Particionamento de saída de blob personalizado do Azure Stream Analytics
O Azure Stream Analytics dá suporte ao particionamento de saída de blob personalizado com campos ou atributos personalizados e padrões de caminho DateTime personalizados.
Campo ou atributos personalizados
Campo personalizado ou atributos de entrada melhoram os fluxos de trabalho de processamento de dados e relatório downstream permitindo mais controle sobre a saída.
Opções de chave de partição
A chave de partição ou nome da coluna, usada para particionar dados de entrada pode conter qualquer caractere aceitável como nomes de blob. Não é possível usar campos aninhados como uma chave de partição, a menos que sejam usados junto a aliases. No entanto, é possível usar determinados caracteres para criar uma hierarquia de arquivos. Por exemplo, para criar uma coluna que combine dados de duas outras colunas para fazer uma chave de partição exclusiva, é possível usar a consulta a seguir:
SELECT name, id, CONCAT(name, "/", id) AS nameid
A chave de partição deve ser NVARCHAR(MAX), BIGINT, FLOAT ou BIT (nível de compatibilidade 1.2 ou superior). Não há suporte para os tipos DateTime, Array e Records, mas eles podem ser usados como chaves de partição se forem convertidos em cadeias de caracteres. Para saber mais, confira Tipo de dados do Azure Stream Analytics.
Exemplo
Suponha que um trabalho pegue dados de entrada de sessões de usuário ativas conectadas a um serviço de videogame externo em que os dados ingeridos contêm uma coluna client_id para identificar as sessões. Para particionar os dados por client_id, defina o campo do blob padrão de caminho para incluir um token de partição {client_id} nas propriedades de saída de blob ao criar um trabalho. Como dados com vários valores de client_id fluem pelo trabalho do Stream Analytics, os dados de saída são salvos em pastas separadas com base em um único valor client_id por pasta.

Da mesma forma, se a entrada do trabalho for composta por dados do sensor de milhões de sensores em que cada sensor tem uma sensor_id, o padrão de caminho será {sensor_id} para particionar os dados de cada sensor em pastas diferentes.
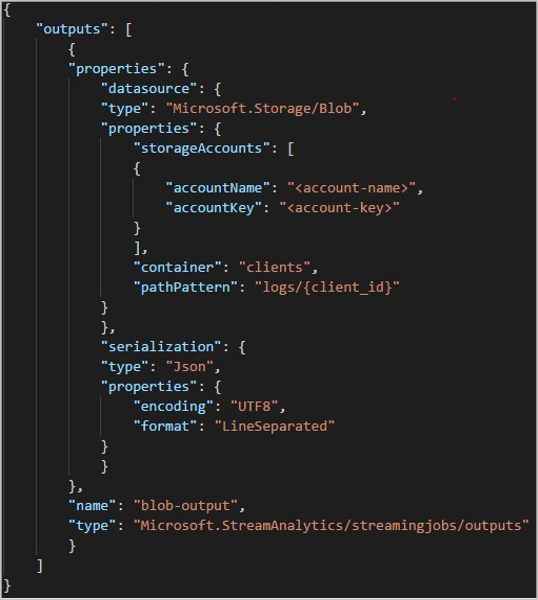
Quando você usa a API REST, a seção de saída de um arquivo JSON usado para essa solicitação pode ser semelhante à seguinte imagem:
Depois que o trabalho começa a ser executado, o contêiner de clients deve ser semelhante a seguinte imagem:
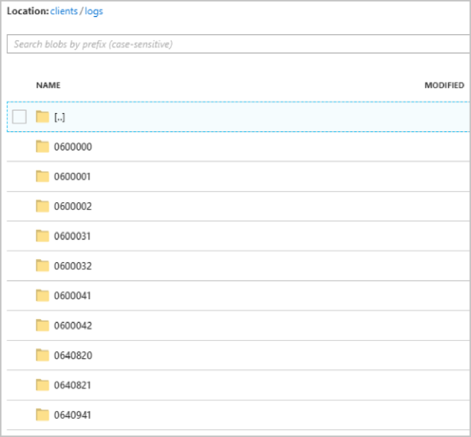
Cada pasta pode conter vários blobs em que cada blob contém um ou mais registros. No exemplo anterior, há um único blob em uma pasta rotulada "06000000" com o seguinte conteúdo:
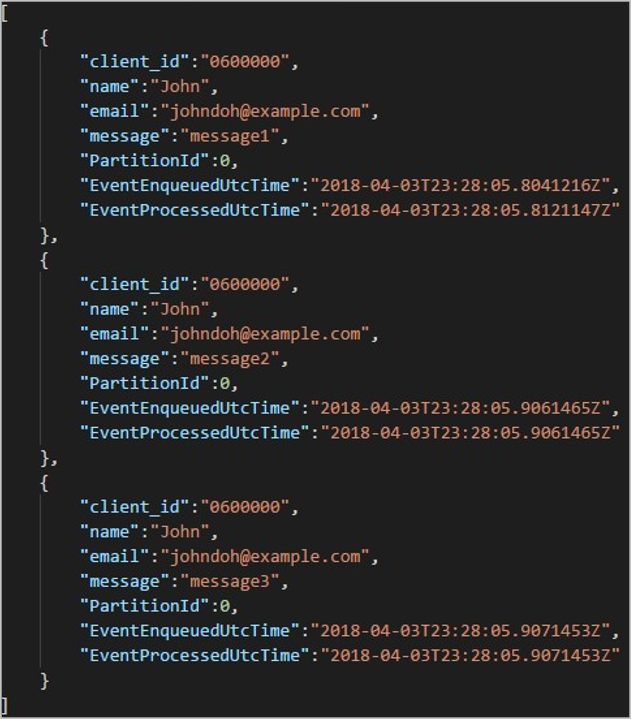
Observe que cada registro no blob tem uma coluna client_id correspondendo ao nome da pasta, porque a coluna usada para particionar a saída no caminho de saída era client_id.
Limitações
Apenas uma chave de partição personalizada é permitida na propriedade de saída de blob do padrão de caminho. Todos os padrão de caminho a seguir são válidos:
cluster1/{date}/{aFieldInMyData}cluster1/{time}/{aFieldInMyData}cluster1/{aFieldInMyData}cluster1/{date}/{time}/{aFieldInMyData}
Se os clientes quiserem usar mais de um campo de entrada, eles poderão criar uma chave composta na consulta para partição de caminho personalizado na saída de blob usando
CONCAT. Um exemplo éselect concat (col1, col2) as compositeColumn into blobOutput from input. Em seguida, eles podem especificarcompositeColumncomo o caminho personalizado no Armazenamento de Blobs do Azure.Chaves de partição diferenciam maiúsculas de minúsculas, portanto, as chaves de partição, como
Johnejohnsão equivalentes. Além disso, expressões não podem ser usadas como chaves de partição. Por exemplo,{columnA + columnB}não funciona.Quando um fluxo de entrada consiste em registros com uma cardinalidade de chave de partição abaixo de 8.000, os registros são acrescentados a blobs existentes. Eles só criam novos blobs quando necessário. Se a cardinalidade for superior a 8.000, não haverá garantia de que os blobs existentes serão gravados. Novos blobs não serão criados para um número arbitrário de registros com a mesma chave de partição.
Se a saída do blob estiver configurada como imutável, o Stream Analytics cria um novo blob sempre que os dados forem enviados.
Padrões de caminho de DateTime personalizados
Padrões de caminho de DateTime personalizados permitem que você especifique um formato de saída que se alinhe com as convenções de Streaming de Hive, possibilitando ao Stream Analytics enviar dados para o Azure HDInsight e o Azure Databricks para processamento downstream. Padrões de caminho de DateTime personalizados são implementados facilmente usando a palavra-chave datetime no campo de Prefixo de caminho de sua saída de blob, juntamente com o especificador de formato. Um exemplo é {datetime:yyyy}.
Tokens com suporte
Os seguintes tokens especificadores de formato podem ser usados sozinhos ou de forma combinada para chegar aos formatos de DateTime personalizados.
| Especificador de formato | Descrição | Resulta na hora de exemplo 2018-01-02T10:06:08 |
|---|---|---|
| {datetime:yyyy} | O ano como um número de quatro dígitos | 2018 |
| {datetime:MM} | Mês de 01 a 12 | 01 |
| {datetime:M} | Mês de 1 a 12 | 1 |
| {datetime:dd} | Dia de 01 a 31 | 02 |
| {datetime:d} | Dia de 1 a 31 | 2 |
| {datetime:HH} | Hora usando o formato de 24 horas, de 00 a 23 | 10 |
| {datetime:mm} | Minutos de 00 a 60 | 06 |
| {datetime:m} | Minutos de 0 a 60 | 6 |
| {datetime:ss} | Segundos de 00 a 60 | 08 |
Se você não quiser usar padrões personalizados DateTime, poderá adicionar o token {date} e/ou {time} ao campo Prefixo de caminho para gerar uma lista suspensa com formatos internos DateTime.
Extensibilidade e restrições
Você pode usar tantos tokens ({datetime:<specifier>}) quantos quiser no padrão do caminho, até alcançar o limite de caracteres do prefixo do caminho. Especificadores de formato não podem ser combinados em um único token além das combinações já listadas pelos menus suspensos de data e hora.
Para uma partição de caminho de logs/MM/dd:
| Expressão válida | Expressão inválida |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
Você pode usar o mesmo especificador de formato várias vezes no prefixo do caminho. O token deve ser repetido a cada vez.
Convenções de streaming de Hive
Padrões de caminho personalizados para o Armazenamento de Blobs podem ser usados com a convenção de Streaming de Hive, que espera que as pastas sejam rotuladas com column= no nome da pasta.
Um exemplo é year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}.
A saída personalizada elimina o incômodo de alterar as tabelas e adicionar partições manualmente para mover dados entre o Stream Analytics e o Hive. Em vez disso, muitas pastas podem ser adicionadas automaticamente usando:
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
Exemplo
Crie uma conta de armazenamento, um grupo de recursos, um trabalho do Stream Analytics e uma fonte de entrada de acordo com o início rápido do Portal do Azure no Stream Analytics. Use os mesmos dados de exemplo usados no início rápido. Os dados de exemplo também estão disponíveis no GitHub.
Crie um coletor de saída de blob com a seguinte configuração:
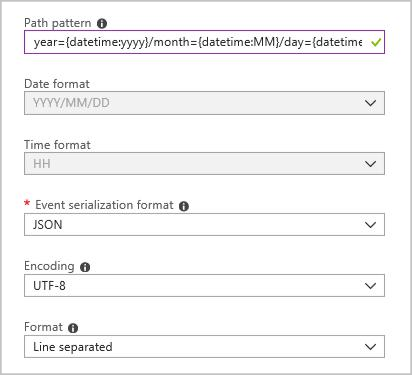
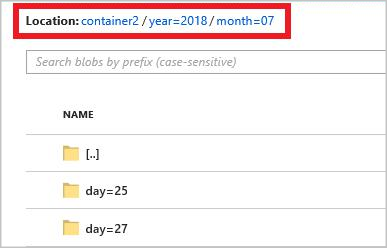
O padrão de caminho completo é:
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
Quando você inicia o trabalho, uma estrutura de pastas com base no padrão do caminho é criada em seu contêiner de blob. Você pode fazer drill down até o nível do dia.