Coletar métricas de aplicativos Apache Spark usando APIs
Visão geral
Neste tutorial, você aprenderá a integrar o servidor Prometheus local existente ao workspace do Azure Synapse para obter métricas do aplicativo Apache Spark quase em tempo real usando o conector do Synapse Prometheus.
Este tutorial também apresenta as APIs de métricas REST do Azure Synapse. Você pode buscar os dados de métricas do aplicativo Apache Spark por meio das APIs REST para criar seu kit de ferramentas de monitoramento e diagnóstico ou integrá-los aos seus sistemas de monitoramento.
Usar o conector do Azure Synapse Prometheus para os servidores locais do Prometheus
O conector do Azure Synapse Prometheus é um projeto de software livre. O conector do Synapse Prometheus usa um método de descoberta de serviço baseado em arquivo para permitir que você:
- Autentique-se no espaço de trabalho do Synapse por uma entidade de serviço do Microsoft Entra.
- Busque a lista de aplicativos Apache Spark do workspace.
- Efetue pull das métricas do aplicativo Apache Spark por meio da configuração baseada em arquivo do Prometheus.
1. Pré-requisito
Você precisa ter um servidor do Prometheus implantado em uma VM Linux.
2. Criar uma entidade de serviço
Para usar o conector do Azure Synapse Prometheus no servidor local do Prometheus, você deve seguir as etapas abaixo para criar uma entidade de serviço.
2.1 Criar uma entidade de serviço:
az ad sp create-for-rbac --name <service_principal_name> --role Contributor --scopes /subscriptions/<subscription_id>
O resultado deve ter esta aparência:
{
"appId": "abcdef...",
"displayName": "<service_principal_name>",
"name": "http://<service_principal_name>",
"password": "abc....",
"tenant": "<tenant_id>"
}
Anote a appId, senha e ID de locatário.
2.2 Adicionar permissões correspondentes à entidade de serviço criada na etapa acima.
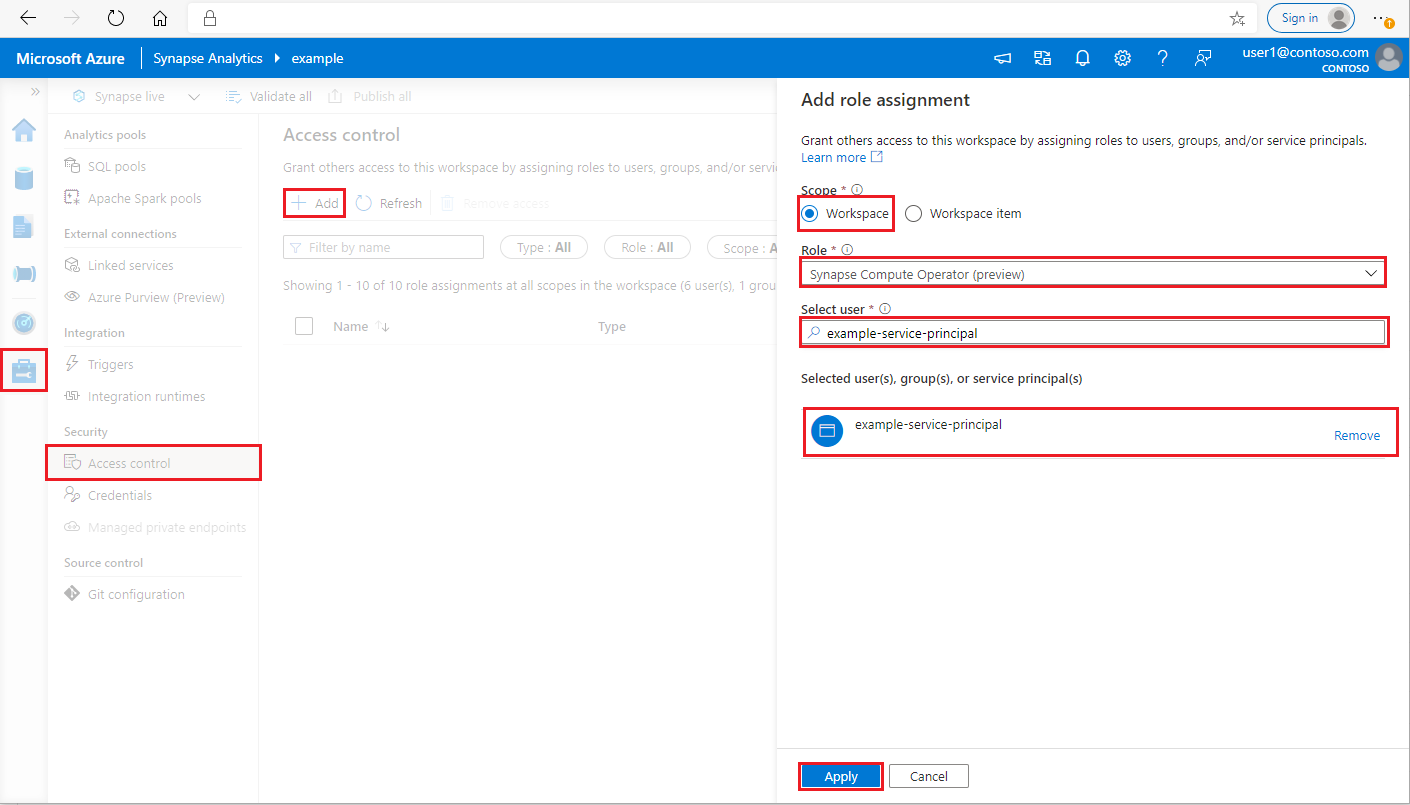
Faça logon no workspace do Azure Synapse Analytics como administrador do Synapse
No Synapse Studio, no painel do lado esquerdo, selecione Gerenciar > Controle de acesso
Clique no botão Adicionar na parte superior esquerda para adicionar uma atribuição de função
Para escopo, escolha Workspace
Para função, escolha Operador de computação do Synapse
Para selecionar usuário, insira o <service_principal_name> e clique na entidade de serviço
Clique em Aplicar (aguarde 3 minutos para que a permissão entre em vigor.)
3. Baixar o conector do Azure Synapse Prometheus
Use os comandos para instalar o conector do Azure Synapse Prometheus.
git clone https://github.com/microsoft/azure-synapse-spark-metrics.git
cd ./azure-synapse-spark-metrics/synapse-prometheus-connector/src
python pip install -r requirements.txt
4. Criar um arquivo de configuração para os workspaces do Azure Synapse
Crie um arquivo config.yaml na pasta de configuração e preencha os seguintes campos: workspace_name, tenant_id, service_principal_name e service_principal_password. Você pode adicionar vários workspaces na configuração do YAML.
workspaces:
- workspace_name: <your_workspace_name>
tenant_id: <tenant_id>
service_principal_name: <service_principal_app_id>
service_principal_password: "<service_principal_password>"
5. Atualizar a configuração do Prometheus
Adicione a seção de configuração a seguir no scrape_config do Prometheus e substitua o <
- job_name: synapse-prometheus-connector
static_configs:
- labels:
__metrics_path__: /metrics
__scheme__: http
targets:
- localhost:8000
- job_name: synapse-workspace-<your_workspace_name>
bearer_token_file: <path_to_synapse_connector>/output/workspace/<your_workspace_name>/bearer_token
file_sd_configs:
- files:
- <path_to_synapse_connector>/output/workspace/<your_workspace_name>/application_discovery.json
refresh_interval: 10s
metric_relabel_configs:
- source_labels: [ __name__ ]
target_label: __name__
regex: metrics_application_[0-9]+_[0-9]+_(.+)
replacement: spark_$1
- source_labels: [ __name__ ]
target_label: __name__
regex: metrics_(.+)
replacement: spark_$1
6. Iniciar o conector na VM do servidor do Prometheus
Inicie um servidor de conector na VM de servidor do Prometheus da seguinte maneira.
python main.py
Aguarde alguns segundos até que o conector comece a funcionar. E você pode ver o "synapse-prometheus-connector" na página de descoberta do serviço Prometheus.
Use o Azure Synapse Prometheus ou as APIs de métrica REST para coletar os dados de métricas
1. Autenticação
Você pode usar o fluxo de credenciais do cliente para obter um token de acesso. Para acessar a API de métricas, você deve obter um token de acesso do Microsoft Entra para a entidade de serviço, que tem permissão adequada para acessar as APIs.
| Parâmetro | Obrigatório | Descrição |
|---|---|---|
| tenant_id | True | A ID de locatário da entidade de serviço do Azure (aplicativo) |
| grant_type | True | Especifica o tipo de concessão solicitada. Em um fluxo de Concessão de Credenciais de Cliente, o valor deve ser client_credentials. |
| client_id | True | A ID do aplicativo (entidade de serviço) que você registrou no portal do Azure ou na CLI do Azure. |
| client_secret | True | O segredo gerado para o aplicativo (entidade de serviço) |
| recurso | True | O URI de recurso do Azure Synapse deveria ser "https://dev.azuresynapse.net" |
curl -X GET -H 'Content-Type: application/x-www-form-urlencoded' \
-d 'grant_type=client_credentials&client_id=<service_principal_app_id>&resource=<azure_synapse_resource_id>&client_secret=<service_principal_secret>' \
https://login.microsoftonline.com/<tenant_id>/oauth2/token
A resposta tem esta aparência:
{
"token_type": "Bearer",
"expires_in": "599",
"ext_expires_in": "599",
"expires_on": "1575500666",
"not_before": "1575499766",
"resource": "2ff8...f879c1d",
"access_token": "ABC0eXAiOiJKV1Q......un_f1mSgCHlA"
}
2. Listar aplicativos em execução no workspace do Azure Synapse
Para obter uma lista de aplicativos Apache Spark para um workspace do Azure Synapse, siga este documento Monitoramento – Obter a lista de trabalhos do Apache Spark.
3. Coletar métricas do aplicativo Apache Spark com a API do Prometheus ou as APIs REST
Coletar as métricas do aplicativo Apache Spark com a API do Prometheus
Obter as métricas mais recentes do aplicativo Apache Spark especificadas pela API do Prometheus
GET https://{endpoint}/livyApi/versions/{livyApiVersion}/sparkpools/{sparkPoolName}/sessions/{sessionId}/applications/{sparkApplicationId}/metrics/executors/prometheus?format=html
| Parâmetro | Obrigatório | Descrição |
|---|---|---|
| endpoint | True | O ponto de extremidade de desenvolvimento do workspace, por exemplo https://myworkspace.dev.azuresynapse.net. |
| livyApiVersion | True | Versão de API válida para a solicitação. No momento, é 2019-11-01-preview |
| sparkPoolName | True | Nome do pool do Spark. |
| sessionID | True | Identificador da sessão. |
| sparkApplicationId | True | ID do aplicativo Spark |
Exemplo de solicitação:
GET https://myworkspace.dev.azuresynapse.net/livyApi/versions/2019-11-01-preview/sparkpools/mysparkpool/sessions/1/applications/application_1605509647837_0001/metrics/executors/prometheus?format=html
Exemplo de resposta:
Código de status: a resposta 200 tem esta aparência:
metrics_executor_rddBlocks{application_id="application_1605509647837_0001", application_name="mynotebook_mysparkpool_1605509570802", executor_id="driver"} 0
metrics_executor_memoryUsed_bytes{application_id="application_1605509647837_0001", application_name="mynotebook_mysparkpool_1605509570802", executor_id="driver"} 74992
metrics_executor_diskUsed_bytes{application_id="application_1605509647837_0001", application_name="mynotebook_mysparkpool_1605509570802", executor_id="driver"} 0
metrics_executor_totalCores{application_id="application_1605509647837_0001", application_name="mynotebook_mysparkpool_1605509570802", executor_id="driver"} 0
metrics_executor_maxTasks{application_id="application_1605509647837_0001", application_name="mynotebook_mysparkpool_1605509570802", executor_id="driver"} 0
metrics_executor_activeTasks{application_id="application_1605509647837_0001", application_name="mynotebook_mysparkpool_1605509570802", executor_id="driver"} 1
metrics_executor_failedTasks_total{application_id="application_1605509647837_0001", application_name="mynotebook_mysparkpool_1605509570802", executor_id="driver"} 0
metrics_executor_completedTasks_total{application_id="application_1605509647837_0001", application_name="mynotebook_mysparkpool_1605509570802", executor_id="driver"} 2
...
Coletar as métricas do aplicativo Apache Spark com a API REST
GET https://{endpoint}/livyApi/versions/{livyApiVersion}/sparkpools/{sparkPoolName}/sessions/{sessionId}/applications/{sparkApplicationId}/executors
| Parâmetro | Obrigatório | Descrição |
|---|---|---|
| endpoint | True | O ponto de extremidade de desenvolvimento do workspace, por exemplo https://myworkspace.dev.azuresynapse.net. |
| livyApiVersion | True | Versão de API válida para a solicitação. No momento, é 2019-11-01-preview |
| sparkPoolName | True | Nome do pool do Spark. |
| sessionID | True | Identificador da sessão. |
| sparkApplicationId | True | ID do aplicativo Spark |
Solicitação de Exemplo
GET https://myworkspace.dev.azuresynapse.net/livyApi/versions/2019-11-01-preview/sparkpools/mysparkpool/sessions/1/applications/application_1605509647837_0001/executors
Código de status de resposta de exemplo: 200
[
{
"id": "driver",
"hostPort": "f98b8fc2aea84e9095bf2616208eb672007bde57624:45889",
"isActive": true,
"rddBlocks": 0,
"memoryUsed": 75014,
"diskUsed": 0,
"totalCores": 0,
"maxTasks": 0,
"activeTasks": 0,
"failedTasks": 0,
"completedTasks": 0,
"totalTasks": 0,
"totalDuration": 0,
"totalGCTime": 0,
"totalInputBytes": 0,
"totalShuffleRead": 0,
"totalShuffleWrite": 0,
"isBlacklisted": false,
"maxMemory": 15845975654,
"addTime": "2020-11-16T06:55:06.718GMT",
"executorLogs": {
"stdout": "http://f98b8fc2aea84e9095bf2616208eb672007bde57624:8042/node/containerlogs/container_1605509647837_0001_01_000001/trusted-service-user/stdout?start=-4096",
"stderr": "http://f98b8fc2aea84e9095bf2616208eb672007bde57624:8042/node/containerlogs/container_1605509647837_0001_01_000001/trusted-service-user/stderr?start=-4096"
},
"memoryMetrics": {
"usedOnHeapStorageMemory": 75014,
"usedOffHeapStorageMemory": 0,
"totalOnHeapStorageMemory": 15845975654,
"totalOffHeapStorageMemory": 0
},
"blacklistedInStages": []
},
// ...
]
4. Criar suas próprias ferramentas de diagnóstico e monitoramento
A API do Prometheus e as APIs REST fornecem dados de métricas sofisticados sobre o aplicativo Apache Spark que executa as informações. Você pode coletar os dados de métricas relacionados ao aplicativo por meio da API do Prometheus e das APIs REST. E você pode criar suas próprias ferramentas de diagnóstico e monitoramento que são mais adequadas para suas necessidades.