Tutorial: Monitorar um cluster do Service Fabric no Azure
O monitoramento e o diagnóstico são essenciais para o desenvolvimento, os testes e a implantação de cargas de trabalho em qualquer ambiente. Este tutorial é a segunda parte de uma série e mostra como monitorar e diagnosticar um cluster do Service Fabric usando eventos, contadores de desempenho e relatórios de integridade. Para obter mais informações, leia a visão geral sobre monitoramento de cluster e monitoramento de infraestrutura.
Neste tutorial, você aprenderá como:
- Exibir eventos do Service Fabric
- Consultar APIs do EventStore para eventos de cluster
- Monitorar a infraestrutura/coletar contadores de desempenho
- Exibir relatórios de integridade do cluster
Nesta série de tutoriais, você aprenderá a:
- Criar um cluster do Windows seguro no Azure usando um modelo
- Monitorar um cluster
- Reduzir ou escalar um cluster horizontalmente
- Atualizar o runtime de um cluster
- Excluir um cluster
Observação
Recomendamos que você use o módulo Az PowerShell do Azure para interagir com o Azure. Para começar, consulte Instalar o Azure PowerShell. Para saber como migrar para o módulo Az PowerShell, confira Migrar o Azure PowerShell do AzureRM para o Az.
Pré-requisitos
Antes de começar este tutorial:
- Se você não tem uma assinatura do Azure, crie uma conta gratuita
- Instale o Azure PowerShell ou a CLI do Azure.
- Crie um cluster do Windows seguro
- Configure a coleção de diagnósticos para o cluster
- Habilite o EventStore serviço no cluster
- Configure os logs do Azure Monitor e o agente do Log Analytics para o cluster
Exiba os eventos do Service Fabric usando os logs do Azure Monitor
O Azure Monitor coleta e analisa a telemetria dos aplicativos e serviços hospedados na nuvem e fornece as ferramentas de análise para ajudar a maximizar sua disponibilidade e desempenho. É possível executar consultas no Azure Monitor para obter informações e solucionar problemas que estão acontecendo em seu cluster.
Para acessar a solução de análise do Service Fabric, vá para o portal do Azure e selecione o grupo de recursos em que você criou a solução de Análise do Service Fabric.
Selecione o recurso ServiceFabric(meuespaçodetrabalho) .
Em Visão geral você verá o bloco na forma de um gráfico para cada uma das soluções habilitadas, incluindo uma para o Service Fabric. Selecione o gráfico Service Fabric para continuar para a solução Análise do Service Fabric.
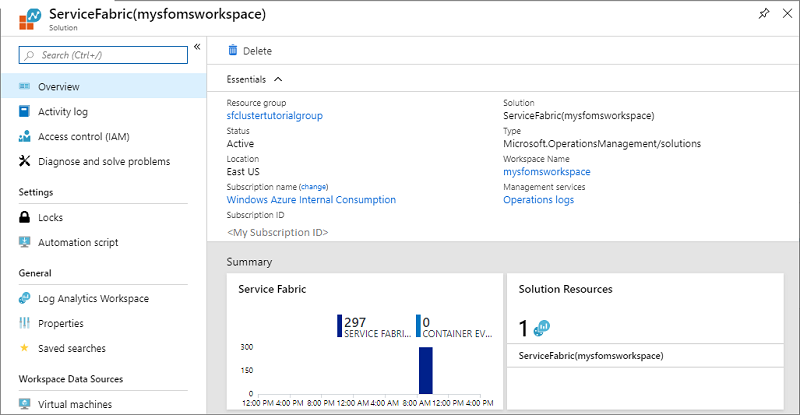
A imagem acima é a home page da solução de Análise do Service Fabric. Essa home page fornece uma visão instantânea do que está acontecendo no seu cluster.
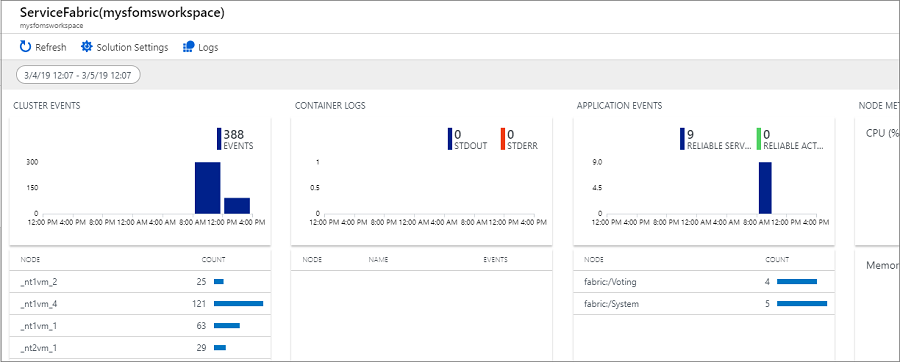
Se você habilitou o diagnóstico após a criação do cluster, você pode ver eventos para
- Eventos de cluster do Service Fabric
- Eventos do modelo de programação Reliable Actors
- Eventos do modelo de programação Reliable Services
Observação
Além dos eventos do Service Fabric prontos para uso, é possível coletar eventos do sistema mais detalhados ao atualizar a configuração da sua extensão de diagnóstico.
Exibir eventos do Service Fabric, incluindo ações em nós
Na página Análise do Service Fabric, clique no grafo para Eventos do Cluster. Os logs para todos os eventos do sistema que foram coletados aparecem. A consulta usa a linguagem de consulta do Kusto, que você pode modificar para refinar o que você estiver procurando. Por exemplo, para localizar todas as ações executadas em nós no cluster, você pode usar a consulta a seguir. As IDs de evento usadas abaixo são encontradas em referência de eventos do canal operacional.
ServiceFabricOperationalEvent
| where EventId < 25627 and EventId > 25619
A linguagem de consulta Kusto é eficiente. Aqui estão algumas outras consultas úteis.
Criar uma tabela de pesquisa ServiceFabricEvent como função definida pelo usuário, salvando a consulta como uma função com alias ServiceFabricEvent:
let ServiceFabricEvent = datatable(EventId: int, EventName: string)
[
...
18603, 'NodeUpOperational',
18604, 'NodeDownOperational',
...
];
ServiceFabricEvent
Eventos operacionais retornados registrados na última hora:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Retornar os eventos operacionais com EventId == 18604 e EventName == “NodeDownOperational”:
ServiceFabricOperationalEvent
| where EventId == 18604
| project EventId, EventName = 'NodeDownOperational', TaskName, Computer, EventMessage, TimeGenerated
| sort by TimeGenerated
Retornar os eventos operacionais com EventId == 18604 e EventName == “NodeUpOperational”:
ServiceFabricOperationalEvent
| where EventId == 18603
| project EventId, EventName = 'NodeUpOperational', TaskName, Computer, EventMessage, TimeGenerated
| sort by TimeGenerated
Retorna Health Reports com HealthState == 3 (Error) e extrai mais propriedades do campo EventMessage:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
Retornar um gráfico de tempo de eventos com EventId ! = 17523:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| where EventId != 17523
| summarize Count = count() by Timestamp = bin(TimeGenerated, 1h), strcat(tostring(EventId), " - ", case(EventName != "", EventName, "Unknown"))
| render timechart
Obter eventos operacionais do Service Fabric agregados ao serviço e nó específico:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
Renderizar a contagem de eventos do Service Fabric por EventId / EventName usando uma consulta de recursos cruzados:
app('PlunkoServiceFabricCluster').traces
| where customDimensions.ProviderName == 'Microsoft-ServiceFabric'
| extend EventId = toint(customDimensions.EventId), TaskName = tostring(customDimensions.TaskName)
| where EventId != 17523
| join kind=leftouter ServiceFabricEvent on EventId
| extend EventName = case(EventName != '', EventName, 'Undocumented')
| summarize ["Event Count"]= count() by bin(timestamp, 30m), EventName = strcat(tostring(EventId), " - ", EventName)
| render timechart
Visualizar os eventos do aplicativo do Service Fabric
Você pode exibir eventos para os aplicativos de serviço confiáveis e atores confiáveis implantados no cluster. Na página Análise do Service Fabric, selecione o gráfico para Eventos de Aplicativo.
Execute a consulta a seguir para exibir eventos de seus aplicativos de serviços confiáveis:
ServiceFabricReliableServiceEvent
| sort by TimeGenerated desc
Veja eventos diferentes para quando o serviço runasync é iniciado e concluído, o que normalmente acontece em implantações e atualizações.
Você também pode encontrar eventos para o serviço confiável com ServiceName == "fabric:/Watchdog/WatchdogService":
ServiceFabricReliableServiceEvent
| where ServiceName == "fabric:/Watchdog/WatchdogService"
| project TimeGenerated, EventMessage
| order by TimeGenerated desc
Os eventos de ator confiável podem ser exibidos de forma semelhante:
ServiceFabricReliableActorEvent
| sort by TimeGenerated desc
Para configurar os eventos mais detalhados para atores confiáveis, você pode alterar o scheduledTransferKeywordFilter na configuração para a extensão no modelo do cluster. Detalhes sobre os valores deles estão em referência de eventos de atores confiáveis.
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
Exibir contadores de desempenho com logs do Azure Monitor
Para visualizar contadores de desempenho, vá para o portal do Azure e para o grupo de recursos em que você criou a solução de Análise do Service Fabric.
Selecione o recurso ServiceFabric(mysfomsworkspace) , em seguida, Espaço de trabalho do Log Analyticse então Configurações avançadas.
Selecione Dados e escolha Contadores de desempenho do Windows. Há uma lista de contadores padrão que você pode ativar e também pode definir o intervalo de coleta. Você pode também adicionar contadores de desempenho adicionais para coletar. O formato correto é referenciado neste artigo. Clique em Salvar e selecione OK.
Feche a folha de Configurações Avançadas e selecione Resumo de workspace no título Geral. Para cada uma das soluções habilitadas há um bloco gráfico, incluindo um para Service Fabric. Selecione o gráfico Service Fabric para continuar para a solução Análise do Service Fabric.
Há blocos gráficos para o canal operacional e eventos de serviços confiáveis. A representação gráfica dos dados que fluem para os contadores selecionados aparece em Métricas do nó.
Selecione o gráfico Container Metric para ver mais detalhes. Você também pode consultar dados do contador de desempenho da mesma forma que os eventos de cluster e filtrar por nome do contador de desempenho, nós e valores, usando a linguagem de consulta Kusto.
Consultar o serviço EventStore
O serviço do EventStore fornece uma maneira de entender o estado do cluster ou cargas de trabalho em um determinado ponto no tempo. O EventStore é um serviço do Service Fabric com monitoramento de estado que mantém os eventos do cluster. Os eventos são expostos por meio do Service Fabric Explorer, REST e APIs. O EventStore consulta o cluster diretamente para obter os dados de diagnóstico em qualquer entidade no seu cluster para ver uma lista completa de eventos disponíveis na EventStore, consulte eventos do Service Fabric.
As APIs do EventStore podem ser consultadas programaticamente usando a biblioteca de clientes do Service Fabric.
Aqui está um exemplo de solicitação para todos os eventos de cluster entre 2018-04-03T18:00:00Z e 2018-04-04T18:00:00Z, por meio da função GetClusterEventListAsync.
var sfhttpClient = ServiceFabricClientFactory.Create(clusterUrl, settings);
var clstrEvents = sfhttpClient.EventsStore.GetClusterEventListAsync(
"2018-04-03T18:00:00Z",
"2018-04-04T18:00:00Z")
.GetAwaiter()
.GetResult()
.ToList();
Aqui está outro exemplo que consultará a integridade do cluster e todos os eventos de nó em setembro de 2018 e imprime-os.
const int timeoutSecs = 60;
var clusterUrl = new Uri(@"http://localhost:19080"); // This example is for a Local cluster
var sfhttpClient = ServiceFabricClientFactory.Create(clusterUrl);
var clusterHealth = sfhttpClient.Cluster.GetClusterHealthAsync().GetAwaiter().GetResult();
Console.WriteLine("Cluster Health: {0}", clusterHealth.AggregatedHealthState.Value.ToString());
Console.WriteLine("Querying for node events...");
var nodesEvents = sfhttpClient.EventsStore.GetNodesEventListAsync(
"2018-09-01T00:00:00Z",
"2018-09-30T23:59:59Z",
timeoutSecs,
"NodeDown,NodeUp")
.GetAwaiter()
.GetResult()
.ToList();
Console.WriteLine("Result Count: {0}", nodesEvents.Count());
foreach (var nodeEvent in nodesEvents)
{
Console.Write("Node event happened at {0}, Node name: {1} ", nodeEvent.TimeStamp, nodeEvent.NodeName);
if (nodeEvent is NodeDownEvent)
{
var nodeDownEvent = nodeEvent as NodeDownEvent;
Console.WriteLine("(Node is down, and it was last up at {0})", nodeDownEvent.LastNodeUpAt);
}
else if (nodeEvent is NodeUpEvent)
{
var nodeUpEvent = nodeEvent as NodeUpEvent;
Console.WriteLine("(Node is up, and it was last down at {0})", nodeUpEvent.LastNodeDownAt);
}
}
Monitorar a integridade do cluster
O Service Fabric apresenta um modelo de integridade com entidades de integridade nas quais os componentes do sistema e watchdogs podem relatar condições locais que estão monitorando. O repositório de integridade agrega todos os dados de integridade para determinar se as entidades estão íntegras.
O cluster é populado automaticamente com relatórios de integridade enviados pelos componentes do sistema. Leia mais em Usar relatórios de integridade do sistema para solução de problemas.
A Malha do Serviço expõe consultas de integridade para cada um dos tipos de entidadecom suporte. Elas podem ser acessados pela API usando métodos de FabricClient.HealthManager, por cmdlets do PowerShell e por REST. Essas consultas retornam informações de integridade completas sobre a entidade: o estado de integridade agregada, eventos de integridade da entidade, estados de integridade dos filhos (quando aplicável), avaliações não íntegras (quando a entidade não está íntegra) e estatísticas sobre a integridade dos filhos (quando aplicável).
Obter integridade do cluster
O cmdlet Get-ServiceFabricClusterHealth retorna a integridade da entidade do cluster e contém os estados da integridade de aplicativos e nós (filhos do cluster). Primeiro, conecte-se ao cluster usando o cmdlet Connect-ServiceFabricCluster.
O estado do cluster é de 11 nós, o aplicativo do sistema e fabric:/Voting configurado conforme descrito.
O exemplo a seguir obtém a integridade do cluster usando políticas de integridade padrão. O 11 nós estão íntegros, mas o estado de integridade agregado do cluster é Erro porque o aplicativo fabric:/Voting está no Erro. Observe como as avaliações não íntegras mostram com detalhes a condição que disparou a integridade agregada.
Get-ServiceFabricClusterHealth
AggregatedHealthState : Error
UnhealthyEvaluations :
100% (1/1) applications are unhealthy. The evaluation tolerates 0% unhealthy applications.
Application 'fabric:/Voting' is in Error.
33% (1/3) deployed applications are unhealthy. The evaluation tolerates 0% unhealthy deployed applications.
Deployed application on node '_nt2vm_3' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '8723eb73-9b83-406b-9de3-172142ba15f3' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376195593305'.
There was an error during CodePackage activation.The service host terminated with exit code:1
NodeHealthStates :
NodeName : _nt2vm_3
AggregatedHealthState : Ok
NodeName : _nt1vm_4
AggregatedHealthState : Ok
NodeName : _nt2vm_2
AggregatedHealthState : Ok
NodeName : _nt1vm_3
AggregatedHealthState : Ok
NodeName : _nt2vm_1
AggregatedHealthState : Ok
NodeName : _nt1vm_2
AggregatedHealthState : Ok
NodeName : _nt2vm_0
AggregatedHealthState : Ok
NodeName : _nt1vm_1
AggregatedHealthState : Ok
NodeName : _nt1vm_0
AggregatedHealthState : Ok
NodeName : _nt3vm_0
AggregatedHealthState : Ok
NodeName : _nt2vm_4
AggregatedHealthState : Ok
ApplicationHealthStates :
ApplicationName : fabric:/System
AggregatedHealthState : Ok
ApplicationName : fabric:/Voting
AggregatedHealthState : Error
HealthEvents : None
HealthStatistics :
Node : 11 Ok, 0 Warning, 0 Error
Replica : 4 Ok, 0 Warning, 0 Error
Partition : 2 Ok, 0 Warning, 0 Error
Service : 2 Ok, 0 Warning, 0 Error
DeployedServicePackage : 3 Ok, 1 Warning, 1 Error
DeployedApplication : 1 Ok, 1 Warning, 1 Error
Application : 0 Ok, 0 Warning, 1 Error
O exemplo a seguir obtém a integridade do cluster, usando uma política de aplicativo personalizado. Ele filtra os resultados para obter apenas os aplicativos e nós com erro ou aviso. Neste exemplo, nenhum nó é retornado, pois todos estão íntegros. Somente o aplicativo fabric:/Voting respeita o filtro de aplicativos. Como a política personalizada especifica a consideração de avisos como erros para o aplicativo fabric:/Voting, o aplicativo é avaliado como em estado de erro, assim como o cluster.
$appHealthPolicy = New-Object -TypeName System.Fabric.Health.ApplicationHealthPolicy
$appHealthPolicy.ConsiderWarningAsError = $true
$appHealthPolicyMap = New-Object -TypeName System.Fabric.Health.ApplicationHealthPolicyMap
$appUri1 = New-Object -TypeName System.Uri -ArgumentList "fabric:/Voting"
$appHealthPolicyMap.Add($appUri1, $appHealthPolicy)
Get-ServiceFabricClusterHealth -ApplicationHealthPolicyMap $appHealthPolicyMap -ApplicationsFilter "Warning,Error" -NodesFilter "Warning,Error" -ExcludeHealthStatistics
AggregatedHealthState : Error
UnhealthyEvaluations :
100% (1/1) applications are unhealthy. The evaluation tolerates 0% unhealthy applications.
Application 'fabric:/Voting' is in Error.
100% (5/5) deployed applications are unhealthy. The evaluation tolerates 0% unhealthy deployed applications.
Deployed application on node '_nt2vm_3' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '8723eb73-9b83-406b-9de3-172142ba15f3' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376195593305'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_2' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '2466f2f9-d5fd-410c-a6a4-5b1e00630cca' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376486201388'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_4' is in Error.
100% (1/1) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '5faa5201-eede-400a-865f-07f7f886aa32' is in Error.
'System.Hosting' reported Warning for property 'CodePackageActivation:Code:SetupEntryPoint:131959376207396204'. The evaluation treats
Warning as Error.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_0' is in Error.
100% (1/1) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '204f1783-f774-4f3a-b371-d9983afaf059' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959375885791093'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt3vm_0' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '2533ae95-2d2a-4f8b-beef-41e13e4c0081' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376108346272'.
There was an error during CodePackage activation.The service host terminated with exit code:1
NodeHealthStates : None
ApplicationHealthStates :
ApplicationName : fabric:/Voting
AggregatedHealthState : Error
HealthEvents : None
Obter integridade do nó
O cmdlet Get-ServiceFabricNodeHealth retorna a integridade de uma entidade de nó e contém os eventos de integridade reportados no nó. Primeiro, conecte-se ao cluster usando o cmdlet Connect-ServiceFabricCluster. O exemplo a seguir obtém a integridade de um nó específico usando políticas de integridade padrão:
Get-ServiceFabricNodeHealth _nt1vm_3
O exemplo a seguir obtém a integridade de todos os nós no cluster:
Get-ServiceFabricNode | Get-ServiceFabricNodeHealth | select NodeName, AggregatedHealthState | ft -AutoSize
Obter integridade do serviço de sistema
Obter a integridade agregada dos serviços do sistema:
Get-ServiceFabricService -ApplicationName fabric:/System | Get-ServiceFabricServiceHealth | select ServiceName, AggregatedHealthState | ft -AutoSize
Próximas etapas
Neste tutorial, você aprendeu a:
- Exibir eventos do Service Fabric
- Consultar APIs do EventStore para eventos de cluster
- Monitorar a infraestrutura/coletar contadores de desempenho
- Exibir relatórios de integridade do cluster
Em seguida, avance para o próximo tutorial para saber como dimensionar o cluster.