Detecção de anomalias no Azure Stream Analytics
Disponível na nuvem e no Azure IoT Edge, o Azure Stream Analytics oferece recursos internos de detecção de anomalias baseados em aprendizado de máquina que podem ser usados para monitorar as duas anomalias que ocorrem com mais frequência: temporárias e persistentes. Com as funções AnomalyDetection_SpikeAndDip e AnomalyDetection_ChangePoint, você pode detectar anomalias diretamente no seu trabalho do Stream Analytics.
Os modelos de machine learning supõem uma série temporal incluída na amostra de maneira uniforme. Se a série temporal não for uniforme, você poderá inserir uma etapa de agregação com uma janela de tombamento antes de chamar a detecção de anomalias.
No momento, as operações de aprendizado de máquina não são compatíveis com tendências de sazonalidade nem correlações multivariadas.
Detecção de anomalias usando o aprendizado de máquina Azure Stream Analytics
O vídeo a seguir demonstra como detectar uma anomalia em tempo real usando funções de aprendizado de máquina Azure Stream Analytics.
Comportamento do modelo
De modo geral, a precisão do modelo melhora com mais dados na janela deslizante. Os dados na janela deslizante especificada são tratados como parte de seu intervalo de valores normal para o período. O modelo considera o histórico de eventos ao longo da janela deslizante apenas para verificar se o evento atual é anormal. Conforme a janela deslizante se move, os valores antigos são removidos do treinamento do modelo.
As funções operam estabelecendo um determinado valor normal com base no que foi observado até o momento. As exceções são identificadas pela comparação em relação ao normal estabelecido, no nível de confiança. O tamanho da janela deve se basear nos eventos mínimos necessários para treinar o modelo para comportamento normal, de modo que ele esteja apto a reconhecê-la quando uma anomalia ocorrer.
O tempo de resposta do modelo aumenta com o tamanho do histórico, pois é preciso fazer a comparação com um número maior de eventos passados. Recomendamos que você inclua apenas o número necessário de eventos para um melhor desempenho.
As lacunas na série temporal podem ser um resultado do não recebimento de eventos pelo modelo em determinados pontos no tempo. Essa situação é tratada pelo Stream Analytics usando lógica de imputação. O tamanho do histórico e a duração para a mesma janela deslizante são usados para calcular a taxa média na qual os eventos são esperados.
Um gerador de anomalias disponível aqui pode ser usado para alimentar um hub IOT com dados com padrões de anomalia diferentes. Um trabalho do Azure Stream Analytics pode ser configurado com essas funções de detecção de anomalias para ler esse Hub Iot e detectar anomalias.
Pico e queda
As anomalias temporárias em um fluxo de eventos de série temporal são conhecidas como picos e quedas. Os picos e quedas podem ser monitorados usando o operador baseado em Machine Learning, AnomalyDetection_SpikeAndDip.
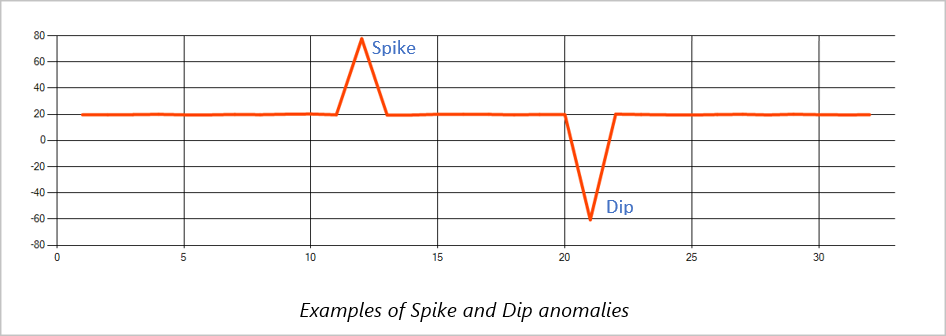
Na mesma janela deslizante, se um segundo pico for menor que o primeiro, a pontuação calculada para o menor pico provavelmente não será significativa o suficiente em comparação com a pontuação para o primeiro pico no nível de confiança especificado. Você pode tentar diminuir a configuração do nível de confiança do modelo para detectar essas anomalias. No entanto, se começar a receber muitos alertas, é possível usar um intervalo de confiança maior.
O exemplo de consulta a seguir pressupõe uma taxa uniforme de entrada de um evento por segundo em uma janela deslizante de 2 minutos com um histórico de 120 eventos. A instrução SELECT final extrai e gera a pontuação e o status da anomalia com um nível de confiança de 95%.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
Ponto de alteração
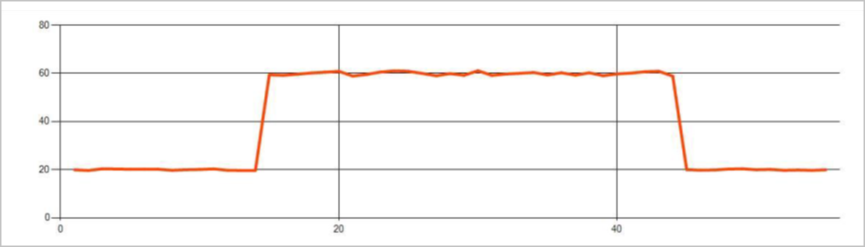
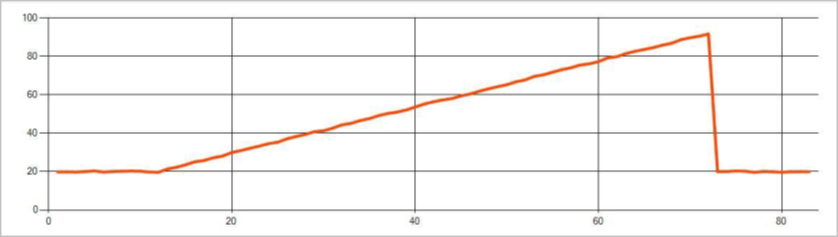
As anomalias persistentes em um fluxo de eventos de série temporal são alterações na distribuição de valores no fluxo de eventos, como alterações e tendências no nível. No Stream Analytics, tais anomalias são detectadas usando o operador AnomalyDetection_ChangePoint baseado em Machine Learning.
Mudanças persistentes duram muito mais do que picos e quedas e podem indicar eventos catastróficos. As alterações persistentes geralmente não são vistas a olho nu, mas podem ser detectadas com o operador AnomalyDetection_ChangePoint.
A seguinte imagem é um exemplo de alteração no nível:
A seguinte imagem é um exemplo de alteração na tendência:
A consulta de exemplo a seguir assume uma taxa de entrada uniforme de um evento por segundo em uma janela deslizante de 20 minutos com um tamanho de histórico de 1.200 eventos. A instrução SELECT final extrai e gera a pontuação e o status da anomalia com um nível de confiança de 80%.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
Características de desempenho
O desempenho desses modelos depende do tamanho do histórico, da duração da janela, da carga de eventos e do uso do particionamento no nível da função. Esta seção discute essas configurações e fornece exemplos de como sustentar taxas de ingestão de eventos de 1 K, 5 K e 10K por segundo.
- Tamanho do histórico - esses modelos são executados linearmente com o tamanho do histórico. Quanto maior o tamanho do histórico, mais tempo os modelos levam para pontuar um novo evento. É porque os modelos comparam o novo evento com cada um dos eventos passados no buffer de histórico.
- Duração da janela – a duração da janela deve refletir o tempo necessário para receber tantos eventos quantos forem especificados pelo tamanho do histórico. Sem esses muitos eventos na janela, Azure Stream Analytics imputar valores ausentes. Portanto, o consumo de CPU é uma função do tamanho do histórico.
- Carga de eventos - quanto maior a carga de eventos, mais trabalho é executado pelos modelos, o que afeta o consumo da CPU. O trabalho pode ser escalado para fora, tornando-o embaraçosamente paralelo, supondo que faça sentido para a lógica de negócios usar mais partições de entrada.
- Particionamento de nível de função - o particionamento de nível de função é feito usando
PARTITION BYa chamada de função de detecção de anomalias. Esse tipo de particionamento adiciona uma sobrecarga, pois o estado precisa ser mantido para vários modelos ao mesmo tempo. O particionamento no nível da função é usado em cenários como o particionamento no nível do dispositivo.
Relação
O tamanho do histórico, a duração da janela e a carga total do evento estão relacionados da seguinte maneira:
windowDuration (em ms) = 1000 * historySize/(total de eventos de entrada por segundo/contagem de partições de entrada)
Ao particionar a função por deviceId, adicione "PARTITION BY deviceId" à chamada de função de detecção de anomalias.
Observações
A tabela a seguir inclui as observações de taxa de transferência para um único nó (seis SU) para o caso não particionado:
| Tamanho do histórico (eventos) | Duração da janela (minutos) | Total de eventos de entrada por segundo |
|---|---|---|
| 60 | 55 | 2.200 |
| 600 | 728 | 1,650 |
| 6.000 | 10,910 | 1.100 |
A tabela a seguir inclui as observações de taxa de transferência para um único nó (seis SU) para o caso particionado:
| Tamanho do histórico (eventos) | Duração da janela (minutos) | Total de eventos de entrada por segundo | Contagem de dispositivos |
|---|---|---|---|
| 60 | 1\.091 | 1.100 | 10 |
| 600 | 10,910 | 1.100 | 10 |
| 6.000 | 218,182 | <550 | 10 |
| 60 | 21.819 | 550 | 100 |
| 600 | 218,182 | 550 | 100 |
| 6.000 | 2,181,819 | <550 | 100 |
O código de exemplo para executar as configurações não particionadas acima está localizado no repositório Streaming em Escala dos Exemplos do Azure. O código cria um trabalho do Stream Analytics sem particionamento de nível de função que usa Hubs de Eventos como entrada e saída. A carga de entrada é gerada usando clientes de teste. Cada evento de entrada é um documento json de 1 KB. Os eventos simulam um dispositivo IoT enviando dados JSON (para dispositivos de até 1 K). O tamanho do histórico, a duração da janela e a carga total de eventos são variados em duas partições de entrada.
Observação
Para obter uma estimativa mais precisa, personalize os exemplos para se ajustarem ao seu cenário.
Identificar gargalos
Para identificar gargalos em seu pipeline, use o painel Métricas em seu trabalho do Azure Stream Analytics. Examine Eventos de Entrada/Saída para taxa de transferência e "Atraso de Marca-d'água" ou Eventos Acumulados para ver se o trabalho está acompanhando a taxa de entrada. Para as métricas dos Hubs de Eventos, procure Solicitações Limitadas e ajuste as Unidades de Limite adequadamente. Para métricas do Azure Cosmos DB, examine Máximo de RU/s consumidas por intervalo de chaves de partição em Taxa de Transferência para verificar se os intervalos de chave de partição foram consumidos uniformemente. Para o BD SQL do Azure, monitore a E/S de Log e CPU.