Guia estratégico de POC do Synapse: análise de Big Data com o pool do Apache Spark no Azure Synapse Analytics
Este artigo apresenta uma metodologia de alto nível para preparar e executar um projeto de POC (prova de conceito) eficaz do Azure Synapse Analytics para o pool do Apache Spark.
Observação
Este artigo faz parte da série de artigos Guia estratégico de prova de conceito do Azure Synapse. Para obter uma visão geral da série, confira Guia estratégico de prova de conceito do Azure Synapse.
Preparação para o POC
Um projeto de POC pode ajudar você a tomar uma decisão comercial informada sobre a implementação de um ambiente de análise avançada e de Big Data em uma plataforma baseada em nuvem que tira proveito do pool do Apache Spark no Azure Synapse.
Um projeto de POC identificará suas principais metas e impulsionadores de negócios a que a plataforma de análise avançada e big data baseada em nuvem deve dar suporte. Ele testará as principais métricas e provará os principais comportamentos críticos para o sucesso da sua engenharia de dados, criação de modelo de machine learning e requisitos de treinamento. O POC não é projetado para ser implantado em ambiente de produção. Ela é um projeto de curto prazo que se concentra em questões-chave, e seu resultado pode ser descartado.
Antes de começar a planejar seu projeto de POC do Spark:
- Identifique eventuais restrições ou diretrizes que sua organização tenha em relação a mover dados para a nuvem.
- Identifique patrocinadores executivos ou empresariais para um projeto de plataforma de análise avançada e big data. Garanta o suporte à migração para a nuvem.
- Identifique a disponibilidade de especialistas técnicos e usuários de negócios para dar suporte durante a execução do POC.
Antes de começar a se preparar para o projeto de POC, recomendamos que primeiro leia a documentação do Apache Spark.
Dica
Se você não estiver familiarizado com pools do Spark, recomendamos que examine o roteiro de aprendizagem Executar engenharia de dados com os Pools do Apache Spark no Azure Synapse.
Agora você deve ter determinado que não há bloqueios imediatos e que já pode começar a se preparar para o seu POC. Se você for novo nos Pools do Apache Spark no Azure Synapse Analytics, você poderá consultar esta documentação e obter uma visão geral da arquitetura do Spark e entender como ela funciona no Azure Synapse.
Desenvolva uma compreensão desses conceitos principais:
- Apache Spark e a arquitetura distribuída dele.
- Conceitos do Spark, como RDD (Conjuntos de Dados Distribuídos Resilientes) e partições (em memória e físicas).
- Workspace do Azure Synapse, os diferentes mecanismos de computação, o pipeline e o monitoramento.
- Separação de computação e armazenamento no pool do Spark.
- Autenticação e autorização no Azure Synapse.
- Conectores nativos que se integram ao pool de SQL dedicado do Azure Synapse, ao Azure Cosmos DB e a outros.
O Azure Synapse separa os recursos de computação do armazenamento para que você possa gerenciar melhor suas necessidades de processamento de dados e controlar os custos. A arquitetura sem servidor do pool do Spark permite que você gire para cima e para baixo, bem como aumente e reduza seu cluster do Spark, independentemente do armazenamento. Você pode pausar um cluster do Spark por completo (ou configurar uma pausa automática). Dessa forma, você paga pela computação somente quando ela está em uso. Quando ela não está em uso, você paga apenas pelo armazenamento. Você pode escalar verticalmente o cluster do spark para necessidades pesadas de processamento de dados ou cargas grandes, depois dimensioná-lo novamente durante momentos de processamento menos intensos (ou desligá-lo por completo). Você pode escalar e pausar efetivamente um cluster para reduzir os custos. Os testes de POC do Spark devem incluir ingestão de dados e processamento de dados em diferentes escalas (pequenas, médias e grandes) para comparar os preços e o desempenho nesses diferentes cenários. Para mais informações, confira Dimensionar automaticamente os pools do Apache Spark no Azure Synapse Analytics.
É importante entender a diferença entre os diferentes conjuntos de APIs do Spark para que você possa decidir o que funciona melhor no seu cenário. Você pode escolher aquele que fornece melhor desempenho ou facilidade de uso, aproveitando os conjuntos de habilidades existentes da sua equipe. Para obter mais informações, confira A história de três APIs do Apache Spark: RDDs, DataFrames e Conjuntos de Dados.
O particionamento de dados e arquivos funciona de maneira ligeiramente diferente no Spark. Entender as diferenças ajudará você a otimizar o desempenho. Para mais informações, confira a documentação do Apache Spark: Opções de configuração de partição e descoberta de partição.
Definir as metas
Um projeto de POC bem-sucedido exige planejamento. Comece identificando por que você está fazendo um POC a fim de entender por completo as motivações reais. As motivações podem incluir modernização, redução de custos, melhoria de desempenho ou experiência integrada. Documente metas claras para seu POC, bem como critérios que definirão o sucesso dele. Pergunte-se:
- O que você deseja obter como resultado do seu POC?
- O que você fará com esses resultados?
- Quem usará os resultados?
- O que definirá se o POC foi bem-sucedido?
Tenha em mente que um POC deve ser um esforço curto e concentrado para comprovar rapidamente um conjunto limitado de conceitos e funcionalidades. Esses conceitos e funcionalidades devem ser representativos da carga de trabalho geral. Se você tiver uma longa lista de itens a serem provados, talvez seja o caso de planejar mais de um POC. Nesse caso, defina os limites entre os POCs para determinar quando precisa passar para o próximo. Considerando as diferentes funções profissionais que podem usar notebooks e pools do Spark no Azure Synapse, você pode optar por executar vários POCs. Por exemplo, um POC pode se concentrar em requisitos para a função de engenharia de dados, como ingestão e processamento. Outro POC pode se concentrar no desenvolvimento de modelos de ML (machine learning).
Ao considerar suas metas de POC, faça as seguintes perguntas para definir as metas:
- Você está migrando de uma plataforma existente de análise avançada e de big data (local ou na nuvem)?
- Você está migrando, mas deseja fazer o menor número possível de alterações na ingestão e no processamento de dados existentes? Por exemplo, uma migração do Spark para o Spark ou uma migração do Hadoop/Hive para o Spark.
- Você está migrando, mas deseja fazer algumas melhorias extensas ao longo do percurso? Por exemplo, redigir trabalhos MapReduce como trabalhos do Spark ou converter código baseado em RDD herdado em código baseado em DataFrame/Conjunto de Dados.
- Você está criando uma plataforma de análise avançada e big data totalmente nova (projeto greenfield)?
- Quais são suas dificuldades atuais? Por exemplo, escalabilidade, desempenho ou flexibilidade.
- A quais novos requisitos de negócios você precisa dar suporte?
- Quais são os SLAs que você precisa atender?
- Quais serão as cargas de trabalho? Por exemplo, ETL, processamento em lote, processamento de fluxo, treinamento de modelo de machine learning, análise, consultas de relatório ou consultas interativas?
- Quais são as habilidades dos usuários que serão proprietários do projeto (caso o POC seja implementado)? Por exemplo, habilidades PySpark vs Scala, experiência com notebooks vs IDE.
Aqui estão alguns exemplos de configuração de metas de POC:
- Por que estamos fazendo um POC?
- Precisamos estar seguros de que o desempenho de ingestão e processamento de dados da nossa carga de trabalho de Big Data atenderá aos nossos novos SLAs.
- Precisamos saber se o processamento de fluxo quase em tempo real é possível e a taxa de transferência a que ele pode dar suporte. (Ele dará suporte aos nossos requisitos de negócios?)
- Precisamos saber se nossos processos de ingestão e transformação de dados existentes são adequados e onde teremos que fazer melhorias.
- Precisamos saber se – e quanto – podemos reduzir nossos tempos de execução para integração de dados.
- Precisamos saber se nossos cientistas de dados podem criar e treinar modelos de machine learning e aproveitar as bibliotecas de IA/ML conforme necessário em um pool do Spark.
- A mudança para o Synapse Analytics baseado em nuvem atenderá às nossas metas de custo?
- Ao final deste POC:
- Teremos os dados para determinar se nossos requisitos de desempenho de processamento de dados podem ser atendidos para streaming em lote e em tempo real.
- Testaremos a ingestão e o processamento de todos os nossos diferentes tipos de dados (estruturados, semi e não estruturados) que dão suporte a nossos casos de uso.
- Testaremos alguns dos nossos processamentos de dados complexos existentes e poderemos identificar o trabalho que precisará ser concluído para migrar nosso portfólio de integração de dados para o novo ambiente.
- Testaremos a ingestão e o processamento de dados e teremos os pontos de dados para estimar os esforços necessários para a migração inicial e a carga de dados históricos, bem como para estimar os esforços necessários para migrar nossa ingestão de dados (ADF [Azure Data Factory], Distcp, Databox ou outras).
- Testaremos a ingestão e o processamento de dados e poderemos determinar se nossos requisitos de processamento ETL/ELT podem ser atendidos.
- Teremos obtido insights para estimar melhor os esforços necessários para concluir o projeto de implementação.
- Testaremos as opções de escala e dimensionamento e teremos os pontos de dados para configurar melhor nossa plataforma para melhores definições de preço-desempenho.
- Teremos uma lista de itens que talvez precisem de mais testes.
Planejar o projeto
Use suas metas para identificar testes específicos e fornecer os resultados identificados. É importante que você tenha pelo menos um teste para fundamentar cada meta e resultado esperados. Além disso, identifique a ingestão de dados específica, o processamento em lote ou em fluxos e todos os outros processos que serão executados para que você possa identificar um conjunto de dados e uma base de código muito específicos. Esse conjunto de dados específico e a base de código definirão o escopo do POC.
Aqui está um exemplo do nível necessário de especificidade no planejamento:
- Meta A: precisamos saber se nosso requisito de ingestão de dados e processamento de dados em lotes pode ser atendido no SLA definido.
- Resultado A: teremos os dados para determinar se nossa ingestão e processamento de dados em lote podem atender aos requisitos de processamento de dados e ao SLA.
- Teste A1: as consultas de processamento A, B e C são identificadas como bons testes de desempenho, pois geralmente são executadas pela equipe de engenharia de dados. Além disso, elas representam necessidades gerais de processamento de dados.
- Teste A2: as consultas de processamento X, Y e Z são identificadas como bons testes de desempenho, pois contêm requisitos de processamento de fluxo quase em tempo real. Além disso, elas representam as necessidades gerais de processamento de fluxo baseados em eventos.
- Teste A3: compare o desempenho dessas consultas em uma escala diferente do cluster do Spark (número variado de nós de trabalho, tamanho dos nós de trabalho – como número pequeno, médio e grande – e tamanho de executores) com o parâmetro de comparação obtido do sistema existente. Mantenha em mente a lei de redução de retornos; adicionar mais recursos (seja escalando vertical ou horizontalmente) pode ajudar a alcançar o paralelismo, no entanto, há um determinado limite exclusivo para cada cenário a fim de alcançar o paralelismo. Descubra a configuração ideal para cada caso de uso identificado em seus testes.
- Meta B: precisamos saber se nossos cientistas de dados podem criar e treinar modelos de aprendizado de máquina nesta plataforma.
- Resultado B: testaremos alguns de nossos modelos de machine learning treinando-os em dados em um pool do Spark ou em um pool de SQL, aproveitando diferentes bibliotecas de machine learning. Esses testes ajudarão a determinar quais modelos de machine learning podem ser migrados para o novo ambiente
- Teste B1: modelos específicos de machine learning serão testados.
- Teste B2: testar bibliotecas de machine learning base que vêm com o Spark (Spark MLLib) juntamente com uma biblioteca adicional que pode ser instalada no Spark (como scikit-learn) para atender aos requisitos.
- Meta C: testaremos a ingestão de dados e teremos os pontos de dados para:
- Estimar os esforços para nossa migração de dados históricos inicial para o data lake e/ou para o pool do Spark.
- Planeje uma abordagem para migrar dados históricos.
- Resultado C: testaremos e determinado a taxa de ingestão de dados que pode ser alcançada em nosso ambiente e poderemos determinar se nossa taxa de ingestão de dados é suficiente para migrar dados históricos durante a janela de tempo disponível.
- Teste C1: testar diferentes abordagens para a migração de dados históricos. Para mais informações, confira Transferir dados de/para o Azure.
- Teste C2: identifique a largura de banda alocada do ExpressRoute e se há qualquer configuração de limitação pela equipe de infra. Para mais informações, confira O que é o Azure ExpressRoute? (opções de largura de banda).
- Teste C3: testar a taxa de transferência de dados para a migração de dados online e offline. Para obter mais informações, confira Guia de desempenho e escalabilidade da atividade Copy.
- Teste C4: testar a transferência de dados do data lake para o pool de SQL usando o comando ADF, Polybase ou COPY. Para mais informações, confira Estratégias de carregamento de dados para pool de SQL dedicado no Azure Synapse Analytics.
- Meta D: testaremos a taxa de ingestão de dados do carregamento incremental de dados e teremos os pontos de dados para estimar a janela de tempo de ingestão e processamento de dados para o data lake e/ou para o pool de SQL dedicado.
- Resultado D: testaremos a taxa de ingestão de dados e poderemos determinar se nossos requisitos de ingestão e processamento de dados podem ser atendidos com a abordagem identificada.
- Teste D1: testar a ingestão e o processamento de dados de atualização diária.
- Teste D2: testar o carregamento de dados processados para a tabela de pool de SQL dedicado do pool do Spark. Para mais informações, confira Conector do Pool de SQL Dedicado do Azure Synapse para Apache Spark.
- Teste D3: execute o processo de carregamento de atualização diária simultaneamente durante a execução de consultas do usuário final.
Refine seus testes adicionando vários cenários de teste. O Azure Synapse facilita o teste de diferentes escalas (número variado de nós de trabalho, com tamanhos distintos – pequeno, médio e grande) para comparar desempenho e comportamento.
Aqui estão alguns cenários de teste possíveis:
- Teste do pool do Spark A: executaremos o processamento de dados em vários tipos de nós (pequenos, médios e grandes), bem como diferentes números de nós de trabalho.
- Teste do pool do Spark B: carregaremos/recuperaremos dados processados do pool do Spark para o pool de SQL dedicado usando o conector.
- Teste do Pool do Spark C: carregaremos/recuperaremos dados processados do pool do Spark para o Azure Cosmos DB usando o Link do Azure Synapse.
Avaliar o conjunto de dados da POC
Usando os testes específicos que você identificou, selecione um conjunto de dados para fundamentar os testes. Reserve um tempo para examinar esse conjunto de dados. Você deve verificar se o conjunto de dados representará adequadamente seu processamento futuro em termos de conteúdo, complexidade e escala. Não use um conjunto de dados pequeno demais (menor que 1 TB), pois ele não terá um desempenho representativo. Por outro lado, não use um conjunto de dados grande demais, pois o POC não deve se tornar uma migração completa de dados. Obtenha os parâmetros de comparação apropriados com sistemas existentes para que você possa usá-los na comparação do desempenho.
Importante
Verifique com os proprietários de negócios se há impedimentos antes de mover os dados para a nuvem. Identifique todas as preocupações de segurança ou de privacidade ou necessidades de ofuscação de dados que devem ser feitas antes de mover dados para a nuvem.
Criar uma arquitetura geral
Com base na visão geral da arquitetura proposta para seu estado futuro, identifique os componentes que farão parte do POC. Sua arquitetura geral do estado futuro provavelmente contém muitas fontes de dados, vários consumidores de dados, componentes de Big Data e, possivelmente, consumidores de dados de IA (machine learning e inteligência artificial). Sua arquitetura de POC deve identificar especificamente componentes que farão parte do POC. O mais importante: ela deve identificar todos os componentes que não fazem parte do teste de POC.
Se você já estiver usando o Azure, identifique todos os recursos já existentes (Microsoft Entra ID, ExpressRoute e outros) que você pode usar durante a POC. Identifique também as regiões do Azure que sua organização usa. Agora é um excelente momento para identificar a taxa de transferência da sua conexão com o ExpressRoute e verificar com outros usuários de negócios se o seu POC consegue consumir parte dessa taxa de transferência sem ter impacto negativo nos sistemas de produção.
Para obter mais informações, confira arquiteturas de Big Data.
Identificar recursos de POC
Identifique especificamente os recursos técnicos e os compromissos de tempo necessários para dar suporte ao seu POC. Seu POC precisará de:
- Um representante comercial para supervisionar os requisitos e os resultados.
- Um especialista em dados de aplicativo para fornecer os dados ao POC e compartilhar conhecimentos sobre os processos e as lógica existentes.
- Um especialista em Apache Spark e em pools do Spark.
- Um consultor especialista para otimizar os testes de POC.
- Recursos que serão necessários para componentes específicos do seu projeto de POC, mas não necessariamente necessários durante o POC. Esses recursos podem incluir administradores de rede, administradores do Azure, administradores do Active Directory, administradores do portal do Azure e outros.
- Verifique se todos os recursos de serviços do Azure necessários estão provisionados e se o nível de acesso necessário foi concedido, incluindo acesso a contas de armazenamento.
- Verifique se você tem uma conta com as permissões de acesso a dados necessárias para recuperar dados de todas as fontes de dados no escopo do POC.
Dica
É recomendável contratar um consultor especialista para auxiliar em seu POC. A comunidade de parceiros da Microsoft tem disponibilidade global de consultores especialistas que podem ajudá-lo a apurar, avaliar ou implementar o Azure Synapse.
Definir a linha do tempo
Examine os detalhes de planejamento do POC e as necessidades de negócios a fim de identificar um período para o POC. Faça estimativas realistas do tempo necessário para concluir as metas do POC. O tempo para concluir o POC será influenciado pelo tamanho do conjunto de dados utilizado, o número de testes e a complexidade deles, e o número de interfaces a serem testadas. Se você estimar que seu POC será executado por mais de quatro semanas, considere reduzir o escopo para se concentrar nas metas de maior prioridade. Obtenha a aprovação e o comprometimento de todos os principais recursos e patrocinadores antes de continuar.
Colocar a POC em prática
Recomendamos que você execute seu projeto de POC com disciplina e rigor equivalentes a um projeto de produção. Execute o projeto de acordo com o plano e gerencie um processo de solicitação de alteração para evitar o crescimento descontrolado do escopo do POC.
Aqui estão alguns exemplos de tarefas gerais:
Crie um workspace do Synapse, pools do Spark e pools de SQL dedicados, contas de armazenamento e todos os recursos do Azure identificados no plano do POC.
Carregar conjunto de dados do POC:
- Disponibilize dados no Azure extraindo da origem ou criando dados de exemplo no Azure. Para obter mais informações, consulte:
- Teste o conector dedicado para o pool do Spark e o pool de SQL dedicado.
Migre códigos existentes para o pool do Spark:
- Se você estiver migrando do Spark, os esforços de migração provavelmente serão simples, dado que o pool do Spark aproveita a distribuição de código aberto do Spark. No entanto, se você estiver usando recursos específicos do fornecedor sobre os principais recursos do Spark, será necessário mapear corretamente esses recursos para os recursos do pool do Spark.
- Se você estiver migrando de um sistema não relacionado ao Spark, seus esforços de migração poderão variar de acordo com a complexidade envolvida.
Execute os testes:
- Muitos testes podem ser executados em paralelo, em vários clusters de pool do Spark.
- Registre seus resultados em um formato consumível e facilmente compreensível.
Monitore a solução de problemas e o desempenho. Para obter mais informações, consulte:
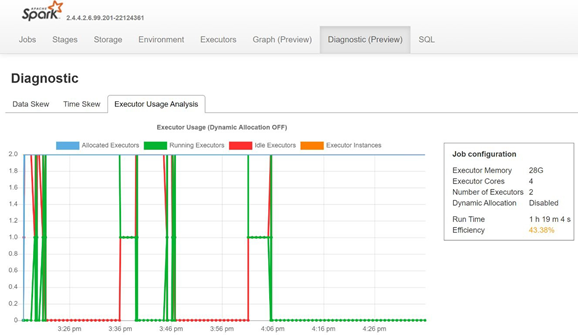
Monitore a distorção de dados, a distorção de tempo e o percentual de uso do executor abrindo a guia Diagnóstico do servidor de histórico do Spark.
Interpretar os resultados do POC
Ao concluir todos os testes de POC, você avaliará os resultados. Comece avaliando se as metas do POC foram atingidas e se as saídas desejadas foram coletadas. Determine se mais testes são necessários ou se alguma questão precisa ser abordada.