Como configurar o controle de acesso em objetos sincronizados no pool de SQL sem servidor
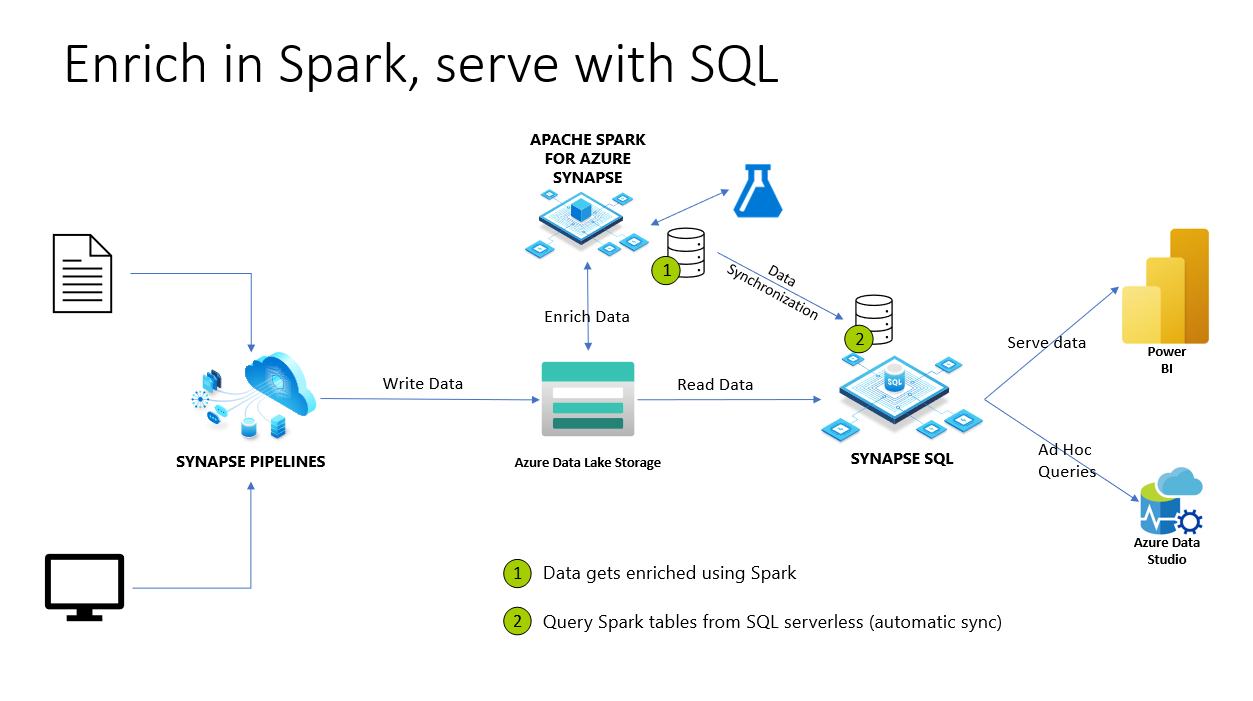
No Azure Synapse Analytics, os bancos de dados e as tabelas do Spark são compartilhados com o pool de SQL sem servidor. Tabelas incluídas em backup de Bancos de dados do Lake, Parquet e CSV criados com o Spark estão automaticamente disponíveis no pool de SQL sem servidor. Esse recurso permite o uso do pool de SQL sem servidor para explorar e consultar dados preparados usando pools do Spark. No diagrama abaixo, você pode ver uma visão geral da arquitetura de alto nível para utilizar esse recurso. Primeiro, os Pipelines do Azure Synapse estão movendo dados do armazenamento local (ou outro) para o Azure Data Lake Storage. Agora, o Spark pode enriquecer os dados e criar bancos de dados e tabelas que estão sendo sincronizados com SQL do Synapse sem servidor. Depois, o usuário pode executar consultas ad hoc nos dados enriquecidos ou servi-los ao Power BI, por exemplo.
Acesso de administrador completo (sysadmin)
Assim que esses bancos de dados e tabelas são sincronizados do Spark para o pool de SQL sem servidor, essas tabelas externas no pool SQL sem servidor podem ser usadas para acessar os mesmos dados. No entanto, os objetos no pool de SQL sem servidor são somente leitura devido à manutenção da consistência com os objetos de pools do Spark. A limitação faz com somente os usuários com funções de Administrador do SQL do Synapse ou Administrador do Synapse possam acessar esses objetos no pool SQL sem servidor. Se um usuário não administrador tentar executar uma consulta no banco de dados/tabela sincronizada, ele receberá um erro como: External table '<table>' is not accessible because content of directory cannot be listed. apesar de terem acesso aos dados nas contas de armazenamento subjacentes.
Como os bancos de dados sincronizados no pool de SQL sem servidor são somente leitura, eles não podem ser modificados. Criar um usuário ou conceder outras permissões falharão se tentadas. Para ler bancos de dados sincronizados, deve-se ter permissões de nível de servidor privilegiadas (como sysadmin). Essa limitação também está presente em tabelas externas no pool de SQL sem servidor ao usar o Link do Azure Synapse para Dataverse e tabelas de bancos de dados lake.
Acesso de não administrador a bancos de dados sincronizados
Um usuário que precisa ler dados e criar relatórios geralmente não tem o acesso de administrador completo (sysadmin). Esse usuário geralmente é analista de dados que precisa apenas ler e analisar dados usando as tabelas existentes. Eles não precisam criar novos objetos.
Um usuário com permissão mínima deve ser capaz de:
- Conectar-se a um banco de dados que é replicado do Spark
- Selecionar dados por meio de tabelas externas e acessar os dados do ADLS subjacentes.
Após executar o script de código abaixo, ele permitirá ao usuários não administradores ter permissões de nível de servidor para se conectarem a qualquer banco de dados. Ele também permitirá aos usuários exibir dados de todos os objetos de nível de esquema, como tabelas ou exibições. A segurança de acesso a dados pode ser gerenciada na camada de armazenamento.
-- Creating Azure AD login (same can be achieved for Azure AD app)
CREATE LOGIN [login@contoso.com] FROM EXTERNAL PROVIDER;
go;
GRANT CONNECT ANY DATABASE to [login@contoso.com];
GRANT SELECT ALL USER SECURABLES to [login@contoso.com];
GO;
Observação
Essas instruções devem ser executadas no banco de dados mestre, pois são todas permissões no nível do servidor.
Após criar um logon e conceder permissões, os usuários podem executar consultas na parte superior das tabelas externas sincronizadas. Essa mitigação também pode ser aplicada aos grupos de segurança do Microsoft Entra.
Mais segurança sobre os objetos pode ser gerenciada por meio de esquemas específicos e bloquear o acesso a um esquema específico. A solução alternativa requer DDL extra. Para esse cenário, você pode criar novos bancos de dados sem servidor, esquemas e exibições que apontarão para os data de tabelas do Spark no ADLS.
O acesso aos dados na conta de armazenamento pode ser gerenciado pela A ou funções regulares de Proprietário/Leitor/Colaborador dos Dados de Blob de Armazenamento dos usuários/grupos do Microsoft Entra. Nas entidades de serviço (aplicativos do Microsoft Entra), use a configuração de ACL.
Observação
- Se desejar proibir o uso de OPENROWSET sobre os dados, você pode usar
DENY ADMINISTER BULK OPERATIONS to [login@contoso.com];Para obter mais informações, visite DENY Permissões de servidor. - Se desejar proibir o uso de esquemas específicos, você pode usar
DENY SELECT ON SCHEMA::[schema_name] TO [login@contoso.com];Para obter mais informações, visite DENY Permissões de esquema.
Próximas etapas
Para obter mais informações, confira Autenticação do SQL.