Planejamento de capacidade para Aplicativos do Service Fabric
Este documento ensina a você como estimar a quantidade de recursos (CPU, RAM, armazenamento de disco) necessários para a execução dos aplicativos Service Fabric. É comum os requisitos de recursos mudarem ao longo do tempo. Normalmente, você precisa de alguns recursos enquanto desenvolve/testa seu serviço e, posteriormente, precisa de mais recursos à medida que entra na fase de produção e a popularidade de seu aplicativo aumenta. Ao projetar o aplicativo, pense nos requisitos de longo prazo e faça escolhas que permitam a ampliação do serviço, a fim de atender à alta demanda dos clientes.
Ao criar um cluster do Service Fabric, você decide quais tipos de VMs (máquinas virtuais) compõem o cluster. Cada VM é acompanhada por uma quantidade limitada de recursos na forma de CPU (núcleos e velocidade), largura de banda de rede, RAM e armazenamento em disco. À medida que o serviço cresce com o tempo, você pode atualizar para VMs que oferecem mais recursos e/ou adicionar mais VMs ao seu cluster. Para executar a última sugestão, você deverá arquitetar seu serviço inicialmente para que ele possa tirar proveito de novas VMs adicionadas dinamicamente ao cluster.
Alguns serviços gerenciam nenhum ou poucos dados nas VMs em si. Portanto, o planejamento de capacidade para esses serviços deve se concentrar principalmente no desempenho, o que significa selecionar as CPUs apropriadas (núcleos e velocidade) das VMs. Além disso, você deve considerar a largura de banda da rede, incluindo a frequência das transferências de rede e a quantidade de dados que está sendo transferida. Se o serviço precisar ser executado com qualidade à medida que o uso do serviço aumenta, você poderá adicionar mais VMs ao cluster e balancear a carga das solicitações de rede em todas as VMs.
Para serviços que gerenciam grandes volumes dados nas VMs, o planejamento de capacidade deve se concentrar principalmente no tamanho. Portanto, você deve considerar cuidadosamente a capacidade de RAM e o armazenamento de disco da VM. O sistema de gerenciamento de memória virtual no Windows faz o espaço em disco se parecer com a memória RAM para o código do aplicativo. Além disso, o runtime do Service Fabric fornece a paginação inteligente mantendo apenas dados dinâmicos na memória e movendo dados sem vida para o disco. Assim, os aplicativos usam mais memória do que está fisicamente disponível na VM. Ter mais RAM simplesmente aumenta o desempenho, pois a VM pode manter mais armazenamento em disco na RAM. A máquina virtual que você selecionar deve ter um disco grande o suficiente para armazenar os dados que você deseja na VM. Da mesma forma, a VM deve ter RAM suficiente para fornecer o desempenho desejado. Se os dados do serviço crescerem com o tempo, você poderá adicionar mais VMs ao cluster e particionar os dados em todas as VMs.
Determinar quantos nós são necessários
O particionamento do serviço permite que você escale horizontalmente os dados do serviço. Para obter mais informações sobre particionamento, consulte Particionamento do Service Fabric. Cada partição deve se ajustar a uma única VM, mas várias partições (pequenas) podem ser colocadas em uma única VM. Portanto, ter mais partições pequenas fornece maior flexibilidade do que ter poucas partições maiores. A desvantagem é que ter muitas partições aumenta a sobrecarga do Service Fabric e você não pode executar operações transacionadas entre partições. Também há a possibilidade demais tráfego de rede se o seu código de serviço precisar constantemente acessar partes dos dados que residem em partições diferentes. Ao projetar seu serviço, você deve considerar cuidadosamente esses prós e contras para chegar a uma estratégia de particionamento eficiente.
Vamos supor que seu aplicativo tem um único serviço com estado, com um tamanho de armazenamento que você espera aumentar para determinado tamanho de BD em GB em um ano. Você está disposto a adicionar mais aplicativos (e partições) conforme for crescendo depois desse ano. O RF (fator de replicação), que determina o número de réplicas para o serviço afeta o tamanho de BD total. O tamanho de BD total em todas as réplicas é o fator de replicação multiplicado pelo tamanho de BD. Tamanho do nó representa a RAM/espaço em disco por nó que você deseja usar para seu serviço. Para melhor desempenho, o tamanho de BD deve caber na memória no cluster e um tamanho do nó ao redor da RAM da VM deve ser escolhido. Ao alocar um tamanho de nó maior que a capacidade de RAM, você dependerá da paginação fornecida pelo runtime do Service Fabric. Assim, o desempenho pode não ser ideal se seus dados inteiros são considerados dinâmicos (desde então, os dados são paginados como entrada/saída). No entanto, para muitos serviços em que apenas uma fração dos dados é dinâmica, é mais econômico.
O número de nós exigidos para obter o desempenho máximo pode ser calculado da seguinte maneira:
Number of Nodes = (DB_Size * RF)/Node_Size
Pense no crescimento
Pode ser uma boa ideia calcular o número de nós com base no tamanho de BD que você espera atingir com seu serviço, além do tamanho de BD inicial. Em seguida, aumente o número de nós conforme seu serviço dor crescendo para não provisionar excessivamente o número de nós. Porém, o número de partições deve ter base no número de nós que são necessários durante a execução do seu serviço no crescimento máximo.
É bom ter algumas máquinas adicionais disponíveis a qualquer momento, para que você possa manipular picos inesperados ou falha (por exemplo, se algumas VMs ficarem inativas). Embora a capacidade extra deva ser determinada usando seus picos esperados, um bom ponto de partida seria reservar algumas VMs adicionais (5 a 10% extra).
O ponto anterior pressupõe um único serviço com estado. Se você tiver mais de um serviço com estado, precisará adicionar o tamanho de BD associado aos outros serviços na equação. Como alternativa, você pode calcular o número de nós separadamente para cada serviço com estado. O serviço pode ter réplicas ou partições que não são equilibradas. Tenha em mente que as partições também podem ter mais dados do que outras. Para obter mais informações sobre particionamento, consulte Particionamento de artigo nas práticas recomendadas. No entanto, a equação anterior independe do número de partições ou réplicas, pois o Service Fabric garante que as réplicas sejam distribuídas entre os nós de uma forma otimizada.
Use uma planilha para calcular o custo
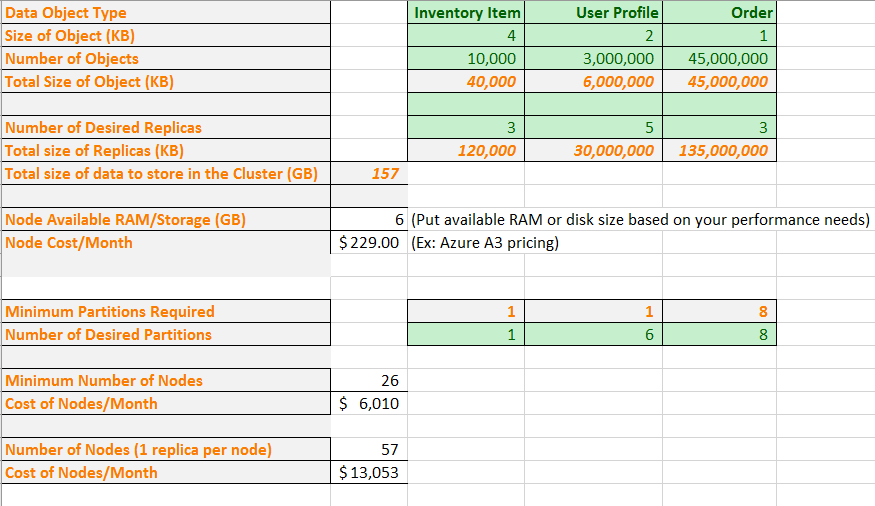
Agora, vamos colocar alguns números reais na fórmula. Uma planilha de exemplo mostra como planejar a capacidade de um aplicativo que contém três tipos de objetos de dados. Para cada objeto, podemos supor seu tamanho e quantos objetos são esperados. Também selecionamos quantas réplicas queremos de cada tipo de objeto. A planilha calcula a quantidade total de memória a ser armazenada no cluster.
Em seguida, inserimos um tamanho de VM e um custo mensal. Com base no tamanho da VM, a planilha informa o número mínimo de partições que você deve usar para dividir seus dados a fim de ajustar fisicamente nos nós. Talvez você queira que um número maior de partições acomode as necessidades de tráfego de computação e de rede específico de seu aplicativo. A planilha mostra que o número de partições que estão gerenciando objetos de perfil de usuário aumentou de uma para seis.
Agora, com base em todas essas informações, a planilha mostra que você pode obter fisicamente todos os dados com as partições e réplicas desejadas em um cluster com 26 nós. No entanto, esse cluster estaria densamente compactado e, por isso, convém adicionar alguns nós para acomodar atualizações e falhas de nó. A planilha também mostra que ter mais de 57 nós não representa um valor adicional, pois você teria nós vazios. Novamente, convém ultrapassar os 57 nós a fim de acomodar falhas de nós e atualizações. É possível ajustar a planilha a fim de atender às necessidades específicas de seu aplicativo.
Próximas etapas
Confira Particionando serviços do Service Fabric para saber mais sobre como particionar o serviço.