Início Rápido: ingerir dados com um clique (versão prévia)
A ingestão com um clique torna o processo de ingestão de dados fácil, rápido e intuitivo. A ingestão com um clique ajuda a aumentar rapidamente para começar a ingerir dados, criar tabelas de banco de dados e mapear estruturas. Selecione dados de diferentes tipos de fontes em formatos de dados diferentes, seja como um processo de ingestão única ou contínua.
Os seguintes recursos tornam a ingestão com um clique muito útil:
- Experiência intuitiva guiada pelo assistente de ingestão
- Ingerir dados em questão de minutos
- Ingerir dados de diferentes tipos de fontes: arquivo local, blobs e contêineres (até 10.000 blobs)
- Ingerir dados em uma variedade de formatos
- Ingerir dados em tabelas novas ou existentes
- O esquema e o mapeamento de tabela são sugeridos para você e são fáceis de alterar
A ingestão com um clique é particularmente útil ao ingerir dados pela primeira vez ou quando o esquema dos dados não é conhecido para você.
Pré-requisitos
Uma assinatura do Azure. Criar uma conta gratuita do Azure.
Criar um pool do Data Explorer usando o Synapse Studio ou o portal do Azure
Criar um banco de dados do Data Explorer.
No Synapse Studio, no painel esquerdo, selecione Dados.
Selecione + (Adicionar novo recurso) >Pool do Data Explorer e use as seguintes informações:
Configuração Valor sugerido Descrição Nome do pool contosodataexplorer O nome do pool do Data Explorer a ser usado Nome TestDatabase O nome do banco de dados deve ser exclusivo dentro do cluster. Período de retenção padrão 365 O período de tempo (em dias) durante o qual há a garantia de que os dados serão mantidos disponíveis para consulta. O período é medido a partir do momento em que os dados são incluídos. Período de cache padrão 31 O período de tempo (em dias) durante o qual os dados consultados com frequência devem ser mantidos disponíveis no armazenamento SSD ou RAM, em vez de no armazenamento de longo prazo. Selecione Criar para criar o banco de dados. A criação geralmente leva menos de um minuto.
Criar uma tabela
- No Synapse Studio, no painel do lado esquerdo, selecione Desenvolver.
- Em Scripts KQL, selecione + (Adicionar novo recurso) >Script KQL. No painel do lado direito, você pode nomear o script.
- No menu Conexão, selecione contosodataexplorer.
- No menu Usar banco de dados, selecione TestDatabase.
- Cole o comando a seguir e selecione Executar para criar uma tabela.
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)Dica
Verifique se a tabela foi criada com êxito. No painel esquerdo, selecione Dados, selecione o menu contosodataexplorer e, em seguida, selecione Atualizar. Em contosodataexplorer, expanda Tabelas e verifique se a tabela StormEvents é exibida na lista.
Acessar o assistente com um clique
O assistente da ingestão com um clique orientará você pelo processo da ingestão com um clique.
Para acessar o assistente do Azure Synapse:
No Synapse Studio, no painel esquerdo, selecione Dados.
Em Bancos de Dados do Data Explorer, clique com o botão direito do mouse no banco de dados relevante e selecione Abrir no Azure Data Explorer.
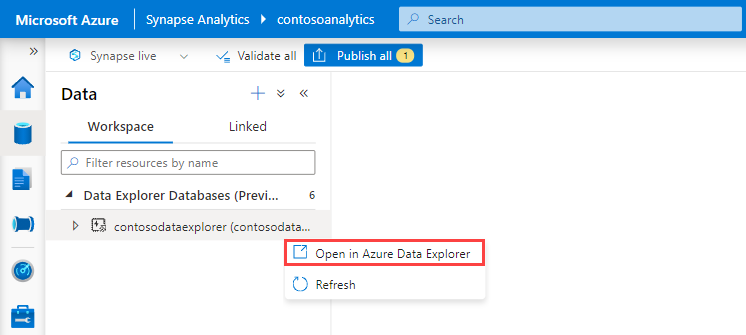
Clique com o botão direito do mouse no pool relevante e selecione Ingerir novos dados.
Para acessar o assistente do portal do Azure:
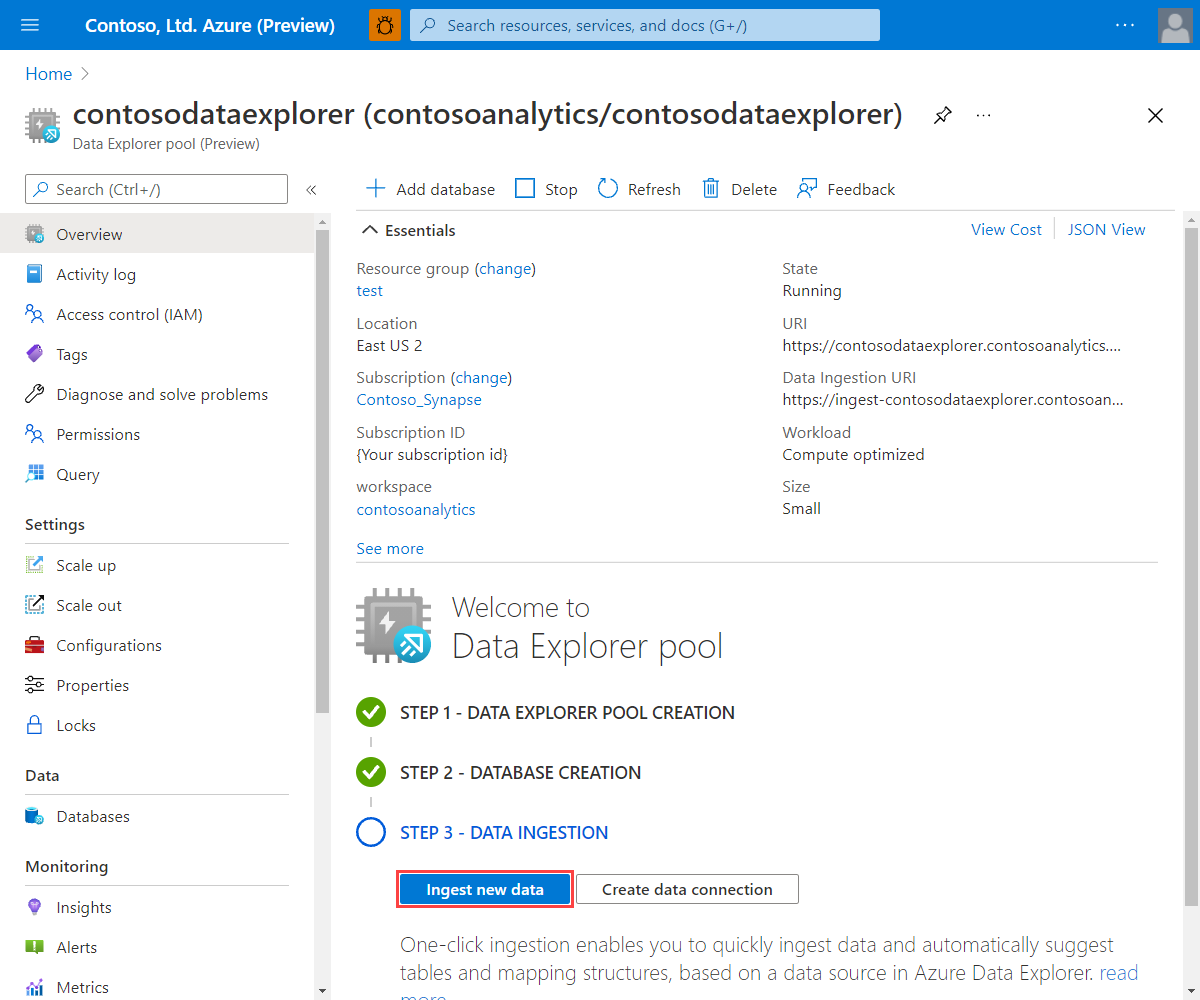
Na portal do Azure, pesquise e selecione o workspace relevante do Synapse.
Em Pools do Data Explorer, selecione o pool relevante.
Na tela inicial de Boas-vindas ao pool do Data Explorer, selecione Ingerir novos dados.
Para acessar o assistente na IU da Web do Azure Data Explorer:
- Antes de começar, use as etapas a seguir para obter os pontos de extremidade de Consulta e Ingestão de Dados.
No Synapse Studio, no painel do lado esquerdo, selecione Gerenciar>Pools do Data Explorer.
Selecione o pool do Data Explorer que você deseja usar para exibir os detalhes correspondentes.
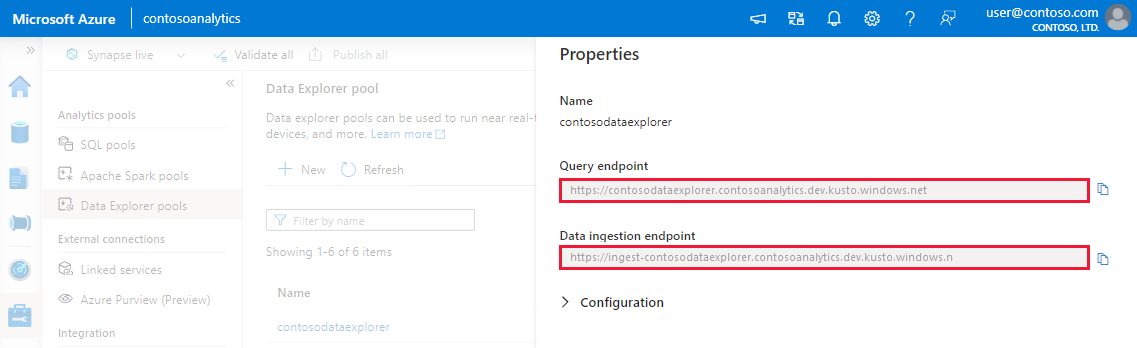
Anote os pontos de extremidade de Consulta e Ingestão de Dados. Use o ponto de extremidade de Consulta como o cluster ao configurar conexões com seu pool do Data Explorer. Ao configurar SDKs para ingestão de dados, use o ponto de extremidade de ingestão de dados.
- Na IU da Web do Azure Data Explorer, adicione uma conexão ao ponto de extremidade de consulta.
- Selecione Consulta no menu à esquerda, clique com o botão direito do mouse no banco de dados ou na tabela e selecione Ingerir novos dados.
- Antes de começar, use as etapas a seguir para obter os pontos de extremidade de Consulta e Ingestão de Dados.
Assistente da ingestão com um clique
Observação
Esta seção descreve o assistente usando o Hub de Eventos como a fonte de dados. Você também pode usar essas etapas para ingerir dados de um blob, arquivo, contêiner de blob e um contêiner ADLS Gen2.
Substitua os valores de exemplo por valores reais no seu workspace do Azure Synapse.
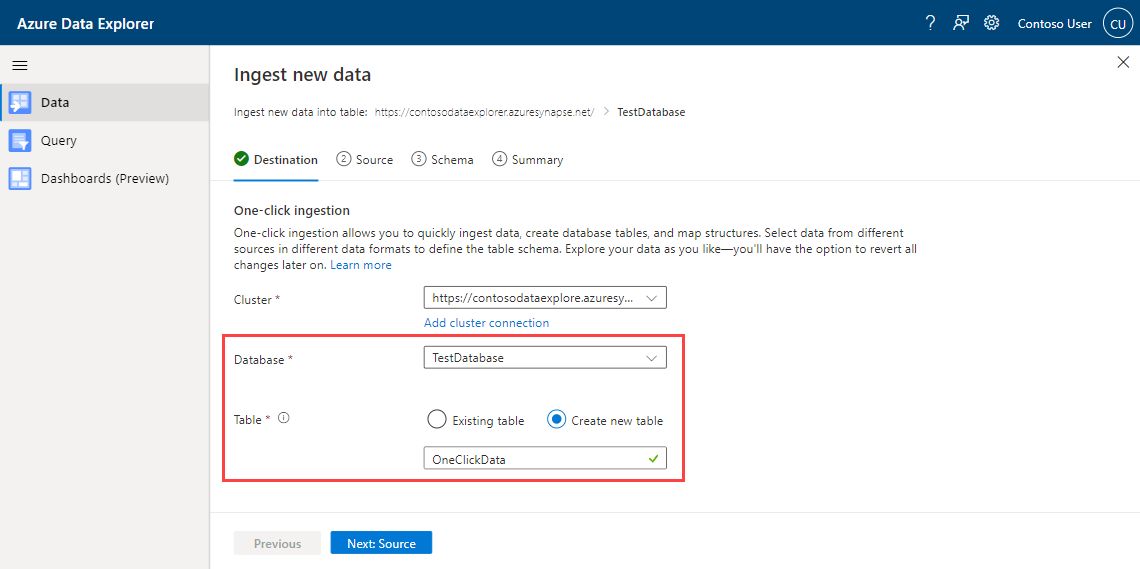
Na guia Destino, escolha o banco de dados e a tabela para os dados ingeridos.
Na guia Origem:
Selecione Hubs de Eventos como o Tipo de fonte para a ingestão.

Preencha os detalhes de conexão de dados do Hub de Eventos usando as seguintes informações:
Configuração Valor de exemplo Descrição Nome da conexão de dados ContosoDataConnection O nome da conexão de dados do Hub de Eventos Assinatura Contoso_Synapse A assinatura em que o Hub de Eventos reside. Namespace do Hub de Eventos contosoeventhubnamespace O namespace do Hub de Eventos. Grupo de consumidores contosoconsumergroup O nome do grupo de consumidores do Hub de Eventos. 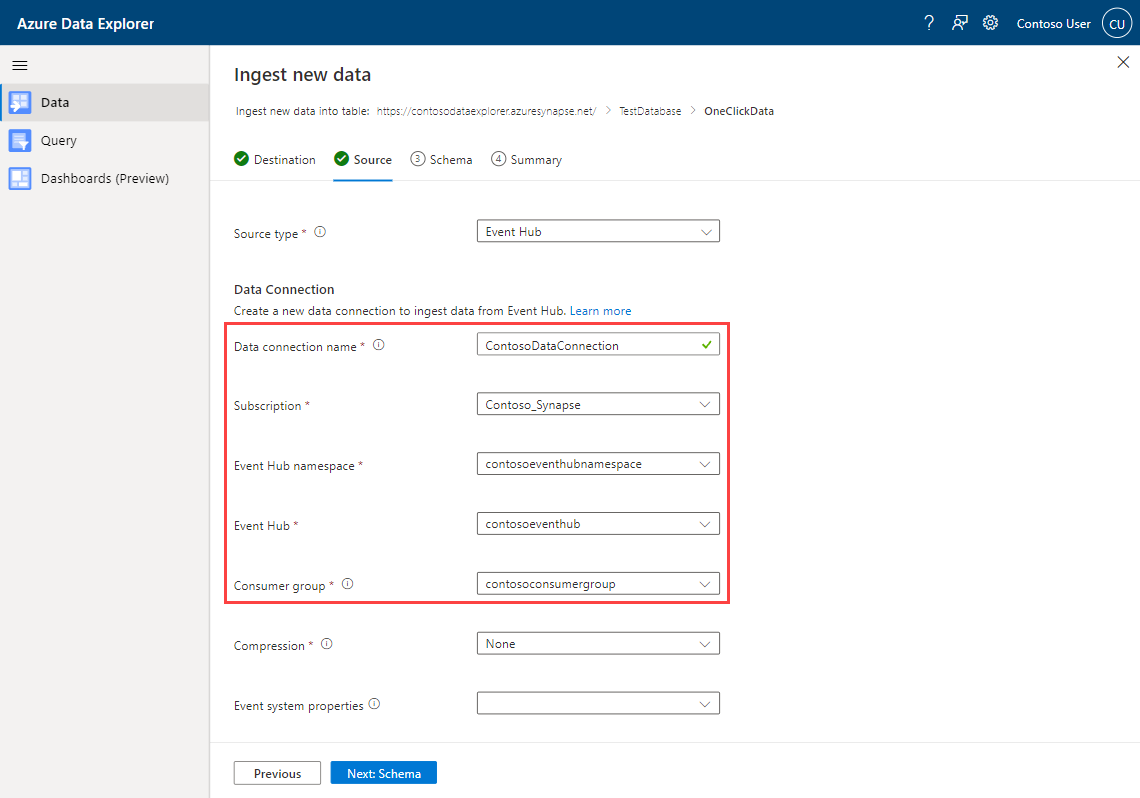
Selecione Avançar.
Mapeamento de esquema
O serviço gera automaticamente propriedades de esquema e de ingestão, que podem ser alteradas. É possível usar uma estrutura de mapeamento existente ou criar uma, dependendo se você está ingerindo em uma tabela nova ou existente.
Na guia Esquema, execute as seguintes ações:
- Confirme o tipo de compactação gerado automaticamente.
- Escolha o formato dos seus dados. Formatos diferentes permitirão que você faça outras alterações.
- Altere o mapeamento na janela Editor.
Formatos de arquivo
A ingestão com um clique dá suporte à ingestão de dados de origem em todos os formatos de dados compatíveis com o Data Explorer para ingestão.
Janela Editor
Na janela Editor da guia Esquema, é possível ajustar as colunas da tabela de dados conforme necessário.
As alterações que você pode fazer em uma tabela dependem dos seguintes parâmetros:
- O tipo de tabela é novo ou existente
- O tipo de mapeamento é novo ou existente
| Tipo de tabela | Tipo de mapeamento | Ajustes disponíveis |
|---|---|---|
| Nova tabela | Novo mapeamento | Alterar tipo de dados, Renomear coluna, Nova coluna, Excluir coluna, Atualizar coluna, Classificar em ordem crescente, Classificar em ordem decrescente |
| Tabela existente | Novo mapeamento | Nova coluna (na qual você pode alterar o tipo de dados, renomear e atualizar), Atualizar coluna, Classificar em ordem crescente, Classificar em ordem decrescente |
| Mapeamento existente | Classificar em ordem crescente, Classificar em ordem decrescente |
Observação
Ao adicionar uma nova coluna ou atualizar uma coluna, você pode alterar as transformações de mapeamento. Para obter mais informações, confira Transformações de mapeamento
Transformações de mapeamento
Alguns mapeamentos de formato de dados (Parquet, JSON e Avro) dão suporte a transformações de tempo de ingestão simples. Para aplicar transformações de mapeamento, crie ou atualize uma coluna na janela do Editor.
As transformações de mapeamento podem ser executadas em uma coluna de cadeia de caracteres de Tipo ou de datetime, com o tipo de dados int ou long selecionado em Origem. As transformações de mapeamento com suporte são:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Ingestão de dados
Depois que você concluir o mapeamento de esquema e as manipulações de coluna, o assistente de ingestão iniciará o processo de ingestão de dados.
Ao ingerir dados de outras fontes não contêiner, a ingestão terá efeito imediato.
Se sua fonte de dados for um contêiner:
- A política de envio em lote do Data Explorer agregará seus dados.
- Após a ingestão, é possível baixar o relatório de ingestão e examinar o desempenho de cada blob que foi resolvido.
Exploração inicial de dados
Após a ingestão, o assistente fornece opções para usar Comandos rápidos para a exploração inicial dos dados.