Descrever um cluster do Service Fabric usando o Gerenciador de Recursos de Cluster
O recurso Gerenciador de Recursos de Cluster do Azure Service Fabric fornece vários mecanismos para descrever um cluster:
- Domínios de falha
- Domínios de atualização
- Propriedades de nó
- Capacidades de nó
Durante o runtime, o Gerenciador de Recursos de Cluster usa essas informações para garantir a alta disponibilidade dos serviços executados no cluster. Ao aplicar essas regras importantes, ele também tenta otimizar o consumo de recursos dentro do cluster.
Domínios de falha
Um domínio de falha é qualquer área da falha coordenada. Um só computador é um domínio de falha. Ele pode falhar por conta própria por vários motivos diferentes, desde falhas de fornecimento de energia até falhas de unidade devido a firmware NIC inválido.
Os computadores conectados ao mesmo comutador Ethernet estão no mesmo domínio de falha. Portanto, os computadores que compartilham uma fonte de energia ou que estão em só local.
Como é natural que as falhas de hardware se sobreponham, os domínios de falha são inerentemente hierárquicos. Eles são representados como URIs no Service Fabric.
É importante que os domínios de falha sejam definidos corretamente, pois o Service Fabric usa essas informações para posicionar os serviços com segurança. O Service Fabric não quer posicionar os serviços de modo que a perda de um domínio de falha (causada pela falha de algum componente) faça com que os serviços fiquem inativos.
No ambiente do Azure, o Service Fabric usa as informações do domínio de falha fornecidas pelo ambiente para configurar corretamente os nós no cluster em seu nome. Para instâncias autônomas do Service Fabric, os domínios de falha são definidos no momento em que o cluster é configurado.
Aviso
É importante que as informações de domínio de falha fornecidas ao Service Fabric sejam precisas. Por exemplo, digamos que nós do cluster do Service Fabric estejam em execução dentro de 10 máquinas virtuais que são executadas em cinco hosts físicos. Nesse caso, mesmo que haja dez máquinas virtuais, há apenas cinco domínios de falha (de nível superior) diferentes. Compartilhar o mesmo host físico faz com que as VMs compartilhem o mesmo domínio de falha raiz, uma vez que as VMs apresentarão falhas coordenadas se seu host físico falhar.
O Service Fabric espera que o domínio de falha de um nó não seja alterado. Outros mecanismos para garantir a alta disponibilidade das VMs, como HA-VMs, podem causar conflitos com o Service Fabric. Esses mecanismos usam migração transparente de VMs de um host para outro. Eles não reconfiguram nem notificam o código em execução dentro da VM. Dessa forma, eles não têm suporte como ambientes para execução de clusters do Service Fabric.
O Service Fabric deve ser a única tecnologia de alta disponibilidade empregada. Mecanismos como migração dinâmica de VMs e SANs não são necessários. Se esses mecanismos forem usados em conjunto com Service Fabric, eles reduzirão a disponibilidade e a confiabilidade do aplicativo. O motivo é que eles aumentam a complexidade, adicionam fontes de falha centralizadas e usam estratégias de confiabilidade e disponibilidade que entram em conflito com aquelas do Service Fabric.
No gráfico a seguir, colorimos todas as entidades que contribuem para domínios de falha e listamos todos os diferentes domínios de falha resultantes. Neste exemplo, temos datacenters (“DC”), racks (“R”) e folhas (“B”). Se cada folha contém mais de uma máquina virtual, pode haver outra camada na hierarquia de domínios de falha.
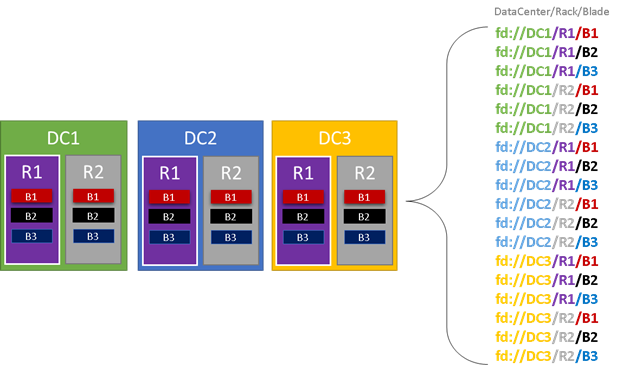
Durante o runtime, o Gerenciador de Recursos de Cluster do Service Fabric leva em consideração os domínios de falha no cluster e planeja layouts. As réplicas com estado ou instâncias sem estado de um serviço são distribuídas para que fiquem em domínios de falha separados. Distribuir o serviço entre domínios de falha garante que a disponibilidade do serviço não seja comprometida quando um domínio de falha falhar em qualquer nível da hierarquia.
O Gerenciador de Recursos de Cluster não se importa com quantas camadas existem na hierarquia de domínio de falha. Ele tenta assegurar que a perda de qualquer parte da hierarquia não afete os serviços em execução nela.
Será melhor se houver o mesmo número de nós em cada nível de profundidade na hierarquia de domínio de falha. Se a "árvore" de domínios de falha estiver desequilibrada em seu cluster, será mais difícil para o Gerenciador de Recursos de Cluster calcular a melhor alocação dos serviços. Layouts de domínio de falha desequilibrados significam que a perda de alguns domínios afeta a disponibilidade de serviços mais do que outros domínios. Como resultado, o Gerenciador de Recursos de Cluster é interrompido entre duas metas:
- Ele quer usar os computadores nesse domínio "pesado" colocando serviços neles.
- Ele deseja colocar serviços em outros domínios para que a perda de um domínio não cause problemas.
Qual é a aparência de um domínio desequilibrado? O diagrama a seguir mostra dois layouts de cluster diferentes. No primeiro exemplo, os nós estão distribuídos uniformemente entre os domínios de falha. No segundo exemplo, um domínio de falha tem muito mais nós do que o outro.
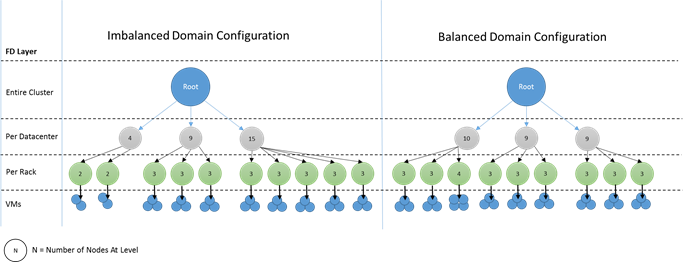
No Azure, a escolha de qual domínio de falha contém um nó é gerenciada por você. Porém, dependendo do número de nós que você provisiona, ainda é possível acabar com os domínios de falha que têm mais nós em relação aos outros.
Por exemplo, digamos que você tenha cinco domínios de falha no cluster, mas provisione sete nós para um tipo de nó (NodeType). Nesse caso, os dois primeiros domínios de falha ficam com mais nós. Se você continuar a implantar mais instâncias de NodeType com apenas algumas instâncias, o problema ficará pior. Por esse motivo, recomendamos que o número de nós em cada tipo de nó seja um múltiplo do número de domínios de falha.
Domínios de atualização
Domínios de atualização são outro recurso que ajuda o Gerenciador de Recursos de Cluster do Service Fabric a entender o layout do cluster. Os domínios de atualização definem conjuntos de nós que são atualizados ao mesmo tempo. Domínios de atualização ajudam o Gerenciador de Recursos de Cluster a entender e coordenar operações de gerenciamento, como atualizações.
Os domínios de atualização são muito semelhantes aos Domínios de Falha, mas com algumas diferenças importantes. Primeiro, as áreas de falhas de hardware coordenadas definem os domínios de falha. Os domínios de atualização, por outro lado, são definidos pela política. Você decide quantos deseja, em vez de permitir que o ambiente defina o número. Você pode o mesmo número de domínios de atualização que o número de nós. Outra diferença entre domínios de falha e domínios de atualização é que os domínios de atualização não são hierárquicos. Em vez disso, eles são mais como uma marca simples.
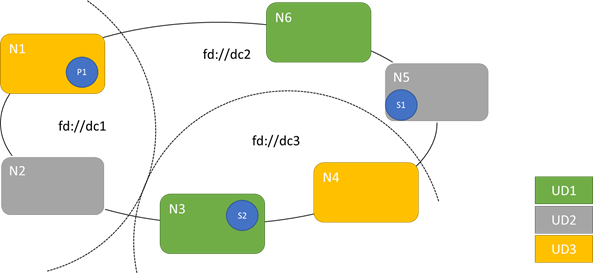
O diagrama a seguir mostra que três domínios de atualização são distribuídos em três domínios de falha. Ele também mostra um possível posicionamento para três réplicas diferentes de um serviço com estado, em que cada um fica em domínios de atualização e de falha diferentes. Esse posicionamento permite perder um domínio de falha durante uma atualização de serviço e ainda ter uma cópia dos códigos e dos dados.
Há prós e contras em ter um grande número de domínios de atualização. Ter mais domínios de atualização significa que cada etapa da atualização é mais granular e afeta um número menor de nós ou serviços. Menos serviços precisam ser movidos de cada vez, introduzindo menos rotatividade no sistema. Isso tende a aumentar a confiabilidade, pois menos do serviço é afetado por qualquer problema introduzido durante a atualização. Ter mais domínios de atualização também significa que você precisa de menos buffer disponível em outros nós para lidar com o impacto da atualização.
Por exemplo, se você tiver cinco domínios de atualização, os nós em cada um serão tratarão de aproximadamente 20% do tráfego. Se você precisar desativar esse domínio de atualização para uma atualização, a carga geralmente precisará ir para algum lugar. Como você tem quatro domínios de atualização restantes, cada um deles deve ter espaço para cerca de 25% do tráfego total. Ter mais domínios de atualização significa que você precisa de menos buffer nos nós do cluster.
Considere se você tinha 10 domínios de atualização em vez disso. Nesse caso, cada domínio de atualização lidaria com apenas cerca de 10% do tráfego total. Quando uma atualização percorre o cluster, cada domínio só precisa ter espaço para aproximadamente 11% do tráfego total. Mais domínios de atualização geralmente permitem que você execute seus nós com maior utilização, pois você precisa de menos capacidade reservada. O mesmo vale para domínios de falha.
A desvantagem de ter vários domínios de atualização é que as atualizações tendem a levar mais tempo. O Service Fabric aguarda um curto período após a conclusão de um domínio de atualização e executa verificações antes de começar a atualizar o próximo. Esses atrasos permitem detectar problemas introduzidos pela atualização antes que ela continue. Essa compensação é aceitável, pois isso evita que alterações incorretas afetem grande parte do serviço de uma só vez.
A presença de poucos domínios de atualização tem muitos efeitos colaterais negativos. Embora cada domínio de atualização esteja inoperante e sendo atualizado, uma grande parte da capacidade geral fica indisponível. Por exemplo, se você tiver apenas três domínios de atualização, estará desativando cerca de um terço da capacidade geral do serviço ou do cluster por vez. Ter uma parte tão grande do seu serviço inoperante ao mesmo tempo não é desejável, uma vez que é necessário ter capacidade suficiente no restante do cluster para lidar com a carga de trabalho. Manter esse buffer significa que, durante a operação normal, esses nós ficam menos carregados do que ficariam em caso contrário. Isso aumenta o custo de execução de seu serviço.
Não há um limite real para o número total de domínios de falha ou de atualização em um ambiente nem restrições sobre como eles se sobrepõem. Porém, há padrões comuns:
- Domínios de falha e domínios de atualização mapeados 1:1
- Um domínio de atualização por nó (instância de sistema operacional física ou virtual)
- Um modelo "distribuído" ou de "matriz" em que os domínios de falha e os domínios de atualização formam uma matriz em que os computadores geralmente são executados diagonalmente
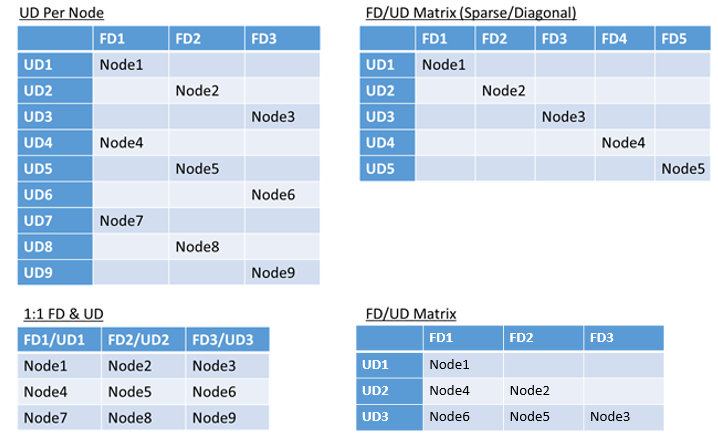
Não existe uma resposta melhor para qual layout escolher. Cada um tem prós e contras. Por exemplo, o modelo de 1FD:1UD é simples de configurar. O modelo de um domínio de atualização por modelo de nó é mais parecido com o que as pessoas estão acostumadas. Durante atualizações, cada nó é atualizado de maneira independente. Isso é semelhante à forma como pequenos conjuntos de computadores eram atualizados manualmente no passado.
O modelo mais comum é a matriz de FD/UD, em que os domínios de falha e os domínios de atualização formam uma tabela e os nós são posicionados começando ao longo da diagonal. Esse é o modelo usado por padrão nos clusters do Service Fabric no Azure. Para clusters com muitos nós, tudo acaba se parecendo com um padrão de matriz densa.
Observação
Clusters do Service Fabric hospedados no Azure não dão suporte à alteração da estratégia padrão. Somente os clusters autônomos oferecem essa personalização.
Restrições de domínio de falha e de atualização e o comportamento resultante
Abordagem padrão
Por padrão, o Gerenciador de Recursos de Cluster mantém os serviços balanceados entre os domínios de atualização e de falha. Isso é modelado como uma restrição. A restrição para estados de domínios de atualização e falha: "para uma partição de serviço específica, nunca deve haver uma diferença maior que um no número de objetos de serviço (instâncias de serviço sem estado ou réplicas de serviço com estado) entre dois domínios no mesmo nível de hierarquia".
Digamos que essa restrição forneça uma garantia de “diferença máxima”. A restrição para domínios de falha e de atualização impede determinadas movimentações ou disposições que violem a regra.
Por exemplo, digamos que tenhamos um cluster com seis nós, configurados com cinco domínios de falha e cinco domínios de atualização.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N3 | ||||
| UD3 | N4 | ||||
| UD4 | N5 |
Agora, digamos que criemos um serviço com um valor de TargetReplicaSetSize (ou, para um serviço sem estado, InstanceCount) de cinco. As réplicas recaem sobre N1 a N5. Na verdade, N6 nunca será usado, independentemente de quantos serviços como este você criar. Mas por quê? Vamos observar a diferença entre o layout atual e o que aconteceria se N6 fosse escolhido.
Aqui está o nosso layout e o número total de réplicas por domínio de falha e de atualização:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | 1 | ||||
| UD3 | R4 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Este layout é balanceado em termos de nós por domínio de falha e domínio de atualização. Ele também é balanceado em termos do número de réplicas por domínio de falha e de atualização. Cada domínio possui o mesmo número de nós e o mesmo número de réplicas.
Agora, vamos ver o que aconteceria se tivéssemos usado N6 em vez de N2. Como as réplicas seriam distribuídas?
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R5 | 1 | ||||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | R4 | 1 | ||||
| FDTotal | 2 | 0 | 1 | 1 | 1 | - |
Esse layout viola nossa definição de garantia de “diferença máxima” para a restrição de Domínio de Falha. O FD0 tem duas réplicas, enquanto FD1 tem zero. A diferença entre FD0 e FD1 um total de dois, o que é maior que a diferença máxima de um. Como a restrição foi violada, o Gerenciador de Recursos de Cluster não permite essa disposição.
Da mesma forma, se escolhêssemos N2 e N6 (em vez de N1 e N2), teríamos:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | 0 | |||||
| UD1 | R5 | R1 | 2 | |||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | R4 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Este layout é equilibrado em termos de domínios de falha. No entanto, agora ela está violando a restrição de domínio de atualização porque o UD0 tem zero réplica enquanto o UD1 tem duas. Esse layout também é inválido e não será escolhido pelo Gerenciador de Recursos de Cluster.
Essa abordagem de distribuição de réplicas com estado ou de instâncias sem estado fornece a melhor tolerância a falhas possível. Se um domínio ficar inoperante, o número mínimo de réplicas/instâncias será perdido.
Por outro lado, essa abordagem pode ser muito restrita e não permitir que o cluster utilize todos os recursos. Para determinadas configurações de cluster, alguns nós não podem ser usados. Isso pode fazer com que o Service Fabric não posicione seus serviços, resultando em mensagens de aviso. No exemplo anterior, alguns nós de cluster não podem ser usados (N6 no exemplo). Mesmo que você tenha adicionado nós a esse cluster (N7-N10), as réplicas/instâncias só serão colocadas em N1 a N5 devido a restrições em domínios de falha e de atualização.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | N10 | |||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N9 | N5 |
Abordagem alternativa
O Gerenciador de Recursos de Cluster dá suporte a outra versão da restrição para domínios de falha e atualização. Ele permite o posicionamento enquanto ainda garante um nível mínimo de segurança. A restrição alternativa pode ser declarada da seguinte maneira: "para uma determinada partição de serviço, a distribuição de réplica entre domínios deve garantir que a partição não sofra uma perda de quorum". Digamos que essa restrição forneça uma garantia de "segurança de quorum".
Observação
Para um serviço com estado, definimos perda de quorum em uma situação em que a maioria das réplicas de partição estão inativas ao mesmo tempo. Por exemplo, se TargetReplicaSetSize for cinco, um conjunto de quaisquer três réplicas representará um quorum. Da mesma forma, se TargetReplicaSetSize for seis, quatro réplicas serão necessárias para o quorum. Em ambos os casos, no máximo duas réplicas podem ficar inativas ao mesmo tempo se a partição deve continuar funcionando normalmente.
Para um serviço sem estado, não existe perda de quorum. Os serviços sem estado continuarão a funcionar normalmente mesmo que a maioria das instâncias fique inativa ao mesmo tempo. Então, vamos nos concentrar nos serviços com estado no restante deste artigo.
Voltar para o exemplo anterior. Com a versão “segurança de quorum” da restrição, todos os três layouts seriam válidos. Mesmo se FD0 tiver falhado no segundo layout ou UD1 tiver falhado no terceiro layout, a partição ainda terá quorum. (A maioria das réplicas ainda estará ativa.) Com essa versão da restrição, o N6 quase sempre pode ser utilizado.
A abordagem de "segurança de quorum" oferece mais flexibilidade do que a abordagem de "diferença máxima". O motivo é que é mais fácil localizar distribuições de réplicas que são válidas em praticamente qualquer topologia de cluster. No entanto, essa abordagem não garante a melhor característica de tolerância a falhas, pois algumas falhas são piores que outras.
Na pior das hipóteses, a maioria das réplicas pode ser perdida com a falha de um domínio e uma réplica adicional. Por exemplo, em vez da necessidade de três falhas para perder quorum com cinco réplicas ou as instâncias, seria possível agora perder a maioria com apenas duas falhas.
Abordagem adaptável
Como ambas as abordagens têm vantagens e desvantagens, apresentamos uma abordagem adaptável que combina essas duas estratégias.
Observação
Esse é o comportamento padrão a começar do Service Fabric versão 6.2.
A abordagem adaptável usa a lógica “diferença máxima” por padrão e muda para a lógica “segurança de quorum” somente quando necessário. O Gerenciador de Recursos de Cluster decide automaticamente qual estratégia é necessária examinando como o cluster e os serviços são configurados.
O Gerenciador de Recursos de Cluster deve usar a lógica "baseada em quorum" para um serviço em que estas duas condições são verdadeiras:
- O TargetReplicaSetSize para o serviço é igualmente divisível pelo número de domínios de falha e pelo número de domínios de atualização.
- O número de nós é menor ou igual ao número de domínios de falha multiplicado pelo número de domínios de atualização.
Lembre-se de o Gerenciador de Recursos de Cluster usará essa abordagem para serviços com e sem estado, embora a perda de quorum não seja relevante para os serviços sem estado.
Vamos voltar ao exemplo anterior e supor que um cluster agora tem oito nós. O cluster ainda é configurado com cinco domínios de falha e cinco domínios de atualização, e o valor de TargetReplicaSetSize de um serviço hospedado nesse cluster continua sendo cinco.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N5 |
Como todas as condições necessárias são cumpridas, o Gerenciador de Recursos de Cluster usará a lógica "baseada em quorum" na distribuição do serviço. Isso permite usar N6 a N8. Uma distribuição de serviço possível nesse caso seria semelhante a isto:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | 0 | |||||
| UD4 | R5 | 1 | ||||
| FDTotal | 2 | 1 | 1 | 0 | 1 | - |
Se o valor TargetReplicaSetSize do serviço for reduzido para quatro (por exemplo), o Gerenciador de Recursos de Cluster notará essa alteração. Ele será retomado usando a lógica "diferença máxima" porque o TargetReplicaSetSize não é mais divisível pelo número de domínios de falha e domínios de atualização. Como resultado, determinados movimentos de réplica ocorrerão para distribuir as quatro réplicas restantes nos nós N1 a N5. Dessa forma, a versão de "diferença máxima" da lógica de domínio de falha e de domínio de atualização não é violada.
No layout anterior, se o valor de TargetReplicaSetSize for cinco e N1 for removido do cluster, o número de domínios de atualização se tornará igual a quatro. Novamente, o Gerenciador de Recursos de Cluster começa usando a lógica "diferença máxima" porque o número de domínios de atualização não divide o valor de TargetReplicaSetSize do serviço de maneira mais uniforme. Como resultado, a réplica R1, quando compilada novamente, precisa parar em N4 para que a restrição para o domínio de atualização e falha não seja violada.
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | N/D | N/D | N/D | N/D | N/D | N/D |
| UD1 | R2 | 1 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | R1 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Configurando domínios de falha e atualização
Em implantações do Service Fabric hospedadas pelo Azure, os domínios de falha e os domínios de atualização são definidos automaticamente. O Service Fabric seleciona e usa as informações de ambiente do Azure.
Se estiver criando o seu cluster (ou desejar executar uma topologia específica no desenvolvimento), você mesmo poderá fornecer as informações de domínio de falha e de domínio de atualização. Neste exemplo, definimos um cluster de desenvolvimento local de nove nós que abrange três "datacenters" (cada um com três racks). Este cluster também tem três domínios de atualização distribuídos entre esses três datacenters. Veja um exemplo da configuração no ClusterManifest.xml:
<Infrastructure>
<!-- IsScaleMin indicates that this cluster runs on one box/one single server -->
<WindowsServer IsScaleMin="true">
<NodeList>
<Node NodeName="Node01" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType01" FaultDomain="fd:/DC01/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node02" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType02" FaultDomain="fd:/DC01/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node03" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType03" FaultDomain="fd:/DC01/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node04" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType04" FaultDomain="fd:/DC02/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node05" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType05" FaultDomain="fd:/DC02/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node06" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType06" FaultDomain="fd:/DC02/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node07" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType07" FaultDomain="fd:/DC03/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node08" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType08" FaultDomain="fd:/DC03/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node09" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType09" FaultDomain="fd:/DC03/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
</NodeList>
</WindowsServer>
</Infrastructure>
Este exemplo usa ClusterConfig.json para implantações autônomas:
"nodes": [
{
"nodeName": "vm1",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm2",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm3",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm4",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm5",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm6",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm7",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm8",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm9",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD3"
}
],
Observação
Quando você está definindo clusters por meio do Azure Resource Manager, o Azure atribui domínios de falha e domínios de atualização. Portanto, a definição de seus tipos de nó e conjuntos de dimensionamento de máquinas virtuais em seu modelo do Azure Resource Manager não inclui informações sobre domínio de falha ou o domínio de atualização.
Restrições de posicionamento e propriedades do nó
Às vezes (na verdade, na maioria das vezes), convém assegurar que determinadas cargas de trabalho sejam executadas apenas em alguns tipos de nós no cluster. Por exemplo, algumas cargas de trabalho podem exigir GPUs ou SSDs enquanto outras podem não exigir.
Um ótimo exemplo de direcionamento de hardware para cargas de trabalho específicas é praticamente toda arquitetura de n camadas. Determinados computadores servem como o lado de serviço de front-end ou API do aplicativo e, portanto, são expostos aos clientes ou à Internet. Diferentes computadores, normalmente com recursos de hardware diferentes, lidam com o trabalho das camadas de computação ou armazenamento. Normalmente, eles não são expostos diretamente a clientes ou à Internet.
O Service Fabric espera que, em alguns casos, cargas de trabalho específicas precisem ser executadas em configurações de hardware específicas. Por exemplo:
- Um aplicativo de n camadas existente foi "transferido e posicionado" em um ambiente do Service Fabric.
- Uma carga de trabalho deve ser executada em um hardware específico por motivos de desempenho, escala ou isolamento de segurança.
- Uma carga de trabalho deve ser isolada de outras cargas de trabalho por motivos de política ou consumo de recursos.
Para dar suporte a esses tipos de configurações, o Service Fabric inclui marcas que você pode aplicar a nós. Essas marcas são chamadas de propriedades de nó. As restrições de posicionamento são as instruções anexadas a serviços individuais que selecionam uma ou mais propriedades do nó. Restrições de posicionamento definem onde os serviços devem ser executados. O conjunto de restrições é extensível. Qualquer par chave/valor pode funcionar.
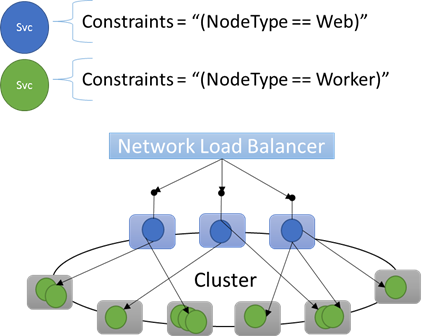
Propriedades de nó internas
O Service Fabric define algumas propriedades de nó padrão que podem ser usadas automaticamente, de modo que você não precisa defini-las. As propriedades padrão definidas em cada nó são NodeType e NodeName.
Por exemplo, você pode escrever uma restrição de posicionamento como "(NodeType == NodeType03)". NodeType é uma propriedade comumente usada. Ela é útil porque corresponde individualmente a um tipo de um computador. Cada tipo de computador corresponde a um tipo de carga de trabalho em um aplicativo de n camadas tradicional.
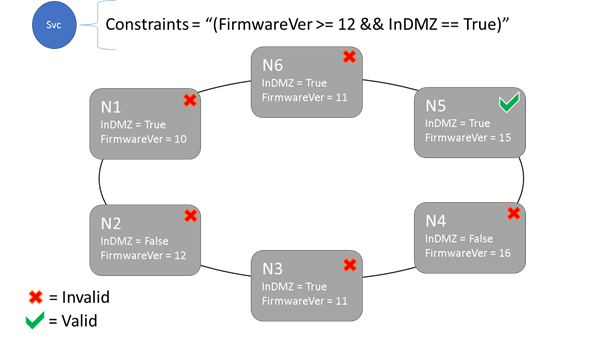
Restrições de posicionamento e sintaxe de propriedade de nó
O valor especificado na propriedade de nó pode ser uma cadeia de caracteres, um booliano ou um longo assinado. A instrução no serviço é chamada de uma restrição de posicionamento, uma vez que ela restringe onde o serviço pode ser executado no cluster. A restrição pode ser qualquer instrução booliana que opera sobre as propriedades de nó no cluster. Os seletores válidos nessas instruções boolianas são:
Verificações condicionais para a criação de instruções:
Instrução Sintaxe "igual a" "==" "diferente de" "!=" "maior que" ">" "maior ou igual a" ">=" "menor que" "<" "menor ou igual a" "<=" Instruções boolianas para operações de agrupamento e lógicas:
Instrução Sintaxe "e" "&&" "ou" "||" "não" "!" "agrupar como instrução única" "()"
Aqui estão alguns exemplos de instruções de restrição básicas:
"Value >= 5""NodeColor != green""((OneProperty < 100) || ((AnotherProperty == false) && (OneProperty >= 100)))"
O serviço pode ser posicionado somente em nós em que a instrução de restrição de posicionamento geral é avaliada como "True". Os nós que não têm uma propriedade definida não correspondem a nenhuma restrição de posicionamento que contenha a propriedade.
Digamos que as seguintes propriedades de nó foram definidas para um tipo de nó no ClusterManifest.xml:
<NodeType Name="NodeType01">
<PlacementProperties>
<Property Name="HasSSD" Value="true"/>
<Property Name="NodeColor" Value="green"/>
<Property Name="SomeProperty" Value="5"/>
</PlacementProperties>
</NodeType>
O exemplo a seguir mostra as propriedades de nó definidas por meio de ClusterConfig.json para implantações autônomas ou Template.json em clusters hospedados no Azure.
Observação
Em seu modelo do Azure Resource Manager, o tipo de nó costuma ser parametrizado. Ele seria semelhante a "[parameters('vmNodeType1Name')]", em vez de NodeType01.
"nodeTypes": [
{
"name": "NodeType01",
"placementProperties": {
"HasSSD": "true",
"NodeColor": "green",
"SomeProperty": "5"
},
}
],
Você pode criar restrições de posicionamento de serviço para um serviço da seguinte forma:
FabricClient fabricClient = new FabricClient();
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
serviceDescription.PlacementConstraints = "(HasSSD == true && SomeProperty >= 4)";
// Add other required ServiceDescription fields
//...
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceType -Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementConstraint "HasSSD == true && SomeProperty >= 4"
Se todos os nós de NodeType01 forem válidos, você também poderá selecionar esse tipo de nó com a restrição "(NodeType == NodeType01)".
As restrições de posicionamento de um serviço podem ser atualizadas dinamicamente durante o runtime. Se necessário, você poderá mover um serviço pelo cluster, adicionar e remover requisitos etc. O Service Fabric garante que o serviço permaneça ativo e disponível mesmo quando esses tipos de alterações forem feitas.
StatefulServiceUpdateDescription updateDescription = new StatefulServiceUpdateDescription();
updateDescription.PlacementConstraints = "NodeType == NodeType01";
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
Update-ServiceFabricService -Stateful -ServiceName $serviceName -PlacementConstraints "NodeType == NodeType01"
Restrições de posicionamento são especificadas para cada instância de serviço nomeada. As atualizações sempre assumem o lugar (substituem) do que foi especificado anteriormente.
A definição do cluster define as propriedades em um nó. Alterar as propriedades de um nó requer uma atualização à configuração do cluster. Atualizar as propriedades de um nó requer que cada nó afetado seja reiniciado para informar suas novas propriedades. O Service Fabric gerencia essas atualizações sem interrupção.
Descrever e gerenciar Recursos de Cluster
Um dos trabalhos mais importantes de qualquer orquestrador é ajudar a gerenciar o consumo de recursos no cluster. Gerenciar recursos de cluster pode significar algumas coisas diferentes.
Primeiro, é necessário garantir que os computadores não sejam sobrecarregados. Isso significa garantir que eles não executem mais serviços do que conseguem tratar.
Segundo, há o balanceamento e a otimização, que são críticos para executar serviços com eficiência. Ofertas de serviço com bom custo-benefício ou sensíveis ao desempenho não podem permitir que alguns nós fiquem frios enquanto outros ficam quentes. Os nós quentes levam a contenção de recurso e baixo desempenho. Os nós frios representam desperdício de recursos e custos maiores.
O Service Fabric representa recursos como métricas. As métricas são qualquer recurso lógico ou físico que você queira descrever para o Service Fabric. Exemplos de métricas são "WorkQueueDepth" ou "MemoryInMb". Para obter informações sobre os recursos físicos que o Service Fabric é capaz de controlar nos nós, confira Governança de recursos. Para obter informações sobre as métricas padrão usadas pelo Gerenciador de Recursos de Cluster e como configurar métricas personalizadas, confira Este artigo.
As métricas são diferentes das restrições de posicionamento e das propriedades de nó. Propriedades do nó são descritores estáticos dos nós propriamente ditos. As métricas descrevem os recursos que os nós têm e que os serviços consomem quando são executados em um nó. Uma propriedade do nó pode ser HasSSD e pode ser definida como true ou false. A quantidade de espaço disponível no SSD e quanto dele é consumido pelos serviços seria uma métrica como "DriveSpaceInMb".
Assim como para restrições de posicionamento e propriedades do nó, Gerenciador de Recursos de Cluster do Service Fabric não entende o que os nomes das métricas significam. Os nomes de métrica são apenas cadeias de caracteres. É uma boa prática declarar as unidades como parte dos nomes de métrica que você criar quando puderem ser ambíguos.
Capacity
Se você desativasse todo o balanceamento de recursos, o Gerenciador de Recursos de Cluster do Service Fabric ainda garantiria que nenhum nó ficasse acima de sua capacidade. É possível gerenciar saturações de capacidade, a menos que o cluster esteja muito cheio ou que a carga de trabalho seja maior do que qualquer nó. A capacidade é outra restrição que usa o Gerenciador de Recursos de Cluster para entender o quanto um nó tem de um recurso. A capacidade restante também é rastreada para o cluster como um todo.
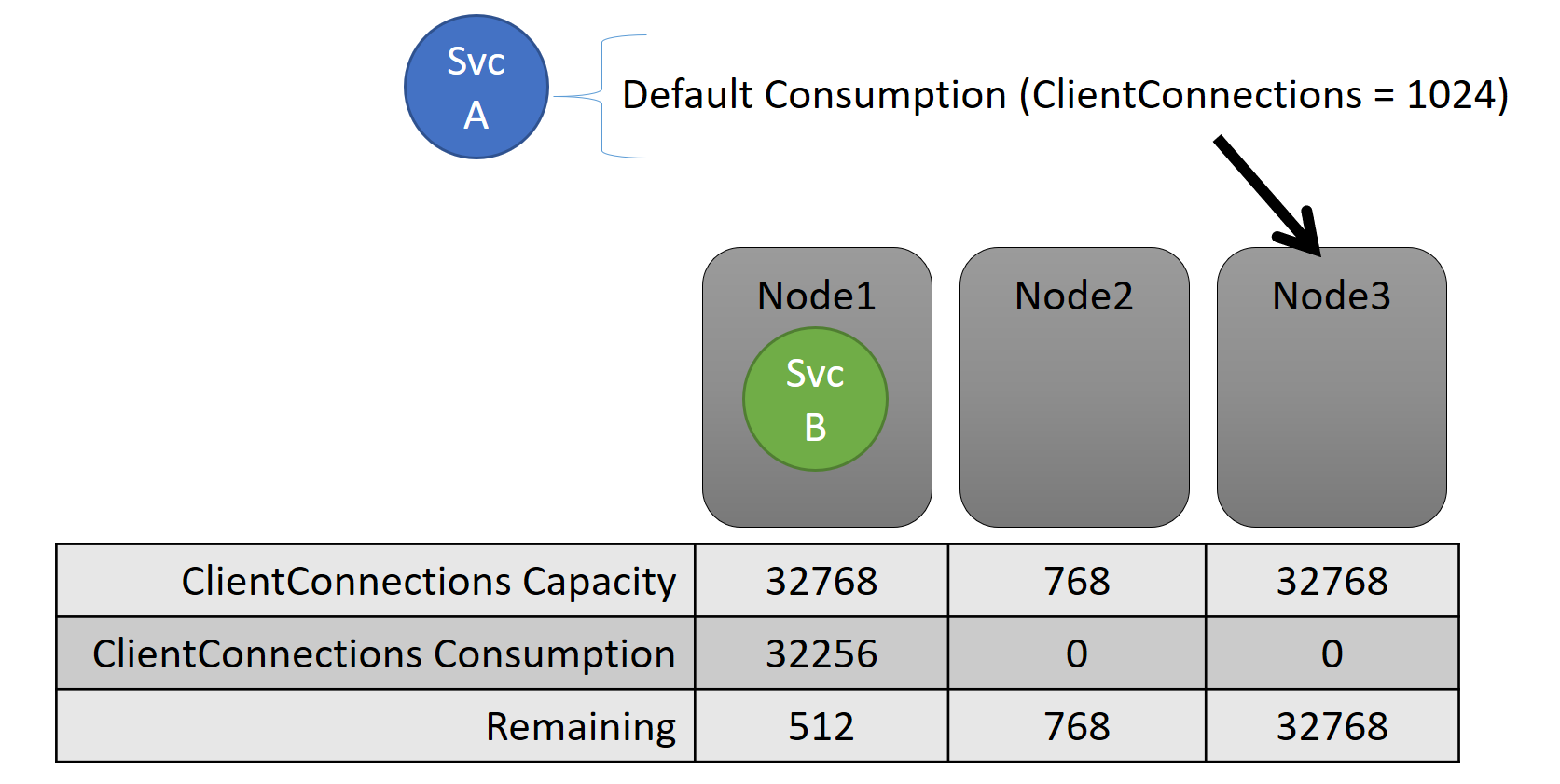
A capacidade e o consumo no nível de serviço são expressos em termos de métricas. Por exemplo, a métrica poderia ser "ClientConnections" e um nó poderia ter uma capacidade de "ClientConnections" igual a 32.768. Outros nós podem ter outros limites. Um serviço em execução nesse nó pode dizer que está consumindo, no momento, 32.256 da métrica "ClientConnections".
Durante o runtime, o Gerenciador de Recursos de Cluster rastreia a capacidade restante no cluster e nos nós. Para acompanhar a capacidade, o Gerenciador de Recursos de Cluster subtrai o uso de cada serviço da capacidade de um nó em que o serviço é executado. Com essas informações, o Gerenciador de Recursos de Cluster pode descobrir em que local posicionar ou mover réplicas para que os nós não ultrapassem a capacidade.
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
ServiceLoadMetricDescription metric = new ServiceLoadMetricDescription();
metric.Name = "ClientConnections";
metric.PrimaryDefaultLoad = 1024;
metric.SecondaryDefaultLoad = 0;
metric.Weight = ServiceLoadMetricWeight.High;
serviceDescription.Metrics.Add(metric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ClientConnections,High,1024,0)
Você pode ver as capacidades definidas no manifesto do cluster. Aqui está um exemplo para ClusterManifest.xml:
<NodeType Name="NodeType03">
<Capacities>
<Capacity Name="ClientConnections" Value="65536"/>
</Capacities>
</NodeType>
Aqui está um exemplo de capacidades definidas por meio de ClusterConfig.json para implantações autônomas ou Template.json para clusters hospedados no Azure:
"nodeTypes": [
{
"name": "NodeType03",
"capacities": {
"ClientConnections": "65536",
}
}
],
A carga de um serviço costuma mudar dinamicamente. Digamos que a carga de uma réplica de "ClientConnections" tenha mudado de 1.024 para 2.048. O nó em que ele estava sendo executado tinha uma capacidade de apenas 512 restantes para essa métrica. Agora essa réplica ou posicionamento da instância é inválido, pois não há espaço suficiente no nó. O Gerenciador de Recursos de Cluster precisa colocar o nó abaixo da capacidade novamente. Ele reduz a carga no nó que está acima da capacidade movendo uma ou mais réplicas ou instâncias desse nó para outros nós.
O Gerenciador de Recursos de Cluster tenta minimizar o custo de mover réplicas. Você pode saber mais sobre o custo de movimento e sobre como reequilibrar estratégias e regras.
Capacidade do cluster
Como o Gerenciador de Recursos de Cluster do Service Fabric impede o cluster geral de ficar muito cheio? Com a carga dinâmica, não há muito que ele possa fazer. Os serviços podem ter o pico de carga independentemente das ações que o Gerenciador de Recursos de Cluster adota. Como resultado, um cluster que hoje tem muito espaço disponível poderá ser insuficiente se houver um pico amanhã.
Os controles no Gerenciador de Recursos de Cluster ajudam a evitar problemas. A primeira coisa que você pode fazer é impedir a criação de cargas de trabalho que poderiam fazer com que o cluster ficasse cheio.
Digamos que você crie um serviço sem estado e que haja alguma carga associada a ele. O serviço se preocupa com a métrica "DiskSpaceInMb". O serviço consumirá cinco unidades de "DiskSpaceInMb" para cada instância do serviço. Você deseja criar três instâncias do serviço. Isso significa que 15 unidades de "DiskSpaceInMb" devem estar presentes no cluster para você sequer criar essas instâncias de serviço.
O Gerenciador de Recursos de Cluster calcula continuamente a capacidade e o consumo de cada métrica para que possa determinar a capacidade restante no cluster. Se não houver espaço suficiente, o Gerenciador de Recursos de Cluster rejeitará a chamada para criar um serviço.
Como o requisito é apenas que 15 unidades estejam disponíveis, você pode alocar esse espaço de várias maneiras. Por exemplo, poderia haver uma unidade restante de capacidade em 15 nós diferentes ou três unidades restantes de capacidade em cinco nós diferente. Se o Gerenciador de Recursos de Cluster puder reorganizar as coisas para que haja cinco unidades disponíveis em três nós, ele posicionará o serviço. Normalmente, é possível reorganizar o cluster, a menos que ele esteja quase cheio ou que os serviços existentes não possam ser consolidados por alguma razão.
Buffer de nó e capacidade de overbooking
Se uma capacidade de nó para uma métrica for especificada, o Gerenciador de Recursos de Cluster nunca colocará nem moverá réplicas para um nó se a carga total ficar acima da capacidade do nó especificado. Às vezes, isso pode impedir o posicionamento de novas réplicas ou a substituição de réplicas com falha se o cluster estiver quase em plena capacidade e uma réplica com uma carga grande precisar ser posicionada, substituída ou movida.
Para fornecer mais flexibilidade, você pode especificar buffer de nó ou capacidade de reserva excessiva. Quando for especificado buffer de nó ou capacidade de reserva excessiva para uma métrica, o Gerenciador de Recursos de Cluster tentará posicionar ou mover réplicas de modo que o buffer ou a capacidade de reserva excessiva permaneça não utilizado, mas permita que o buffer ou a capacidade de reserva excessiva seja usado se necessário para ações que aumentam a disponibilidade do serviço, como:
- Novo posicionamento de réplica ou substituição de réplicas com falha
- Posicionamento durante as atualizações
- Correção de violações de restrição flexível e rígida
- Vantagens da desfragmentação
A capacidade de buffer de nó representa uma parte reservada da capacidade abaixo da capacidade de nó especificada e a capacidade de reserva excessiva representa uma parte da capacidade extra acima da capacidade do nó especificado. Em ambos os casos, o Gerenciador de Recursos de Cluster tentará manter essa capacidade livre.
Por exemplo, se um nó tiver uma capacidade especificada para a métrica CpuUtilization de 100 e o percentual de buffer do nó para essa métrica for definida como 20%, as capacidades total e não armazenada em buffer serão 100 e 80, respectivamente, e o Gerenciador de Recursos de Cluster não colocará mais de 80 unidades de carga no nó durante circunstâncias normais.

O buffer do nó deve ser usado quando você deseja reservar uma parte da capacidade do nó que será usada somente para ações que aumentam a disponibilidade do serviço mencionada acima.
Por outro lado, se o percentual de reserva excessiva de nó for usado e definido como 20%, as capacidades total e não armazenada em buffer serão 120 e 100, respectivamente.
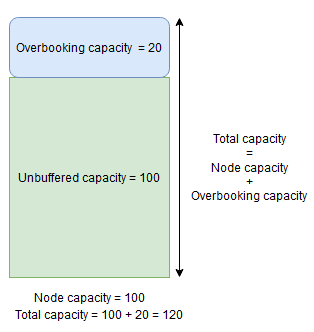
A capacidade de reserva excessiva deve ser usada quando você deseja permitir que o Gerenciador de Recursos de Cluster posicione réplicas em um nó mesmo que o uso total de recursos exceda a capacidade. Isso pode ser usado para fornecer disponibilidade adicional para os serviços à custa do desempenho. Se a reserva excessiva for usada, a lógica do aplicativo do usuário precisará conseguir funcionar com menos recursos físicos do que ela talvez precise.
Se o buffer do nó ou as capacidades de reserva excessiva forem especificadas, o Gerenciador de Recursos de Cluster não moverá nem posicionará réplicas se a carga total no nó de destino ultrapassar a capacidade total (a capacidade do nó no caso do buffer do nó e da capacidade do nó + a capacidade de reserva excessiva em caso de sobreposição).
A capacidade de reserva excessiva também pode ser especificada como infinita. Nesse caso, o Gerenciador de Recursos de Cluster tentará manter a carga total no nó abaixo da capacidade do nó especificado, mas terá permissão para potencialmente posicionar uma carga muito maior no nó, o que poderá levar a uma degradação grave de desempenho.
Uma métrica não pode ter o buffer de nó e a capacidade de reserva excessiva especificada para ele ao mesmo tempo.
Veja um exemplo de como especificar o buffer de nó ou as capacidades de reserva excessiva no ClusterManifest.xml:
<Section Name="NodeBufferPercentage">
<Parameter Name="SomeMetric" Value="0.15" />
</Section>
<Section Name="NodeOverbookingPercentage">
<Parameter Name="SomeOtherMetric" Value="0.2" />
<Parameter Name=”MetricWithInfiniteOverbooking” Value=”-1.0” />
</Section>
Aqui está um exemplo de como especificar o buffer do nó ou as capacidades de reserva excessiva por meio de ClusterConfig.json para implantações autônomas ou Template.json para clusters hospedados no Azure:
"fabricSettings": [
{
"name": "NodeBufferPercentage",
"parameters": [
{
"name": "SomeMetric",
"value": "0.15"
}
]
},
{
"name": "NodeOverbookingPercentage",
"parameters": [
{
"name": "SomeOtherMetric",
"value": "0.20"
},
{
"name": "MetricWithInfiniteOverbooking",
"value": "-1.0"
}
]
}
]
Próximas etapas
- Para obter informações sobre a arquitetura e o fluxo de informações no Gerenciador de Recursos de Cluster, confira Visão geral da arquitetura do Gerenciador de Recursos de Cluster.
- Definir métricas de desfragmentação é uma forma de consolidar a carga em nós, em vez de distribuí-la. Para saber como configurar a desfragmentação, confira Desfragmentação de métricas e carga no Service Fabric.
- Comece do princípio e obtenha uma introdução ao Gerenciador de Recursos de Cluster do Service Fabric.
- Para saber como o Gerenciador de Recursos de Cluster gerencia e balanceia carga no cluster, confira Balanceamento do cluster do Service Fabric.