Filtrar e ingerir para o SQL do Azure Synapse usando o editor sem código do Stream Analytics
Este artigo descreve como você pode usar o editor sem código para criar um trabalho do Stream Analytics com facilidade. Ele lê continuamente nos Hubs de Eventos, filtra os dados de entrada e grava os resultados continuamente em uma tabela de SQL do Synapse.
Pré-requisitos
- Os recursos dos Hubs de Eventos do Azure devem ser acessíveis publicamente e não podem estar protegidos por um firewall ou em uma Rede Virtual do Azure.
- Os dados nos Hubs de Eventos precisam ser serializados no formato JSON, CSV ou Avro.
Desenvolver um trabalho do Stream Analytics para filtrar e ingerir dados
Use as etapas a seguir para desenvolver um trabalho do Stream Analytics para filtrar e ingerir dados em tempo real em uma tabela de SQL do Synapse.
No portal do Azure, localize e selecione a instância dos Hubs de Eventos do Azure.
Selecione Recursos>Processar Dados e selecione Iniciar no cartão Filtrar e ingerir para o SQL do Synapse.
Insira um nome para identificar o trabalho do Stream Analytics e selecione Criar.
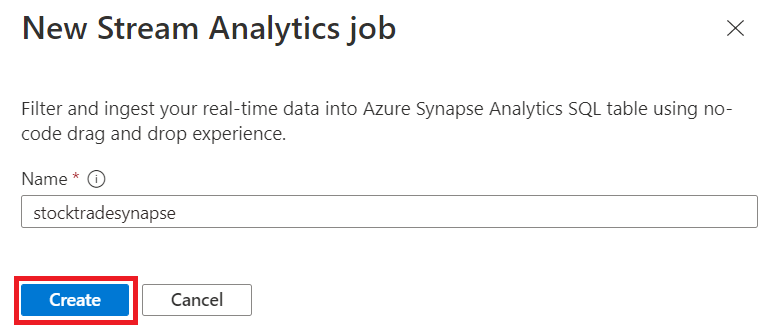
Especifique o tipo de Serialização dos dados na janela Hubs de Eventos e o Método de autenticação que o trabalho usará para se conectar aos Hubs de Eventos. Depois, selecione Conectar.
Quando a conexão for estabelecida com êxito e você tiver fluxos de dados para a instância dos Hubs de Eventos, você verá duas coisas imediatamente:
- Os campos presentes nos dados de entrada. Você pode escolher Adicionar campo ou selecionar o símbolo de três pontos ao lado de um campo para remover, renomear ou alterar o tipo.
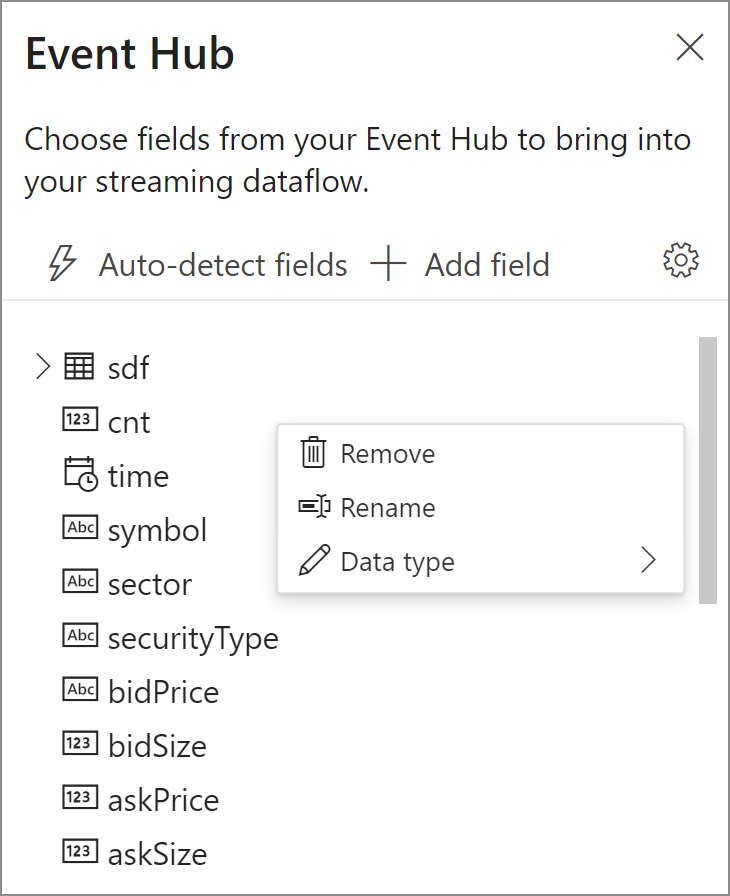
- Um exemplo dinâmico dos dados de entrada na tabela Visualização de dados na exibição de diagrama. Ele é atualizado automaticamente com regularidade. Você pode selecionar Pausar visualização de streaming para ver uma exibição estática dos dados de entrada de exemplo.

- Os campos presentes nos dados de entrada. Você pode escolher Adicionar campo ou selecionar o símbolo de três pontos ao lado de um campo para remover, renomear ou alterar o tipo.
Na área Filtro, selecione um campo para filtrar os dados de entrada com uma condição.
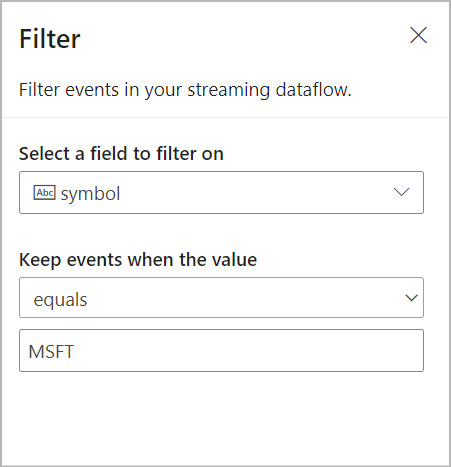
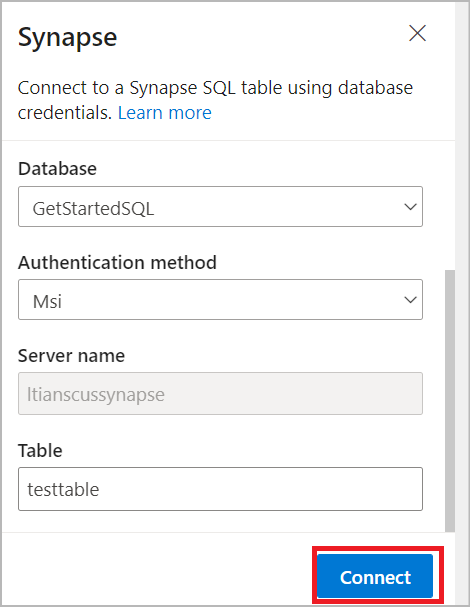
Selecione a tabela SQL do Synapse para enviar seus dados filtrados:
- Selecione Assinatura, Banco de Dados (nome do pool de SQL dedicado) e Método de autenticação no menu suspenso.
- Insira o nome da tabela em que os dados filtrados serão ingeridos. Selecione Conectar.
Observação
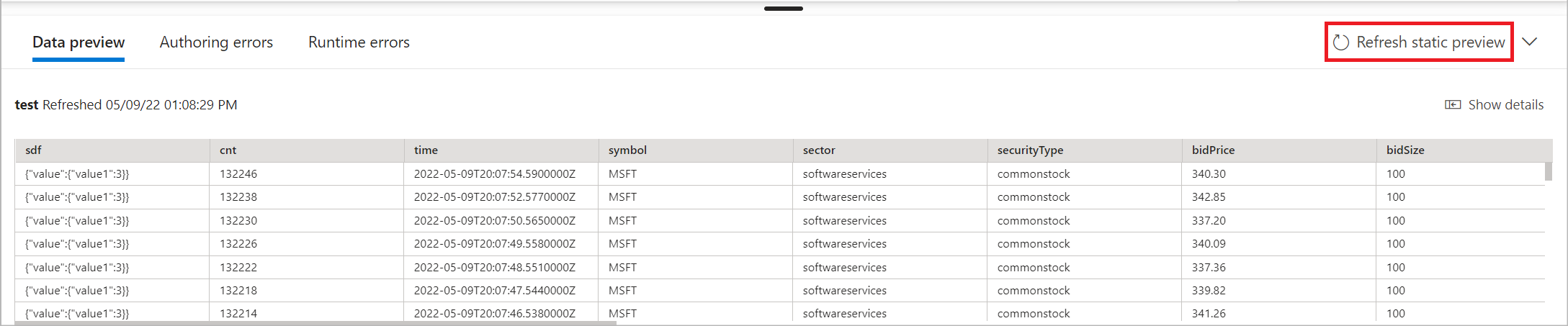
O esquema de tabela precisa corresponder exatamente ao número de campos e tipos gerados pela pré-visualização dos dados.
Como alterativa, selecione Obter visualização estática/Atualizar visualização estática para ver a visualização de dados que será ingerida na tabela selecionada do SQL do Synapse.
Selecione Salvar e depois escolha Iniciar o trabalho do Stream Analytics.
Para iniciar o trabalho, especifique:
- Selecione o número de SUs (unidades de streaming) com as quais o trabalho é executado. As SUs representam a quantidade de computação e memória alocada para o trabalho. É recomendável começar com três e depois ajuste conforme necessário.
- Tratamento de erros de dados de saída – permite que você especifique o comportamento desejado quando a saída de um trabalho para seu destino falhar devido a erros de dados. Por padrão, seu trabalho tenta novamente até que a operação de gravação seja bem-sucedida. Você também pode optar por remover esses eventos de saída.
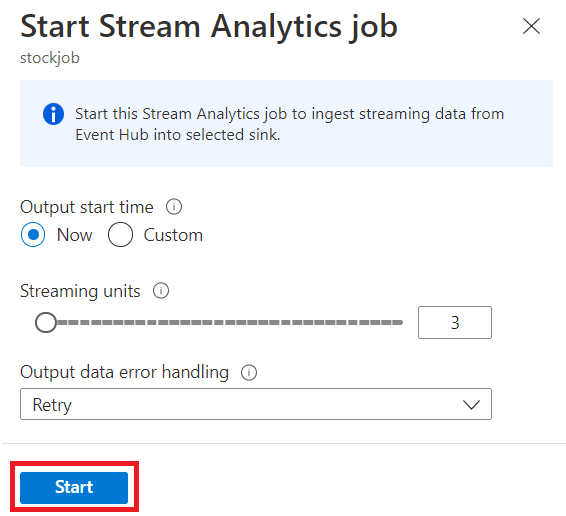
Depois de selecionar Iniciar, o trabalho começará a ser executado em até dois minutos e as métricas serão abertas na seção da guia abaixo.
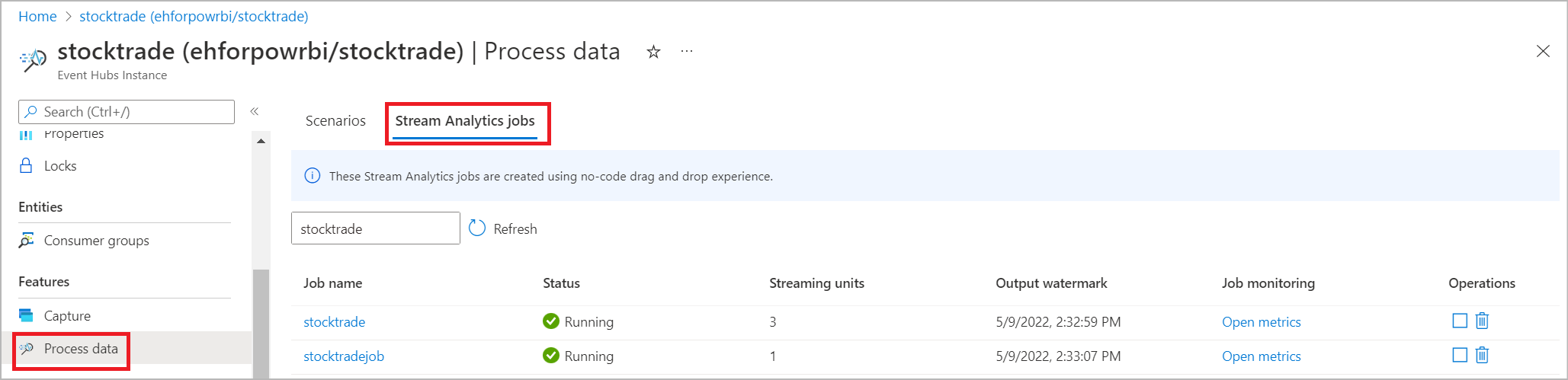
Você também pode ver o trabalho na seção Processar Dados na guia Trabalhos do Stream Analytics. Selecione Abrir métricas para monitorá-las ou interrompê-las e reiniciá-las, conforme o necessário.











Considerações ao usar o recurso de replicação geográfica dos Hubs de Eventos do Azure
Os Hubs de Eventos do Azure lançaram recentemente a versão prévia pública do recurso de replicação geográfica. Esse recurso é diferente do recurso de recuperação de desastres geográficos dos Hubs de Eventos do Azure.
Quando o tipo de failover é Forçado e a consistência de replicação é Assíncrona, o trabalho do Stream Analytics não garante exatamente uma saída para uma saída dos Hubs de Eventos do Azure.
O Azure Stream Analytics, como produtor com um hub de eventos e uma saída, pode observar um atraso de marca d'água no trabalho durante a duração do failover e durante a limitação pelos Hubs de Eventos caso o atraso de replicação entre o primário e o secundário atinja o atraso máximo configurado.
O Azure Stream Analytics, como consumidor com Hubs de Eventos como entrada, pode observar um atraso de marca d'água no trabalho durante a duração do failover e pode pular dados ou encontrar dados duplicados após a conclusão do failover.
Devido a essas limitações, recomendamos que você reinicie o trabalho do Stream Analytics com a hora de início apropriada logo após a conclusão do failover dos Hubs de Eventos do Azure. Além disso, como o recurso de replicação geográfica dos Hubs de Eventos do Azure está em versão prévia pública, não recomendamos usar esse padrão para trabalhos de produção do Stream Analytics no momento. O comportamento atual do Stream Analytics será aprimorado antes da disponibilidade geral do recurso de replicação geográfica dos Hubs de Eventos para uso em trabalhos de produção do Stream Analytics.
Próximas etapas
Saiba mais sobre o Azure Stream Analytics e como monitorar o trabalho criado.