Migração de dados, ETL e carregamento para migrações do Teradata
Este artigo é a segunda parte de uma série de sete partes que fornece orientação sobre como migrar do Teradata para Azure Synapse Analytics. O foco deste artigo são as melhores práticas para ETL e migração de carga.
Considerações sobre migração de dados
Decisões iniciais para migração de dados do Teradata
Ao migrar um data warehouse do Teradata, você precisa fazer algumas perguntas básicas relacionadas a dados. Por exemplo:
As estruturas de tabela não utilizadas devem ser migradas?
Qual é a melhor abordagem de migração para minimizar o risco e o impacto sobre os usuários?
Quando migrar data marts — continuar no físico ou usar o virtual?
As próximas seções discutem esses pontos dentro do contexto de migração do Teradata.
Migrar tabelas não utilizadas?
Dica
Em sistemas herdados, não é incomum que as tabelas se tornem redundantes com o tempo.Na maioria dos casos, não é necessário migrá-las.
Faz sentido migrar apenas as tabelas que estão em uso no sistema existente. As tabelas que não estão ativas podem ser arquivadas em vez de migradas, de modo que os dados fiquem disponíveis, para o caso de serem necessários no futuro. É melhor usar os metadados do sistema e os arquivos de log em vez da documentação para determinar quais tabelas estão em uso, pois a documentação pode estar desatualizada.
Se habilitadas, as tabelas e logs de catálogo do sistema Teradata conterão informações que podem determinar quando uma certa tabela foi acessada pela última vez, o que, por sua vez, pode ser usado para decidir se uma tabela é candidata à migração.
Confira um exemplo de consulta de DBC.Tables que fornece a data do último acesso e a última modificação:
SELECT TableName, CreatorName, CreateTimeStamp, LastAlterName,
LastAlterTimeStamp, AccessCount, LastAccessTimeStamp
FROM DBC.Tables t
WHERE DataBaseName = 'databasename'
Se o registro em log estiver habilitado e o histórico de logs estiver acessível, outras informações, como texto de consulta SQL, estarão disponíveis na tabela DBQLogTbl e nas tabelas de log associadas. Para saber mais, confira o histórico de logs do Teradata.
Qual é a melhor abordagem de migração para minimizar o risco e o impacto sobre os usuários?
Esta questão surge com frequência porque as empresas podem querer diminuir o impacto das mudanças no modelo de dados de data warehouse para melhorar a agilidade. As empresas frequentemente veem uma oportunidade de modernizar ou transformar ainda mais seus dados durante uma migração ETL. Esta abordagem carrega um risco maior porque muda múltiplos fatores simultaneamente, tornando difícil comparar os resultados do sistema antigo com o novo. Fazer alterações no modelo de dados aqui também pode afetar os trabalhos de ETL upstream ou downstream para outros sistemas. Devido a esse risco, é melhor redesenhar nesta escala após a migração do data warehouse.
Mesmo que um modelo de dados seja alterado intencionalmente como parte da migração geral, é uma boa prática migrar o modelo existente como está para a Azure Synapse, em vez de fazer qualquer reengenharia na nova plataforma. Esta abordagem minimiza o efeito nos sistemas de produção existentes, enquanto se beneficia do desempenho e da escalabilidade elástica da plataforma Azure para tarefas pontuais de reengenharia.
Ao migrar de Teradata, considere a criação de um ambiente Teradata em uma VM dentro do Azure como um trampolim no processo de migração.
Dica
Inicialmente, migre o modelo existente como está, mesmo que haja um plano de alteração do modelo de dados no futuro.
Usar uma instância do Teradata para VM como parte da migração
Uma abordagem opcional para migrar de um ambiente Teradata local é aproveitar o ambiente do Azure para criar uma instância do Teradata em uma VM no Azure, colocada com o ambiente de destino do Azure Synapse. Isso é possível porque o Azure fornece armazenamento em nuvem barato e escalabilidade elástica.
Com essa abordagem, utilitários padrão do Teradata, como o Teradata Parallel Data Transporter (ou ferramentas de replicação de dados de terceiros, como o Attunity Replicate) podem ser usados para mover com eficiência o subconjunto de tabelas do Teradata que deve ser migrado para a instância da VM. Em seguida, todas as tarefas de migração podem ocorrer no ambiente do Azure. Essa abordagem tem vários benefícios:
Após a replicação inicial dos dados, as tarefas de migração não afetam o sistema de origem.
Há interfaces, ferramentas e utilitários conhecidos do Teradata disponíveis no ambiente do Azure.
O ambiente do Azure fornece disponibilidade de largura de banda de rede entre o sistema de origem local e o sistema de destino na nuvem.
Ferramentas como o Azure Data Factory podem chamar utilitários como o Teradata Parallel Transporter de maneira eficiente para migrar dados de forma rápida e fácil.
O processo de migração é orquestrado e controlado inteiramente no ambiente do Azure.
Quando migrar data marts — continuar no físico ou usar o virtual?
Dica
A virtualização de data marts pode economizar recursos de armazenamento e de processamento.
Em ambientes herdados de data warehouse do Teradata, é comum criar vários data marts estruturados para fornecer um bom desempenho para consultas e relatórios de autoatendimento ad hoc para um certo departamento ou função comercial em uma organização. Dessa forma, um data mart normalmente é composto por um subconjunto do data warehouse e contém versões agregadas dos dados em um formulário que permite que os usuários consultem facilmente esses dados, com tempos de resposta rápidos e por meio de ferramentas de consulta simples de usar, como o Microsoft Power BI, o Tableau ou o MicroStrategy. Esse formulário costuma ser um modelo de dados dimensional. Uma das utilizações dos data marts é expor os dados em um formato utilizável, mesmo que o modelo de dados do warehouse subjacente seja um pouco diferente, como um cofre de dados.
É possível usar data marts separados para unidades de negócio individuais de uma organização a fim de implementar regimes robustos de segurança de dados, permitindo que os usuários acessem apenas os data marts específicos relevantes a eles e eliminando, ofuscando ou anonimizando dados confidenciais.
Se esses data marts forem implementados como tabelas físicas, exigirão recursos de armazenamento adicionais e mais processamento para compilá-los e atualizá-los regularmente. Além disso, o nível de atualização dos dados no mart corresponderá à última operação de atualização e, portanto, podem ser inadequados para painéis de dados altamente voláteis.
Dica
O desempenho e a escalabilidade do Azure Synapse permitem a virtualização sem sacrificar o desempenho.
Com o advento de arquiteturas MPP escalonáveis de custo relativamente baixo, como o Azure Synapse, e com as características inerentes de desempenho dessas arquiteturas, talvez você possa fornecer funcionalidade de data mart sem precisar instanciar o mart como um conjunto de tabelas físicas. Isso é feito virtualizando efetivamente os data marts por meio de exibições SQL no data warehouse principal ou por meio de uma camada de virtualização usando recursos como exibições no Azure ou os produtos de visualização de parceiros da Microsoft. Essa abordagem simplifica ou elimina a necessidade de processamento adicional de armazenamento e agregação e reduz o número geral de objetos de banco de dados a serem migrados.
Há outro benefício potencial para essa abordagem. Ao implementar a agregação e lógica de junção em uma camada de virtualização e apresentar ferramentas de relatórios externos por meio de uma visualização virtualizada, o processamento necessário para criar essas visualizações é "empurrado" para o warehouse de dados, que geralmente é o melhor local para executar associações, agregações e outras operações relacionadas em grandes volumes de dados.
Os principais motivadores para escolher uma implementação de data mart virtual em vez de um data mart físico são:
Mais agilidade: um data mart virtual é mais fácil de mudar do que tabelas físicas e os processos ETL associados.
Menor custo total de propriedade: uma implementação virtualizada requer menos armazenamentos de dados e cópias de dados.
Eliminação de trabalhos de ETL para migrar e simplificar a arquitetura de data warehouse em um ambiente virtualizado.
Desempenho: embora os data marts físicos tenham historicamente mais desempenho, os produtos de virtualização agora implementam técnicas de armazenamento em cache inteligentes para mitigar.
Migração de dados do Teradata
Entender seus dados
Parte do planejamento de migração é entender detalhadamente o volume de dados que precisa ser migrado, pois isso pode afetar as decisões sobre a abordagem de migração. Use os metadados do sistema para determinar o espaço físico ocupado pelos "dados brutos" nas tabelas a serem migradas. Nesse contexto, "dados brutos" representam a quantidade de espaço usado pelas linhas de dados dentro de uma tabela, excluindo sobrecargas como índices e compactação. Isso é especialmente verdadeiro para as maiores tabelas de fatos, pois elas normalmente abrangem mais de 95% dos dados.
Você pode obter um número preciso do volume de dados a ser migrado para uma determinada tabela extraindo uma amostra representativa dos dados — por exemplo, um milhão de linhas — para um arquivo de dados ASCII simples delimitado não compactado. Em seguida, use o tamanho desse arquivo para obter um tamanho médio de dados brutos por linha dessa tabela. Por fim, multiplique esse tamanho médio pelo número total de linhas na tabela completa para dar um tamanho dados brutos para a tabela. Use esse tamanho de dados brutos em seu planejamento.
Considerações sobre a migração de ETL
Decisões iniciais sobre a migração de ETL do Teradata
Dica
Planeje a abordagem para a migração de ETL com antecedência e aproveite as instalações do Azure quando apropriado.
Para processamento ETL/ELT, os data warehouses do Teradata herdados podem usar scripts personalizados com os utilitários teradata, como BTEQ e Teradata Parallel Transporter (TPT), ou ferramentas ETL de terceiros, como Informatica ou Ab Initio. Às vezes, os data warehouses do Teradata usam uma combinação de abordagens ETL e ELT que evoluíram ao longo do tempo. Ao planejar uma migração para Azure Synapse, você precisa determinar a melhor maneira de implementar o processamento ETL/ELT necessário no novo ambiente, minimizando o custo e o risco envolvidos. Para saber mais sobre o processamento de ETL e ELT, confira a abordagem de design ELT versus ETL.
As seções a seguir discutem as opções de migração e fazem recomendações para vários casos de uso. Esse fluxograma resume uma abordagem:
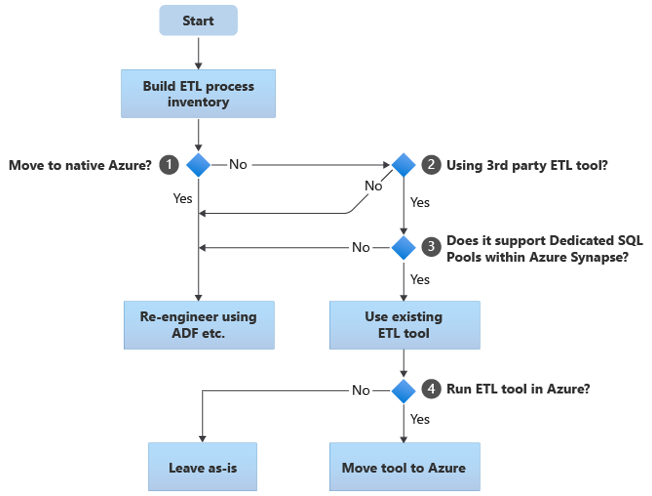
A primeira etapa é sempre criar um inventário de processos ETL/ELT que precisam ser migrados. Assim como em outras etapas, é possível que os recursos padrão "internos" do Azure tornem desnecessária a migração de alguns processos existentes. Para fins de planejamento, é importante entender a escala da migração a ser executada.
No fluxograma anterior, a decisão 1 está relacionada a uma decisão de alto nível sobre a migração para um ambiente totalmente nativo do Azure. Se você estiver migrando para um ambiente totalmente nativo do Azure, recomendamos que você reprojete o processamento de ETL usando Pipelines e atividades no Azure Data Factory ou em Pipelines do Azure Synapse. Se você não estiver migrando para um ambiente totalmente nativo do Azure, a decisão 2 será a verificação do uso de uma ferramenta ETL de terceiros existente.
No ambiente do Teradata, parte ou todo o processamento de ETL pode ser executado por scripts personalizados usando utilitários específicos do Teradata, como BTEQ e TPT. Nesse caso, sua abordagem deve ser reprojetar usando o Data Factory.
Dica
Aproveite o investimento em ferramentas de terceiros existentes para reduzir o custo e o risco.
Se uma ferramenta ETL de terceiros já estiver em uso e, principalmente, se houver um grande investimento em habilidades ou se vários fluxos de trabalho e agendamentos existentes usarem essa ferramenta, a decisão 3 será verificar se a ferramenta pode dar suporte eficiente ao Azure Synapse como um ambiente de destino. Idealmente, a ferramenta incluirá conectores "nativos" que podem aproveitar os recursos do Azure, como PolyBase ou COPY INTO, para o carregamento de dados mais eficiente. Há uma maneira de chamar um processo externo, como PolyBase ou COPY INTO, e passar os parâmetros apropriados. Nesse caso, aproveite as habilidades e os fluxos de trabalho existentes, com o Azure Synapse como o novo ambiente de destino.
Se você decidir manter uma ferramenta de ETL de terceiros existente, talvez haja benefícios na execução dessa ferramenta dentro do ambiente do Azure (em vez de em um servidor ETL local existente) e fazer o Azure Data Factory lidar com a orquestração geral dos fluxos de trabalho existentes. Um benefício específico é que menos dados precisam ser baixados do Azure, processados e carregados novamente no Azure. Portanto, a decisão 4 é se você vai deixar a ferramenta existente em execução como está ou se vai movê-la para o ambiente do Azure, a fim de obter benefícios de custo, desempenho e escalabilidade.
Reprojetar scripts específicos do Teradata existentes
Se parte ou todo o processamento existente de ETL/ELT do warehouse do Teradata for tratado por scripts personalizados que usam utilitários específicos do Teradata, como BTEQ, MLOAD ou TPT, esses scripts precisarão ser recodificados para o novo ambiente do Azure Synapse. Da mesma forma, se os processos de ETL foram implementados usando procedimentos armazenados no Teradata, eles também precisarão ser recodificados.
Dica
O inventário de tarefas de ETL a serem migradas deve incluir scripts e procedimentos armazenados.
Alguns elementos do processo de ETL são fáceis de migrar, por exemplo, por carregamento simples de dados em massa em uma tabela de preparo de um arquivo externo. Pode até ser possível automatizar essas partes do processo, por exemplo, usando o PolyBase em vez de carregamento rápido ou MLOAD. Se os arquivos exportados forem Parquet, você poderá usar um leitor Parquet nativo, que é uma opção mais rápida que o PolyBase. Outras partes do processo que contêm SQL arbitrário complexo e/ou procedimentos armazenados levarão mais tempo para serem reprojetados.
Uma forma de testar a compatibilidade do Teradata SQL com o Azure Synapse é capturar algumas instruções SQL representativas dos logs do Teradata, prefixar essas consultas com EXPLAIN e, considerando um modelo de dados migrado por semelhança no Azure Synapse, executar essas instruções EXPLAIN no Azure Synapse. Qualquer SQL incompatível gerará um erro e as informações de erro podem determinar a escala da tarefa de recodificação.
Parceiros da Microsoft oferecem ferramentas e serviços para migrar o Teradata SQL e procedimentos armazenados para o Azure Synapse.
Usar ferramentas ETL de terceiros
Conforme descrito na seção anterior, em muitos casos, o sistema de data warehouse herdado existente já será preenchido e mantido por produtos ETL de terceiros. Para obter uma lista de parceiros de integração de dados da Microsoft para Azure Synapse, confira Parceiros de integração de dados.
Carregamento de dados do Teradata
Opções disponíveis ao carregar dados do Teradata
Dica
Ferramentas de terceiros podem simplificar e automatizar o processo de migração e, portanto, reduzir riscos.
Quando se trata de migrar dados de um data warehouse Teradata, há algumas questões básicas associadas ao carregamento de dados que precisam ser resolvidas. Você precisará decidir como os dados serão movidos fisicamente do ambiente do Teradata local existente para o Azure Synapse na nuvem, e quais ferramentas serão usadas para executar a transferência e o carregamento. Considere as perguntas a seguir, que serão discutidas nas próximas seções.
Você extrairá os dados para arquivos ou os moverá diretamente por meio de uma conexão de rede?
Você orquestrará o processo do sistema de origem ou do ambiente de destino do Azure?
Quais ferramentas você usará para automatizar e gerenciar o processo?
Transferir dados por meio de arquivos ou conexão de rede?
Dica
Entenda os volumes de dados a serem migrados e a largura de banda de rede disponível, pois esses fatores influenciam a decisão sobre como conduzir a migração.
Depois que as tabelas de banco de dados a serem migradas forem criadas no Azure Synapse, você poderá mover os dados para preencher essas tabelas fora do sistema Teradata herdado e para o novo ambiente. Há duas abordagens básicas:
Extração de arquivo: extraia os dados das tabelas do Teradata para arquivos simples, normalmente em formato CSV, por meio de BTEQ, Exportação Rápida ou TPT (Teradata Parallel Transporter). Use o TPT sempre que possível, pois é o mais eficiente em termos de taxa de transferência de dados.
Essa abordagem exige espaço para guardar os arquivos de dados extraídos. O espaço pode ser local para o banco de dados de origem do Teradata (se houver armazenamento suficiente disponível) ou remoto no Armazenamento de Blobs do Azure. O melhor desempenho é obtido quando um arquivo é gravado localmente, pois isso evita a sobrecarga de rede.
Para minimizar os requisitos de armazenamento e transferência de rede, é uma boa prática compactar os arquivos de dados extraídos usando um utilitário como gzip.
Depois de extraídos, os arquivos simples podem ser movidos para o Armazenamento de Blobs do Azure (colocados com a instância do Azure Synapse de destino) ou carregados diretamente no Azure Synapse usando PolyBase ou COPY INTO. O método para transferência física de dados do armazenamento local para o ambiente em nuvem do Azure depende da quantidade de dados e da largura de banda de rede disponível.
A Microsoft fornece opções diferentes para mover grandes volumes de dados, incluindo o AZCopy para mover arquivos pela rede para o Armazenamento do Azure, o Azure ExpressRoute para mover dados em massa em uma conexão de rede privada e o Azure Data Box, para onde os arquivos são transferidos em um dispositivo de armazenamento físico que é enviado para um data center do Azure para carregamento. Para saber mais, confira transferência de dados.
Extração e carregamento direto pela rede: o ambiente de destino do Azure envia uma solicitação de extração de dados, normalmente por meio de um comando SQL, para o sistema herdado do Teradata para extração dos dados. Os resultados são enviados pela rede e carregados diretamente no Azure Synapse, sem a necessidade de "guardar" os dados em arquivos intermediários. O fator limitante nesse cenário normalmente é a largura de banda da conexão de rede entre o banco de dados do Teradata e o ambiente do Azure. Para volumes de dados muito grandes, talvez essa abordagem não seja prática.
Há também uma abordagem híbrida que usa os dois métodos. Por exemplo, você pode usar a abordagem de extração de rede direta para tabelas de dimensões menores e exemplos das tabelas de fatos maiores para fornecer rapidamente um ambiente de teste no Azure Synapse. Para as tabelas de fatos históricos de grande volume, é possível usar a abordagem de extração e transferência de arquivo usando o Azure Data Box.
Orquestrar do Teradata ou do Azure?
A abordagem recomendada ao mover para o Azure Synapse é orquestrar a extração e o carregamento de dados do ambiente do Azure usando Pipelines do Azure Synapse ou o Azure Data Factory, bem como utilitários associados, como PolyBase ou COPY INTO, para um carregamento de dados mais eficiente. Essa abordagem aproveita os recursos do Azure e fornece um método fácil para criar pipelines de carregamento de dados reutilizáveis.
Outros benefícios dessa abordagem incluem o impacto reduzido no sistema do Teradata durante o processo de carregamento de dados, já que o processo de gerenciamento e carregamento está em execução no Azure e a capacidade de automatizar o processo usando pipelines de carregamento de dados controlados por metadados.
Quais ferramentas podem ser usadas?
A tarefa de transformação e movimentação de dados é a função básica de todos os produtos de ETL. Se um desses produtos já estiver em uso no ambiente existente do Teradata, o uso da ferramenta ETL existente poderá simplificar a migração de dados do Teradata para o Azure Synapse. Essa abordagem pressupõe que a ferramenta de ETL dá suporte ao Azure Synapse como ambiente de destino. Para saber mais sobre ferramentas que dão suporte ao Azure Synapse, confira Parceiros de integração de dados.
Se você estiver usando uma ferramenta de ETL, considere executar essa ferramenta no ambiente do Azure para se beneficiar do desempenho, escalabilidade e custo da nuvem do Azure e liberar recursos no data center do Teradata. Outro benefício é a redução da movimentação de dados entre a nuvem e os ambientes locais.
Resumo
Para resumir, nossas recomendações para migrar dados e processos de ETL associados do Teradata para o Azure Synapse são:
Planeje com antecedência para garantir um exercício de migração bem-sucedido.
Crie um inventário detalhado de dados e processos a serem migrados o mais rápido possível.
Use metadados do sistema e arquivos de log para obter uma compreensão precisa de uso de dados e de processo. Não confie na documentação, pois ela pode estar desatualizada.
Entenda os volumes de dados a serem migrados, e a largura de banda de rede entre o data center local e os ambientes de nuvem do Azure.
Considere o uso de uma instância do Teradata em uma VM do Azure como um degrau para descarregar a migração do ambiente herdado do Teradata.
Aproveite os recursos padrão "internos" do Azure para minimizar a carga de trabalho de migração.
Identifique e entenda as ferramentas mais eficientes para extração e carregamento de dados em ambientes do Teradata e do Azure. Use as ferramentas apropriadas em cada fase do processo.
Use instalações do Azure, como Pipelines do Azure Synapse ou Azure Data Factory, para orquestrar e automatizar o processo de migração, minimizando o impacto no sistema do Teradata.
Próximas etapas
Para saber mais sobre operações de acesso à segurança, confira o próximo artigo desta série: Segurança, acesso e operações para migrações do Teradata.