Como funciona a recuperação planejada gerenciada pelo cliente (versão prévia)
O failover planejado gerenciado pelo cliente pode ser útil em cenários como planejamento e teste de desastre e recuperação, correção proativa de desastres previstos em larga escala e interrupções não relacionadas à recuperação.
Durante o processo de recuperação planejada, as regiões primária e secundária da sua conta de armazenamento são trocadas. A região primária original é rebaixada e torna-se a nova secundária, enquanto a região secundária original é promovida e torna-se a nova primária. A conta de armazenamento deve estar disponível nas regiões primária e secundária antes que uma recuperação planejada possa ser iniciada.
Este artigo descreve o que acontece durante um failover e failback planejados da conta de armazenamento gerenciada pelo cliente em cada fase do processo. Para entender como funciona um failover devido a uma interrupção inesperada do ponto de extremidade de armazenamento, confira Como o failover gerenciado pelo cliente (não planejado).
Importante
A recuperação planejada gerenciada pelo cliente está atualmente em PREVIEW e limitado às seguintes regiões:
- Leste da Ásia
- Sudeste Asiático
- Leste da Austrália
- Sudeste da Austrália
- França Central
- Sul da França
- Centro da Índia
- Oeste da Índia
- Oeste da Suíça
- Norte da Suíça
Para aceitar a visualização, consulte Configurar recursos de visualização na assinatura do Azure e especifique AllowSoftFailover como o nome do recurso. O nome do provedor para essa versão prévia do recurso é Microsoft.Storage.
Veja os Termos de Uso Complementares para Versões Prévias do Microsoft Azure para obter termos legais que se aplicam aos recursos do Azure que estão em versão beta, versão prévia ou que, de outra forma, ainda não foram lançados em disponibilidade geral.
Importante
Após uma recuperação planejada, o valor LST (última hora de sincronização) de uma conta de armazenamento pode parecer obsoleto ou ser relatado como NULL quando os dados dos Arquivos do Azure estiverem presentes.
Os instantâneos do sistema são criados periodicamente na região secundária de uma conta de armazenamento para manter pontos de recuperação consistentes usados durante o failover e o failback. Iniciar a recuperação planejada gerenciada pelo cliente faz com que a região primária original se torne a nova secundária. Em alguns casos, não há instantâneos do sistema disponíveis na nova secundária após a conclusão da recuperação planejada, fazendo com que o valor do LST geral da conta pareça desatualizado ou seja exibido como Null.
Como as atividades do usuário, como criar, modificar ou excluir objetos, podem acionar a criação de instantâneos, qualquer conta na qual essas atividades ocorram após a recuperação planejada não exigirá atenção adicional. No entanto, as contas que não têm instantâneos ou atividade do usuário podem continuar exibindo um valor Null de LST até que a criação do instantâneo do sistema seja acionada.
Se necessário, execute uma das seguintes atividades para cada compartilhamento em uma conta de armazenamento para disparar a criação de instantâneo. Após a conclusão, sua conta deverá exibir um valor de LST válido dentro de 30 minutos.
- Monte o compartilhamento e abra qualquer arquivo para leitura.
- Carregue um arquivo de teste ou de exemplo no compartilhamento.
Gerenciamento de redundância durante failover e failback planejados
Dica
Para entender os vários estados de redundância durante o processo de failover e failback gerenciado pelo cliente em detalhes, consulte Redundância de Armazenamento do Microsoft Azure, para obter definições de cada um.
Durante o processo de recuperação planejada, os pontos de extremidade do serviço de armazenamento da região primária tornam-se somente leitura, e todas as atualizações restantes concluem a replicação para a região secundária. Em seguida, todas as entradas DNS (serviço de nome de domínio) do ponto de extremidade de serviço de armazenamento são alternadas. Os pontos de extremidade secundários da conta de armazenamento tornam-se os novos pontos de extremidade primários e os pontos de extremidade primários originais tornam-se os novos secundários. A replicação de dados em cada região permanece inalterada, embora as regiões primária e secundária sejam alternadas.
O processo de failback planejado é essencialmente o mesmo que o processo de recuperação planejada, mas com uma exceção. Durante o failback planejado, o Azure armazena a configuração de redundância original da sua conta de armazenamento e a restaura para seu estado original após o failback. Por exemplo, se sua conta de armazenamento foi originalmente configurada como o GZRS, a conta de armazenamento será o GZRS após o failback.
Observação
Ao contrário do failover (não planejado) gerenciado pelo cliente, durante a recuperação planejada, a replicação da região primária para a secundária precisa ser concluída antes que as entradas de DNS para os pontos de extremidade sejam alteradas para a nova secundária. Por isso, a perda de dados não é esperada durante o failover ou failback planejados, desde que as regiões primária e secundária estejam disponíveis durante todo o processo.
Como iniciar um failover
Para saber como iniciar um failover, consulte Iniciar um failover de conta.
O processo de failover e failback planejados
Os diagramas a seguir mostram o que acontece durante uma recuperação planejada gerenciada pelo cliente e o failback de uma conta de armazenamento.
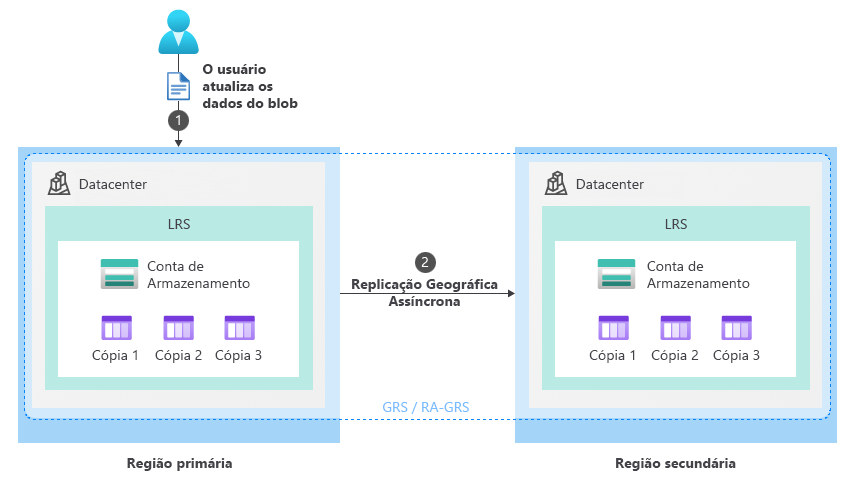
Em circunstâncias normais, um cliente grava dados em uma conta de armazenamento na região primária por meio de pontos de extremidade do serviço de armazenamento (1). Os dados são então copiados de forma assíncrona da região primária para a região secundária (2). A imagem a seguir mostra o estado normal de uma conta de armazenamento configurada como GRS:

O processo de recuperação planejada (GRS/RA-GRS)
Inicie o teste de recuperação de desastre ao iniciar um failover da sua conta de armazenamento para a região secundária. Confira uma descrição das etapas do processo de failover planejado e a imagem seguinte fornece uma ilustração:
- A região primária perde temporariamente o acesso de leitura e gravação. Os usuários RA-GRS ou RA-GZRS continuarão tendo acesso de leitura na região secundária.
- A replicação de todos os dados da região primária para a região secundária é concluída.
- As entradas de DNS para pontos de extremidade de serviço de armazenamento na região secundária são promovidas e se tornam os novos pontos de extremidade primários para sua conta de armazenamento.
O failover normalmente leva cerca de uma hora.

Depois que o failover for concluído, a região primária original se tornará a nova secundária (1) e a região secundária original se tornará a nova primária (2). Os URIs para os ponto de extremidade de serviço de armazenamento para blobs, tabelas, filas e arquivos permanecem os mesmos, mas suas entradas de DNS são alteradas para apontar para a nova região primária (3). Os usuários podem retomar a gravação de dados na conta de armazenamento na nova região primária e os dados são copiados de forma assíncrona para a nova secundária (4), conforme mostrado na seguinte imagem:

Enquanto estiver no estado de failover, execute o teste de recuperação de desastre.
O processo de failback planejado (GRS/RA-GRS)
Após a conclusão do teste, execute outro failover para fazer failback para a região primária original. Durante o processo de failover, conforme mostrado na imagem a seguir:
- A região primária perde temporariamente o acesso de leitura e gravação. Os usuários RA-GRS ou RA-GZRS continuarão tendo acesso de leitura na região secundária.
- Todos os dados terminam de replicar da região primária atual para a região secundária atual.
- As entradas de DNS para os pontos de extremidade de serviço de armazenamento são alteradas para apontar de volta para a região que era a principal antes do failover inicial ser executado.
O failback normalmente leva cerca de uma hora.

Depois que o failback for concluído, a conta de armazenamento será restaurada para a configuração de redundância original. Os usuários podem retomar a gravação de dados na conta de armazenamento na região primária original (1), enquanto a replicação para a secundária original (2) continua como antes do failover: