. Aqui estão algumas estratégias.
Anonimização de dados. À medida que os dados passam da ingestão para o treinamento ou avaliação, faça verificações ao longo do caminho para minimizar o risco de vazamento de informações pessoais e evitar a exposição de dados brutos do usuário.
Moderação de conteúdo. Use a API de segurança de conteúdo que avalia solicitações e respostas em tempo real e verifique se essas APIs estão acessíveis.
Identifique e mitigue ameaças. Aplique práticas de segurança bem conhecidas aos seus cenários de IA. Por exemplo, conduza a modelagem de ameaças e documente ameaças e sua mitigação. Práticas de segurança comuns, como exercícios de equipe vermelha, são aplicáveis a cargas de trabalho de IA. As equipes vermelhas podem testar se os modelos podem ser manipulados para gerar conteúdo prejudicial. Essas atividades devem ser integradas às operações de IA.
Para obter informações sobre como realizar testes de equipe vermelha, consulte Planejando a equipe vermelha para modelos de linguagem grandes (LLMs) e seus aplicativos.
Use as métricas certas. Use métricas apropriadas que sejam eficazes para medir o comportamento ético do modelo. As métricas variam dependendo do tipo de modelo de IA. A medição de modelos generativos pode não se aplicar a modelos de regressão. Considere um modelo que prevê a expectativa de vida e os resultados impactam as taxas de seguro. O viés neste modelo pode levar a questões éticas, mas esse problema decorre do desvio nos testes de métricas principais. Melhorar a precisão pode reduzir os problemas éticos, pois as métricas éticas e de precisão geralmente estão interligadas.
Adicione instrumentação ética. Os resultados do modelo de IA devem ser explicáveis. Você precisa justificar e rastrear como as inferências são feitas, incluindo os dados usados para treinamento, os recursos calculados e os dados de aterramento. Na IA discriminativa, você pode justificar as decisões passo a passo. No entanto, para modelos generativos, explicar os resultados pode ser complexo. Documente o processo de tomada de decisão para abordar possíveis implicações legais e fornecer transparência.
Esse aspecto de explicabilidade deve ser implementado em todo o ciclo de vida da IA. A limpeza, a linhagem, os critérios de seleção e o processamento de dados são estágios críticos em que as decisões devem ser rastreadas.
Ferramentas
Ferramentas para segurança de conteúdo e rastreabilidade de dados, como o Microsoft Purview, devem ser integradas. As APIs de Segurança de Conteúdo de IA do Azure podem ser chamadas de seus testes para facilitar o teste de segurança de conteúdo.
O Azure AI Foundry fornece métricas que avaliam o comportamento do modelo. Para obter mais informações, consulte Métricas de avaliação e monitoramento para IA generativa.
Para modelos de treinamento, recomendamos examinar as métricas fornecidas pelo Azure Machine Learning.
Inspecionar dados de entrada e saída
Ataques de injeção imediata, como jailbreak, são uma preocupação comum para cargas de trabalho de IA. Nesse caso, alguns usuários podem tentar usar indevidamente o modelo para fins não intencionais. Para garantir a segurança, inspecione os dados para evitar ataques e filtre conteúdo impróprio. Essa análise deve ser aplicada à entrada do usuário e às respostas do sistema para garantir que haja moderação de conteúdo completa nos fluxos de entrada e saída.
Em cenários em que você está fazendo várias invocações de modelo, como por meio do Azure OpenAI, para atender a uma única solicitação de cliente, a aplicação de verificações de segurança de conteúdo a cada invocação pode ser cara e desnecessária. Considere centralizar esse trabalho na arquitetura, mantendo a segurança como uma responsabilidade do lado do servidor. Suponha que uma arquitetura tenha um gateway na frente do ponto de extremidade de inferência do modelo para descarregar determinados recursos de back-end. Esse gateway pode ser projetado para lidar com verificações de segurança de conteúdo para solicitações e respostas que o back-end pode não suportar nativamente. Embora um gateway seja uma solução comum, uma camada de orquestração pode lidar com essas tarefas de forma eficaz em arquiteturas mais simples. Em ambos os casos, você pode aplicar seletivamente essas verificações quando necessário, otimizando o desempenho e o custo.
As inspeções devem ser multimodais, abrangendo vários formatos. Ao usar a entrada multimodal, como imagens, é importante analisá-las em busca de mensagens ocultas que possam ser prejudiciais ou violentas. Essas mensagens podem não ser imediatamente visíveis, semelhantes à tinta invisível, e requerem uma inspeção cuidadosa. Use ferramentas como APIs de segurança de conteúdo para essa finalidade.
Para aplicar políticas de privacidade e segurança de dados, inspecione os dados do usuário e os dados de aterramento para conformidade com os regulamentos de privacidade. Certifique-se de que os dados sejam limpos ou filtrados à medida que fluem pelo sistema. Por exemplo, dados de conversas anteriores de suporte ao cliente podem servir como dados de base. Deve ser higienizado antes de ser reutilizado.
Lidar com os dados do usuário de forma ética
As práticas éticas envolvem o tratamento cuidadoso do gerenciamento de dados do usuário. Isso inclui saber quando usar dados e quando evitar depender de dados do usuário.
Inferência sem compartilhar dados do usuário. Para compartilhar com segurança os dados do usuário com outras organizações para obter insights, use um modelo de câmara de compensação. Nesse cenário, as organizações fornecem dados a um terceiro confiável, que treina um modelo usando os dados agregados. Esse modelo pode ser usado por todas as instituições, permitindo insights compartilhados sem expor conjuntos de dados individuais. O objetivo é usar os recursos de inferência do modelo sem compartilhar dados de treinamento detalhados.
Promova a diversidade e a inclusão. Quando os dados do usuário forem necessários, use uma gama diversificada de dados, incluindo gêneros e criadores sub-representados, para minimizar o viés. Implemente recursos que incentivem os usuários a explorar conteúdo novo e variado. Tenha monitoramento contínuo do uso e ajuste as recomendações para evitar a representação excessiva de qualquer tipo de conteúdo único.
Respeite o "Direito de ser esquecido". Evite usar dados do usuário, sempre que possível. Garantir a conformidade com o "Direito de ser esquecido" adotando as medidas necessárias para garantir que os dados do usuário sejam excluídos diligentemente.
Para garantir a conformidade, pode haver solicitações para remover dados do usuário do sistema. Para modelos menores, isso pode ser feito treinando novamente com dados que excluem informações pessoais. Para modelos maiores, que podem consistir em vários modelos menores e treinados independentemente, o processo é mais complexo e o custo e o esforço são significativos. Busque orientação legal e ética sobre como lidar com essas situações e certifique-se de que isso esteja incluído em sua política de IA responsável, descrita em Desenvolver políticas de IA responsável.
Mantenha com responsabilidade. Quando a exclusão de dados não for possível, obtenha o consentimento explícito do usuário para a coleta de dados e forneça políticas de privacidade claras. Colete e retenha dados somente quando for absolutamente necessário. Tenha operações em vigor para remover dados agressivamente quando não forem mais necessários. Por exemplo, limpe o histórico de bate-papo assim que possível e anonimize os dados confidenciais antes da retenção. Certifique-se de que métodos avançados de criptografia sejam usados para esses dados em repouso.
Suporte à explicabilidade. Rastreie decisões no sistema para dar suporte aos requisitos de explicabilidade. Desenvolva explicações claras de como os algoritmos de recomendação funcionam, oferecendo aos usuários insights sobre por que um conteúdo específico é recomendado a eles. O objetivo é garantir que as cargas de trabalho de IA e seus resultados sejam transparentes e justificáveis, detalhando como as decisões são tomadas, quais dados foram usados e como os modelos foram treinados.
Criptografar dados do usuário. Os dados de entrada devem ser criptografados em todos os estágios do pipeline de processamento de dados a partir do momento em que o usuário insere os dados. Isso inclui dados à medida que se movem de um ponto para outro, onde são armazenados e durante a inferência, se necessário. Equilibre segurança e funcionalidade, mas procure manter os dados privados durante todo o seu ciclo de vida.
Para obter informações sobre técnicas de criptografia, consulte Design de Aplicativo.
Forneça controles de acesso robustos. Vários tipos de identidades podem acessar dados do usuário. Implemente o RBAC (Controle de Acesso Baseado em Função) para o plano de controle e o plano de dados, abrangendo a comunicação entre usuários e sistemas
Além disso, mantenha a segmentação adequada de usuários para proteger a privacidade. Por exemplo, o Copilot para Microsoft 365 pode pesquisar e fornecer respostas com base em documentos e emails específicos de um usuário, garantindo que apenas o conteúdo relevante para esse usuário seja acessado.
Para obter informações sobre como impor controles de acesso, consulte Design do aplicativo.
Reduza a área de superfície. Uma estratégia fundamental do pilar Well-Architected Framework Security é minimizar a superfície de ataque e proteger os recursos. Essa estratégia deve ser aplicada às práticas padrão de segurança de endpoint, controlando rigidamente os endpoints da API, expondo apenas dados essenciais e evitando informações irrelevantes nas respostas. A escolha do projeto deve ser equilibrada entre flexibilidade e controle.
Verifique se não há pontos de extremidade anônimos. Em geral, evite dar aos clientes mais controle do que o necessário. Na maioria dos cenários, os clientes não precisam ajustar hiperparâmetros, exceto em ambientes experimentais. Para casos de uso típicos, como interagir com um agente virtual, os clientes devem controlar apenas os aspectos essenciais para garantir a segurança, limitando o controle desnecessário.
Para obter informações, consulte Design do aplicativo.