Design e desempenho para migrações Oracle
Este artigo é a primeira parte de uma série de sete partes que oferece diretrizes para fazer a migração do Oracle para o Azure Synapse Analytics. O foco deste artigo é fornecer práticas recomendadas de design e desempenho.
Visão geral
Devido ao custo e à complexidade de manter e atualizar ambientes Oracle locais herdados, muitos usuários existentes do Oracle desejam aproveitar as inovações fornecidas pelos ambientes de nuvem modernos. A IaaS (infraestrutura como serviço) e os ambientes de nuvem PaaS (plataforma como serviço) permitem delegar tarefas como manutenção de infraestrutura e desenvolvimento de plataforma ao provedor de nuvem.
Dica
Mais do que apenas um banco de dados — o ambiente do Azure inclui um conjunto abrangente de recursos e ferramentas.
Embora o Oracle e o Azure Synapse sejam semelhantes por serem ambos bancos de dados SQL que usam técnicas de MPP (processamento paralelo massivo) a fim de obter alto desempenho de consulta em grandes volumes de dados, eles têm algumas diferenças básicas de abordagem:
Os sistemas herdados da Oracle geralmente são instalados localmente e usam hardware relativamente caro, enquanto Azure Synapse é baseado em nuvem e usa recursos de computação e Armazenamento do Azure.
Atualizar uma configuração do Oracle é uma tarefa importante que envolve hardware físico extra e uma reconfiguração de banco de dados potencialmente demorada ou despejo e recarga. Como os recursos de armazenamento e computação são separados no ambiente do Azure e têm recursos de escalonamento elásticos, eles podem ser dimensionados para mais ou para menos de forma independente.
É possível pausar ou redimensionar o Azure Synapse conforme necessário para reduzir a utilização de recursos e o custo.
O Microsoft Azure é um ambiente de nuvem escalonável, altamente seguro e disponível globalmente que inclui o Azure Synapse em um ecossistema de ferramentas e recursos de suporte. O próximo diagrama resume o ecossistema do Azure Synapse.
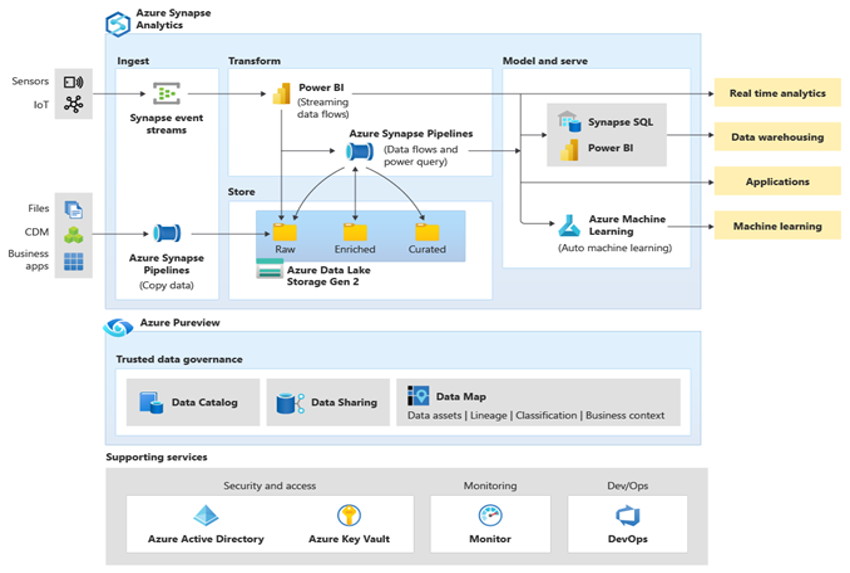
O Azure Synapse fornece o melhor desempenho de banco de dados relacional usando técnicas como MPP e cache automático na memória. Os resultados dessas técnicas podem ser vistos em parâmetros de comparação independentes, como aquele executado recentemente pela GigaOm, que compara o Azure Synapse com outras ofertas de data warehouse de nuvem populares. Os clientes que migram para o ambiente Azure Synapse observam muitos benefícios, inclusive:
Desempenho e preço por desempenho aprimorados.
Maior agilidade e menor tempo de retorno.
Implantação de servidor e desenvolvimento de aplicativos mais rápidos.
Escalabilidade elástica – pague apenas pelo uso real.
Melhora da segurança/conformidade.
Custos reduzidos de armazenamento e recuperação de desastre.
TCO geral mais baixo, melhor controle de custo e OPEX (despesas operacionais simplificadas).
Para maximizar esses benefícios, migre dados e aplicativos novos ou existentes para a plataforma do Azure Synapse. Em muitas organizações, a migração inclui mover um data warehouse existente de uma plataforma local herdada, como o Oracle, para o Azure Synapse. Em alto nível, o processo de migração inclui estas etapas:
Preparação 🡆
Definir escopo – o que deve ser migrado.
Compilar o inventário de dados e processos para migração.
Definir alterações de modelo de dados (se houver).
Definir o mecanismo de extração de dados de origem.
Identificar as ferramentas e recursos de terceiros e do Azure apropriados a este uso.
Treine a equipe antecipadamente na nova plataforma.
Configure a plataforma de destino do Azure.
Migração 🡆
Comece aos poucos e de maneira simples.
Automatize sempre que possível.
Use ferramentas e recursos internos do Azure para reduzir o esforço de migração.
Migre metadados para tabelas e exibições.
Migre os dados históricos a serem mantidos.
Migre ou refatore os processos de negócios e procedimentos armazenados.
Migre ou refatore os processos de carga incremental de ETL/ELT.
Pós-migração
Monitore e documente todos os estágios do processo.
Use a experiência adquirida para criar um modelo para migrações futuras.
Refaça a engenharia do modelo de dados, se preciso (usando o novo desempenho e a escalabilidade da plataforma).
Aplicativos de teste e ferramentas de consulta.
Crie um parâmetro de comparação e otimize o desempenho da consulta.
Este artigo fornece informações gerais e diretrizes para otimização de desempenho ao migrar um data warehouse de um ambiente Oracle existente para o Azure Synapse. A meta de otimização de desempenho é alcançar o desempenho igual ou melhor do data warehouse no Azure Synapse após a migração.
Considerações sobre o design
Escopo da migração
Ao se preparar para migrar de um ambiente Oracle, considere as seguintes opções de migração.
Escolha a carga de trabalho para a migração inicial
Normalmente, os ambientes Oracle herdados evoluem ao longo do tempo para abranger várias áreas de assunto e cargas de trabalho mistas. Ao decidir onde iniciar um projeto de migração, escolha uma área em que você possa:
Comprove a viabilidade da migração para o Azure Synapse por meio da entrega rápida de benefícios do novo ambiente.
Permitir que sua equipe técnica interna ganhe experiência relevante com os processos e as ferramentas que eles usarão ao migrar outras áreas.
Criar um modelo para migrações adicionais específicas do ambiente Oracle de origem e as ferramentas e processos atuais já em vigor.
Um bom candidato à migração inicial de um ambiente Oracle dá suporte aos itens anteriores e:
Implementa uma carga de trabalho de BI/Análise em vez de OLTP (processamento de transações online).
Tem um modelo de dados que possa ser migrado com modificações mínimas, como um esquema em estrela ou snowflake.
Dica
Crie um inventário de objetos que precisem ser migrados e documente o processo de migração.
O volume de dados migrados em uma migração inicial deve ser grande o suficiente para demonstrar os recursos e benefícios do ambiente Azure Synapse, porém sem excesso, para uma demonstração rápida do seu valor. Um tamanho entre 1 e 10 terabytes é típico.
Uma abordagem inicial a um projeto de migração é minimizar o risco, o esforço e o tempo necessários para que você veja rapidamente os benefícios do ambiente de nuvem do Azure. As abordagens a seguir limitam o escopo da migração inicial apenas aos data marts e não abordam aspectos de migração mais amplos, como migração de ETL e de dados históricos. No entanto, você pode abordar esses aspectos em fases posteriores do projeto após a camada de data mart migrada ser novamente preenchida com os dados e processos de compilação necessários.
Migração lift-and-shift versus abordagem em Fases
Em geral, há dois tipos de migração, independentemente da finalidade e do escopo planejado: lift-and-shift sem alterações e uma abordagem em fases que incorpora alterações.
Lift-and-shift
Em uma migração do tipo lift-and-shift, um modelo de dados existente, como um esquema em estrela, é migrado inalterado para a nova plataforma Azure Synapse. Essa abordagem minimiza o risco e o tempo de migração, reduzindo o trabalho necessário para alcançar os benefícios da migração para o ambiente de nuvem do Azure. A migração lift-and-shift é uma boa opção para estes cenários:
- Você tem um ambiente Oracle já existente com um só data mart para migrar ou
- Você tem um ambiente Oracle com dados que já estão em um esquema de estrela ou snowflake bem projetado, ou
- Você está sob pressão de tempo e custo para migrar para um ambiente de nuvem moderno.
Dica
O formato lift-and-shift é um bom ponto de partida, mesmo que as fases subsequentes implementem alterações no modelo de dados.
Abordagem em fases que incorpora alterações
Se um data warehouse herdado estiver em evolução há um longo período, talvez seja necessário refazer sua engenharia para manter os níveis de desempenho necessários. Talvez você também precise refazer a engenharia para oferecer suporte a novos dados, como fluxos de IoT (Internet das Coisas). Como parte do processo de reengenharia, migre para o Azure Synapse para obter os benefícios de um ambiente de nuvem escalonável. A migração pode incluir uma alteração no modelo de dados subjacente, como a mudança de um modelo Inmon para um cofre de dados.
A Microsoft recomenda mover o modelo de dados existente sem alterações para o Azure e usar o desempenho e a flexibilidade do ambiente do Azure para aplicar as alterações geradas pelo trabalho de reengenharia. Dessa forma, você pode usar os recursos do Azure para fazer as alterações sem afetar o sistema de origem existente.
Usar as instalações da Microsoft para implementar uma migração controlada por metadados
Você pode automatizar e orquestrar o processo de migração usando os recursos do ambiente do Azure. Essa abordagem minimiza o impacto no ambiente Oracle existente, que talvez já esteja funcionando próximo da capacidade total.
O SSMA (Assistente de Migração do SQL Server) para Oracle pode automatizar muitas partes do processo de migração, incluindo, em alguns casos, funções e código de procedimento. O SSMA dá suporte ao Azure Synapse como um ambiente de destino.

O SSMA para Oracle pode ajudar você a migrar um Oracle data warehouse ou data mart para o Azure Synapse. O SSMA foi projetado para automatizar o processo de migração de tabelas, exibições e dados de um ambiente Oracle existente.
O Azure Data Factory é um serviço de integração de dados baseado em nuvem que permite criar na nuvem fluxos de trabalho controlados por dados que orquestram e automatizam a movimentação e a transformação de dados. Você pode usar o Azure Data Factory para criar e agendar fluxos de trabalho controlados por dados (pipelines) que ingerem dados de diferentes armazenamentos de dados. O Data Factory é capaz de processar e transformar dados usando serviços de computação como o Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics e o Azure Machine Learning.
O Data Factory pode ser usado para migrar dados na origem para o SQL do Azure como destino. Essa movimentação de dados offline ajuda a reduzir significativamente o tempo de inatividade da migração.
Os Serviços de Migração de Banco de Dados do Azure podem ajudar você a planejar e executar uma migração de ambientes como o Oracle.
Quando você planeja usar as instalações do Azure para gerenciar o processo de migração, crie metadados que listem todas as tabelas de dados a serem migradas e sua localização.
Diferenças de design entre o Oracle e o Azure Synapse
Conforme mencionado anteriormente, há algumas diferenças básicas de abordagem entre os bancos de dados Oracle e do Azure Synapse Analytics. O SSMA para Oracle não só ajuda a preencher essas lacunas, mas também automatiza a migração. Embora o SSMA não seja a abordagem mais eficiente para volumes muito altos de dados, ele é útil para tabelas menores.
Diversos bancos de dados versus um só banco de dados e esquemas
O ambiente Oracle geralmente contém vários bancos de dados separados. Por exemplo, pode haver bancos de dados separados para: ingestão de dados e tabelas de preparo, tabelas principais do warehouse e data marts – às vezes chamados de camada semântica. O processamento em pipelines de ETL ou ELT pode implementar junções entre bancos de dados e mover dados entre os bancos de dados separados.
Por outro lado, o ambiente Azure Synapse contém um único banco de dados e usa esquemas para separar tabelas em grupos separados logicamente. Recomendamos usar uma série de esquemas no banco de dados do Azure Synapse de destino para imitar os bancos de dados separados migrados do ambiente Oracle. Se o ambiente Oracle já usa esquemas, talvez seja necessário empregar uma nova convenção de nomenclatura a fim de mover as tabelas e exibições existentes do Oracle para o novo ambiente. Por exemplo, é possível concatenar o esquema existente do Oracle e os nomes de tabela no novo nome de tabela do Azure Synapse e, em seguida, usar nomes de esquema no novo ambiente para manter os nomes de banco de dados separados originais. Você pode usar exibições SQL sobre as tabelas subjacentes para manter as estruturas lógicas, mas há algumas desvantagens potenciais nessa abordagem:
As exibições no Azure Synapse são somente leitura, portanto, as atualizações nos dados devem ocorrer nas tabelas base subjacentes.
Talvez já haja uma ou mais camadas de exibições, e a adição de uma camada extra pode afetar o desempenho.
Dica
Combine vários bancos de dados em um único banco de dados no Azure Synapse e use esquemas para separar logicamente as tabelas.
Considerações sobre tabela
Ao migrar tabelas entre ambientes diferentes, normalmente só é possível migrar dados brutos e os metadados que os descrevem. Outros elementos de banco de dados do sistema de origem, como índices, geralmente não são migrados porque podem ser desnecessários ou implementados de forma diferente no novo ambiente.
Otimizações de desempenho no ambiente de origem, como índices, indicam onde você pode adicionar otimização de desempenho no novo ambiente. Por exemplo, se consultas no ambiente Oracle de origem usam índices mapeados por bits frequentemente, isso sugere que um índice não clusterizado deve ser criado dentro do Azure Synapse. Outras técnicas nativas de otimização de desempenho, como a replicação de tabela, podem ser mais aplicáveis do que uma criação direta de índice por semelhança. O SSMA para Oracle pode ser usado para fornecer recomendações de migração para distribuição e indexação de tabelas.
Dica
Índices existentes indicam candidatos à indexação no warehouse migrado.
Tipos de objeto de banco de dados Oracle sem suporte
Os recursos específicos do Oracle normalmente podem ser substituídos por recursos do Azure Synapse. No entanto, alguns objetos de banco de dados Oracle não têm suporte direto no Azure Synapse. A lista a seguir de objetos de banco de dados Oracle sem suporte descreve como você pode obter uma funcionalidade equivalente no Azure Synapse.
Diversas opções de indexação: no Oracle, várias opções de indexação, como índices mapeados por bit, índices baseados em função e índices de domínio, não têm equivalente direto em Azure Synapse.
Você pode descobrir quais colunas são indexadas e o tipo de índice:
Consultando tabelas e exibições do catálogo do sistema, como
ALL_INDEXES,DBA_INDEXES,USER_INDEXESeDBA_IND_COL. Você pode usar as consultas internas no Oracle SQL Developer, conforme mostrado na captura de tela a seguir.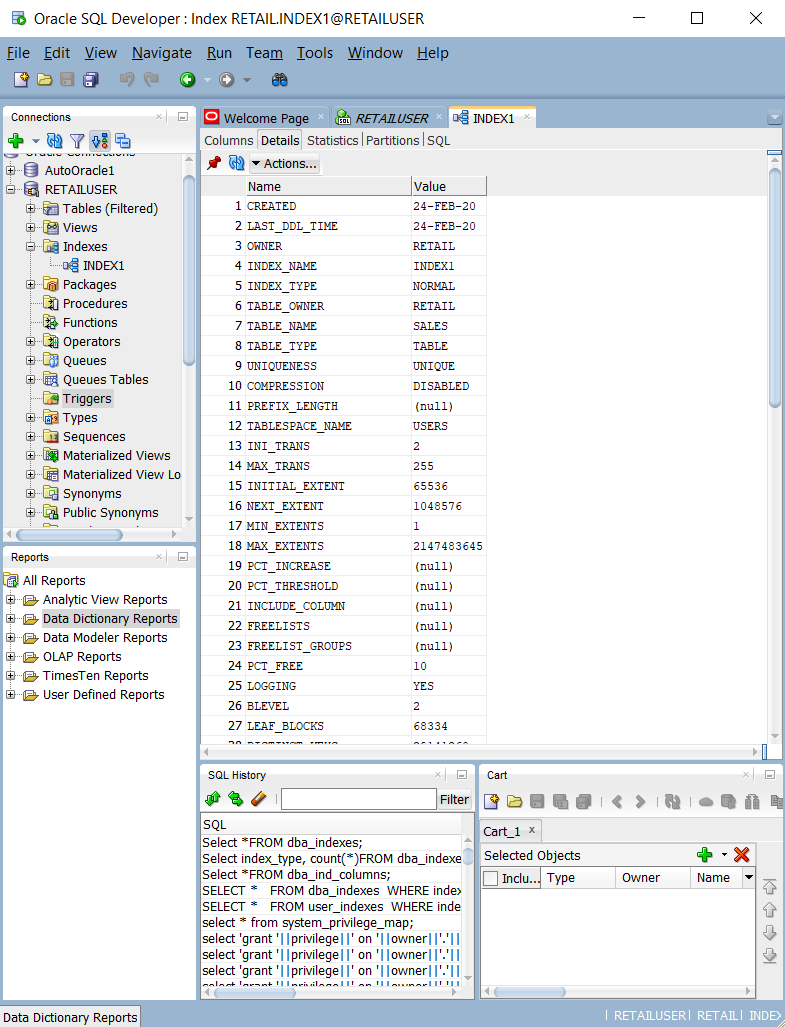
Ou execute a seguinte consulta para localizar todos os índices de um determinado tipo:
SELECT * FROM dba_indexes WHERE index_type LIKE 'FUNCTION-BASED%';Consultando as exibições
dba_index_usageouv$object_usagequando o monitoramento estiver habilitado. Você pode consultar essas exibições no Oracle SQL Developer, conforme mostrado na captura de tela a seguir.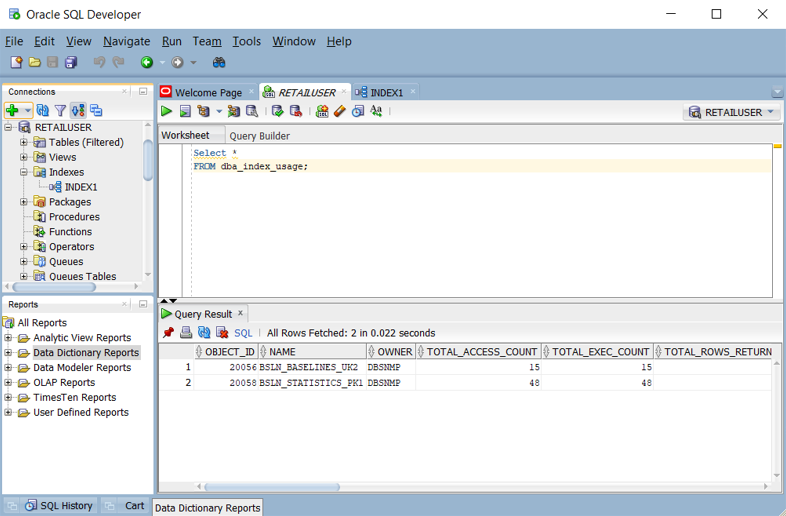
Índices baseados em função, em que o índice contém o resultado de uma função nas colunas de dados subjacentes, não têm equivalente direto no Azure Synapse. Recomendamos que primeiro você migre os dados e, no Azure Synapse, execute as consultas Oracle que usam índices baseados em função para medir o desempenho. Se o desempenho dessas consultas no Azure Synapse não for aceitável, considere criar uma coluna que contenha o valor pré-calculado e indexe essa coluna.
Quando você configura o ambiente do Azure Synapse, faz sentido implementar apenas índices em uso. Atualmente, o Azure Synapse dá suporte aos tipos de índice mostrados aqui:
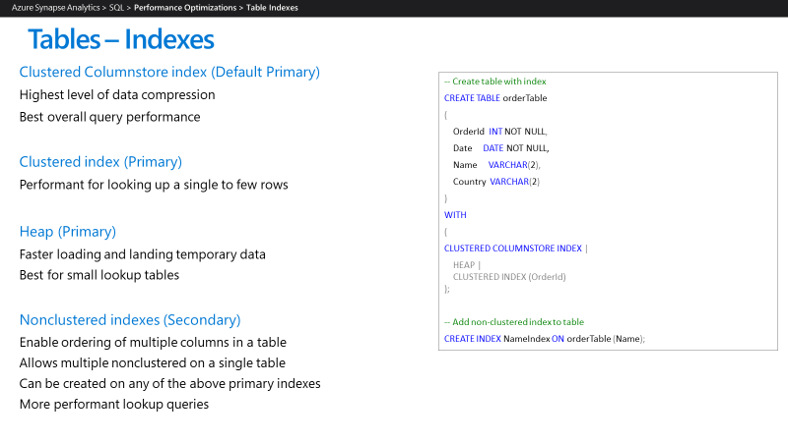
Os recursos do Azure Synapse, como processamento de consulta paralela e armazenamento em cache de dados e resultados na memória, tornam provável que menos índices sejam necessários para que os aplicativos de data warehouse alcancem metas de desempenho. Recomendamos que você use os seguintes tipos de índice no Azure Synapse:
Índices columnstore clusterizados: quando nenhuma opção de índice é especificada para uma tabela, o Azure Synapse por padrão cria um índice columnstore clusterizado. As tabelas columnstore clusterizadas oferecem o nível mais alto de compactação de dados, o melhor desempenho geral da consulta e geralmente superam tabelas de índice clusterizado ou de heap. Um índice columnstore clusterizado geralmente é a melhor opção para tabelas grandes. Ao criar uma tabela, escolha a opção de columnstore clusterizado se não tiver certeza de como indexá-la. No entanto, há alguns cenários em que índices columnstore clusterizados não são a melhor opção:
- Tabelas com dados de pré-classificação em uma ou mais chaves de classificação podem se beneficiar da eliminação de segmentos habilitada por índices columnstore clusterizados ordenados.
- Tabelas com os tipos de dados varchar(max), nvarchar(max) ou varbinary(max), porque um índice columnstore clusterizado não dá suporte a esses tipos de dados. Em vez disso, considere usar um heap ou um índice clusterizado.
- Tabelas com dados transitórios, pois as tabelas columnstore podem ser menos eficientes do que as tabelas de heap ou temporárias.
- Tabelas pequenas com menos de cem milhões de linhas. Em vez disso, considere o uso de tabelas de heap.
Índices columnstore clusterizados ordenados: quando você habilita a eliminação eficiente de segmentos, os índices columnstore clusterizados ordenados em pools de SQL dedicados do Azure Synapse têm um desempenho muito mais rápido, pois ignoram grandes quantidades de dados ordenados que não correspondem ao predicado de consulta. Carregar dados em uma tabela de CCI ordenado pode levar mais tempo do que em uma tabela de CCI não ordenado devido à operação de classificação de dados, no entanto, as consultas podem ser executadas posteriormente de maneira mais rápida com o CCI ordenado. Para saber mais sobre índices columnstore clusterizados ordenados, confira Ajuste de desempenho com índice columnstore clusterizado ordenado.
Índices clusterizados e não clusterizados: índices clusterizados podem superar o desempenho de índices columnstore clusterizados quando uma linha precisa ser recuperada rapidamente. Para consultas em que uma pesquisa de linha única, ou pesquisas de apenas algumas linhas, devem ser executadas com velocidade extrema, considere usar um índice de cluster ou um índice secundário não clusterizado. A desvantagem de usar um índice clusterizado é que apenas consultas que usam um filtro altamente seletivo na coluna de índice clusterizado se beneficiarão. Para aprimorar a filtragem em outras colunas, você pode adicionar um índice não clusterizado a elas. No entanto, cada índice adicionado a uma tabela usa mais espaço e aumenta o tempo de processamento para ser carregado.
Tabelas de heap: quando está recebendo dados temporariamente no Azure Synapse, você pode descobrir que o uso de uma tabela de heap torna o processo geral mais rápido. Isso ocorre porque carregar dados em tabelas de heap é mais rápido do que carregar dados em tabelas de índice e, em alguns casos, as leituras posteriores podem ser feitas do cache. Se você estiver carregando dados apenas para prepará-los antes de executar mais transformações, é muito mais rápido carregá-los em uma tabela de heap do que em uma tabela columnstore clusterizada. Além disso, carregar dados em uma tabela temporária é mais rápido do que carregar uma tabela em um armazenamento permanente. Para tabelas de pesquisa pequenas com menos de 100 milhões de linhas, as tabelas de heap geralmente são a escolha certa. As tabelas columnstore de cluster começam a obter compactação ideal quando contêm mais de 100 milhões de linhas.
Tabelas clusterizadas: as tabelas Oracle podem ser organizadas de modo que as linhas de tabela acessadas juntas com frequência (com base em um valor comum) sejam armazenadas fisicamente juntas para reduzir a E/S de disco quando dados são recuperados. O Oracle também fornece uma opção de cluster de hash para tabelas individuais, que aplica um valor de hash à chave de cluster e armazena fisicamente linhas com o mesmo valor de hash juntas. Para listar os clusters em um banco de dados Oracle, use a consulta
SELECT * FROM DBA_CLUSTERS;. Para determinar se uma tabela está dentro de um cluster, use a consultaSELECT * FROM TAB;, que mostra o nome da tabela e a ID do cluster para cada tabela.No Azure Synapse, você pode obter resultados semelhantes usando tabelas materializadas e/ou replicadas, pois esses tipos de tabela minimizam a E/S necessária no tempo de execução da consulta.
Exibições materializadas: o Oracle dá suporte a exibições materializadas e recomenda usar uma ou mais para tabelas grandes com muitas colunas em que apenas algumas delas são usadas regularmente em consultas. Exibições materializadas serão atualizadas automaticamente pelo sistema quando os dados na tabela base forem atualizados.
Em 2019, a Microsoft anunciou que o Azure Synapse dará suporte a exibições materializadas com a mesma funcionalidade que no Oracle. As exibições materializadas agora são uma versão prévia do recurso no Azure Synapse.
Gatilhos no banco de dados: no Oracle, um gatilho pode ser configurado para ser executado automaticamente quando ocorre um evento de gatilho. Os eventos de gatilho podem ser:
Uma instrução DML (linguagem de manipulação de dados), como
INSERT,UPDATEouDELETE, é executada em uma tabela. Se você definiu um gatilho que é acionado antes de uma instruçãoINSERTem uma tabela do cliente, o gatilho será acionado uma vez antes de uma nova linha ser inserida na tabela do cliente.Uma instrução DDL, como
CREATEouALTER, é executada. Muitas vezes, esse gatilho é usado para fins de auditoria para registrar alterações de esquema.Um evento do sistema, como inicialização ou desligamento do banco de dados Oracle.
Um evento do usuário, como entrar ou sair.
Você pode obter uma lista dos gatilhos definidos em um banco de dados Oracle consultando as exibições
ALL_TRIGGERS,DBA_TRIGGERSouUSER_TRIGGERS. A captura de tela a seguir mostra uma consultaDBA_TRIGGERSno Oracle SQL Developer.
O Azure Synapse não dá suporte a gatilhos de banco de dados Oracle. No entanto, você pode adicionar uma funcionalidade equivalente usando o Data Factory, embora isso exija que você refatore os processos que usam gatilhos.
Sinônimos: o Oracle dá suporte à definição de sinônimos como nomes alternativos para vários tipos de objeto de banco de dados. Esses tipos de objeto incluem tabelas, exibições, sequências, procedimentos, funções armazenadas, pacotes, exibições materializadas, objetos de esquema de classe Java, objetos definidos pelo usuário ou outros sinônimos.
No momento, o Azure Synapse não dá suporte à definição de sinônimos, embora se um sinônimo no Oracle se referir a uma tabela ou exibição, você poderá definir uma exibição no Azure Synapse para corresponder ao nome alternativo. Se um sinônimo no Oracle se referir a uma função ou um procedimento armazenado, no Azure Synapse você poderá criar outra função ou procedimento armazenado, com um nome correspondente ao sinônimo, que chame o destino.
Tipos definidos pelo usuário: o Oracle dá suporte a objetos definidos pelo usuário que podem conter uma série de campos individuais, cada um com a própria definição e valores padrão. Esses objetos podem ser referenciados dentro de uma definição de tabela da mesma forma que tipos de dados internos, como
NUMBERouVARCHAR. Você pode obter uma lista de tipos definidos pelo usuário em um banco de dados Oracle consultando as exibiçõesALL_TYPES,DBA_TYPESouUSER_TYPES.No momento, o Azure Synapse não dá suporte a tipos definidos pelo usuário. Se os dados que você precisa migrar incluirem tipos de dados definidos pelo usuário, "nivele-os" em uma definição de tabela convencional ou, se forem matrizes de dados, normalize-os em uma tabela separada.




Mapeamento de tipo de dados do Oracle
A maioria dos tipos de dados do Oracle tem um equivalente direto no Azure Synapse. A tabela a seguir mostra a abordagem recomendada para mapear tipos de dados do Oracle para o Azure Synapse.
| Tipo de dados do Oracle | Tipo de dados do Azure Synapse |
|---|---|
| BFILE | Não há suporte. Mapear para VARBINARY (MAX). |
| BINARY_FLOAT | Não há suporte. Mapear para FLOAT. |
| BINARY_DOUBLE | Não há suporte. Mapear para DOUBLE. |
| BLOB | Sem suporte direto. Substituir por VARBINARY(MAX). |
| CHAR | CHAR |
| CLOB | Sem suporte direto. Substituir por VARCHAR(MAX). |
| DATE | DATE no Oracle também pode conter informações de hora. Dependendo uso, mapear para DATE ou TIMESTAMP. |
| DECIMAL | DECIMAL |
| DOUBLE | PRECISION DOUBLE |
| FLOAT | FLOAT |
| INTEGER | INT |
| INTERVAL YEAR TO MONTH | Não há suporte para tipos de dados INTERVAL. Use funções de comparação de data, como DATEDIFF ou DATEADD, para cálculos de data. |
| INTERVAL DAY TO SECOND | Não há suporte para tipos de dados INTERVAL. Use funções de comparação de data, como DATEDIFF ou DATEADD, para cálculos de data. |
| LONG | Não há suporte. Mapear para VARCHAR(MAX). |
| LONG RAW | Não há suporte. Mapear para VARBINARY(MAX). |
| NCHAR | NCHAR |
| NVARCHAR2 | NVARCHAR |
| NUMBER | FLOAT |
| NCLOB | Sem suporte direto. Substituir por NVARCHAR(MAX). |
| NUMERIC | NUMERIC |
| Tipos de dados de mídia ORD | Sem suporte |
| RAW | Não há suporte. Mapear para VARBINARY. |
| real | real |
| ROWID | Não há suporte. Mapear para GUID, que é semelhante. |
| Tipos de dados geoespaciais SDO | Sem suporte |
| SMALLINT | SMALLINT |
| timestamp | DATETIME2 ou a função CURRENT_TIMESTAMP() |
| TIMESTAMP WITH LOCAL TIME ZONE | Não há suporte. Mapear para DATETIMEOFFSET. |
| TIMESTAMP WITH TIME ZONE | Não há suporte porque TIME é armazenado usando a hora do relógio de parede sem um deslocamento de fuso horário. |
| URIType | Não há suporte. Armazenar em um VARCHAR. |
| UROWID | Não há suporte. Mapear para GUID, que é semelhante. |
| VARCHAR | VARCHAR |
| VARCHAR2 | VARCHAR |
| XMLType | Não há suporte. Armazenar dados XML em um VARCHAR. |
O Oracle também dá suporte a objetos definidos pelo usuário que podem conter uma série de campos individuais, cada um com a própria definição e valores padrão. Esses objetos podem ser referenciados dentro de uma definição de tabela da mesma forma que tipos de dados internos, como NUMBER ou VARCHAR. No momento, o Azure Synapse não dá suporte a tipos definidos pelo usuário. Se os dados que você precisa migrar incluirem tipos de dados definidos pelo usuário, "nivele-os" em uma definição de tabela convencional ou, se forem matrizes de dados, normalize-os em uma tabela separada.
Dica
Avalie o número e o tipo de tipos de dados sem suporte durante a fase de preparação da migração.
Fornecedores de terceiros oferecem ferramentas e serviços para automatizar a migração, incluindo o mapeamento de tipos de dados. Se uma ferramenta ETL de terceiros já estiver em uso no ambiente Oracle, use essa ferramenta para implementar transformações de dados necessárias.
Diferenças de sintaxe de DML SQL
Existem diferenças de sintaxe DML do SQL entre o Oracle SQL e Azure Synapse T-SQL. Essas diferenças são discutidas detalhadamente em Minimizar problemas de SQL para migrações do Oracle. Em alguns casos, você pode automatizar a migração de DML usando ferramentas da Microsoft, como o SSMA para Oracle e o Serviço de Migração de Banco de Dados do Azure, ou produtos e serviços de migração de terceiros.
Funções, procedimentos armazenados e sequências
Muitas vezes, ao migrar um data warehouse de um ambiente herdado maduro como o Oracle, provavelmente é preciso migrar elementos que não sejam tabelas e exibições simples. Verifique se as ferramentas do ambiente do Azure podem substituir a funcionalidade de funções, procedimentos armazenados e sequências, pois geralmente é mais eficaz usar ferramentas internas do Azure do que recodificá-los para o Azure Synapse.
Como parte da fase de preparação, crie um inventário de objetos que precisem ser migrados, defina um método para tratá-los e aloque os recursos corretos no seu plano de migração.
Ferramentas da Microsoft, como o SSMA para Oracle e os Serviços de Migração de Banco de Dados do Azure ou produtos e serviços de migração de terceiros, podem automatizar a migração de funções, procedimentos armazenados e sequências.
As seções a seguir discutem mais profundamente a migração de funções, procedimentos armazenados e sequências.
Funções
Como a maioria dos produtos de banco de dados, o Oracle oferece suporte a funções do sistema e definidas pelo usuário em uma implementação SQL. Quando você migra uma plataforma de banco de dados herdada para o Azure Synapse, as funções comuns do sistema geralmente podem ser migradas sem alterações. Algumas funções do sistema podem ter sintaxes um pouco diferentes, mas todas as alterações necessárias podem ser automatizadas. Você pode obter uma lista de funções em um banco de dados Oracle consultando a exibição ALL_OBJECTS com a cláusula WHERE apropriada. Você pode usar o Oracle SQL Developer para obter uma lista de funções, conforme mostrado na captura de tela a seguir.

No caso de funções do sistema Oracle ou arbitrárias definidas pelo usuário sem equivalente no Azure Synapse, recodifique-as usando uma linguagem de ambiente de destino. As funções definidas pelo usuário do Oracle são codificadas em PL/SQL, Java ou C. O Azure Synapse usa a linguagem Transact-SQL para implementar funções definidas pelo usuário.
Procedimentos armazenados
A maioria dos produtos de banco de dados modernos permite que os procedimentos sejam armazenados no banco de dados. O Oracle fornece a linguagem PL/SQL para essa finalidade. Um procedimento armazenado normalmente contém instruções SQL e lógica de procedimento, retornando dados ou um status. Você pode obter uma lista de procedimentos armazenados em um banco de dados Oracle consultando a exibição ALL_OBJECTS com a cláusula WHERE apropriada. Você pode usar o Oracle SQL Developer para obter uma lista de procedimentos armazenados, conforme mostrado na próxima captura de tela.

O Azure Synapse dá suporte a procedimentos armazenados usando T-SQL, portanto, você precisará recodificar todos os procedimentos armazenados migrados nessa linguagem.
Sequências
No Oracle, uma sequência é um objeto de banco de dados nomeado criado usando CREATE SEQUENCE. Uma sequência fornece valores numéricos exclusivos por meio do método CURRVAL e NEXTVAL. Você pode usar números exclusivos gerados como valores de chave substituta para chaves primárias.
O Azure Synapse não implementa CREATE SEQUENCE, mas você pode implementar sequências usando colunas IDENTITY ou o código SQL que gera o próximo número de sequência em uma série.
Extraindo metadados e dados de um ambiente Oracle
Geração de linguagem de definição de dados
O padrão ANSI SQL define a sintaxe básica para comandos DDL (Linguagem de Definição de Dados). Alguns comandos DDL, como CREATE TABLE eCREATE VIEW, são comuns ao Oracle e ao Azure Synapse, mas também fornecem recursos específicos de implementação, como indexação, distribuição de tabelas e opções de particionamento.
Você pode editar scripts Oracle CREATE TABLE e CREATE VIEW existentes para alcançar definições equivalentes no Azure Synapse. Para isso, talvez seja necessário usar tipos de dados modificados e remover ou modificar cláusulas específicas do Oracle, como TABLESPACE.
No ambiente Oracle, as tabelas do catálogo do sistema especificam a tabela e a definição de exibição atuais. Ao contrário da documentação mantida pelo usuário, as informações do catálogo do sistema estão sempre completas e em sincronia com as definições de tabela atuais. Você pode acessar informações do catálogo do sistema usando utilitários como o Oracle SQL Developer. O Oracle SQL Developer pode gerar instruções DDL CREATE TABLE que você pode editar para criar tabelas equivalentes no Azure Synapse.
Ou você pode usar SSMA para Oracle para migrar tabelas de um ambiente Oracle existente para o Azure Synapse. O SSMA para Oracle aplicará os mapeamentos de tipo de dados apropriados e os tipos de tabela e distribuição recomendados, conforme mostrado na captura de tela a seguir.

Você também pode usar ferramentas ETL e de migração de terceiros que processem informações de catálogo do sistema para obter resultados semelhantes.
Extração de dados do Oracle
Você pode extrair dados brutos de tabelas Oracle para arquivos delimitados simples, como arquivos CSV, usando utilitários padrão da Oracle, como o Oracle SQL Developer, o SQL*Plus e o SCLcl. Em seguida, você pode compactar os arquivos delimitados simples usando gzip e carregar os arquivos compactados para o Armazenamento de Blobs do Azure usando ferramentas de transporte de dados do AzCopy ou do Azure, como o Azure Data Box.
Extraia dados de tabela da maneira mais eficiente possível, especialmente ao migrar tabelas de fatos grandes. Para tabelas Oracle, use o paralelismo para maximizar a taxa de transferência de extração. Você pode obter o paralelismo executando vários processos que extraem individualmente segmentos discretos de dados ou usando ferramentas capazes de automatizar a extração paralela por meio do particionamento.
Dica
Use o paralelismo para a extração de dados mais eficiente.
Se houver largura de banda de rede suficiente, você poderá extrair dados do sistema do Oracle local diretamente para as tabelas do Azure Synapse ou para o Armazenamento de Dados de Blob do Azure. Para fazer isso, use processos do Data Factory, o Serviço de Migração de Banco de Dados do Azure ou a migração de dados de terceiros ou produtos de ETL.
Os arquivos de dados extraídos devem conter texto delimitado no formato CSV, ORC (Optimized Row Columnar) ou Parquet.
Para obter mais informações sobre o processo de migração de dados e ETL de um ambiente Oracle, consulte Migração de dados, ETL e carregamento para migrações do Oracle.
Recomendações de desempenho para migrações do Oracle
A meta de otimização de desempenho é um desempenho do data warehouse igual ou melhor após a migração para o Azure Synapse.
Semelhanças nos conceitos de abordagem de ajuste de desempenho
Muitos conceitos de ajuste de desempenho para bancos de dados Oracle são verdadeiros para bancos de dados Azure Synapse. Por exemplo:
Use a distribuição de dados para colocar os dados a serem ingressados no mesmo nó de processamento.
Use o menor tipo de dados para uma determinada coluna para economizar espaço de armazenamento e acelerará o processamento de consultas.
Verifique se as colunas a serem ingressadas têm o mesmo tipo de dados para otimizar o processamento de ingresso e reduzir a necessidade de transformações de dados.
Para ajudar o otimizador a produzir o melhor plano de execução, verifique se as estatísticas estão atualizadas.
Monitore o desempenho usando recursos de banco de dados internos para verificar se os recursos estão sendo usados com eficiência.
Dica
Priorize a familiaridade com as opções de ajuste do Azure Synapse no início de uma migração.
Diferenças na abordagem de ajuste de desempenho
Esta seção destaca diferenças de implementação de ajuste de desempenho de nível inferior entre o Oracle e o Azure Synapse.
Opções de distribuição de dados
Em termos de desempenho, o Azure Synapse foi projetado com arquitetura de vários nós e usa processamento paralelo. Para otimizar o desempenho de tabelas no Azure Synapse, você pode definir uma opção de distribuição de dados em instruções CREATE TABLE usando a instrução DISTRIBUTION. Por exemplo, você pode especificar uma tabela distribuída por hash, que distribui linhas de tabela entre nós de computação usando uma função de hash determinística. Muitas implementações Oracle, especialmente sistemas locais mais antigos, não dão suporte a esse recurso.
Diferentemente do Oracle, o Azure Synapse oferece suporte a junções locais entre uma tabela pequena e uma tabela grande por meio de replicação de tabela pequena. Por exemplo, considere uma tabela de dimensões pequena e uma tabela de fatos grande em um modelo de esquema em estrela. O Azure Synapse pode replicar a tabela de dimensões menores em todos os nós para garantir que o valor de qualquer chave de junção para a tabela grande tenha uma linha de dimensão correspondente e disponível localmente. A sobrecarga da replicação da tabela de dimensões é relativamente baixa em uma tabela de pequenas dimensões. Para tabelas de grandes dimensões, uma abordagem de distribuição de hash é mais apropriada. Para obter mais informações sobre opções de distribuição de dados, consulte Orientações sobre design para uso de tabelas replicadas e Orientações sobre a criação de tabelas distribuídas.
Dica
A distribuição de hash aprimora o desempenho da consulta em tabelas de fatos grandes. Distribuição por rodízio é útil para melhorar a velocidade do carregamento.
A distribuição de hash pode ser aplicada em várias colunas para uma distribuição mais uniforme da tabela base. A distribuição de várias colunas permitirá que você escolha até oito colunas para distribuição. Isso não só reduz a distorção de dados ao longo do tempo, mas também aprimora o desempenho da consulta.
Observação
Atualmente, a distribuição de várias colunas está em versão prévia no Azure Synapse Analytics. Você pode usar a distribuição de várias colunas com CREATE MATERIALIZED VIEW, CREATE TABLE e CREATE TABLE AS SELECT.
Assistente de Distribuição
No SQL do Azure Synapse, a forma como cada tabela é distribuída pode ser personalizada. A estratégia de distribuição de tabela afeta substancialmente o desempenho da consulta.
O assistente de distribuição é um novo recurso no SQL do Synapse que analisa consultas e recomenda as melhores estratégias de distribuição para tabelas para aprimorar o desempenho da consulta. As consultas a serem consideradas pelo assistente podem ser fornecidas por você ou extraídas de suas consultas históricas disponíveis no DMV.
Para obter detalhes e exemplos sobre como usar o assistente de distribuição, visite o Assistente de Distribuição no SQL do Azure Synapse.
Indexação de dados
O Azure Synapse dá suporte a várias opções de indexação definíveis pelo usuário que têm uma operação e um uso diferentes em comparação com mapas de zona gerenciados pelo sistema no Oracle. Para obter mais informações sobre as diferentes opções de indexação no Azure Synapse, consulte Índices em tabelas de pool de SQL dedicadas.
Definições de índice em um ambiente Oracle de origem fornecem indicações úteis de uso de dados e as colunas candidatas à indexação no ambiente do Azure Synapse. Normalmente, você não precisará migrar todos os índices de um ambiente Oracle herdado porque o Azure Synapse não depende muito de índices e implementa os seguintes recursos para obter um desempenho excelente:
Processamento paralelo de consultas.
Armazenamento em cache de dados e conjuntos de resultados na memória.
Distribuição de dados, como replicação de tabelas de dimensões pequenas, para reduzir a E/S.
Particionamento de dados
Em um data warehouse corporativo, as tabelas de fatos podem conter bilhões de linhas. O particionamento otimiza a manutenção e consulta dessas tabelas, dividindo-as em partes separadas para reduzir a quantidade de dados processados. No Azure Synapse, a instrução CREATE TABLE define a especificação de particionamento para uma tabela.
Só é possível usar um campo por tabela para particionamento. Este campo é frequentemente um campo de data, pois muitas consultas são filtradas por data ou intervalo de datas. É possível alterar o particionamento de uma tabela após o carregamento inicial, usando a instrução CTAS (CREATE TABLE AS) para recriá-la com uma nova distribuição. Para obter uma descrição detalhada do particionamento no Azure Synapse, consulte Tabelas de particionamento em um pool de SQL dedicado.
PolyBase ou COPY INTO para carregamento de dados
O PolyBase oferece suporte ao carregamento eficiente de grandes volumes de dados para um data warehouse com o uso de fluxos de carregamento paralelos. Para obter mais informações, consulte a estratégia de carregamento de dados do PolyBase.
COPY INTO também oferece suporte à ingestão de dados de alta taxa de transferência e:
- Recuperação de dados de todos os arquivos em uma pasta e em subpastas.
- Recuperação de dados de vários locais na mesma conta de armazenamento. Você pode especificar vários locais usando caminhos separados por vírgulas.
- ADLS (Azure Data Lake Storage) e Armazenamento de Blobs do Azure.
- Formatos de arquivo CSV, PARQUET e ORC.
Dica
O método recomendado para carregamento de dados é usar COPY INTO junto com o formato de arquivo PARQUET.
Gerenciamento de carga de trabalho
A execução de cargas de trabalho mistas pode representar desafios de recursos em sistemas ocupados. Um esquema de gerenciamento de carga de trabalho bem-sucedido gerencia efetivamente os recursos, garante uma utilização de recursos altamente eficiente e maximiza o ROI (retorno sobre o investimento). A classificação da carga de trabalho, a importância da carga de trabalho e o isolamento da carga de trabalho dão mais controle sobre como a carga de trabalho utiliza os recursos do sistema.
O guia de gerenciamento de carga de trabalho descreve as técnicas para analisar a carga de trabalho, gerenciar e monitorar a importância da carga de trabalho e as etapas para converter uma classe de recurso em um grupo de carga de trabalho. Use o portal do Azure e as consultas T-SQL em DMVs para monitorar a carga de trabalho para garantir que os recursos aplicáveis sejam utilizados com eficiência.
Próximas etapas
Para saber mais sobre ETL e carregamento para migração do Oracle, confira o próximo artigo desta série: Migração de dados, ETL e carregamento para migrações do Oracle.