Tutorial: Indexar dados grandes do Apache Spark usando o SynapseML e o Azure AI Search
Neste tutorial do Azure AI Search, saiba como indexar e consultar dados grandes carregados de um cluster Spark. Configure um Jupyter Notebook que execute as seguintes ações:
- Carregar vários formulários (faturas) em um dataframe em uma sessão do Apache Spark
- Analisá-los para determinar seus recursos
- Combinar a saída resultante em uma estrutura de dados tabular
- Gravar a saída em um índice de pesquisa hospedado no Azure AI Search
- Explorar e pesquisar o conteúdo criado
Este tutorial usa uma dependência do SynapseML, uma biblioteca de código aberto que dá suporte ao machine learning paralelo em massa em Big Data. No SynapseML, a indexação de pesquisa e o machine learning são expostos por meio de transformadores que executam tarefas especializadas. Os transformadores aproveitam uma ampla gama de funcionalidades de IA. Neste exercício, use as APIs AzureSearchWriter para análise e enriquecimento de IA.
Embora o Azure AI Search tenha enriquecimento de IA nativo, este tutorial mostra como acessar recursos de IA fora do Azure AI Search. Usando o SynapseML em vez de indexadores ou habilidades, você não fica sujeito a limites de dados ou a restrições associadas a esses objetos.
Dica
Assista a um breve vídeo desta demonstração em https://www.youtube.com/watch?v=iXnBLwp7f88. O vídeo expande este tutorial com mais etapas e visuais.
Pré-requisitos
Você precisará da biblioteca synapseml e de vários recursos do Azure. Se possível, use a mesma assinatura e região para seus recursos do Azure e coloque tudo em um grupo de recursos para simplificar a limpeza posteriormente. Os links a seguir são para instalações do portal. Os dados de exemplo são importados de um site público.
- Pacote SynapseML1
-
Pesquisa de IA do Azure (qualquer camada de serviço), com um Tipo de API de
AIServices2 - Conta multisserviços da Plataforma de IA do Azure (qualquer camada de serviço) 3
- Azure Databricks (qualquer camada de serviço) com o runtime Apache Spark 3.3.04
1 Este link é resolvido para um tutorial para carregar o pacote.
2 Você pode usar a camada de pesquisa gratuita para indexar os dados de amostra, mas escolha uma camada mais alta se os volumes de dados forem grandes. Para as camadas faturáveis, forneça a chave de API de pesquisa na etapa Configurar dependênciasmais adiante.
3 Este tutorial usa a Inteligência de Documentos de IA do Azure e o Tradutor de IA do Azure. Nas instruções a seguir, forneça uma chave de conta multisserviços e a região. A mesma chave funciona para ambos os serviços.
É importante que você use uma conta multisserviços da Plataforma de IA do Azure com o tipo de API AIServices para este tutorial. Você pode verificar o tipo da API no portal do Azure, na seção Visão Geral da página da sua conta multisserviços da Plataforma de IA do Azure. Para mais informações sobre o tipo de API, confira Anexar um recurso multisserviços da Plataforma de IA do Azure na Pesquisa de IA do Azure.
4 Neste tutorial, o Azure Databricks fornece a plataforma de computação do Spark. Usamos as instruções do portal para configurar o cluster e o workspace.
Observação
Todos os recursos do Azure acima dão suporte a recursos de segurança na plataforma de identidade da Microsoft. Para simplificar, este tutorial pressupõe a autenticação baseada em chave, usando pontos de extremidade e chaves copiadas das páginas do portal do Azure de cada serviço. Se você implementar esse fluxo de trabalho em um ambiente de produção ou compartilhar a solução com outras pessoas, lembre-se de substituir as chaves codificadas pela segurança integrada ou por chaves criptografadas.
Etapa 1: Criar um cluster e um notebook do Spark
Nesta seção, crie um cluster, instale a biblioteca synapseml e crie um notebook para executar o código.
No portal do Azure, encontre seu workspace do Azure Databricks e selecione Iniciar workspace.
No menu à esquerda, selecione Computação.
Selecione Criar computação.
Aceite a configuração padrão. São necessários vários minutos para criar o cluster.
Verifique se o cluster está operacional e em execução. Um ponto verde ao lado do nome do cluster confirma seu status.
Instale a biblioteca
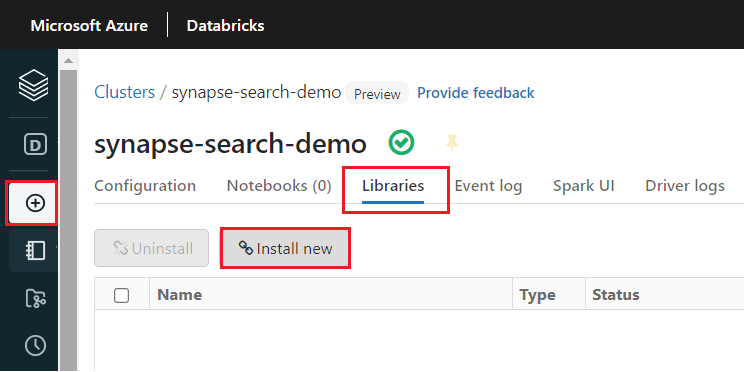
synapsemldepois que o cluster for criado:Selecione as Bibliotecas nas guias na parte superior da página do cluster.
Selecione Instalar novo.
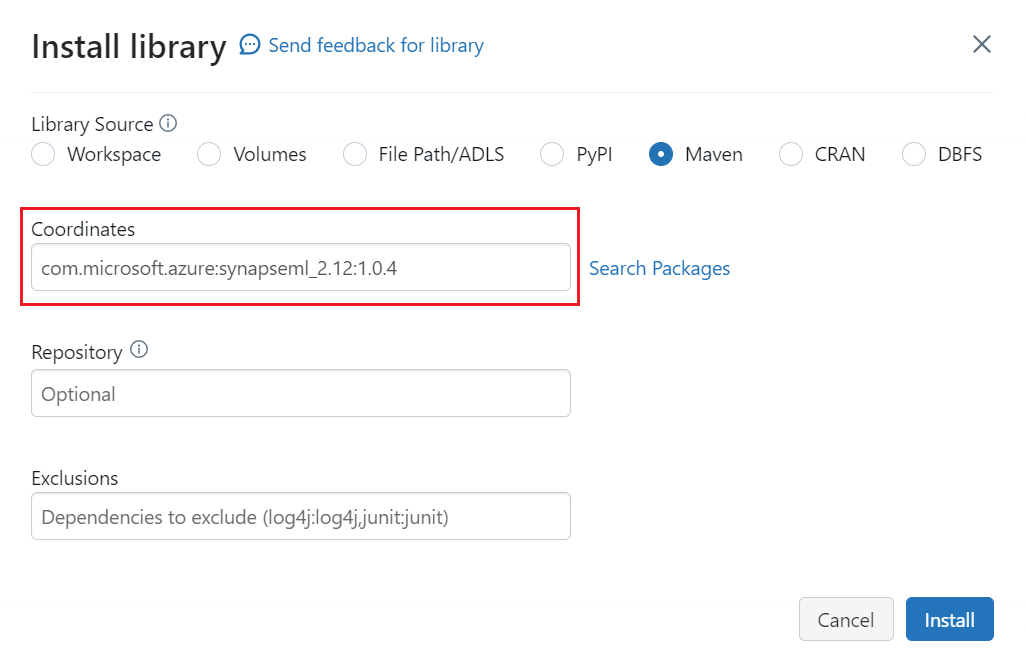
Selecione Maven.
Em Coordenadas, pesquise ou digite
com.microsoft.azure:synapseml_2.12:1.0.9Selecione Instalar.
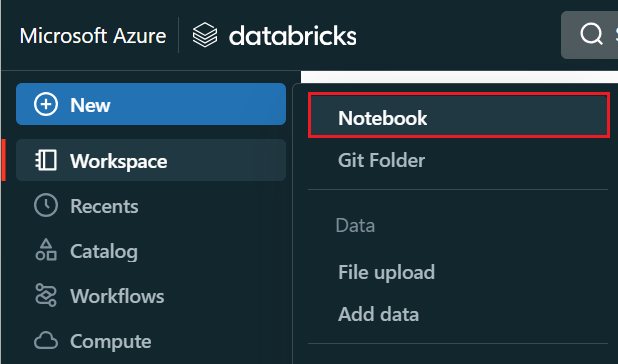
No menu à esquerda, selecione Criar>Notebook.
Dê um nome ao notebook, selecione Python como a linguagem padrão e selecione o cluster que tem a biblioteca
synapseml.Crie sete células consecutivas. Use essas informações para colar nos códigos das próximas seções.
Etapa 2: Configurar dependências
Copie e cole o código a seguir na primeira célula do notebook.
Substitua os espaços reservados por pontos de extremidade e chaves de acesso para cada recurso. Forneça um nome para um novo índice de pesquisa que será criado para você. Nenhuma outra modificação será necessária, portanto, execute o código quando estiver pronto.
Esse código importa vários pacotes e configura o acesso aos recursos do Azure usados neste fluxo de trabalho.
import os
from pyspark.sql.functions import udf, trim, split, explode, col, monotonically_increasing_id, lit
from pyspark.sql.types import StringType
from synapse.ml.core.spark import FluentAPI
cognitive_services_key = "placeholder-azure-ai-services-multi-service-key"
cognitive_services_region = "placeholder-azure-ai-services-region"
search_service = "placeholder-search-service-name"
search_key = "placeholder-search-service-admin-api-key"
search_index = "placeholder-for-new-search-index-name"
Etapa 3: Carregar dados no Spark
Cole o código a seguir na segunda célula. Nenhuma modificação será necessária, portanto, execute o código quando estiver pronto.
Esse código carrega alguns arquivos externos de uma conta de armazenamento do Azure. Os arquivos são várias faturas e são lidos em um dataframe.
def blob_to_url(blob):
[prefix, postfix] = blob.split("@")
container = prefix.split("/")[-1]
split_postfix = postfix.split("/")
account = split_postfix[0]
filepath = "/".join(split_postfix[1:])
return "https://{}/{}/{}".format(account, container, filepath)
df2 = (spark.read.format("binaryFile")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/form_subset/*")
.select("path")
.limit(10)
.select(udf(blob_to_url, StringType())("path").alias("url"))
.cache())
display(df2)
Etapa 4: Adicionar inteligência de documento
Cole o código a seguir na terceira célula. Nenhuma modificação será necessária, portanto, execute o código quando estiver pronto.
Esse código carrega o transformador AnalyzeInvoices e passa uma referência ao dataframe que contém as faturas. Ele chama o modelo de fatura predefinido da IA do Azure para Informação de Documentos para extrair as informações das faturas.
from synapse.ml.services import AnalyzeInvoices
analyzed_df = (AnalyzeInvoices()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setImageUrlCol("url")
.setOutputCol("invoices")
.setErrorCol("errors")
.setConcurrency(5)
.transform(df2)
.cache())
display(analyzed_df)
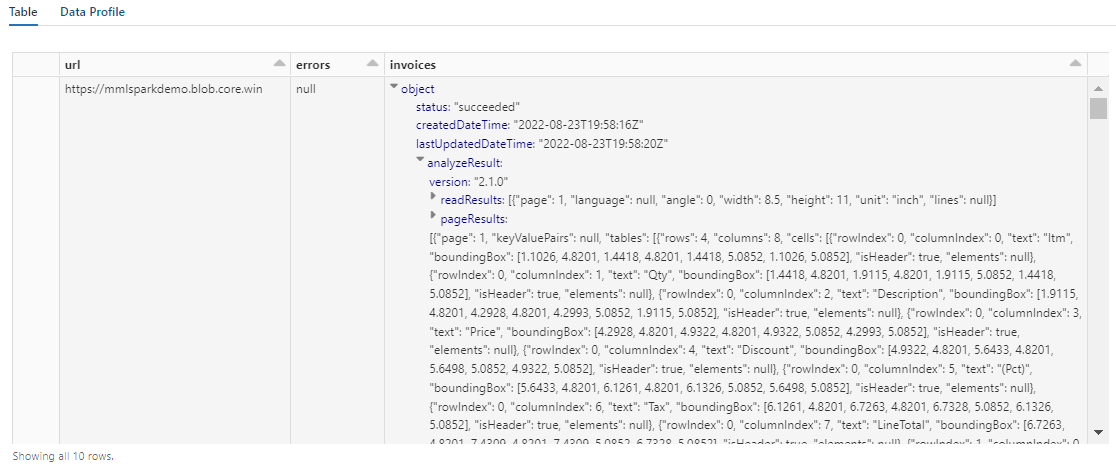
A saída dessa etapa deve ser semelhante à próxima captura de tela. Observe como a análise de formulários é empacotada em uma coluna densamente estruturada, com a qual é difícil de trabalhar. A próxima transformação resolve esse problema analisando a coluna em linhas e colunas.
Etapa 5: Reestruturar a saída de inteligência do documento
Cole o código a seguir na quarta célula e execute-o. Nenhuma modificação é necessária.
Esse código carrega FormOntologyLearner, um transformador que analisa a saída de transformadores da Informação de Documentos e infere uma estrutura de dados tabular. A saída de AnalyzeInvoices é dinâmica e varia de acordo com os recursos detectados em seu conteúdo. Além disso, o transformador consolida a saída em uma só coluna. Como a saída é dinâmica e consolidada, é difícil usá-la em transformações downstream que exigem mais estrutura.
FormOntologyLearner estende o utilitário do transformador AnalyzeInvoices procurando por padrões que podem ser usados para criar uma estrutura de dados tabular. Organizar a saída em várias colunas e linhas torna o conteúdo consumível em outros transformadores, como o AzureSearchWriter.
from synapse.ml.cognitive import FormOntologyLearner
itemized_df = (FormOntologyLearner()
.setInputCol("invoices")
.setOutputCol("extracted")
.fit(analyzed_df)
.transform(analyzed_df)
.select("url", "extracted.*").select("*", explode(col("Items")).alias("Item"))
.drop("Items").select("Item.*", "*").drop("Item"))
display(itemized_df)
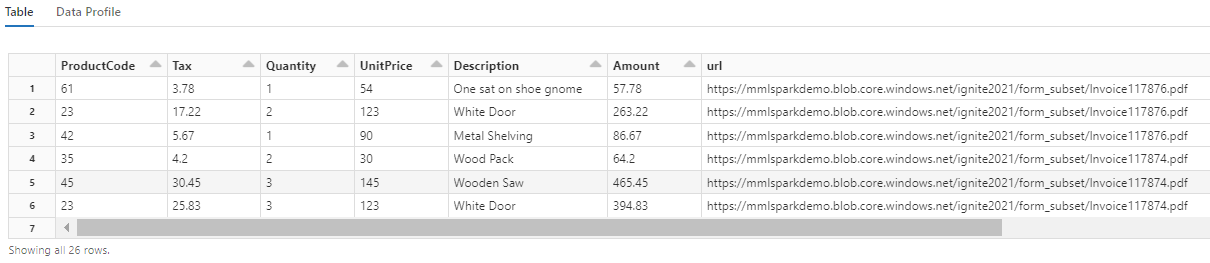
Observe como essa transformação reformula os campos aninhados em uma tabela, o que habilita as duas próximas transformações. Esta captura de tela é cortada para resumir. Se estiver acompanhando em seu próprio notebook, você terá 19 colunas e 26 linhas.
Etapa 6: Adicionar traduções
Cole o código a seguir na quinta célula. Nenhuma modificação será necessária, portanto, execute o código quando estiver pronto.
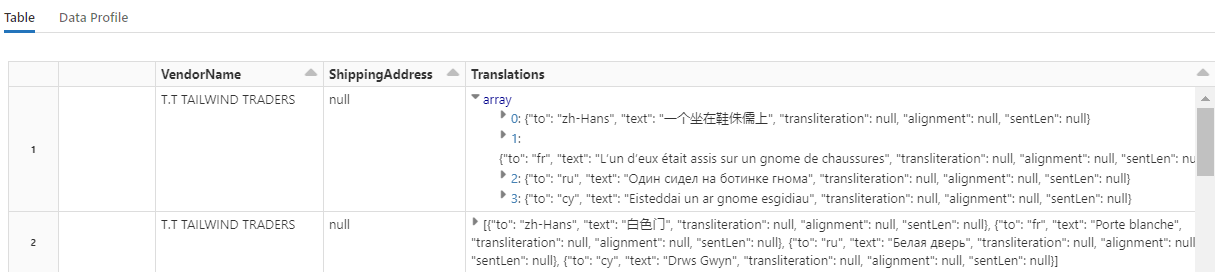
Esse código carrega Translate, um transformador que chama o serviço de Tradutor nos serviços de IA do Azure. O texto original, que está em inglês na coluna "Description", é traduzido para vários idiomas. Toda a saída é consolidada na matriz "output.translations".
from synapse.ml.cognitive import Translate
translated_df = (Translate()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setTextCol("Description")
.setErrorCol("TranslationError")
.setOutputCol("output")
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
.setConcurrency(5)
.transform(itemized_df)
.withColumn("Translations", col("output.translations")[0])
.drop("output", "TranslationError")
.cache())
display(translated_df)
Dica
Para verificar se há cadeias de caracteres traduzidas, role até o final das linhas.
Etapa 7: Adicionar um índice de pesquisa com o AzureSearchWriter
Cole o código a seguir na sexta célula e execute-o. Nenhuma modificação é necessária.
Esse código carrega AzureSearchWriter. Ele consome um conjunto de dados tabular e infere um esquema de índice de pesquisa que define um campo para cada coluna. Como a estrutura de traduções é uma matriz, ela é articulada no índice como uma coleção complexa com subcampos para cada tradução de idioma. O índice gerado tem uma chave de documento e usa os valores padrão para os campos criados usando a API REST Criar Índice.
from synapse.ml.cognitive import *
(translated_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
.withColumn("SearchAction", lit("upload"))
.writeToAzureSearch(
subscriptionKey=search_key,
actionCol="SearchAction",
serviceName=search_service,
indexName=search_index,
keyCol="DocID",
))
Você pode verificar as páginas do serviço de pesquisa no portal do Azure para explorar a definição de índice criada pelo AzureSearchWriter.
Observação
Se você não puder usar o índice de pesquisa padrão, poderá fornecer uma definição personalizada externa em JSON, passando o respectivo URI como uma cadeia de caracteres na propriedade "indexJson". Gere o índice padrão primeiro para que você saiba quais campos especificar e siga com propriedades personalizadas se precisar de analisadores específicos, por exemplo.
Etapa 8: Consultar o índice
Cole o código a seguir na sétima célula e execute-o. Nenhuma modificação é obrigatória, mas talvez você queira variar a sintaxe ou experimentar mais exemplos para explorar ainda mais o conteúdo:
Não há nenhum transformador nem módulo que emita consultas. Essa célula é uma chamada simples para a API REST de Documentos de Pesquisa.
Este exemplo específico está procurando a palavra "door" ("search": "door"). Ele também retorna uma "contagem" do número de documentos correspondentes e seleciona apenas o conteúdo dos campos "Descrição" e "Traduções" para os resultados. Se quiser ver a lista completa de campos, remova o parâmetro "select".
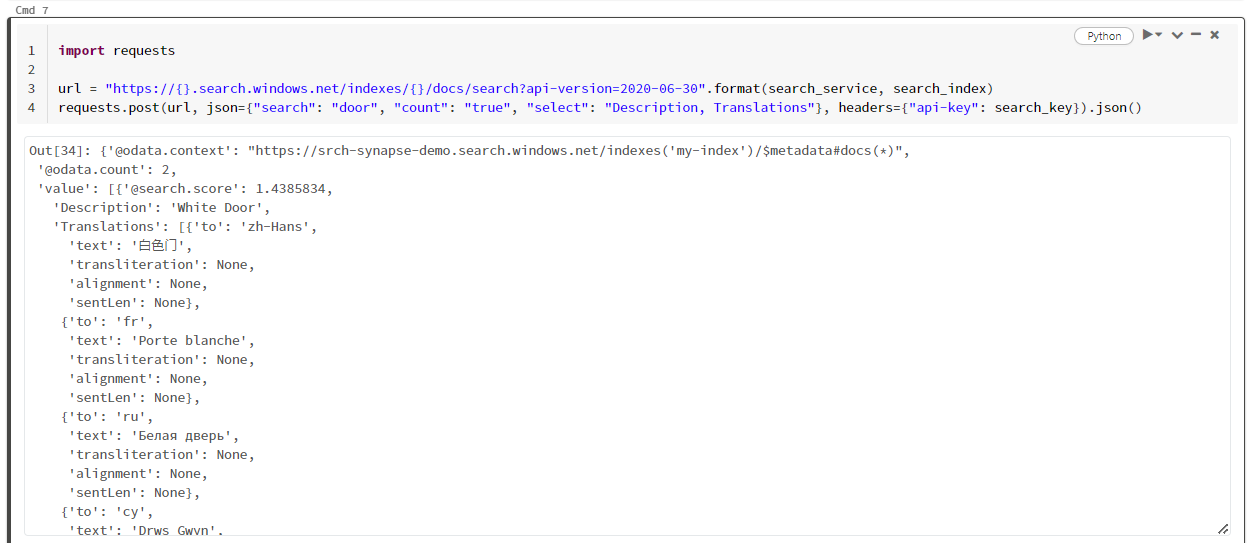
import requests
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2024-07-01".format(search_service, search_index)
requests.post(url, json={"search": "door", "count": "true", "select": "Description, Translations"}, headers={"api-key": search_key}).json()
A captura de tela a seguir mostra a saída da célula para o script de exemplo.
Limpar os recursos
Quando você está trabalhando em sua própria assinatura, no final de um projeto, é uma boa ideia remover os recursos que já não são necessários. Recursos deixados em execução podem custar dinheiro. É possível excluir os recursos individualmente ou excluir o grupo de recursos para excluir todo o conjunto de recursos.
Você pode localizar e gerenciar recursos no portal do Azure, usando o link Todos os recursos ou Grupos de recursos no painel de navegação à esquerda.
Próximas etapas
Neste tutorial, você conheceu o transformador AzureSearchWriter do SynapseML, que é uma nova maneira de criar e carregar índices de pesquisa no Azure AI Search. O transformador usa JSON estruturado como entrada. O FormOntologyLearner pode fornecer a estrutura necessária para a saída produzida pelos transformadores da Informação de Documentos no SynapseML.
Como próxima etapa, examine os outros tutoriais do SynapseML que produzem o conteúdo transformado que talvez você queira explorar por meio do Azure AI Search: