Início rápido: transformar dados usando a definição de trabalho do Apache Spark
Neste início rápido, você usará o Azure Synapse Analytics para criar um pipeline usando a definição de trabalho do Apache Spark.
Pré-requisitos
- Assinatura do Azure: Caso você não tenha uma assinatura do Azure, crie uma conta gratuita do Azure antes de começar.
- Workspace do Azure Synapse: crie um workspac do Azure Synapse usando o portal do Azure e seguindo as instruções no guia de Início Rápido: criar um workspace do Synapse.
- Definição de trabalho do Apache Spark: crie uma definição de trabalho do Apache Spark no espaço de trabalho do Synapse seguindo as instruções em Tutorial: criar uma definição de trabalho do Apache Spark no Synapse Studio.
Navegar até o Synapse Studio
Após criar o workspace do Azure Synapse, você tem duas maneiras de abrir o Synapse Studio:
- Abra o workspace do Synapse no portal do Azure. Selecione Abrir no cartão Abrir o Synapse Studio em Introdução.
- Abra o Azure Synapse Analytics e entre no seu workspace.
Neste guia de início rápido, usamos o espaço de trabalho chamado "sampletest" como um exemplo.
Criar um pipeline com uma definição de trabalho do Apache Spark
Um pipeline contém o fluxo lógico para uma execução de um conjunto de atividades. Nesta seção, você criará um pipeline que contém uma atividade de definição de trabalho do Apache Spark.
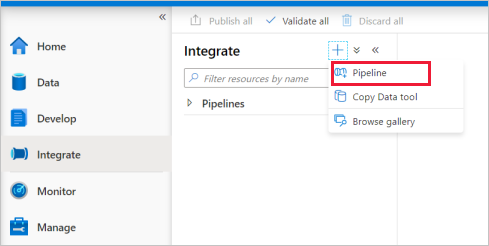
Vá até a guia Integrar. Selecione o ícone de adição ao lado do cabeçalho de pipelines e selecione Pipeline.
Na página de configurações de Propriedades do pipeline, digite demo para Nome.
Em Synapse no painel Atividades, arraste Definição de trabalho do Spark para a tela do pipeline.
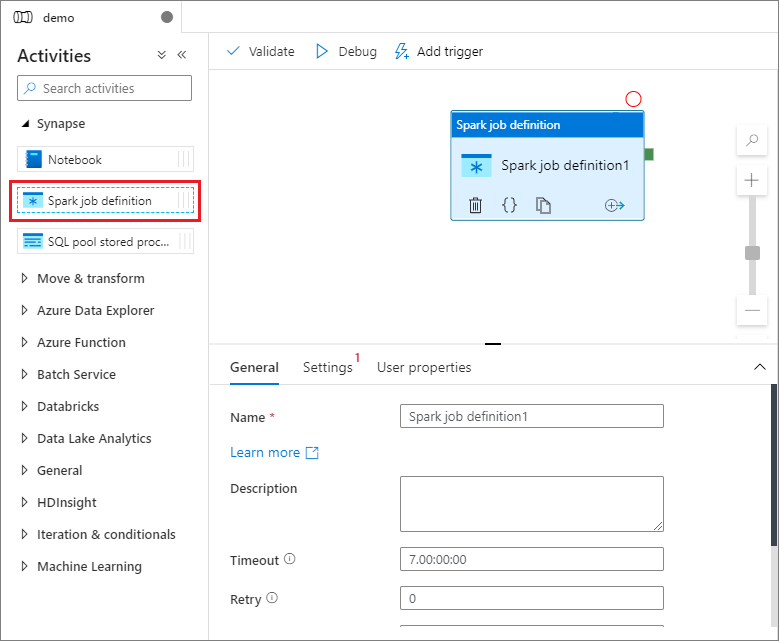
Tela de configuração da definição de trabalho do Apache Spark
Depois de criar sua definição de trabalho do Apache Spark, você será enviado automaticamente para a tela de definição de trabalho do Spark.
Configurações gerais
Selecione o módulo de definição de trabalho do Spark na tela.
Na guia Geral, insira exemplo para Nome.
(Opção) Também é possível inserir uma descrição.
Tempo limite: a quantidade máxima de tempo de execução de uma atividade. O padrão é sete dias, que também é a quantidade máxima de tempo permitido. O formato está em D.HH:MM:SS.
Novas tentativas: o número máximo de novas tentativas.
Intervalo de novas tentativas: o número de segundos entre cada nova tentativa.
Saída segura: quando marcada, a saída da atividade não é capturada no log.
Entrada segura: quando marcada, a entrada da atividade não é capturada no registro em log.
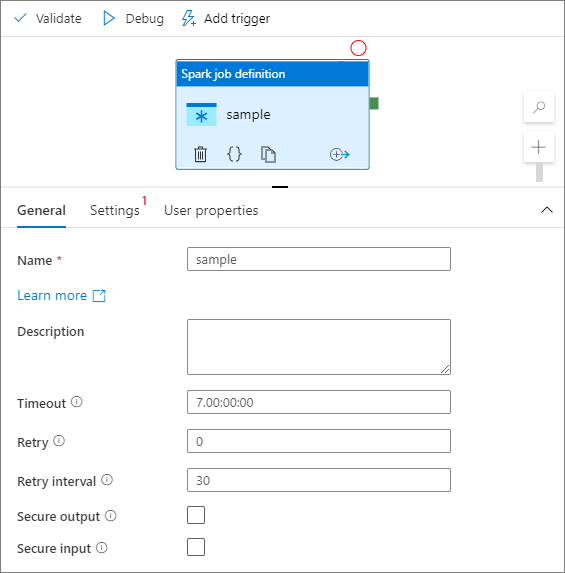
Guia Configurações
Neste painel, você pode fazer referência à definição de trabalho do Spark que será executada.
Expanda a lista de definições de trabalho do Spark para escolher uma definição de trabalho existente do Apache Spark. Você também pode criar uma definição de trabalho do Apache Spark selecionando o botão Novo para fazer referência à definição de trabalho do Spark que será executada.
(Opcional) Você pode preencher informações para a definição de trabalho do Apache Spark. Se as configurações a seguir estiverem vazias, as configurações da própria definição de trabalho do Spark serão usadas para execução; se as configurações a seguir não estiverem vazias, essas configurações substituirão as configurações da própria definição de trabalho do Spark.
Propriedade Descrição Arquivo de definição principal O arquivo principal usado para o trabalho. Selecione um arquivo ZIP/PY/JAR no armazenamento. Você pode selecionar Carregar arquivo para carregar o arquivo em uma conta de armazenamento.
Exemplo:abfss://…/path/to/wordcount.jarReferências de subpastas Verificando subpastas da pasta raiz do arquivo de definição principal, esses arquivos são adicionados como arquivos de referência. As pastas chamadas "jars", "pyFiles", "files" ou "archives" são verificadas e o nome das pastas diferencia maiúsculas de minúsculas. Nome da classe principal O identificador totalmente qualificado ou a classe principal que está no arquivo de definição principal.
Exemplo:WordCountArgumentos de linha de comando É possível adicionar argumentos de linha de comando clicando no botão Novo. Deve-se observar que a adição de argumentos de linha de comando substitui os argumentos de linha de comando definidos pela definição de trabalho do Spark.
Exemplo:abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultPool do Apache Spark Você pode selecionar o pool do Apache Spark na lista. Referência de código Python Outros arquivos de código Python usados para referência no arquivo de definição principal.
Ele dá suporte à transmissão de arquivos (.py, .py3, .zip) para a propriedade "pyFiles". Ele substitui a propriedade "pyFiles" definida na definição de trabalho do Spark.Arquivos de referência Outros arquivos usados para referência no arquivo de definição principal. Alocar executores dinamicamente Esta configuração é mapeada para a propriedade de alocação dinâmica na configuração do Spark para a alocação de executores do Aplicativo Spark. Mínimo de executores Número mínimo de executores a serem alocados no Pool do Spark especificado para o trabalho. Máximo de executores Número máximo de executores a serem alocados no Pool do Spark especificado para o trabalho. Tamanho do driver Número de núcleos e memória a serem usados para o driver fornecido no pool do Apache Spark especificado para o trabalho. Configuração do Apache Spark Especifique valores para propriedades de configuração do Spark listadas no artigo: Configuração do Spark – Propriedades de aplicativo. Os usuários podem usar a configuração padrão e a configuração personalizada. 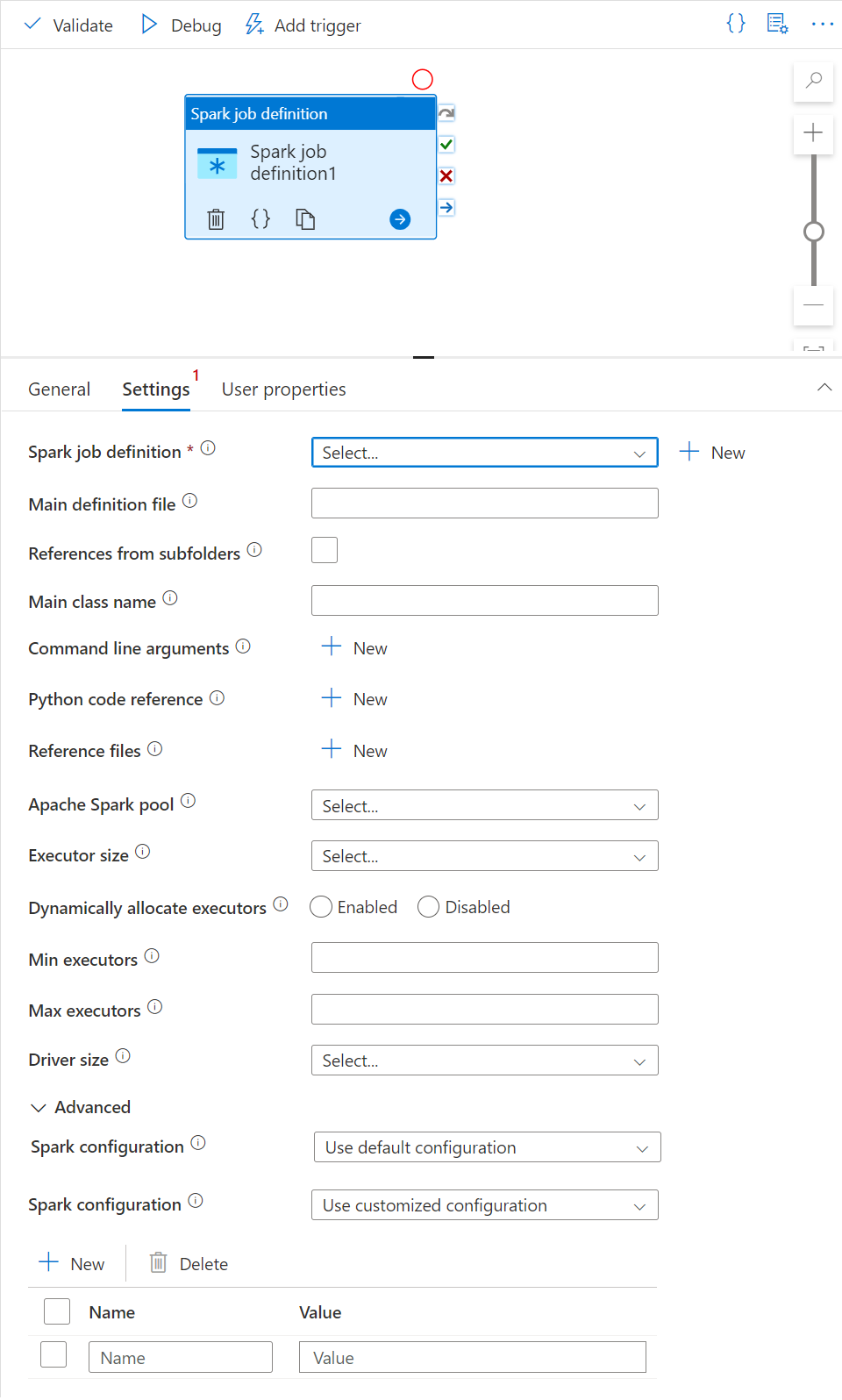
Você pode adicionar conteúdo dinâmico clicando no botão Adicionar conteúdo dinâmico ou pressionando a tecla de atalho Alt+Shift+D. Na página Adicionar conteúdo dinâmico, você pode usar qualquer combinação de expressões, funções e variáveis de sistema para adicionar ao conteúdo dinâmico.
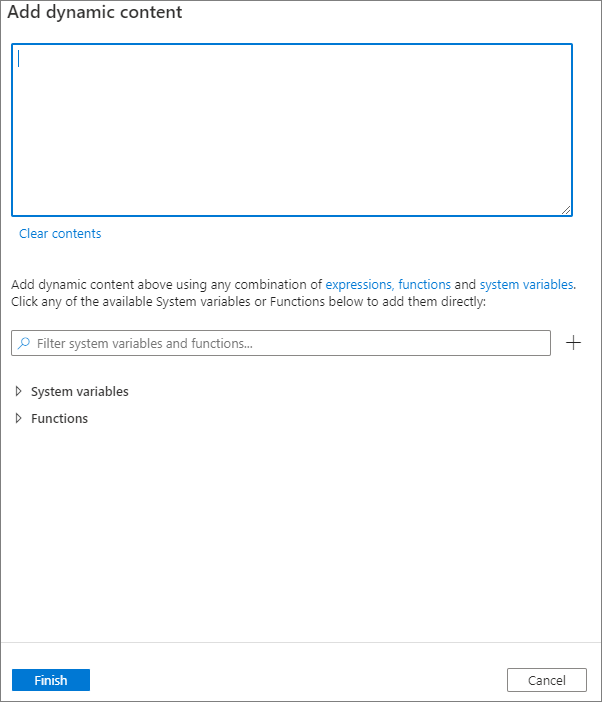
Guia de propriedades do usuário
Você pode adicionar propriedades para a atividade de definição de trabalho do Apache Spark neste painel.

Conteúdo relacionado
Vá para os seguintes artigos para saber mais sobre o suporte do Azure Synapse Analytics: