Coletar métricas e logs de aplicativos Apache Spark usando a conta do Armazenamento do Azure
A extensão do emissor de diagnóstico do Synapse Apache Spark é uma biblioteca que permite que o aplicativo Apache Spark emita os logs, os logs de eventos e as métricas para um ou mais destinos, incluindo o Azure Log Analytics, o Armazenamento do Azure e os Hubs de Eventos do Azure.
Neste tutorial, você aprenderá a usar a extensão do emissor de diagnóstico do Synapse Apache Spark para emitir logs, logs de eventos e métricas de aplicativos Apache Spark para sua conta de armazenamento do Azure.
Coletar logs e métricas para a conta de armazenamento
Etapa 1: criar uma conta de armazenamento
Para coletar logs de diagnóstico e métricas para a conta de armazenamento, use as contas existentes do Armazenamento do Azure. Ou, então, caso não tenha uma, crie uma conta de Armazenamento de Blobs do Azure ou crie uma conta de armazenamento para usar com o Azure Data Lake Storage Gen2.
Etapa 2: Criar um arquivo de configuração do Apache Spark
Crie um diagnostic-emitter-azure-storage-conf.txt e copie o conteúdo a seguir para o arquivo. Ou, então, baixe um exemplo de arquivo de modelo para a configuração do Pool do Apache Spark.
spark.synapse.diagnostic.emitters MyDestination1
spark.synapse.diagnostic.emitter.MyDestination1.type AzureStorage
spark.synapse.diagnostic.emitter.MyDestination1.categories Log,EventLog,Metrics
spark.synapse.diagnostic.emitter.MyDestination1.uri https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>
spark.synapse.diagnostic.emitter.MyDestination1.auth AccessKey
spark.synapse.diagnostic.emitter.MyDestination1.secret <storage-access-key>
Preencha os seguintes parâmetros no arquivo de configuração: <my-blob-storage>, <container-name>, <folder-name> e <storage-access-key>.
Para obter uma descrição mais detalhada dos parâmetros, confira Configurações do Armazenamento do Azure
Etapa 3: Carregar o arquivo de configuração do Apache Spark para Synapse Studio e usá-lo no pool do Spark
- Abra a página de configurações do Apache Spark (Gerenciar –> configurações do Apache Spark).
- Clique no botão Importar para carregar o arquivo de configuração do Apache Spark no Synapse Studio.
- Navegue até o Pool do Apache Spark no Synapse Studio (Gerenciar -> Pools do Apache Spark).
- Clique no botão "..." à direita do Pool do Apache Spark e selecione Configuração do Apache Spark.
- Você pode selecionar o arquivo de configuração que acabou de carregar no menu suspenso.
- Clique em Aplicar depois de selecionar o arquivo de configuração.
Etapa 4: Exibir os arquivos de logs na conta de armazenamento do Azure
Depois de enviar um trabalho para o Pool do Apache Spark configurado, você poderá ver os logs e os arquivos de métricas na conta de armazenamento de destino.
Os logs serão colocados em caminhos correspondentes de acordo com diferentes aplicativos pelo <workspaceName>.<sparkPoolName>.<livySessionId>.
Todos os arquivos de logs estarão no formato de linhas JSON (também chamado de JSON delimitado por nova linha, ndjson), o que é conveniente para o processamento de dados.
Configurações disponíveis
| Configuração | Descrição |
|---|---|
spark.synapse.diagnostic.emitters |
Obrigatórios. Os nomes de destino separados por vírgula dos emissores de diagnóstico. Por exemplo, MyDest1,MyDest2 |
spark.synapse.diagnostic.emitter.<destination>.type |
Obrigatórios. Tipo de destino interno. Para habilitar o destino do armazenamento do Azure, AzureStorage precisa ser incluído nesse campo. |
spark.synapse.diagnostic.emitter.<destination>.categories |
Opcional. As categorias de log selecionadas separadas por vírgula. Os valores disponíveis incluem DriverLog, ExecutorLog, EventLog e Metrics. Se ele não for definido, o valor padrão será todas as categorias. |
spark.synapse.diagnostic.emitter.<destination>.auth |
Obrigatórios. AccessKey para usar a autorização de chave de acesso da conta de armazenamento. SAS para autorização com assinaturas de acesso compartilhado. |
spark.synapse.diagnostic.emitter.<destination>.uri |
Obrigatórios. O URI da pasta de contêiner de blobs de destino. Deve corresponder ao padrão https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>. |
spark.synapse.diagnostic.emitter.<destination>.secret |
Opcional. O conteúdo do segredo (AccessKey ou SAS). |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault |
Obrigatório se .secret não for especificado. O nome do Azure Key Vault em que o segredo (AccessKey ou SAS) está armazenado. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.secretName |
Obrigatório se .secret.keyVault for especificado. O nome do segredo do Azure Key Vault em que o segredo (AccessKey ou SAS) está armazenado. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.linkedService |
Opcional. O nome do serviço vinculado do Azure Key Vault. Quando habilitado no pipeline do Synapse, isso é necessário para obter o segredo do AKV. (Verifique se o MSI tem permissão de leitura no AKV). |
spark.synapse.diagnostic.emitter.<destination>.filter.eventName.match |
Opcional. Os nomes de eventos do Spark separados por vírgula. Você pode especificar quais eventos serão coletados. Por exemplo: SparkListenerApplicationStart,SparkListenerApplicationEnd |
spark.synapse.diagnostic.emitter.<destination>.filter.loggerName.match |
Opcional. Os nomes dos agentes log4j separados por vírgula. Você pode especificar os logs que serão coletados. Por exemplo: org.apache.spark.SparkContext,org.example.Logger |
spark.synapse.diagnostic.emitter.<destination>.filter.metricName.match |
Opcional. Os sufixos de nome de métrica do Spark separados por vírgula. Você pode especificar as métricas que serão coletadas. Por exemplo: jvm.heap.used |
Exemplo de dados de log
Este é um exemplo de registro de log no formato JSON:
{
"timestamp": "2021-01-02T12:34:56.789Z",
"category": "Log|EventLog|Metrics",
"workspaceName": "<my-workspace-name>",
"sparkPool": "<spark-pool-name>",
"livyId": "<livy-session-id>",
"applicationId": "<application-id>",
"applicationName": "<application-name>",
"executorId": "<driver-or-executor-id>",
"properties": {
// The message properties of logs, events and metrics.
"timestamp": "2021-01-02T12:34:56.789Z",
"message": "Registering signal handler for TERM",
"logger_name": "org.apache.spark.util.SignalUtils",
"level": "INFO",
"thread_name": "main"
// ...
}
}
Workspace do Azure Synapse com a proteção contra exfiltração dos dados habilitada
Espaços de trabalho do Azure Synapse Analytics dão suporte à habilitação da proteção de vazamento de dados para espaços de trabalho. Com a proteção contra exfiltração, os logs e as métricas não podem ser enviados diretamente para os pontos de extremidade de destino. Você pode criar pontos de extremidade privados gerenciados correspondentes para diferentes pontos de extremidade de destino ou criar regras de firewall de IP nesse cenário.
Navegue até Synapse Studio > Gerenciar > Pontos de extremidade privados gerenciados, clique no botão Novo, selecione Armazenamento de Blobs do Azure ou Azure Data Lake Storage Gen2 e continue.
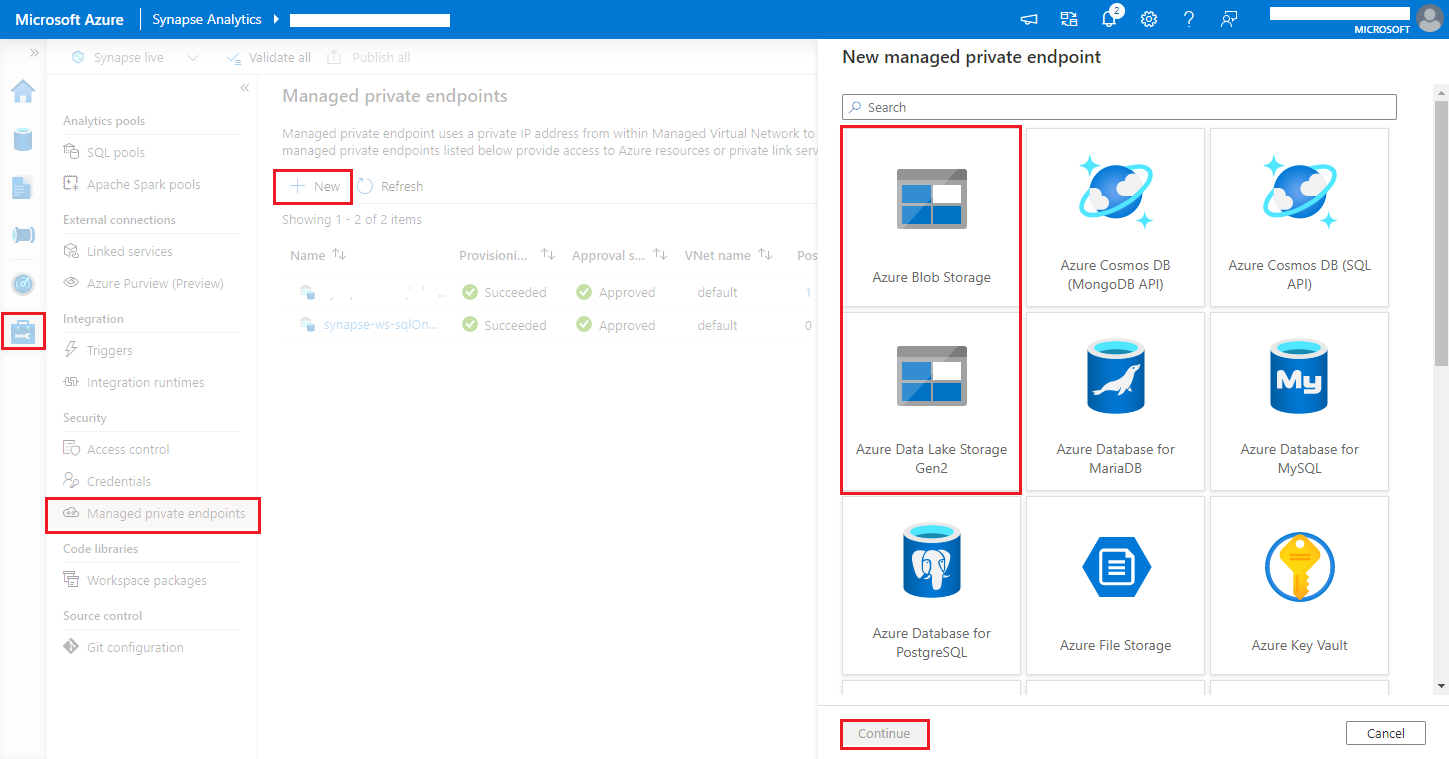
Observação
Podemos dar suporte a Armazenamento de Blobs do Azure e Azure Data Lake Storage Gen2. Mas não foi possível analisar o formato abfss://. Pontos de extremidade do Azure Data Lake Storage Gen2 devem ser formatados como uma URL de blob:
https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>Escolha sua conta de Armazenamento do Azure em Nome da conta de armazenamento e clique no botão Criar.
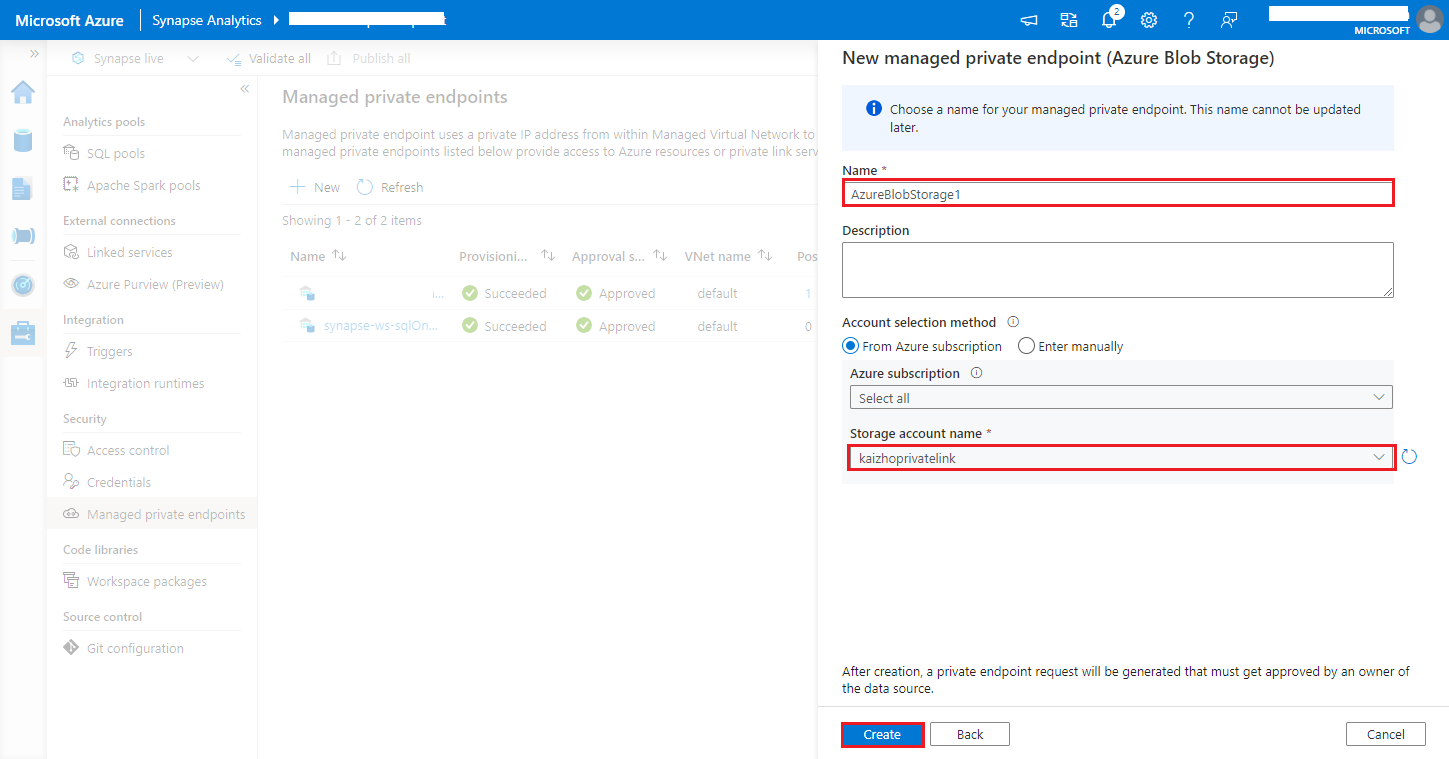
Aguarde alguns minutos para o provisionamento do ponto de extremidade privado.
Navegue até a sua conta de armazenamento no portal do Azure e, na página Rede>Conexões de ponto de extremidade privado, selecione a conexão provisionada e Aprovar.