Tutorial: Criar um aplicativo de aprendizado de máquina com o Apache Spark MLlib e o Azure Synapse Analytics
Neste artigo, você vai saber como usar a MLlib do Apache Spark para criar um aplicativo de machine learning que faz uma análise preditiva simples em um conjunto de dados em aberto do Azure. O Spark fornece bibliotecas de aprendizado de máquina integradas. Este exemplo usa classificação por meio de regressão logística.
O SparkML e o MLlib são bibliotecas básicas do Spark que fornecem muitos utilitários úteis para tarefas de machine learning, incluindo utilitários adequados para:
- classificação
- Regressão
- Clustering
- Modelagem de tópico
- Decomposição de valor singular (SVD) e análise de componente principal (PCA)
- Teste de hipótese e cálculo de estatísticas de exemplo
Compreender a classificação e regressão logística
Classificação, uma tarefa popular de aprendizado de máquina, é o processo de classificação de dados de entrada em categorias. É o trabalho de um algoritmo de classificação para descobrir como atribuir rótulos a dados de entrada que você fornece. Por exemplo, você pode pensar em um algoritmo de machine learning que aceite informações sobre estoque como entrada e divida o estoque em duas categorias: estoque que você deve vender e estoque que deve ser mantido.
Regressão logística é um algoritmo que você pode usar para classificação. A API de regressão logística do Spark é útil para classificação bináriaou para classificação de dados de entrada em um dos dois grupos. Para obter mais informações sobre a regressão logística, confira a Wikipédia.
Em resumo, o processo de regressão logística produz uma função logística que pode ser usada para prever a probabilidade de um vetor de entrada pertencer a um grupo ou outro.
Exemplo de análise preditiva em dados de táxi de Nova York
Neste exemplo, você usa o Spark para realizar uma análise preditiva nos dados de gorjeta das corridas de táxi de Nova York. Os dados estão disponíveis por meio dos Conjuntos de Dados em Aberto no Azure. Esse subconjunto do conjunto de dados contém informações sobre as corridas de táxi amarelo, incluindo informações sobre cada corrida, a hora de início e de término e os locais, o custo e outros atributos interessantes.
Importante
Pode haver encargos adicionais para a extração desses dados no local de armazenamento.
Nas etapas a seguir, você desenvolverá um modelo para prever se uma corrida específica inclui uma gorjeta ou não.
Criar um modelo de machine learning do Apache Spark
Crie um notebook usando o kernel do PySpark. Para obter instruções, confira Criar um notebook.
Importe os tipos obrigatórios necessários para este aplicativo. Copie e cole o código a seguir em uma célula vazia e pressione Shift+Enter. Alternativamente, execute a célula usando o ícone de reprodução azul à esquerda do código.
import matplotlib.pyplot as plt from datetime import datetime from dateutil import parser from pyspark.sql.functions import unix_timestamp, date_format, col, when from pyspark.ml import Pipeline from pyspark.ml import PipelineModel from pyspark.ml.feature import RFormula from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorIndexer from pyspark.ml.classification import LogisticRegression from pyspark.mllib.evaluation import BinaryClassificationMetrics from pyspark.ml.evaluation import BinaryClassificationEvaluatorPor causa do kernel do PySpark, não será necessário criar nenhum contexto explicitamente. O contexto do Spark é criado automaticamente para você ao executar a primeira célula do código.
Construir o DataFrame de entrada
Como os dados brutos estão no formato Parquet, você pode usar o contexto do Spark para extrair o arquivo diretamente na memória como um DataFrame. Embora o código nas etapas a seguir use as opções padrão, é possível forçar o mapeamento dos tipos de dados e outros atributos de esquema, se necessário.
Execute as linhas a seguir para criar um DataFrame do Spark, colando o código em uma nova célula. Essa etapa recupera os dados por meio da API do Conjunto de Dados em Aberto no Azure. A extração de todos esses dados gera cerca de 1,5 bilhão de linhas.
Dependendo do tamanho do Pool do Apache Spark sem servidor, os dados brutos podem ser muito grandes ou levar muito tempo para serem operados. Você pode filtrar esses dados para um volume menor. O exemplo de código a seguir usa
start_dateeend_datepara aplicar um filtro que retorna um mês de dados.from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())A desvantagem da filtragem simples é que, de uma perspectiva estatística, ela pode introduzir desvio nos dados. Outra abordagem é usar a amostragem incorporada ao Spark.
O código a seguir reduz o conjunto de dados para cerca de duas mil linhas, se aplicado após o código acima. Essa etapa de amostragem pode ser usada em vez do filtro simples ou em conjunto com o filtro simples.
# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234)Já é possível examinar os dados para ver o que foi lido. Normalmente, é melhor examinar os dados com um subconjunto em vez do conjunto completo, dependendo do tamanho do conjunto de dados.
O código a seguir oferece duas maneiras de exibir os dados. A primeira maneira é básica. A segunda maneira fornece uma experiência de grade muito mais avançada, juntamente com a capacidade de visualizar os dados graficamente.
#sampled_taxi_df.show(5) display(sampled_taxi_df)Dependendo do tamanho do conjunto de dados gerado e da necessidade de experimentar ou executar o notebook muitas vezes, pode ser aconselhável armazenar em cache o conjunto de dados localmente no workspace. Há três maneiras de realizar o armazenamento em cache explícito:
- Salvar o DataFrame localmente como um arquivo.
- Salvar o DataFrame como tabela ou exibição temporária.
- Salvar o DataFrame como tabela permanente.
As duas primeiras abordagens estão inclusas nos exemplos de código a seguir.
A criação de uma tabela ou exibição temporária fornece caminhos de acesso diferentes para os dados, mas só funciona durante a sessão de instância do Spark.
sampled_taxi_df.createOrReplaceTempView("nytaxi")
Preparar os dados
Os dados em forma bruta geralmente não são adequados para serem passados diretamente para um modelo. É necessário realizar uma série de ações nos dados para que eles cheguem a um estado em que possam ser utilizados pelo modelo.
No seguinte código, você executa quatro classes de operações:
- A remoção de exceções/valores incorretos por meio da filtragem.
- A remoção de colunas que não são necessárias.
- A criação de colunas derivadas dos dados brutos para fazer com que o modelo funcione com mais eficiência. Essa operação às vezes é chamada de definição de recursos.
- Rotulagem. Já que você está realizando classificação binária (haverá gorjeta ou não em determinada corrida), é necessário converter o valor das gorjetas em um valor 0 ou 1.
taxi_df = sampled_taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\
, 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\
, date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\
, date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\
, (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\
, (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped')
)\
.filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\
& (sampled_taxi_df.tipAmount >= 0) & (sampled_taxi_df.tipAmount <= 25)\
& (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\
& (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\
& (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 100)\
& (sampled_taxi_df.rateCodeId <= 5)
& (sampled_taxi_df.paymentType.isin({"1", "2"}))
)
Em seguida, uma segunda passagem é feita sobre os dados para adicionar os recursos finais.
taxi_featurised_df = taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'passengerCount'\
, 'tripDistance', 'weekdayString', 'pickupHour','tripTimeSecs','tipped'\
, when((taxi_df.pickupHour <= 6) | (taxi_df.pickupHour >= 20),"Night")\
.when((taxi_df.pickupHour >= 7) & (taxi_df.pickupHour <= 10), "AMRush")\
.when((taxi_df.pickupHour >= 11) & (taxi_df.pickupHour <= 15), "Afternoon")\
.when((taxi_df.pickupHour >= 16) & (taxi_df.pickupHour <= 19), "PMRush")\
.otherwise(0).alias('trafficTimeBins')
)\
.filter((taxi_df.tripTimeSecs >= 30) & (taxi_df.tripTimeSecs <= 7200))
Criar um modelo de regressão logística
A tarefa final é converter os dados rotulados para um formato que possa ser analisado pela regressão logística. A entrada para um algoritmo de regressão logística precisa ser um conjunto de pares de vetor de recurso de rótulo, em que o vetor de recurso é um vetor de números que representa o ponto de entrada.
Portanto, é necessário converter as colunas categóricas em números. Especificamente, as colunas trafficTimeBins e weekdayString precisam ser convertidas em representações de inteiros. Há várias abordagens para executar a conversão. O exemplo a seguir usa a abordagem OneHotEncoder, que é comum.
# Because the sample uses an algorithm that works only with numeric features, convert them so they can be consumed
sI1 = StringIndexer(inputCol="trafficTimeBins", outputCol="trafficTimeBinsIndex")
en1 = OneHotEncoder(dropLast=False, inputCol="trafficTimeBinsIndex", outputCol="trafficTimeBinsVec")
sI2 = StringIndexer(inputCol="weekdayString", outputCol="weekdayIndex")
en2 = OneHotEncoder(dropLast=False, inputCol="weekdayIndex", outputCol="weekdayVec")
# Create a new DataFrame that has had the encodings applied
encoded_final_df = Pipeline(stages=[sI1, en1, sI2, en2]).fit(taxi_featurised_df).transform(taxi_featurised_df)
Essa ação resulta em um novo DataFrame com todas as colunas no formato certo para treinar um modelo.
Treinar um modelo de regressão logística
A primeira tarefa é dividir o conjunto de dados em um conjunto de treinamento e um conjunto de teste ou validação. A divisão aqui é arbitrária. Experimente diferentes configurações de divisão para ver se elas afetam o modelo.
# Decide on the split between training and testing data from the DataFrame
trainingFraction = 0.7
testingFraction = (1-trainingFraction)
seed = 1234
# Split the DataFrame into test and training DataFrames
train_data_df, test_data_df = encoded_final_df.randomSplit([trainingFraction, testingFraction], seed=seed)
Agora que há dois DataFrames, a próxima tarefa é criar a fórmula do modelo e executá-la no DataFrame de treinamento. Em seguida, você pode validá-lo em relação ao DataFrame de teste. Faça experiências com versões diferentes da fórmula do modelo para ver o impacto de diferentes combinações.
Observação
Para salvar o modelo, atribua a função Colaborador de Dados do Blob de Armazenamento ao escopo do recursos do servidor do Banco de Dados SQL do Azure. Para ver as etapas detalhadas, confira Atribuir funções do Azure usando o portal do Azure. Somente membros com os privilégios de proprietário podem executar essa etapa.
## Create a new logistic regression object for the model
logReg = LogisticRegression(maxIter=10, regParam=0.3, labelCol = 'tipped')
## The formula for the model
classFormula = RFormula(formula="tipped ~ pickupHour + weekdayVec + passengerCount + tripTimeSecs + tripDistance + fareAmount + paymentType+ trafficTimeBinsVec")
## Undertake training and create a logistic regression model
lrModel = Pipeline(stages=[classFormula, logReg]).fit(train_data_df)
## Saving the model is optional, but it's another form of inter-session cache
datestamp = datetime.now().strftime('%m-%d-%Y-%s')
fileName = "lrModel_" + datestamp
logRegDirfilename = fileName
lrModel.save(logRegDirfilename)
## Predict tip 1/0 (yes/no) on the test dataset; evaluation using area under ROC
predictions = lrModel.transform(test_data_df)
predictionAndLabels = predictions.select("label","prediction").rdd
metrics = BinaryClassificationMetrics(predictionAndLabels)
print("Area under ROC = %s" % metrics.areaUnderROC)
A saída desta célula é:
Area under ROC = 0.9779470729751403
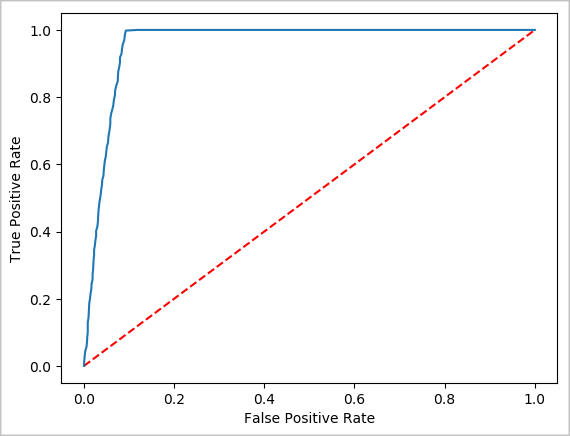
Criar uma representação visual da previsão
Agora você pode construir uma visualização final para ajudar a justificar os resultados deste teste. Uma curva ROC é uma forma de examinar o resultado.
## Plot the ROC curve; no need for pandas, because this uses the modelSummary object
modelSummary = lrModel.stages[-1].summary
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(modelSummary.roc.select('FPR').collect(),
modelSummary.roc.select('TPR').collect())
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
Desligar a instância do Spark
Depois de concluir a execução do aplicativo, encerre o notebook fechando a guia para liberar os recursos. Alternativamente, selecione Encerrar Sessão na barra de status na parte inferior do notebook.