Introdução à API de montagem/desmontagem de arquivos no Azure Synapse Analytics
A equipe do Azure Synapse Studio criou duas novas APIs de montagem/desmontagem no pacote Utilitários do Microsoft Spark (mssparkutils). Essas APIs podem ser usadas para anexar o armazenamento remoto (Armazenamento de Blobs do Azure ou Azure Data Lake Storage Gen2) a todos os nós em funcionamento (nó do driver e nós de trabalho). Depois que o armazenamento estiver em vigor, você poderá usar a API de arquivo local para acessar dados como se estivessem armazenados no sistema de arquivos local. Para saber mais, confira Introdução aos Utilitários do Microsoft Spark.
O artigo mostra como usar APIs de montagem/desmontagem em seu workspace. O que você aprenderá:
- Como montar Data Lake Storage Gen2 ou Armazenamento de Blobs.
- Como acessar arquivos no ponto de montagem por meio da API do sistema de arquivos local.
- Como acessar arquivos no ponto de montagem por meio da API
mssparktuils fs. - Como acessar arquivos no ponto de montagem por meio da API de leitura do Spark.
- Como desmontar o ponto de montagem.
Aviso
A montagem de compartilhamento de arquivos do Azure está temporariamente desabilitada. Você pode usar uma montagem do Data Lake Storage Gen2 ou Armazenamento de Blobs do Azure, conforme descrito na próxima seção.
O armazenamento do Azure Data Lake Storage Gen1 não tem suporte. Você pode migrar para Data Lake Storage Gen2 seguindo as diretrizes de migração do Azure Data Lake Storage Gen1 para Gen2 antes de usar as APIs de montagem.
Armazenamento da montagem
Esta seção ilustra como montar Data Lake Storage Gen2 passo a passo como exemplo. A montagem do Armazenamento de Blobs funciona da mesma forma.
O exemplo pressupõe que você tenha uma conta Data Lake Storage Gen2 chamada storegen2. A conta tem um contêiner chamado mycontainer, que você deseja montar em /test no pool do Spark.
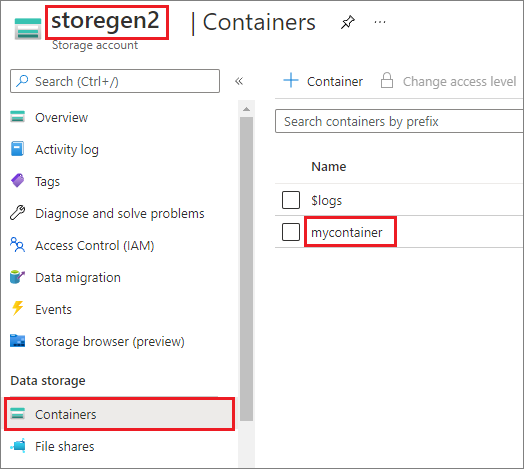
Para montar o contêiner chamado mycontainer, mssparkutils primeiro precisa verificar se você tem a permissão para acessar o contêiner. Atualmente, o Azure Synapse Analytics dá suporte a três métodos de autenticação para a operação de montagem do gatilho: linkedService, accountKeye sastoken.
Montar usando um serviço vinculado (recomendado)
Recomendamos uma montagem de gatilho por meio do serviço vinculado. Esse método evita vazamentos de segurança, pois mssparkutils não armazena nenhum segredo ou valores de autenticação em si. Em vez disso, mssparkutils sempre busca valores de autenticação do serviço vinculado para solicitar dados de blob do armazenamento remoto.
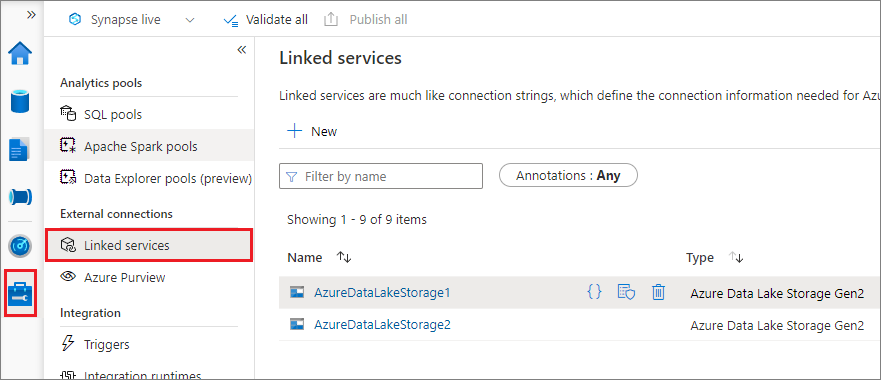
Você pode criar um serviço vinculado para Data Lake Storage Gen2 ou Armazenamento de Blobs. Atualmente, o Azure Synapse Analytics dá suporte a dois métodos de autenticação ao criar um serviço vinculado:
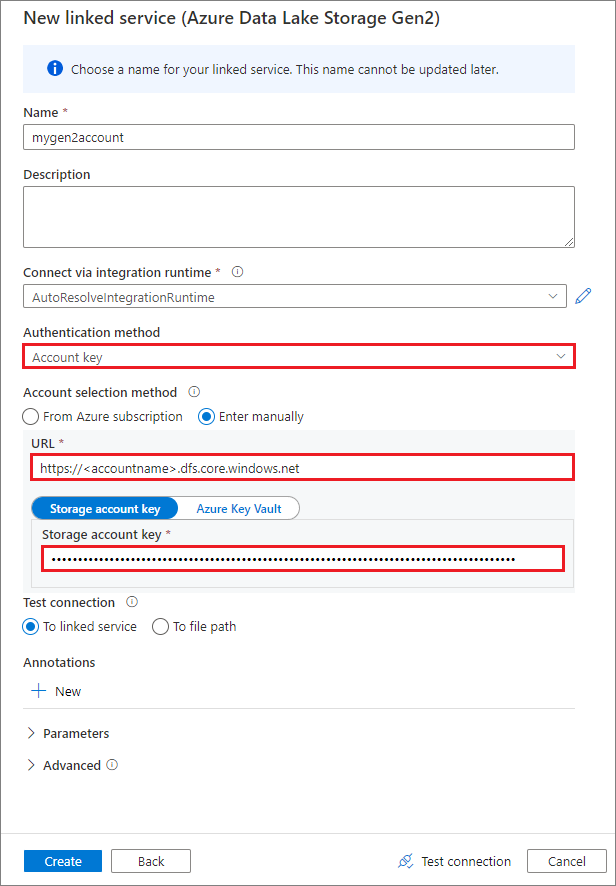
Criar um serviço vinculado por meio de uma chave de conta
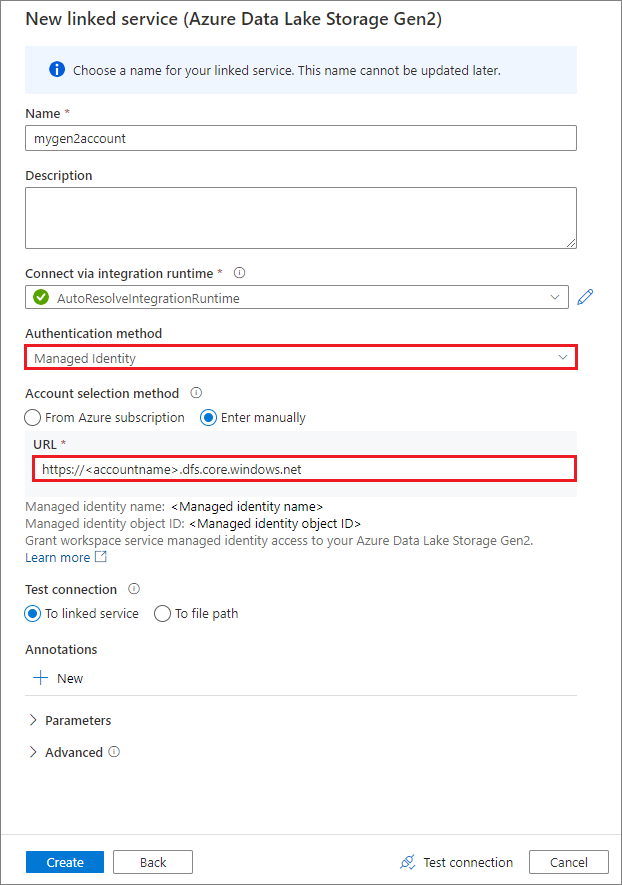
Criar um serviço vinculado usando uma identidade gerenciada atribuída pelo sistema
Importante
- Se o Serviço Vinculado ao Azure Data Lake Storage Gen2 criado acima usar umponto de extremidade privado gerenciado (com um URI dfs), precisaremos criar outro ponto de extremidade privado gerenciado secundário usando a opção Armazenamento de Blobs do Azure (com um URI de blob) para garantir que o código interno fsspec/adlfs possa se conectar usando a Interface BlobServiceClient.
- Caso o ponto de extremidade privado gerenciado secundário não esteja configurado corretamente, veremos uma mensagem de erro como ServiceRequestError: Não é possível se conectar ao host [storageaccountname].blob.core.windows.net:443 ssl:True [Nome ou serviço desconhecido]
Observação
Se você criar um serviço vinculado usando uma identidade gerenciada como método de autenticação, verifique se o arquivo MSI do workspace tem a função de Colaborador do Armazenamento do Microsoft Azure do contêiner montado.
Depois de criar o serviço vinculado com êxito, você pode facilmente montar o contêiner em seu pool do Spark com o código de Python abaixo:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService": "mygen2account"}
)
Observação
Talvez seja necessário importar mssparkutils se ele não estiver disponível:
from notebookutils import mssparkutils
Não recomendamos a montagem de uma pasta raiz, independente do método de autenticação usado.
Parâmetros de montagem:
- fileCacheTimeout: os blobs serão armazenados em cache na pasta temporária local por 120 segundos por padrão. Durante esse tempo, o Blobfuse não verificará se o arquivo está atualizado ou não. O parâmetro pode ser definido para alterar o tempo limite padrão. Quando vários clientes modificam arquivos ao mesmo tempo, para evitar inconsistências entre arquivos locais e remotos, recomendamos reduzir o tempo de cache ou até mesmo alterá-lo para 0 e sempre obter os arquivos mais recentes do servidor.
- tempo limite: o tempo limite da operação de montagem é de 120 segundos por padrão. O parâmetro pode ser definido para alterar o tempo limite padrão. Quando houver muitos executores ou quando a montagem atingir o tempo limite, recomendamos aumentar o valor.
- escopo: o parâmetro de escopo é usado para especificar o escopo da montagem. O valor padrão é "trabalho". Se o escopo estiver definido como "trabalho", a montagem ficará visível apenas para o cluster atual. Se o escopo estiver definido como "espaço de trabalho", a montagem ficará visível para todos os blocos de anotações no espaço de trabalho atual e o ponto de montagem será criado automaticamente se ele não existir. Adicione os mesmos parâmetros à API desmontada para desmontar o ponto de montagem. A montagem no nível do espaço de trabalho só tem suporte para autenticação do serviço vinculado.
Você pode usar esses parâmetros como este:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService":"mygen2account", "fileCacheTimeout": 120, "timeout": 120}
)
Montagem por meio de token de assinatura de acesso compartilhado ou chave de conta
Além de montar por meio de um serviço vinculado, mssparkutils dá suporte a passar explicitamente uma chave de conta ou um token de assinatura de acesso compartilhado (SAS) como um parâmetro para montar o destino.
Por motivos de segurança, recomendamos que você armazene chaves de conta ou tokens SAS no Azure Key Vault (como mostra a captura de tela de exemplo a seguir). Em seguida, você pode recuperá-los usando a API mssparkutil.credentials.getSecret. Para saber mais, confira Gerenciar chaves da conta de armazenamento com o Key Vault e a CLI do Azure (herdado).
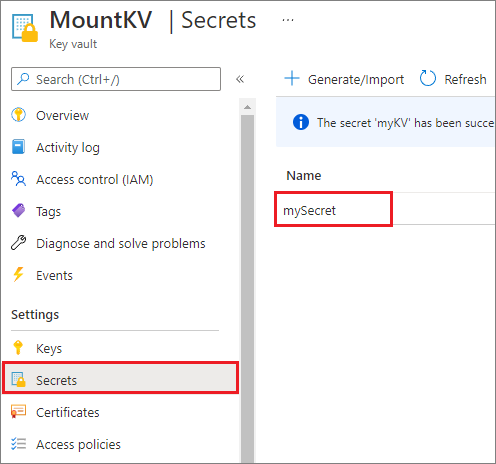
Veja o código de exemplo:
from notebookutils import mssparkutils
accountKey = mssparkutils.credentials.getSecret("MountKV","mySecret")
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"accountKey":accountKey}
)
Observação
Por motivos de segurança, não armazene credenciais no código.
Acessar os arquivos no ponto de montagem usando a API mssparkutils fs
A principal finalidade da operação de montagem é permitir o acesso dos clientes aos dados armazenados em uma conta de armazenamento remoto por meio da API do sistema de arquivos local. Você também pode acessar os dados usando a API mssparkutils fs com um caminho montado como parâmetro. O formato de caminho usado aqui é um pouco diferente.
Supondo que você tenha montado o contêiner mycontainer do Data Lake Storage Gen2 em /test usando a API de montagem. Ao acessar os dados por meio de uma API do sistema de arquivos local:
- Para versões do Spark menores ou iguais a 3.3, o formato do caminho é
/synfs/{jobId}/test/{filename}. - Para versões do Spark maiores ou iguais a 3.4, o formato do caminho é
/synfs/notebook/{jobId}/test/{filename}.
É recomendável usar um mssparkutils.fs.getMountPath() para obter o caminho preciso:
path = mssparkutils.fs.getMountPath("/test")
Observação
Quando você monta o armazenamento com workspace escopo, o ponto de montagem é criado na /synfs/workspace pasta. E você precisa usar mssparkutils.fs.getMountPath("/test", "workspace") para obter o caminho preciso.
Quando você deseja acessar os dados usando a mssparkutils fs API, o formato do caminho é assim: synfs:/notebook/{jobId}/test/{filename}. Você pode ver que synfs é usado como esquema nesse caso em vez de uma parte do caminho montado. Claro, você também pode usar o esquema do sistema de arquivos local para acessar os dados. Por exemplo, file:/synfs/notebook/{jobId}/test/{filename}.
Os três exemplos a seguir mostram como acessar um arquivo com um caminho de ponto de montagem usando mssparkutils fs.
Listar diretórios:
mssparkutils.fs.ls(f'file:{mssparkutils.fs.getMountPath("/test")}')Ler conteúdo do arquivo:
mssparkutils.fs.head(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv')Criar um diretório:
mssparkutils.fs.mkdirs(f'file:{mssparkutils.fs.getMountPath("/test")}/myDir')
Acessar arquivos no ponto de montagem por meio da API de leitura do Spark
Você pode fornecer um parâmetro para acessar os dados por meio da API de leitura do Spark. O formato do caminho aqui é o mesmo quando você usa a mssparkutils fs API.
Ler um arquivo de uma conta de armazenamento Data Lake Storage Gen2 montada
O exemplo a seguir pressupõe que uma conta de armazenamento Data Lake Storage Gen2 já foi montada e, em seguida, você lê o arquivo usando um caminho de montagem:
%%pyspark
df = spark.read.load(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv', format='csv')
df.show()
Observação
Ao montar o armazenamento usando um serviço vinculado, você sempre deve definir explicitamente a configuração de serviço vinculado do Spark antes de usar o esquema synfs para acessar os dados. Consulte Armazenamento do ADLS Gen2 com serviços vinculados para obter detalhes.
Ler um arquivo de uma conta de Armazenamento de Blobs montada
Se você montou uma conta de Armazenamento de Blobs e quer acessá-la usando mssparkutils ou a API do Spark, precisará configurar explicitamente o token SAS por meio da configuração do Spark antes de tentar montar o contêiner usando a API de montagem:
Para acessar uma conta de Armazenamento de Blobs usando
mssparkutilsou a API do Spark após uma montagem de gatilho, atualize a configuração do Spark conforme mostrado no exemplo de código a seguir. Você pode ignorar essa etapa se quiser acessar a configuração do Spark apenas usando a API de arquivo local após a montagem.blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds("myblobstorageaccount") spark.conf.set('fs.azure.sas.mycontainer.<blobStorageAccountName>.blob.core.windows.net', blob_sas_token)Crie o serviço vinculado
myblobstorageaccounte monte a conta de Armazenamento de Blobs por meio desse serviço:%%spark mssparkutils.fs.mount( "wasbs://mycontainer@<blobStorageAccountName>.blob.core.windows.net", "/test", Map("linkedService" -> "myblobstorageaccount") )Monte o contêiner de armazenamento de blobs e leia o arquivo usando o caminho de montagem por meio da API de arquivo local:
# mount the Blob Storage container, and then read the file by using a mount path with open(mssparkutils.fs.getMountPath("/test") + "/myFile.txt") as f: print(f.read())Leia os dados do contêiner de Armazenamento de Blobs montado por meio da API de leitura do Spark:
%%spark // mount blob storage container and then read file using mount path val df = spark.read.text(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.txt') df.show()
Desmonte o caminho de montagem
Use o código a seguir para desmontar o ponto de montagem (/test neste exemplo):
mssparkutils.fs.unmount("/test")
Limitações conhecidas
O mecanismo de desmontagem não é automático. Quando a execução do aplicativo for concluída, para desmontar o ponto de montagem para liberar o espaço em disco, você precisará chamar explicitamente uma API desmontada em seu código. Caso contrário, o ponto de montagem ainda existirá no nó após a conclusão da execução do aplicativo.
Não há suporte para a montagem de uma conta de armazenamento Data Lake Storage Gen1 por enquanto.